[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Disaster Recovery for Multi-Datacenter Apache Kafka Deployments
This post was originally published in 2017 and last updated March 2025.
In the age of the always-on digital business, unexpected downtime unexpected downtime unexpected downtime and data loss can result in businesses losing considerable revenue and damaging their reputation.
As enterprise companies move to the cloud to run their most critical workloads, the need for a business continuity or disaster recovery (DR) plan for data centers or cloud environments is critical. And if your business depends on Apache Kafka® to run mission-critical workloads or customer-facing applications, then you need a multi-region DR plan for your Kafka deployment.
Using Confluent Cloud features like Cluster Linking and Schema Linking, you can develop a disaster recovery plan for:
-
Multi-region deployments
-
Planning failover for regional outages
-
Procedures for region recovery post-outage
For the full details, we recommend reading the white paper, "Best Practices for Multi-Region Apache Kafka: Disaster Recovery in the Cloud."
Why Your Kafka Disaster Recovery Plan Should Be Multi-Region
A disaster recovery plan often requires multi-datacenter Kafka deployments where datacenters are geographically dispersed. If disaster strikes—catastrophic hardware failure, software failure, power outage, denial of service attack, or any other event that causes one datacenter to completely fail—Kafka continues running in another datacenter until service is restored.
To achieve high availability and resiliency across multiple cloud regions, you must run a Kafka cluster in each region and failover when disaster strikes. There are several patterns for how multi-region clusters can work together before, during, and after failure. The right pattern for a particular use case depends on the expectations for the recovery time and behavior of client applications.
Confluent Cloud offers several cloud-native features to create a cohesive, unified architecture that spans multiple clusters in multiple regions or clouds. Cluster Linking and Schema Linking in Confluent Cloud make building multi-region, multi-cloud, and hybrid cloud deployments easy by creating a fully managed, real-time replication pipeline between a source and a destination.
Architecture Designs for Multi-Datacenter Disaster Recovery
The details of your design will vary depending on your business requirements. You may be considering an active-passive design (one-way data replication between Kafka clusters), active-active design (two-way data replication between Kafka clusters), client applications that read from just their local cluster or both local and remote clusters, service discovery mechanisms to enable automated failovers, geo-locality offerings, etc.
Here is a Confluent multi-datacenter reference architecture:
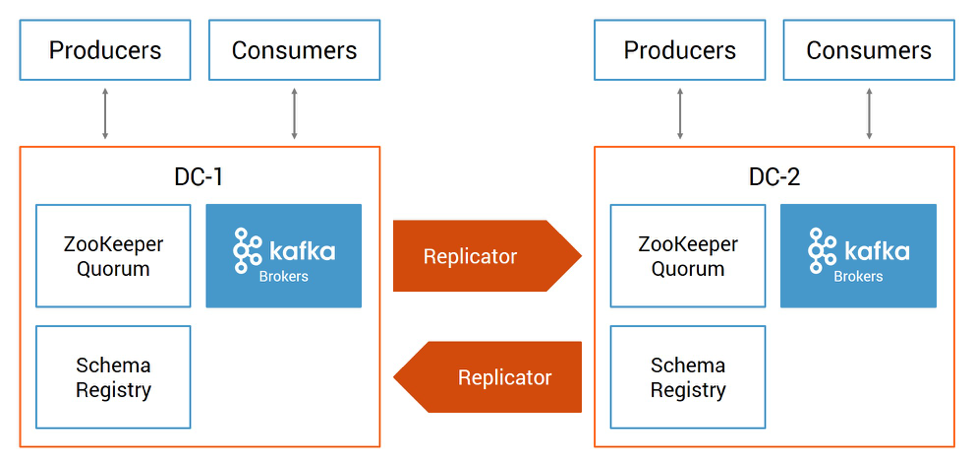
Confluent Replicator is the key to any of these multi-datacenter designs. It manages multiple Kafka deployments and provides a centralized configuration of cross-datacenter replication. It reads data from the origin cluster and writes that data to the destination cluster. As topic metadata or partition count changes in the origin cluster, it replicates the changes in the destination cluster. New topics are automatically detected and replicated to the destination cluster.
Multi-datacenter designs should include the following building blocks:
-
Data replication
-
Timestamp preservation
-
Preventing cyclic repetition of topics
-
Resetting consumer offsets
-
Centralized schema management
Confluent’s disaster recovery white paper is a practical guide for configuring multiple Kafka clusters so that if a disaster scenario strikes, you have a working plan for failover, failback, and ultimately successful recovery. Download the white paper to follow recommendations that will strengthen your disaster recovery plan.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...