[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Dawn of Kafka DevOps: Managing Kafka Clusters at Scale with Confluent Control Center
When managing Apache Kafka® clusters at scale, tasks that are simple on small clusters turn into significant burdens. To be fair, a lot of things turn into significant burdens at scale, and it’s Confluent Control Center’s job to ease as many of them as possible. In Confluent Platform 5.2, Control Center has grown a couple of new features that make large deployments a little more pleasant to manage: It has become much better at managing configuration changes among a large number of brokers, and it scales to a larger number of managed partitions. Let us explain these two in a bit of detail.
Dynamic broker configuration
Two challenges present themselves when configuring a large number of brokers: visualizing the differences in broker configuration and modifying them without resorting to rolling restarts everywhere. These are problems endemic to any distributed system that uses a large number of the same node type, and they become more costly as the number of nodes grows. Confluent Platform 5.2 makes solving both of these problems a bit easier.
In previous versions of Control Center, you could view and download broker configurations, which was good as far as it went. If you wanted to compare broker configurations (hardly an unusual thing to do when trying to troubleshoot a misbehaving cluster), you were left to do the diffing on your own. As of 5.2, you can now directly view the differences in configurations from within Control Center.
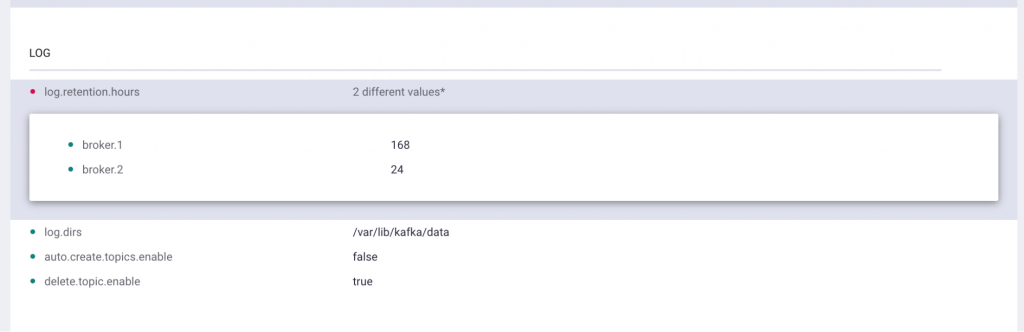
Relatedly, KIP-226 enabled dynamic broker reconfiguration since Apache Kafka 1.1. Put this together with the configuration view, and you now have a powerful way to get misconfigured brokers whipped into shape. Not only can you view their configurations side by side, but you can also make changes to parameters as needed without having to restart the brokers, which is an enormous time savings no matter how you manage your deployment. Of course, not every broker configuration parameter can be changed dynamically. See the documentation (or, if you please, the Apache Kafka wiki) for a complete list of which parameters this applies to.
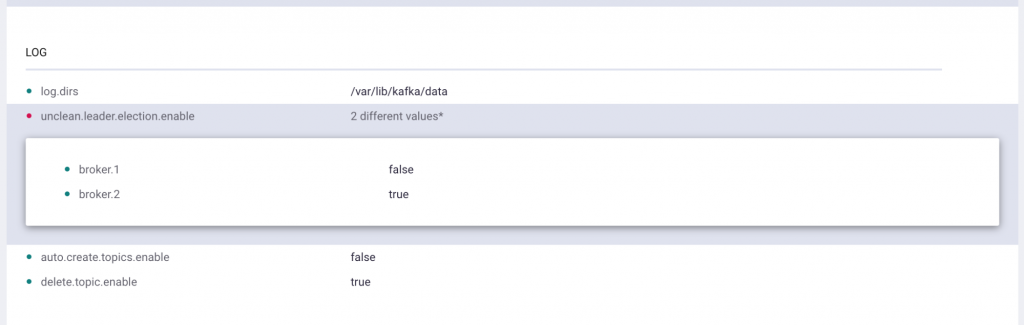
Dynamic broker configuration is enabled by default. To disable, set confluent.controlcenter.broker.config.edit.enable=false in the control-center.properties. And remember, you can always consult the documentation for more information.
Improved scalability
Control Center gives you visibility into the behavior of each topic that it manages, which means it has to keep track of the state of each partition in each topic. (No, this is not a terribly surprising claim of software architecture, but work with me here.) This, in turn, implies that Control Center has its own upper bounds on how large a deployment it can manage. Just how many topics Control Center can handle turns out to be somewhat of a complicated question, depending on replication factor and the distribution of topic partition counts. A cluster may have many topics with a small number of partitions, a small number of topics with many partitions or something in between; and a cluster may have a large replication factor or a small one.
Those statistical variations notwithstanding, Control Center has leveled up significantly in Confluent Platform 5.2. It can now comfortably handle around 120,000 individual partition replicas. Assuming a very typical replication factor of three, this means it can now manage around 40,000 individual partitions. If you take a typical topic partition count of six, this translates to a cluster of about 6,700 topics—which, you might be thinking, is a lot. Most users of Control Center don’t manage deployments that large; in fact, our data tells us that this covers more than 90% of existing customer workloads.
Operating large systems is always a lot of work, and Confluent Platform is singularly focused on making it easier for you. Confluent Platform 5.2 has moved the ball forward in two areas: Control Center’s ability to manage larger clusters, and its ability to help you more easily compare broker configurations and dynamically change them. If you’re running a big cluster, these features will make life that much more pleasant for you.
If you’re still not using Control Center or other parts of the Confluent Platform, you know what to do! Go here, download and check it out.
Other articles in this series:
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...