Let’s take an example. Consider a Facebook-like social networking app (albeit a completely hypothetical one) that updates the profiles database when a user updates their Facebook profile. There are several applications that need to be notified when a user updates their profile — the search application so the user’s profile can be reindexed to be searchable on the changed attribute; the newsfeed application so the user’s connections can find out about the profile update; the data warehouse ETL application to load the latest profile data into the central data warehouse that powers various analytical queries and so on.
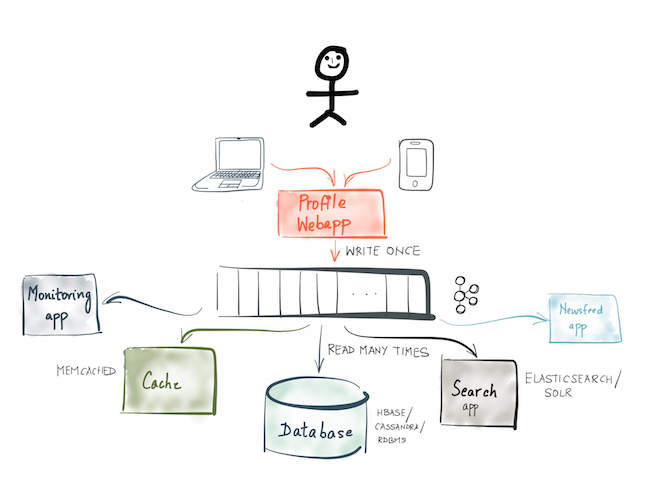
Event sourcing based architecture
Event sourcing involves changing the profile web app to model the profile update as an event — something important that happened — and write it to a central log, like a Kafka topic. In this state of the world, all the applications that need to respond to the profile update event, merely subscribe to the Kafka topic and create the respective materialized views – be it a write to cache, index the event in Elasticsearch or simply compute an in-memory aggregate. The profile web app itself also subscribes to the same Kafka topic and writes the update to the profiles database.
Event Sourcing: Some trade-offs
There are several advantages to modeling applications to use event sourcing — It provides a complete log of every state change ever made to an object; so troubleshooting is easier. By expressing the user intent as an ordered log of immutable events, event sourcing gives the business an audit and compliance log which also has the added benefit of providing data provenance. It enables resilient applications; rolling back applications amounts to rewinding the event log and reprocessing data. It has better performance characteristics; writes and reads can be scaled independently. It enables a loosely coupled application architecture; one that makes it easier to move towards a microservices-based architecture. But most importantly:
Event sourcing enables building a forward-compatible application architecture — the ability to add more applications in the future that need to process the same event but create a different materialized view.
For the upsides mentioned above, there are some downsides as well. Event sourcing has a higher learning curve; it is a new and unfamiliar programming model. The event log might involve more work to query it as it requires converting the events into the required materialized state suitable to query.
That was a quick introduction to event sourcing and some tradeoffs. This article is not meant to go into details of event sourcing or advocate for its usage. You can read more about event sourcing and various tradeoffs here.
Kafka as a backbone for Event Sourcing
Event sourcing and Apache Kafka are related. Here’s how – Event sourcing involves maintaining an immutable sequence of events that multiple applications can subscribe to. Kafka is a high-performance, low-latency, scalable and durable log that is used by thousands of companies worldwide and is battle-tested at scale. Hence, Kafka is a natural backbone for storing events while moving towards an event sourcing based application architecture.
Event Sourcing and CQRS
Furthermore, the event sourcing and CQRS application architecture patterns are also related. Command Query Responsibility Segregation (CQRS) is an application architecture pattern most commonly used with event sourcing. CQRS involves splitting an application into two parts internally — the command side ordering the system to update state and the query side that gets information without changing state. CQRS provides separation of concerns – The command or write side is all about the business; it does not care about the queries, different materialized views over the data, optimal storage of the materialized views for performance and so on. On the other hand, the query or read side is all about the read access; its main purpose is making queries fast and efficient.
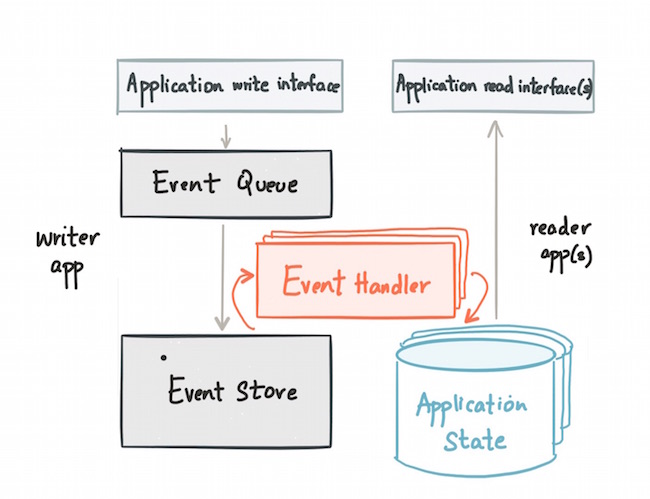
Refactoring an application using event sourcing and CQRS
The way event sourcing works with CQRS is to have part of the application that models updates as writes to an event log or Kafka topic. This is paired with an event handler that subscribes to the Kafka topic, transforms the event (as required) and writes the materialized view to a read store. Finally, the read part of the application issues queries against the read store.
