[Live Demo] Tableflow, Freight Clusters, Flink AI Features | Register Now
Announcing the MongoDB Atlas Sink and Source Connectors in Confluent Cloud
We are excited to announce the preview release of the fully managed MongoDB Atlas source and sink connectors in Confluent Cloud, our fully managed event streaming service based on Apache Kafka®. Our managed MongoDB Atlas source/sink connectors eliminate the need for customers to manage their own Kafka Connect cluster reducing customers’ operational burden when connecting across the best-of-breed open source technologies in all major cloud providers, including Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). MongoDB customers not yet using Atlas can continue to manage their own Kafka Connect cluster and run a MongoDB source/sink connector to connect MongoDB to Kafka.
“Kafka and MongoDB make up the heart of many modern data architectures today. We are excited to work with the Confluent team to make the MongoDB connectors available in Confluent Cloud. These managed connectors make it easy for users to connect Kafka with MongoDB Atlas when processing real-time event streaming data,” said Jeff Sposetti, VP of product management for analytics & tools at MongoDB.
Before we dive into the MongoDB Atlas source and sink, let’s recap what MongoDB Atlas is and does.
What is MongoDB Atlas?
MongoDB Atlas is a global cloud database service for modern applications and is available as part of the MongoDB cloud platform. Atlas is a fully managed service that handles the complexity of deploying, managing, and scaling your deployments across AWS, Azure, or GCP. Atlas provides best-in-class compliance to meet the most demanding data security and privacy standards.
Getting started with Confluent Cloud and MongoDB Atlas
To get started, you will need access to a Kafka cluster (that you get from Confluent Cloud) as well as a MongoDB Atlas database. The easiest and fastest way to spin up a MongoDB database is to use MongoDB Atlas. No more fumbling around with provisioning servers, writing config files, and deploying replica sets—simply pick a cloud provider, a cluster size, and get a connection string!
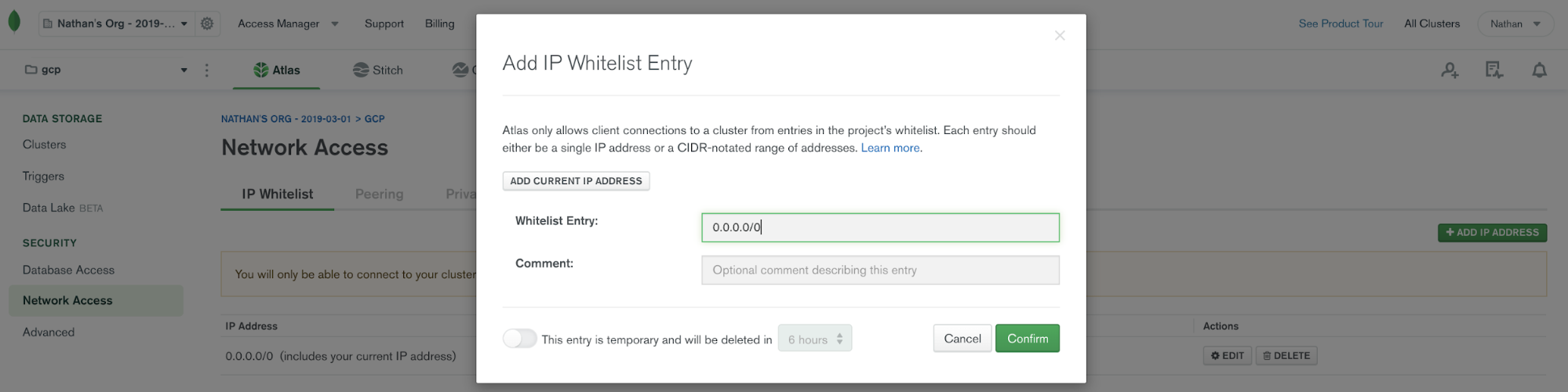
Once you have your MongoDB Atlas database, you’ll need to configure it to allow network access from Confluent.
By default, MongoDB Atlas does not allow any external network connections, such as those from the internet. To allow external connections, you can add a specific IP or a CIDR IP range using the “IP Whitelist” entry dialog under the “Network Access” menu. In order for Confluent Cloud to connect to Atlas, you need to specify the public IP address of your Confluent Cloud cluster. Note: At the time of this writing, Confluent Cloud provides an IP address dynamically and due to this variability, you will have to add 0.0.0.0/0 as the whitelist entry to your MongoDB Atlas cluster. To learn more about this requirement, check out the documentation.
