[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Enterprise Streaming Multi-Datacenter Replication using Apache Kafka
One of the most common pain points we hear is around managing the flow and placement of data between datacenters. Almost every Apache Kafka user eventually ends up with clusters in multiple datacenters, whether their own datacenters or different regions in public clouds. There are many reasons you might need data to reside in Kafka clusters spread across multiple datacenters.
- Geolocalization improves latency and responsiveness for users. However, not all data can be partitioned between datacenters; some may need to be available across all datacenters.
- Backups for disaster recovery are a must for any mission critical data. To protect against natural disasters these backups must be geographically distributed, so stretched clusters are not an option.
- Analytics applications spanning your entire dataset will need data from multiple datacenters aggregated into a single global cluster.
- Sometimes you’ll need to migrate data to a new datacenter. This might be to decommission your datacenter or as part of a migration to the cloud.
These different use cases lead to a number of different deployment patterns for Kafka, but they all share a common requirement: data needs to be copied from one Kafka cluster to another (and sometimes in both directions).
Although Apache Kafka ships with a tool called MirrorMaker that allows you to copy data between two Kafka clusters, it is pretty barebones. We regularly see users encounter gaps that make it more difficult to execute a multi-datacenter plan than it should be. For example, MirrorMaker will copy each message from the source cluster to destination cluster, but doesn’t keep anything else about the two clusters in sync: topics can end up with different numbers of partitions, different replication factors, and different topic-level settings. Trying to manually keep all these settings in sync is error prone and can lead downstream applications, or even replication itself, to fail if the systems fall out of sync. It also has a complex configuration spread across multiple files, requires keeping those configs in sync across instances, and is yet another service to deploy and monitor. We have consistently seen the need for an easier, more complete solution to working with Kafka across multiple datacenters.
Today, I’m happy to introduce Multi-Datacenter Replication, a new capability within Confluent Platform that makes it easy to replicate your data between Kafka clusters across multiple datacenters. Multi-Datacenter Replication fully automates this process, whether you’re aggregating data for analytics, need a backup, or are migrating from on prem to the cloud.
Confluent Platform now comes with these important features out of the box:
- Dynamic topic creation in the destination cluster with matching partition counts, replication factors, and topic configuration overrides.
- Automatic resizing of topics when new partitions are added in the source cluster.
- Automatic reconfiguration of topics when topic configuration changes in the source cluster.
- Topic selection using whitelists, blacklists, and regular expressions. Limit the data you replicate to just the set of data you need.
- Support for replicating between secure Kafka clusters.
- Scalability and fault tolerance baked in by leveraging Kafka’s Connect API
- Integration with Confluent Control Center: configure, deploy, and monitor Multi-Datacenter Replication with ease.
With these features you get hassle-free replication of data, at scale, without writing a single line of code.
At its core, Multi-Datacenter Replication is implemented via a Kafka source connector that reads input from one Kafka cluster and passes that data to the API to be produced to the destination cluster. This means Multi-Datacenter Replication is enabled by all the benefits you’ve come to expect from the Kafka Connect API: the ability to scale elastically, fault tolerance, and a shared, easy to monitor infrastructure for data integration. This also means you can monitor Multi-Datacenter Replication in Confluent Control Center with the same ease as you would monitor any other connector.
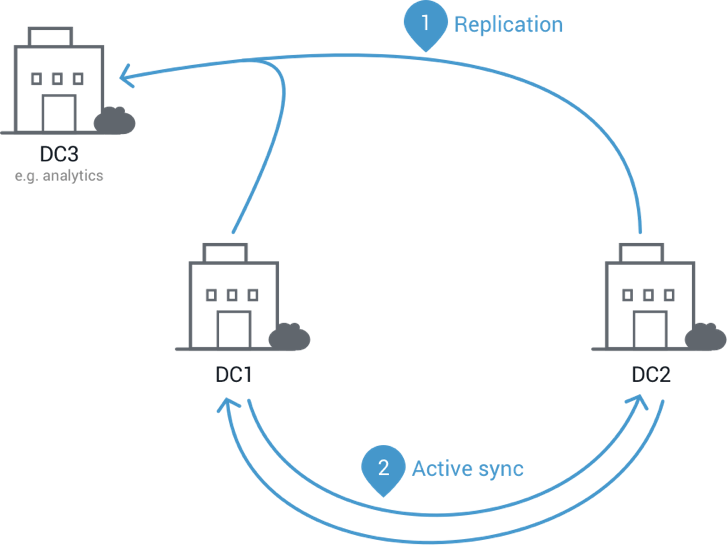
As an example of how you can immediately start leveraging Multi-Datacenter Replication, let’s look at an aggregation use case. Suppose you have an application running in multiple data centers. In each DC you have a Kafka cluster that your application reports data about user actions to. You can process the resulting data within each datacenter independently, but to get a global view of what your users are doing you would need to combine the data sets. For some simple types of analysis you might be able to combine the results from each datacenter, but in many cases, you’ll need to get all the data in one place and then run your analysis.