CQRS has a few advantages — It decouples the load from writes and reads allowing each to be scaled independently; the various read paths themselves can be scaled independently. Furthermore, the read store can be optimized for the query pattern of the application; a graph application can use Neo4j as its read store, a search application can use Lucene indexes and a simple content serving webapp can use an embedded cache. In addition to technology benefits, CQRS also has organizational benefits — by decoupling the write and read paths, you can decouple the teams responsible for the business logic of the write and read paths.
This article only scratches the surface of the nuances of CQRS. If you want to know more, I recommend reading Martin Fowler’s and Udi Dahan’s articles on the subject.
So far, I’ve provided an introduction to event sourcing and CQRS and described how Kafka is a natural backbone for putting these application architecture patterns into practice. But where and how does stream processing come into the picture?
CQRS and Kafka’s Streams API
Here’s how stream processing and, in particular, Kafka Streams enables CQRS. The event handler subscribes to the event log (a Kafka topic), consumes events, processes those events and applies the resulting updates to the read store. This process of doing low-latency transformations on a stream of events has a name — stream processing. In the 0.10 release of Apache Kafka, the community released Kafka Streams; a powerful stream processing engine for modeling transformations over Kafka topics.
Kafka Streams is a great fit for building the event handler component inside an application built to do event sourcing with CQRS. It is a library so it can be embedded in any standard Java application to model transformations on streams of events. For example, here is a code snippet that does word count using Kafka Streams; you can access the code for the entire program in the Confluent examples github repository.
So the event handler inside an application can easily be represented as a Kafka Streams topology, but going a step further, there are two different options available for modeling the output from the event handler as updates to the data store that models the application state.
Take 1: Model application state as an external datastore
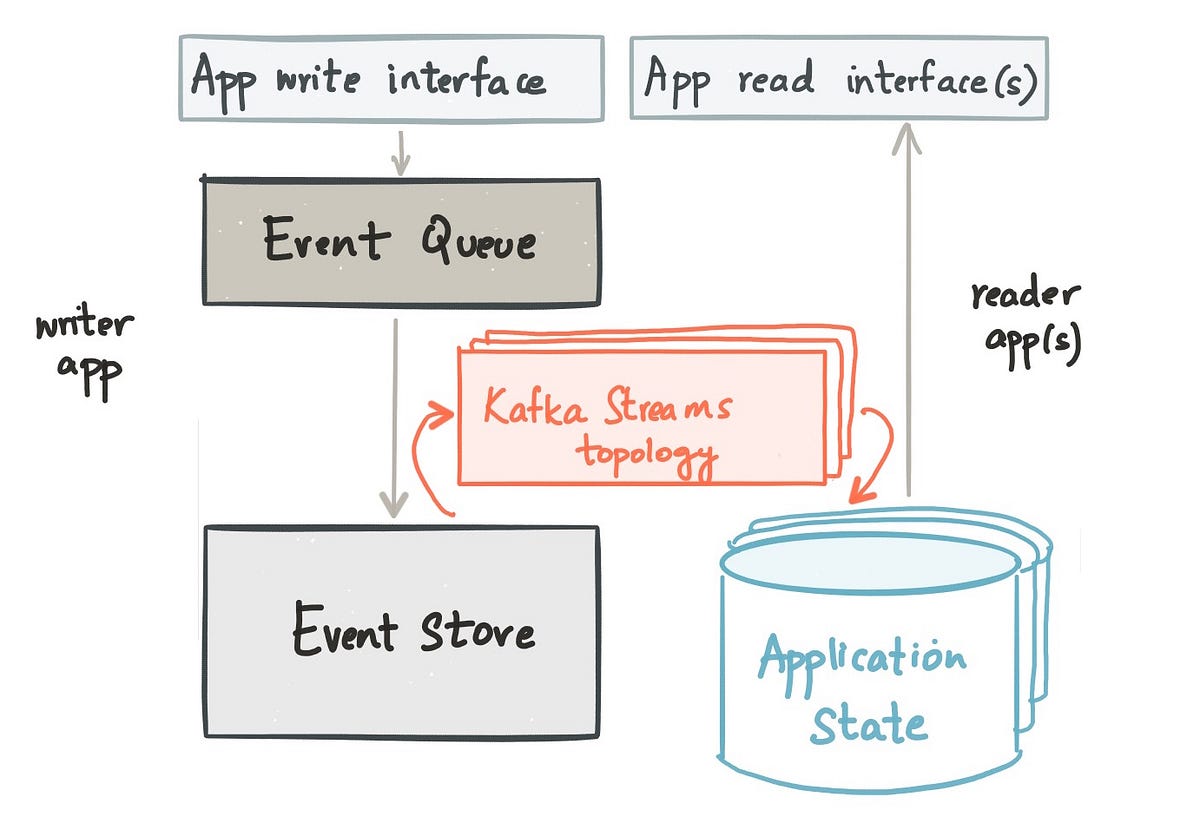
The output from a Kafka Streams topology can either be a Kafka topic (as shown in the example above) or writes to an external datastore like a relational database. In this view of the world, the event handler is modelled as a Kafka Streams topology and the application state is modelled as an external datastore that the user trusts and operates. This option for doing CQRS advocates the use of Kafka Streams to model just the event handler, leaving the application state to live in an external data store that is the final output of the Kafka Streams topology.