With network access in place, we’ll walk through configuring the MongoDB Atlas source and sink followed by two scenarios.
- First, we will show MongoDB used as a source to Kafka, where data flows from a MongoDB Atlas collection to a Kafka topic
- Next, we will show MongoDB Atlas used as a sink, where data flows from the Kafka topic to MongoDB
Note: When using the MongoDB Atlas Source Connector, Confluent Cloud can fetch records from MongoDB Atlas regardless of your cloud provider or region. However, when using the MongoDB Atlas Sink Connector, your Atlas database must be located in the same region as the cloud provider for your Kafka cluster in Confluent Cloud. This prevents you from incurring data movement charges between cloud regions. In this blog post, the MongoDB Atlas database is running on GCP us-central1 and the Kafka cluster is running in the same region.
Using the MongoDB Atlas source
Consider the use case of launching a food delivery service in a new region with the restaurant data stored in MongoDB Atlas. We plan to target restaurants that have a high rating first. To test out our scenario, we will use the sample restaurants dataset MongoDB provides, and we can simply load this dataset to a MongoDB Atlas database.
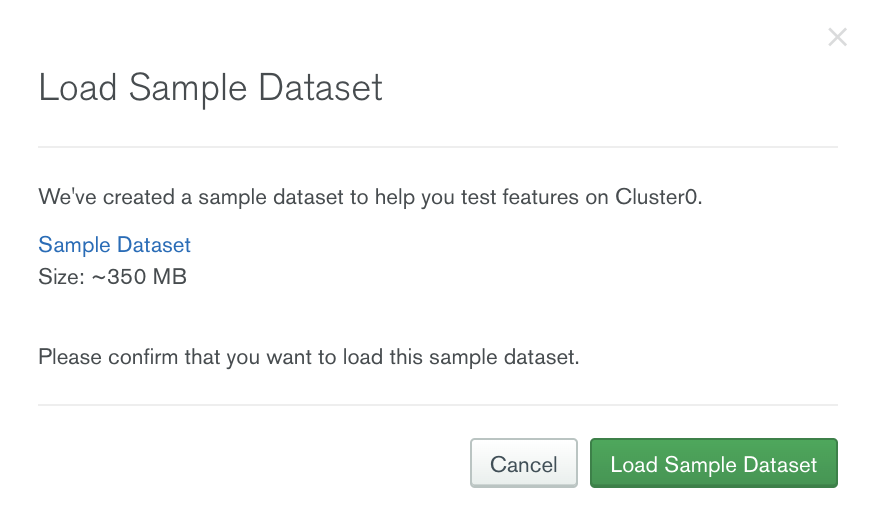
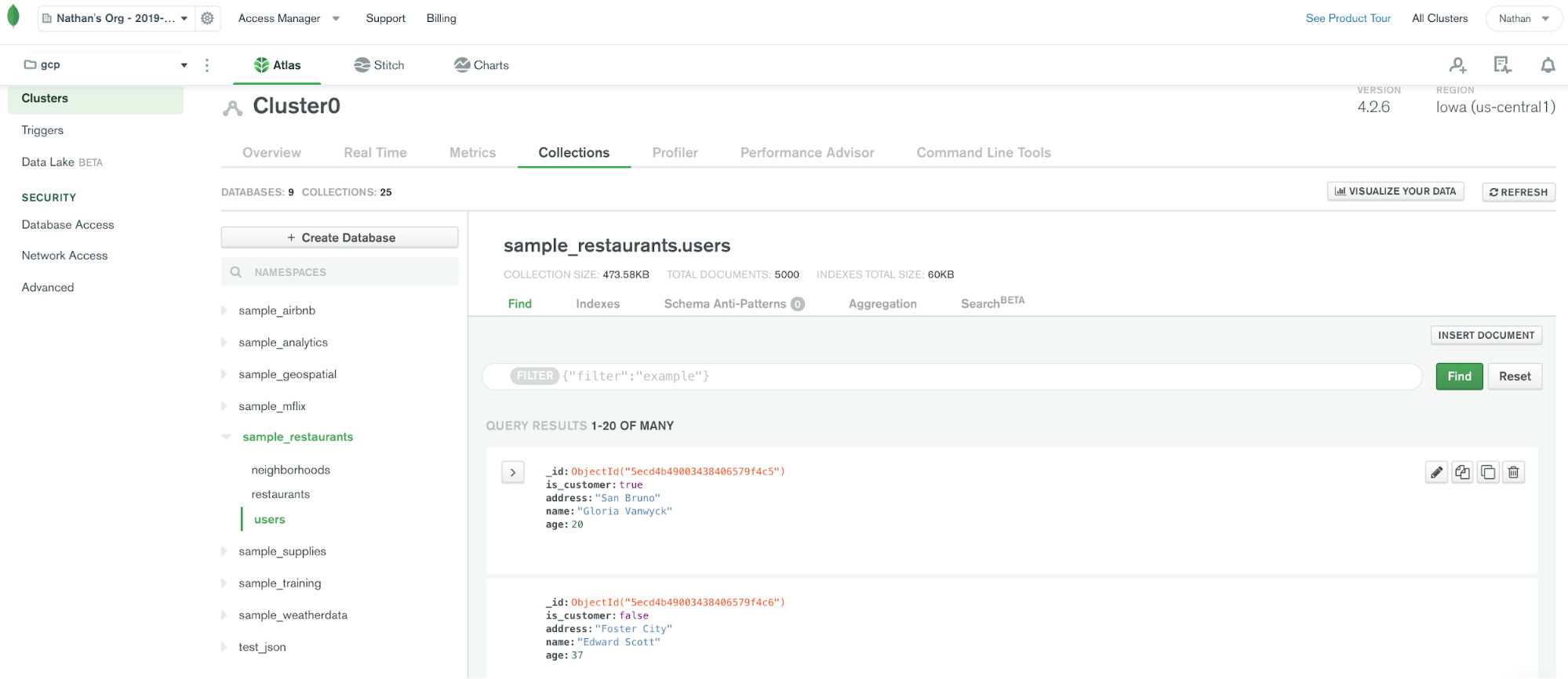
Once the sample dataset is loaded, we will be able to see a collection called restaurants.
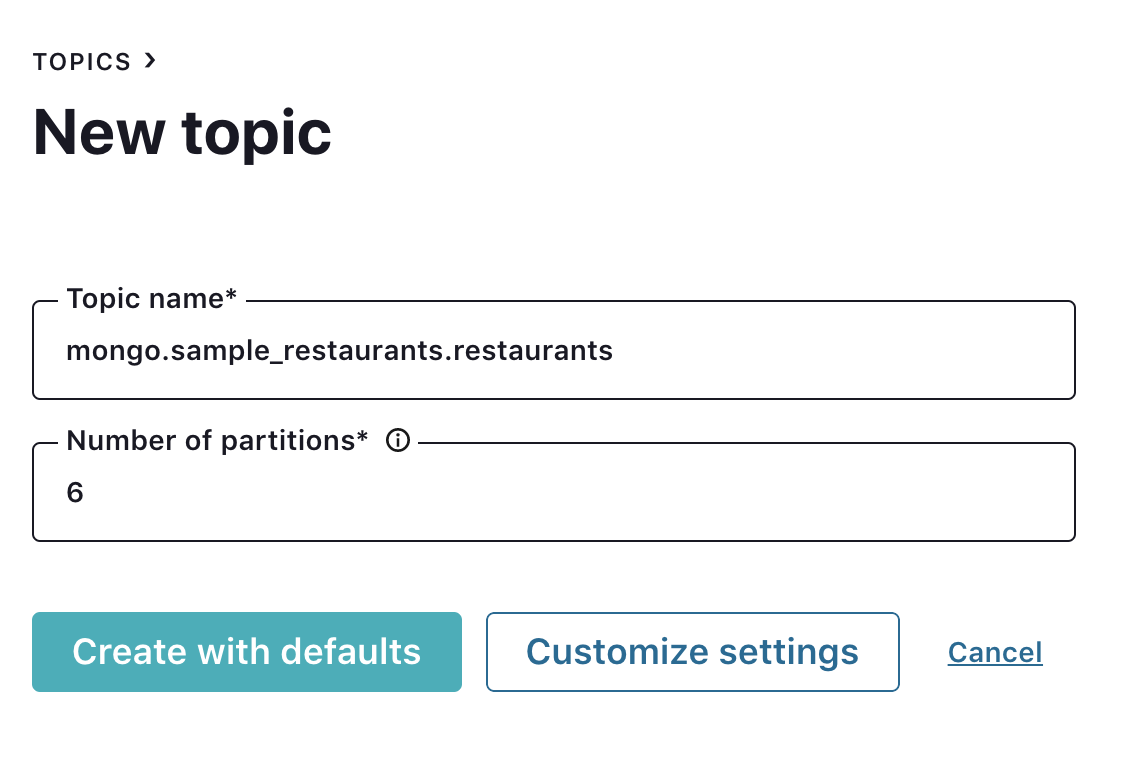
Since auto.create.topics.enable is disabled in Confluent Cloud, we need to create a topic first. Create the topic mongo.sample_restaurants.restaurants, which follows <prefix>.<database>.<collection>.
