[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
The First Annual State of Apache Kafka® Client Use Survey
At the end of 2016 we conducted a survey of the Apache Kafka® community regarding their use of Kafka clients (the producers and consumers used with Kafka) and their priorities when deciding which clients to use.
As a company that is developing Kafka clients in 5 different languages, we wanted to know which languages matter most and which client properties are most important to our users. The survey was well received and generated 187 responses (thank you Kafka community!). We think all developers of Kafka clients can benefit from deeper understanding so we decided to share the survey results and discuss a few unexpected discoveries. Note that the survey addressed clients that are direct implementations of the Kafka protocol in different languages, but not libraries that provide advanced functionality on top of the protocol such as the Streams API.
Kafka Client: Language Adoption
To start, we wanted to learn which languages are most commonly used across the community. We let users choose multiple answers from a short list and also allowed them to fill in their own response.
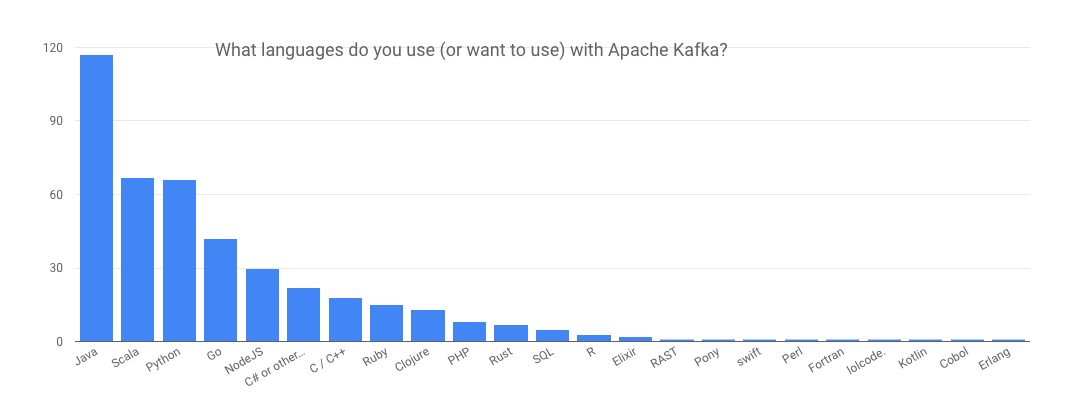
It comes as no surprise that Java is still the most popular language used with Apache Kafka. After all, Java clients are baked right into the Apache Kafka installation and it is a very popular language for enterprise data architectures. It is also no great surprise that Scala and Python are in second and third place – Kafka is written in Scala, so there was always large overlap between the communities and the Kafka ecosystem has three different Python clients for a reason.
The language whose adoption surprised us most is Clojure. Clojure was not part of our list of possible answers and yet 13 people wrote in to inform us that they use it with Kafka. Clojure is a popular language to use with Kafka and we are not sure why! We’ll be sure to track Clojure more closely in the future and to include it in our list next time we run this survey.
Another surprise is the length of the long tail: We did not know that Pony was a programming language, but it looks quite interesting and a good fit for Kafka. We were also surprised to discover that someone uses Kafka with Cobol. Perhaps they are updating their legacy mainframe application?
Of course engineers often use more than one language and the chart above reflects that. But if you are developing Kafka clients, you want to focus on the languages developers use as their primary go-to solution. So we also asked “which language do you mainly use?” and only allowed one selection:
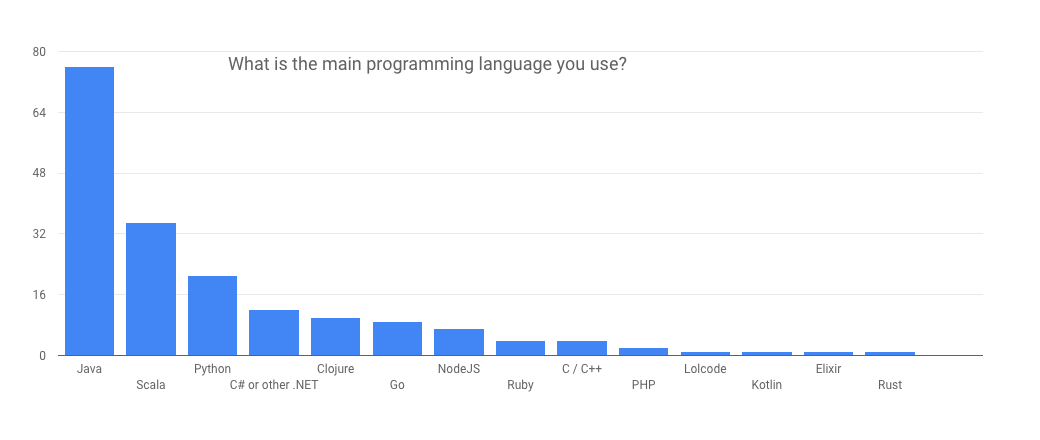
Java, Scala and Python are still the most commonly used with Java still having twice as many users as Scala. The interesting thing is that Go and NodeJS significantly dropped in popularity, now lagging behind C# and Clojure. All 13 people who wrote to say they use Clojure actually use it as their main language, but many Go and NodeJS users use it as a secondary language – perhaps for front-end or operational tools, but not for main backend development. We found this particularly interesting because throughout 2016 we were surprised by how many people expressed interest in a C# client. If we would have done this survey earlier, we would have been much less surprised.