Take 2: Model application state as local state in Kafka Streams
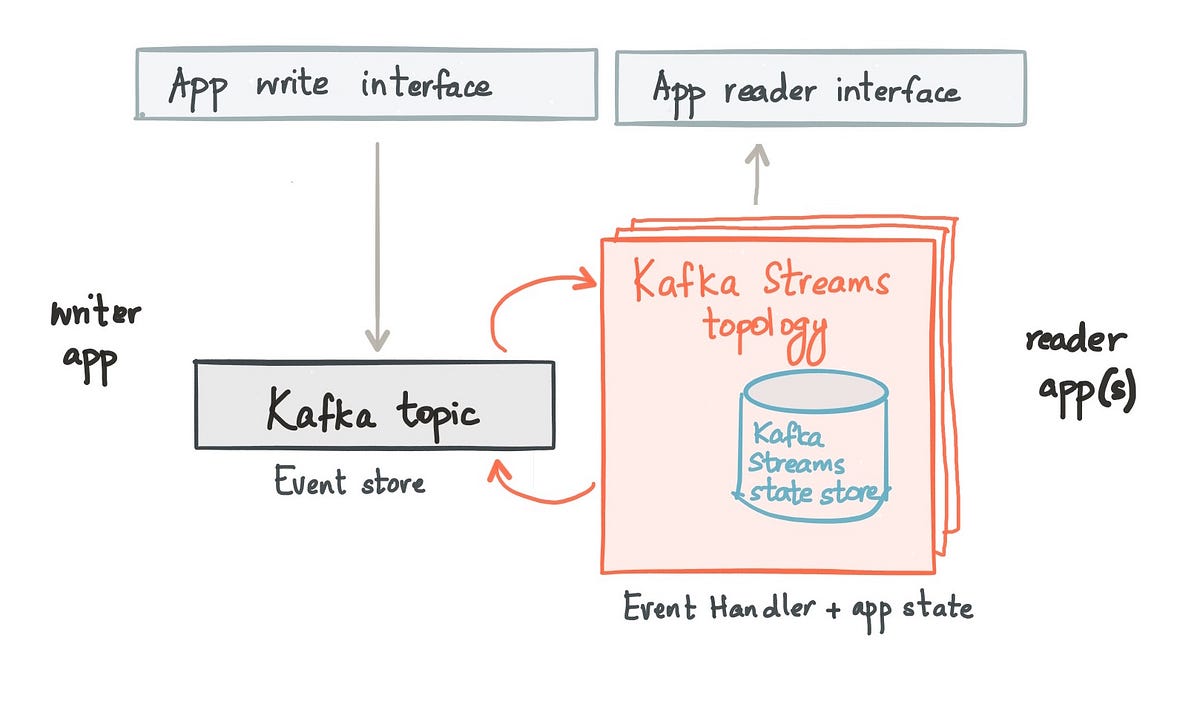
As an alternative, in addition to modeling the event handler, Kafka Streams also provides an efficient way to model the application state — it supports local, partitioned and durable state out-of-the-box. This local state can be a RocksDB store, or simply, an in-memory hashmap.
The way this works is that every instance of an application which embeds the Kafka Streams library to do stateful stream processing, hosts a subset of the application’s state, modeled as shards or partitions of the state store. The state store is partitioned the same way as the application’s key space. As a result, all the data required to serve the queries that arrive at a particular application instance are available locally in the state store shards. Fault tolerance for this local state store is provided by Kafka Streams by logging all updates made to the state store, transparently, to a highly-available and durable Kafka topic. So if an application instance dies and the local state store shards it hosted are lost, Kafka Streams can recreate state store shards by simply reading from the highly-available Kafka topic and refilling the data in the state store.
Effectively, Kafka Streams uses Kafka like a commit log for its local, embedded database. This is exactly how a traditional database is designed underneath the covers — the transaction or redo log is the source of truth and the tables are merely materialized views over the data stored in the transaction log.