Click the MongoDB Atlas Source Connector icon under the “Connectors” menu, and fill out the configuration properties with MongoDB Atlas. Note that the connector exposes a subset of the options available on the self-hosted MongoDB Connector for Apache Kafka. Over time, more options, such as being able to specify an aggregation pipeline parameter, will be exposed. Check out the MongoDB Atlas connector documentation for the latest information on supported connector properties.
In this example, let’s choose copy.existing.data=true. This parameter will fetch all existing records from the restaurant collection.
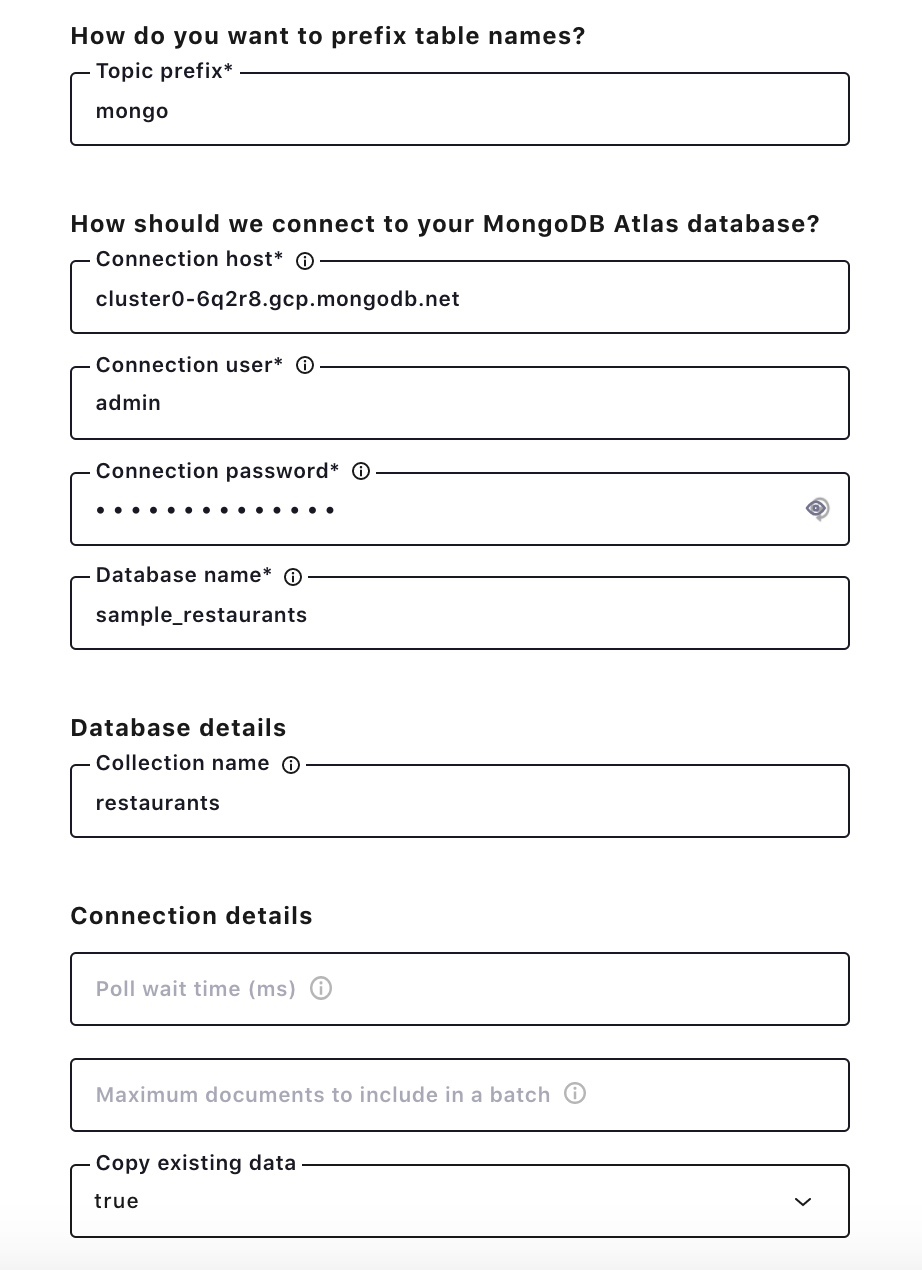
Once the connector is up and running, use a message browser to see restaurant records. By putting 0 / Partition: 0, records similar to the image below will show up for the mongo.sample_restaurants.restaurants