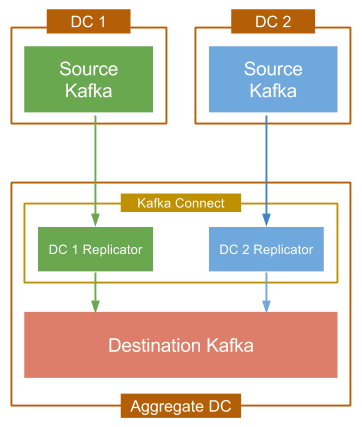
The image shows how you would implement this pattern with Multi-Datacenter Replication:
- Provision the destination Kafka cluster with a cluster of Kafka Connect workers. (You can test with a standalone worker, but distributed mode is recommended for production environments for scalability and fault tolerance).
- On the Connect cluster you provisioned, configure one source connector for each source Kafka cluster. For each connector, specify:
- Connection information for the source Kafka cluster, including its Zookeeper.
- Connection information for the destination Zookeeper. (Kafka connections are defined at the worker configuration level.)
- The set of topics you want copied, as a regex, blacklist, or whitelist.
- How topics should be renamed. By default topic names will be maintained exactly, but when data from multiple clusters is being aggregated you’ll want to add a prefix or suffix to identify the source datacenter, keeping the data in the aggregate cluster isolated and organized. This is especially important if you need consumers in the destination cluster to only read data from a specific data-center.
- Start your connector and watch your data start flowing into your destination DC.
Here you can see how simple setting up Multi-Datacenter Replication from Confluent Control Center is:
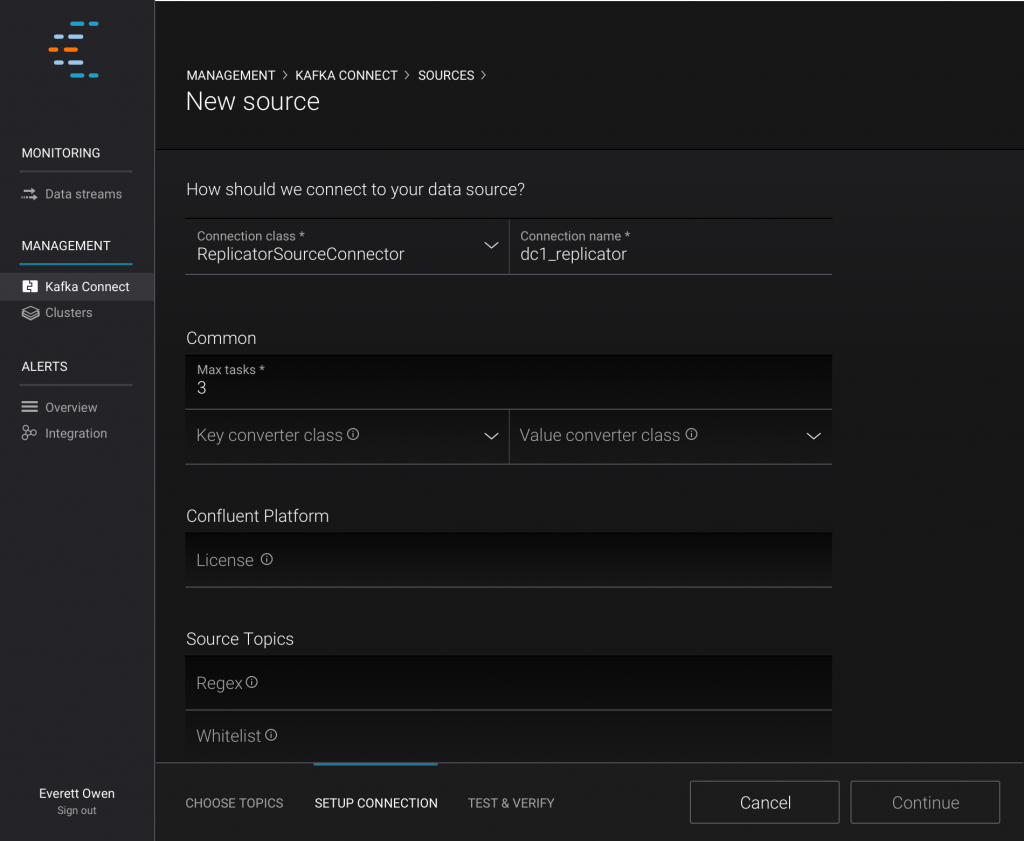
The connector should start creating topics in the destination cluster immediately and then start replicating messages. If you create new topics or modify settings on existing topics, you should see those reflected shortly in the destination cluster without any manual intervention.
As you can see, after some initial setup, Multi-Datacenter Replication can be mostly hands-off while ensuring your data is correctly replicated. If you want to see how easy it is for yourself, download Confluent Platform to try it out and check out the documentation for more details, configuration options, and examples. While Multi-Datacenter Replication is easy to implement, planning for a Multi-datacenter architecture can be more complex and involve many decisions, trade-offs and possible pitfalls. For this reason, we created the Multi-datacenter services engagement for you to consult with an expert and plan out your Multi-datacenter deployment.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...