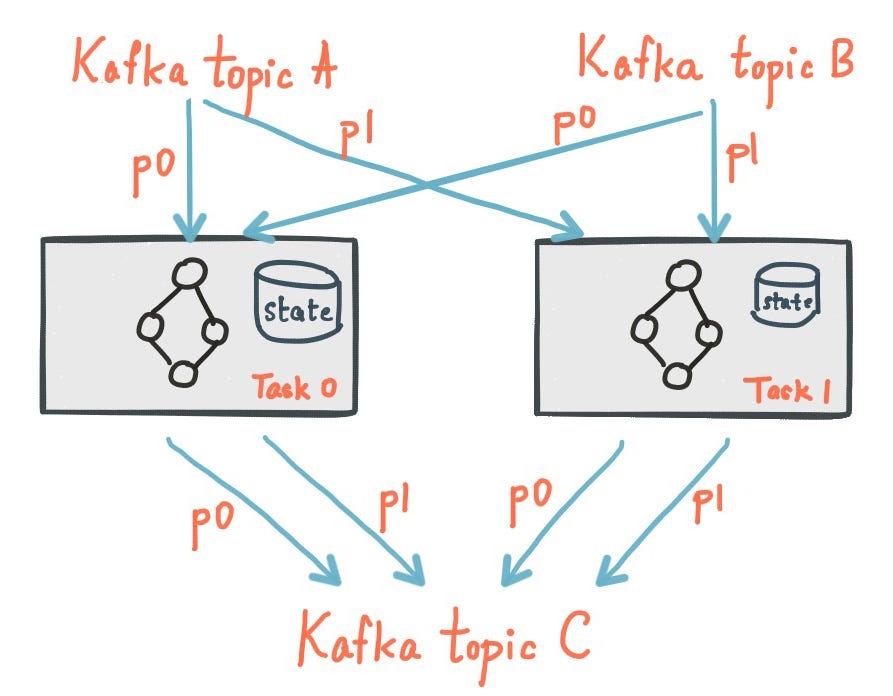 Local, partitioned, durable state in Kafka Streams
Local, partitioned, durable state in Kafka Streams
There are more advantages to using Kafka Streams for stateful applications built to use CQRS – Load balancing and failover are also built into Kafka Streams; if one application instance fails, Kafka Streams automatically redistributes the partitions of the Kafka topics as well as the internal state store shards amongst the remaining application instances. Similarly, Kafka Streams allows for elastic scaling; if new instances of an application that does CQRS using Kafka Streams are started, it automatically moves existing shards of the state store as well as partitions of the Kafka topics evenly amongst the newly started application instances. And all these capabilities are available to the user of Kafka Streams in a transparent manner.
Applications that need to move to a CQRS-based pattern using Kafka Streams do not need to worry about fault tolerance, availability, and scalability of the application and its state.
This embedded, partitioned and durable state store is exposed to the user through a first-class abstraction unique to Kafka Streams — a KTable.
Interactive Querying in Kafka Streams
In the upcoming release of Apache Kafka, Kafka Streams will allow its embedded state store to be queryable.
This unique capability in Kafka Streams — Interactive Queries (previously known to the Kafka community as Queryable State) — also makes it a fit for applying the CQRS design pattern to an application. The event handler is modeled as a Kafka Streams topology that produces data to the read store, which is nothing but the embedded state store inside Kafka Streams. The read part of the application uses the StateStore API for the state store and builds on its get() API to serve reads.
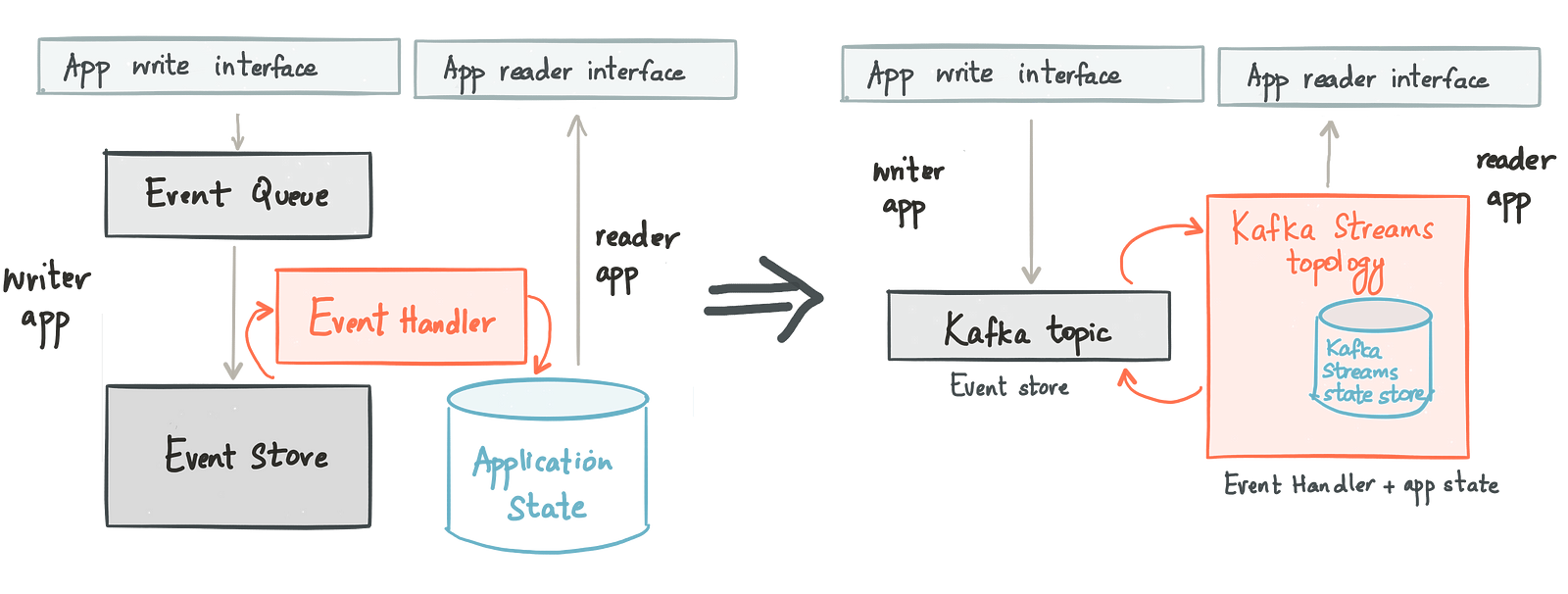
Event sourcing and CQRS based application using Kafka and Kafka Streams
The case for Interactive Queries in Kafka Streams
Note that the use of the embedded state store in Kafka Streams using the Interactive Queries feature is purely optional and does not make sense for all applications; sometimes you just want to use an external database you know and trust. As an alternative, while using Kafka Streams, you can also send the data to an external database like Cassandra and have the read part of the application query that.