topic. With restaurant records in a Kafka topic, we can leverage ksqlDB to calculate the average rating for each restaurant and to focus on ones above a certain threshold.
Using the MongoDB Atlas sink
Continuing the food delivery scenario, when a new user is created on the website, multiple business systems want their contact information. Contact information is placed in the Kafka topic users for shared use, and we then configure MongoDB as a sink to the Kafka topic. This allows a new user’s information to propagate to a users collection in MongoDB Atlas.
To do this, first create the topic users for a Kafka cluster running in Confluent Cloud (GCP us-central1).
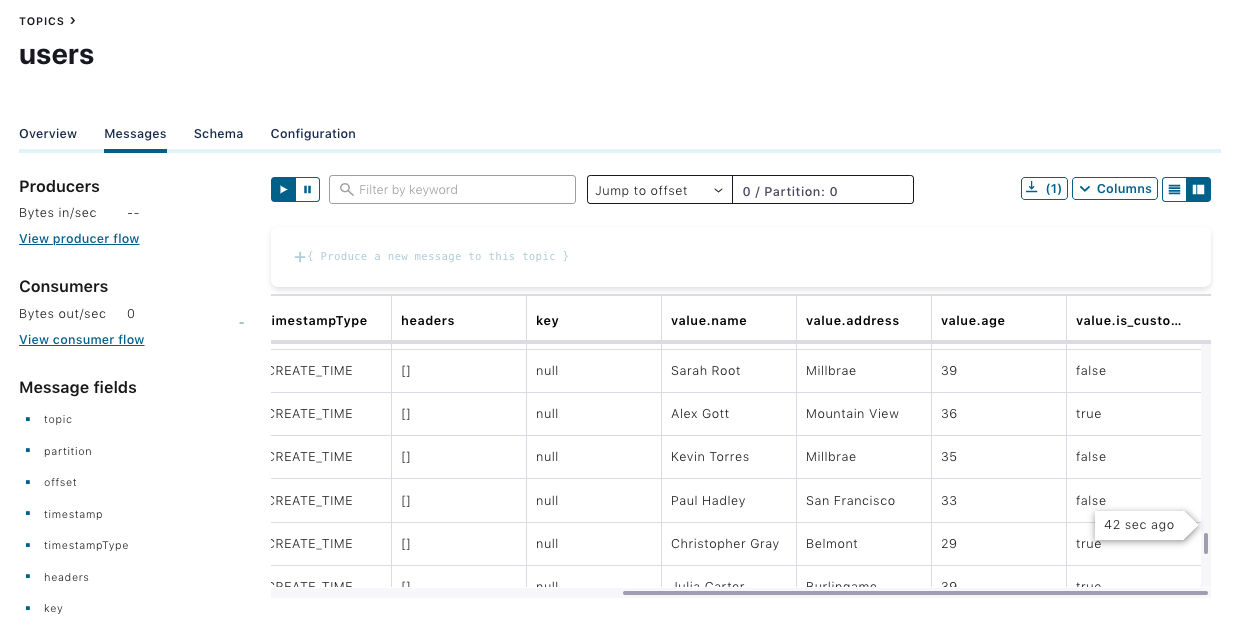
Use this Python script to populate sample records to the users topic, and check whether the records are available in the users topic.