And since we have all this information, we wondered – how many languages do engineers typically use? We derived the answer from responses to the first question:
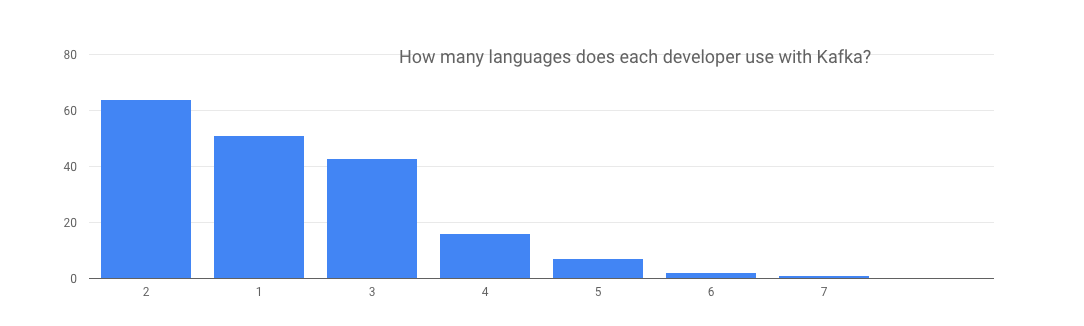
73% of respondents said they use two or more languages, so we were curious which language combinations are most popular.
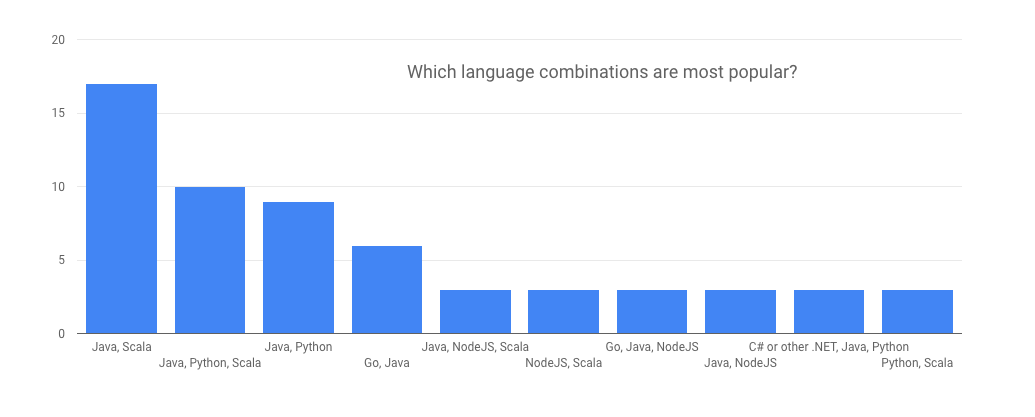
Various combinations of Java, Scala and Python are the most common. Since most combinations include Java + another language, it makes sense for client developers to make sure their client APIs are somewhat similar to those used by the Java clients – after all, many engineers will need to move back and forth between Java and their second language.