But, when does the use of local, embedded application state like this make sense? Here are some pros and cons to consider —
Cons
- The resulting application is now stateful and requires a bit more care to manage.
- It involves moving away from a datastore you know and trust.
Pros
- There are fewer moving pieces; just your application and the Kafka cluster. You don’t have to deploy, maintain and operate an external database to store state required by your application alone.
- It enables faster and more efficient use of the application state. Data is local to your application (in memory or possibly on SSDs); you can access it very quickly. This is especially useful for applications that need to access large amounts of application state. Also, there is no duplication of data between the store doing aggregation for stream processing and the store answering queries.
- It provides better isolation; the state is within the application. One rogue application cannot overwhelm a central data store shared by other stateful applications.
- It allows for flexibility; the internal application state can be optimized for the query pattern required by the application.
Event Sourcing, CQRS using Kafka: The Big Win
The pros and cons I listed above characterize the various tradeoffs involved, however, I think the most significant win of moving towards this application architecture is that application upgrades get simpler. The traditional model of handling no-downtime upgrades for applications — that rely on an external database for its application state — is fairly involved. No downtime upgrades would need the new and the old version of the application to be running at the same time. After upgrading a few instances, if a bug is found, you need to have the ability to transparently switch load back to the old instances of the same application. Given that the new and old instances would need to update the same tables in the external database, extra care needs to be taken to pull off such no-downtime upgrades without corrupting data in the state store.