Click the MongoDB Atlas Sink Connector icon under the “Connectors” menu, and fill out configuration properties with MongoDB Atlas. Make sure JSON is selected as the input message format and leave the collection name field bank. The connector will use the users topic as a collection name.
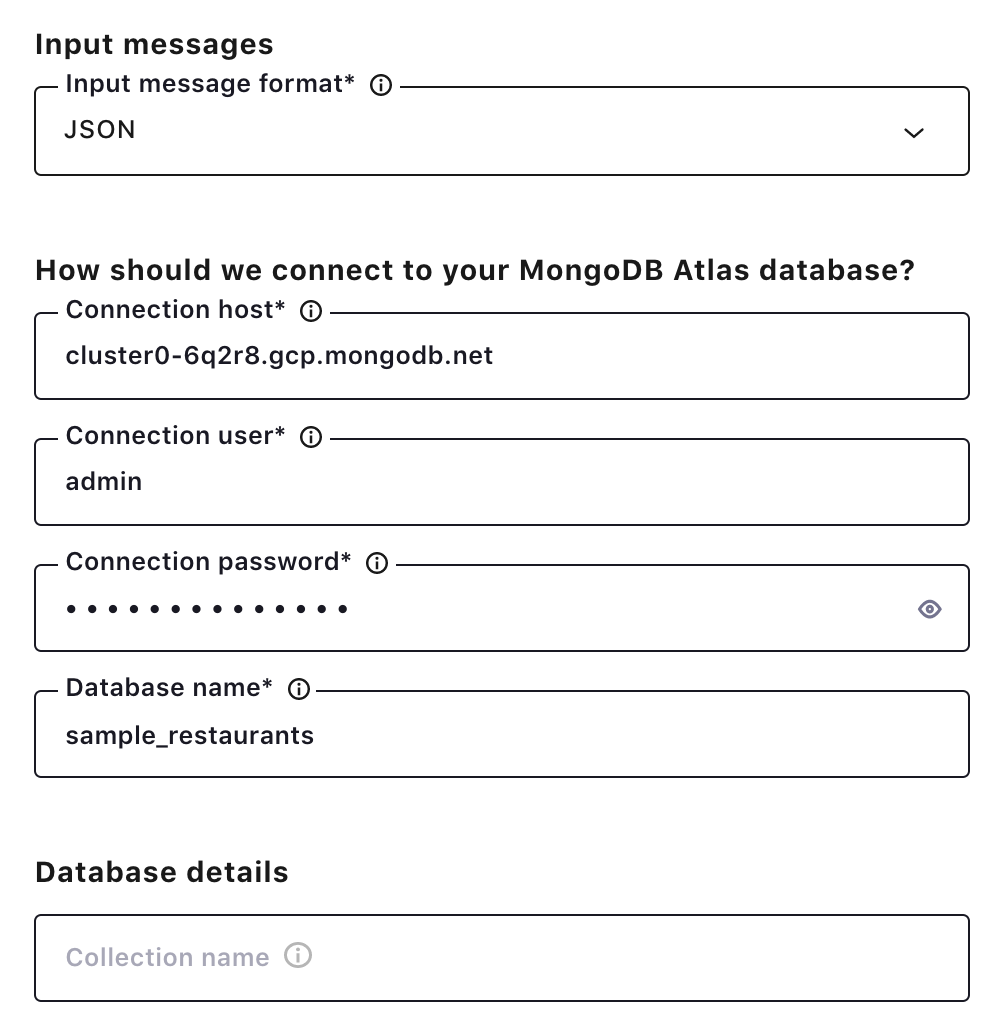
Once the connector is up and running, records for the user collections will show up in the MongoDB Atlas database.
Learn more
To learn more, check out this joint session between Confluent and MongoDB from MongoDB.live.
If you haven’t tried it yet, check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka, available on Microsoft Azure and GCP Marketplaces with MongoDB Atlas source and sink and other fully managed connectors. You can enjoy retrieving data from your data sources to Confluent Cloud and send Kafka records to your destinations without any operational burdens.
You can also check out the Confluent and MongoDB Reference Architecture for more information.
Further reading
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...