How users choose a Kafka client
But languages are really only part of the client story. The rich Kafka ecosystem provides multiple client choices for many of the popular languages. This led us to ask what developers really value when choosing among several available clients:
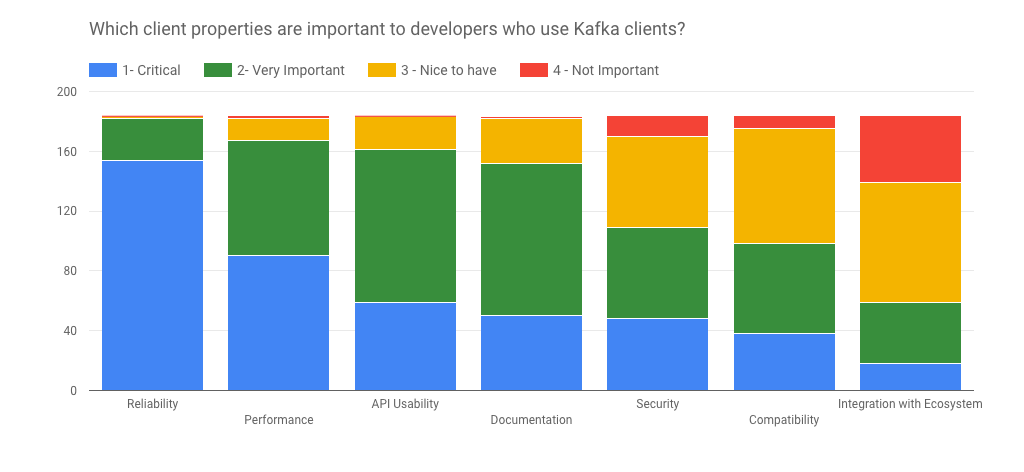
We were very glad we asked! We expected reliability to be important, but with so many use-cases around logs, clicks and metrics – we didn’t expect 87% of the responses to say reliability is “critical” and 99.5% to say reliability is either “critical” or “very important”. We are sure glad we put effort into extensive client system tests that allow us to make sure clients survive controlled shutdowns, crashes, leader elections, controller bounces and all kinds of failure conditions.
Performance is also very important: Almost 50% see it as “critical” and 89% see it as either “critical” or “very important”. This is followed by usable APIs and documentation.
Only 58% of the responders found security to be “critical” or “very important”. Security is often perceived as important as performance and reliability so it’s a bit surprising this number is this low. We’ll want to see if that dynamic changes 12 months from now when we run the survey again. We bet that security will become increasingly important as Kafka becomes the platform of choice for increasingly critical workloads.
Slightly over 50% found compatibility to be “critical” or “very important”. The Kafka developer community has always made significant efforts to maintain compatibility of new brokers with older versions of clients. In 0.10.2.0 release we improved this even further to allow compatibility of new clients with older brokers (as long as the brokers are newer than 0.10.0.0). A likely explanation for the seemingly lesser importance of compatibility might be that the Kafka project has done such a good job in the past in this regard that no one even thinks about compatibility issues. Given the frequency compatibility questions appear on the Kafka mailing list, it is clear that compatibility between different versions of clients and brokers is very important to developers.
Advice for Kafka client developers
For the last question in the survey, we asked respondents to offer some advice to those who develop the clients we all use. 60 (!) respondents took the time to provide advice to anyone considering writing Kafka clients.
Looking at the advice from birds-eye view shows that folks appreciate simplicity, performance and documentation:

When we read all the feedback, a few themes emerged.
Our users love reliability above everything else, saying: “Stability should be priority”. Reliability means good error handling: “No exception should be silently caught”. Reliability means good testing: “Know, document, and test your failure modes” and “Worry about stability under failure conditions (and testing that!) before worrying about performance”. It also means good metrics and logging: “Clearly defined failure mechanics and metrics for monitoring health” and “better logging for errors”
Our respondents wanted clients to be consistent with each other and expose the full range of capabilities the Kafka protocol provides. They asked for Consistent APIs across languages, should support same features”, “Don’t try too hard in using language constructs. Usually a few Kafka people run across the company and need to find their way to the wire in all clients” and “Try to make your base clients as similar as possible to the main Java client”. They also asked for consistent defaults: “Use sensible defaults for the options, preferably the official default ones”
Many asked for simplicity: “Make it easy to use.”, “Keep the simplest use case easy”, “Don’t introduce new concepts or try to enforce invariants that are not natural to kafka” and the memorable “keep it simple, support schema registry, don’t do any stupid shit”
And they shared suggestions for improving the documentation. Some users want more detailed documentation, especially around performance and reliability: “Documentation should show how to maximize throughput”, “Documentation should make very clear the threading models in use and what is threadsafe and what is not” and “Please document clearly data loss scenarios and tuning required on producer side to avoid/minimize data delivery loss” and many others wanted more examples “Provide working examples” and “Improve docs with real world scenarios”
Confluent currently supports and maintains both the Java clients that are part of Apache Kafka and clients for 5 additional languages: C/C++ (librdkafka), Python, Go and C#, all available as part of the Confluent Platform. It is our goal to provide feature-complete, reliable and high performance clients for everyone working with Apache Kafka so we’re pleased to see that the clients available as part of the Confluent solution maps nice to the top-5 most popular languages in our survey. We are working closely with client developers in the community to improve the quality of Kafka clients and we are looking forward to using the feedback from this survey to make things even better in 2017.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