Now consider the same no-downtime upgrade problem for stateful applications that rely on local, embedded state. This model allows you to roll out the new version of the application alongside the old version (with a different application id in Kafka Streams). Each owns its copy of the application state processed the way its version of the application business logic dictates. You can direct traffic from the old to the new gradually. If the new version has some bug that produces unexpected results in the application state store, you can always just throw it away, fix the bug, redeploy the application and let it rebuild its state off of the log.
Putting it all together: Retail Inventory application
Let’s now take an example to illustrate how the concepts introduced in this article can be put into practice — how Kafka and Kafka Streams can be used to enable event sourcing and CQRS for an application.
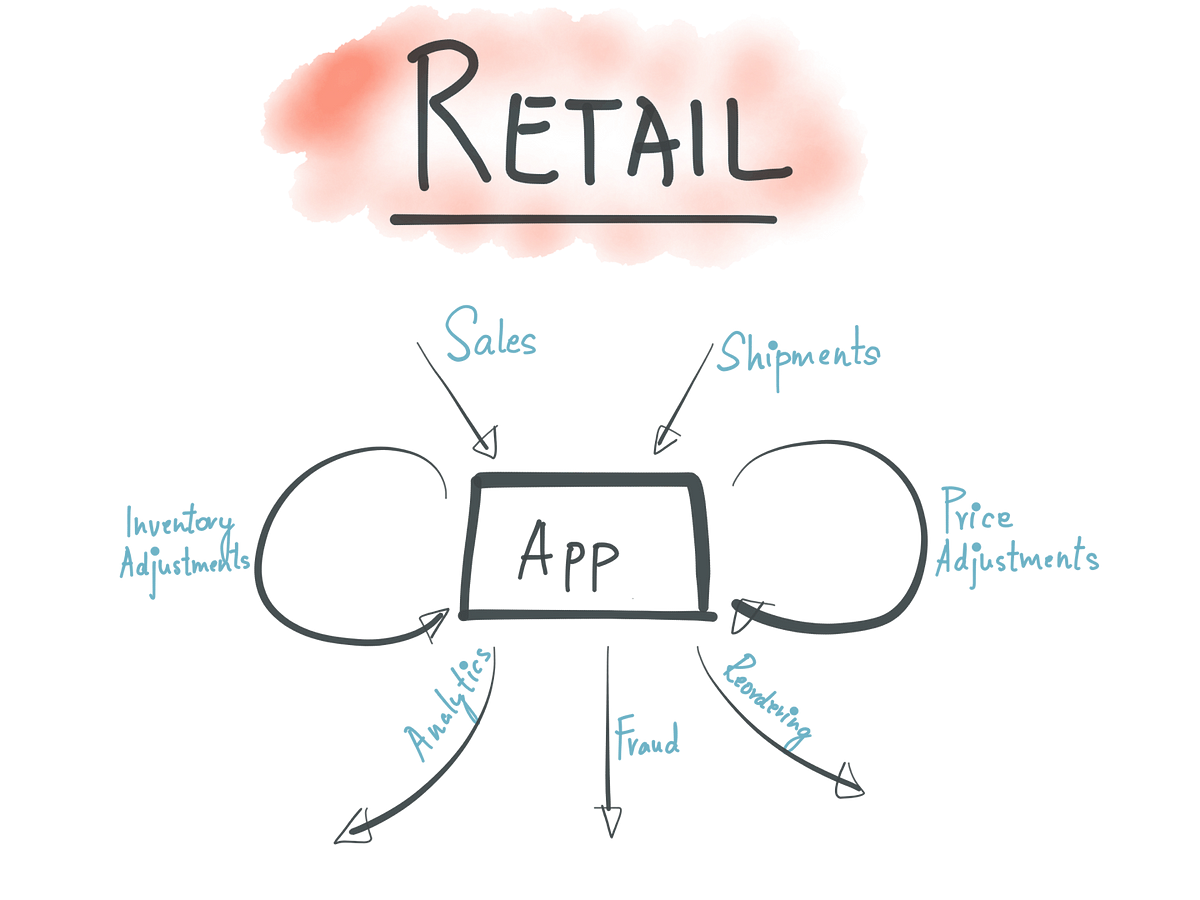
Sample retail application architecture
Consider an application for brick & mortar retailer that manages the inventory for all stores; when a new shipment arrives or a new sale happens, it updates the inventory table and to know the current state of a store’s inventory, it queries the inventory table.
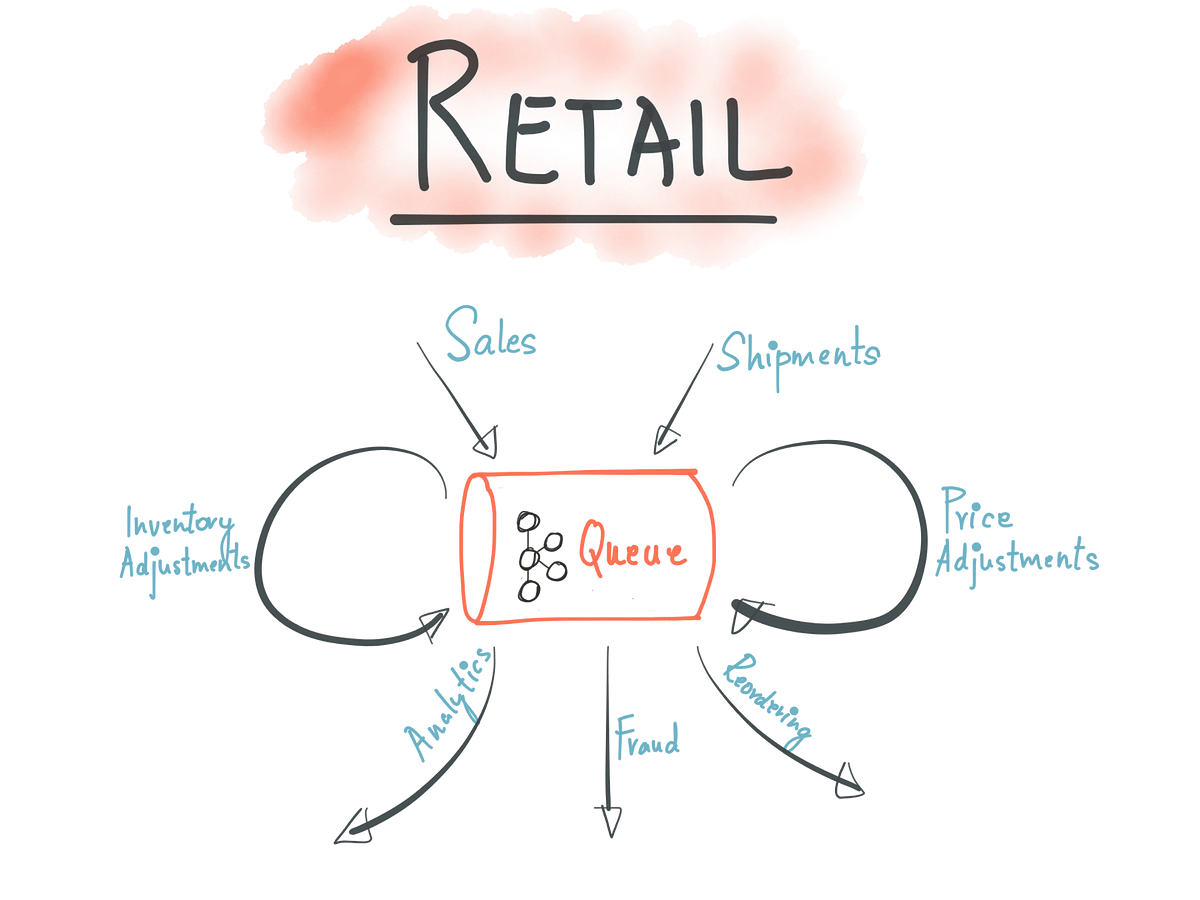 Retail application architecture with event sourcing — powered by Kafka
Retail application architecture with event sourcing — powered by Kafka
If we were to apply the event sourcing architecture pattern to this Inventory app, a new shipment will be represented as an event in a Shipments Kafka topic. Similarly, a new sale will be represented as an event in a Sales Kafka topic, perhaps written by the Sales app. For simplicity, let’s assume that the key for a Kafka message in both the Sales and Shipments topic is the {store id, item id} and the value is the count of the number of items in a store.
The event handler inside the Inventory app is modeled as a Kafka Streams topology that joins the Sales and Shipments Kafka topics. The join operation creates and updates a state store — InventoryTable — that represents the current state of the inventory updated in a continuous fashion.
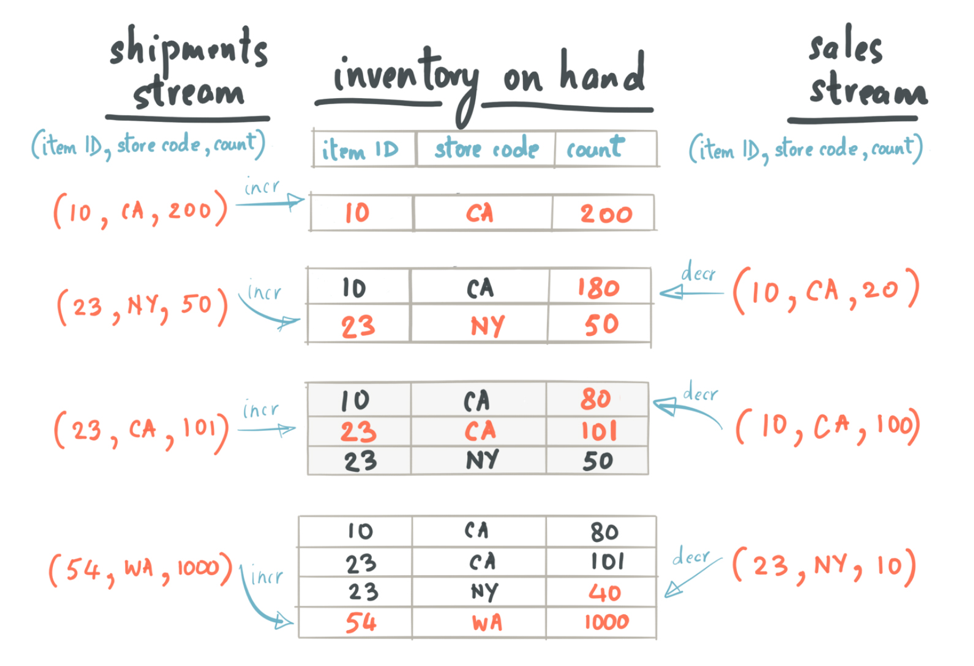
Internals of the join operation to build the InventoryTable
An application like this might be deployed across several instances on different machines (as shown in the figure below). And every instance of the InventoryApp hosts a subset of shards of the InventoryTable holding the result of this join operation. When a user queries the InventoryApp to know the current inventory count for an item in a store —
- A random server running InventoryApp gets a request: GET /inventory/stores/{store id}/items/{item id}/count
- It uses the metadataForKey() API on the Kafka Streams instance to get the StreamsMetadata for a store and the key. StreamsMetadata holds the host and port information for every store in a Kafka Streams topology. Using the StreamsMetadata, the application checks if this instance has the InventoryTable partition containing key {store id, item id}. If so, it uses the store(“InventoryTable”) api on the local Kafka Streams instance to fetch that store and query it.
- If not, it finds the host/port for the instance currently holding the Kafka partition containing {store id, item id}, and forwards the GET request for /inventory/stores/{store id}/items/{item id}/count to the InventoryApp instance running on that host.
- Returns the inventory count to the user
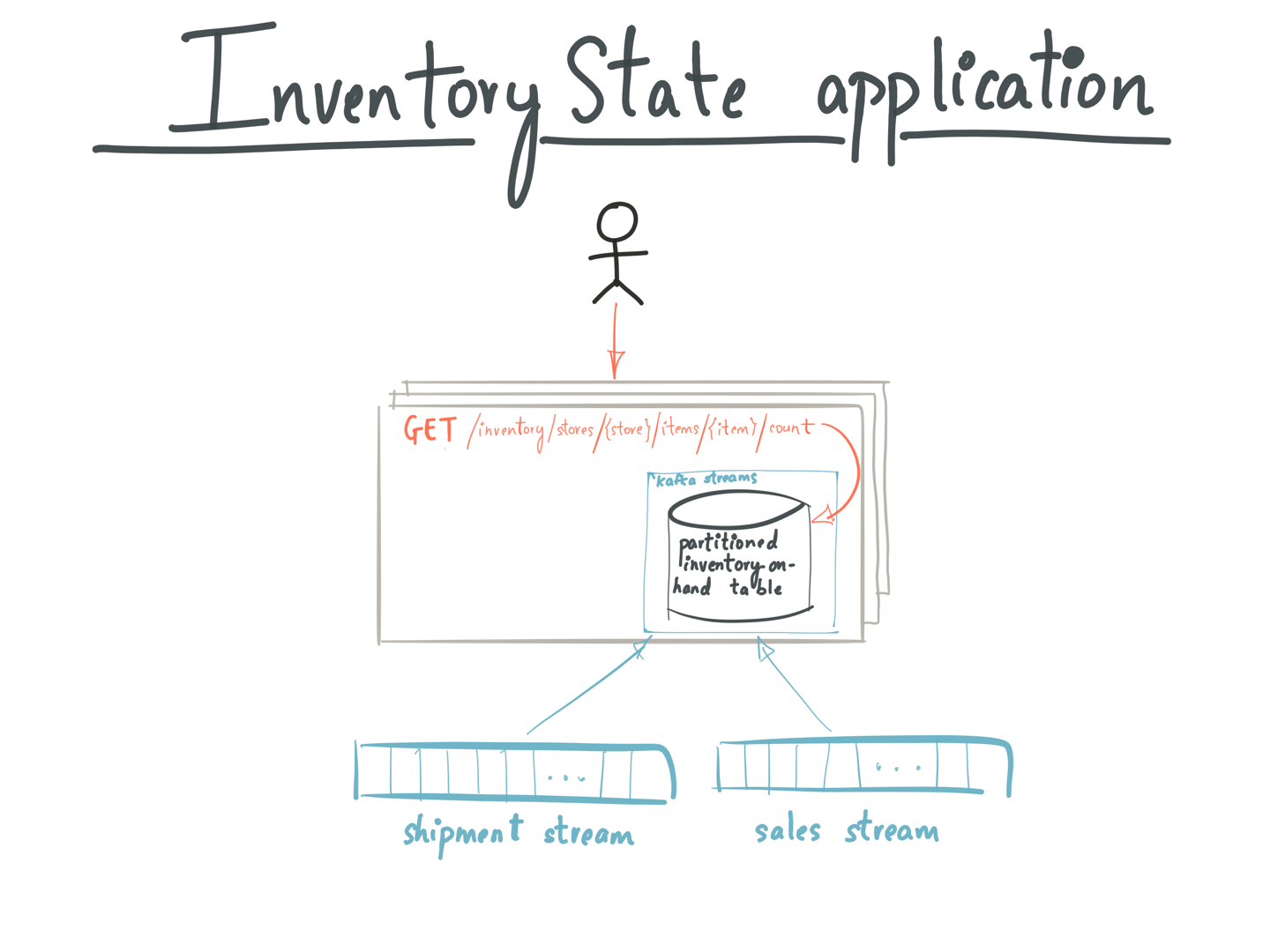
InventoryState application using Interactive Querying in Kafka Streams
To learn more about the Interactive Queries feature, please read its documentation. In addition to these resources, see this presentation from Capital One that applies some of the ideas introduced in this post in practice and outlines an application architecture based on REST, event sourcing, CQRS and reactive stream processing, using Kafka Streams.
Storing and querying local state, as shown in the example above, may not make sense for some stateful applications. Sometimes, you want to store your state in an external database you know and trust. For instance, in the example above, you can use Kafka Streams to compute the inventory count using the join operation but choose to write the result to an external database and query that instead.
It is worth noting, however, that there are several advantages to building stateful applications that query local state, as mentioned earlier in the post.
Concluding thoughts
Event sourcing provides an efficient means for applications to log their inherent, and inevitable changes in state, using a zero loss protocol. This means recovery is simple and efficient, as it is based entirely on a journal, or an ordered log like Kafka. CQRS goes a step further, turning raw events into queryable view; a view that is carefully formed to be relevant to other business processes. Kafka’s Streams API provides both the declarative functions required to create these views in a streaming fashion, as well as a scalable query layer, so users can interact with this view directly. The result is an event-sourcing and CQRS based application architecture, wherever applicable, built on Apache Kafka; allowing such applications to also leverage the core competency of Kafka — performance, scalability, security, reliability and large-scale adoption.
Above all – building stateful applications in this manner allows organizations to end up with a loosely-coupled application architecture — one that is resilient and scalable, easier to troubleshoot and upgrade and most importantly, one that is forward-compatible.
Interested in more?
If you’re looking for the fastest way to run Apache Kafka, you can sign up for fully managed Apache Kafka as a service and receive $400 to spend within Confluent Cloud during your first 60 days, plus an additional $60 of free usage when you use the promo code CL60BLOG.*





