[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
The Cloud-Native Evolution of Apache Kafka on Kubernetes
It’s almost KubeCon! Let’s talk about the state of cloud-native Apache Kafka® and other distributed systems on Kubernetes.
Over the last decade, our industry has seen the rise of container technologies, and importantly, the rise of Docker as a standard, language-agnostic format for packaging, distributing, and executing containerized applications. This has paved the way for container orchestration systems like Kubernetes, Docker Swarm, Apache Mesos and Marathon, HashiCorp Nomad, and Diego (Cloud Foundry). These orchestration systems have offered a powerful new way to manage and run software at scale, and they’ve been able to gain traction by building atop the standardization of containers.
The container orchestration space has standardized too, and that standard is Kubernetes. The evidence is found in observing the directions that companies and projects such as Mirantis (who acquired Docker Enterprise), D2iQ (formerly Mesosphere), the Cloud Foundry project, Red Hat, and Pivotal (now VMware Tanzu) have gone. Kubernetes is the only container orchestration solution offered as a managed service by all of AWS, Azure, Google Cloud, Alibaba Cloud, IBM, and other major cloud providers. The companies behind some of the most popular software products such as Kafka, Redis, MongoDB, Elasticsearch, and Cassandra all include both a fully managed cloud offering and a distribution of their software targeting Kubernetes-based installs as key parts of their portfolios.
This is a really special point that we’ve reached because it means we’re poised to solve some of the biggest challenges we’ve faced in an industry-wide way. This blog post discusses:
- Why some of the most interesting and powerful software is difficult to manage
- A world where you don’t have to deal with most of this difficulty when it comes to Kafka and the event streaming platform
- How Kubernetes and the Confluent Operator are part of an industry-wide movement building on Kubernetes and the Operator pattern
Distributed systems and the cloud native paradigm
Distributed systems are hard. Any system designed to allow clients to write data and read data written to the system will have to incorporate important trade-offs in its design. This isn’t just a temporary problem, where we as an industry haven’t yet figured out how to build the ideal system for managing data.
The CAP theorem implies there are provable limits to how good a data system can be, particularly as it pertains to its availability and consistent presentation of data in the face of blips and delays in the network. In addition, the efficient use of memory, CPU, network bandwidth, disk IO, and other factors play into the trade-offs of designing distributed systems. Performance characteristics like latency and throughput factor in too. The best systems are thoughtfully designed and implemented to reflect the priorities and trade-offs of the use cases or architectural paradigms they’re aiming to support. Apache Kafka is the best platform for event streaming, but you’re probably using something else for a use case like service discovery and DNS.
What we see today is a rich ecosystem of powerful, unique data systems that address a wide variety of technical use cases. While it’s an exciting time to be part of this great ecosystem, there is a downside as well.
If your organization has a large, complex tech stack employing a variety of these distributed data systems, and your job is to operate them all, you’ve got a lot of work cut out for yourself. Configuring and running a system on Day 1 may not be that hard, but scaling processes horizontally, scaling compute and storage vertically, restarting clusters, patching machines, upgrading software, reconfiguring, backing up, restoring, and any other Day 2 operations can be hard.
In particular, the right way to do these operations tend to be unique to each data system you work with. They all have different edge cases, special procedures, and operational tool chains. To actually get the value from these systems in the way that they are designed to provide, you end up needing to become an expert in all these ancillary areas that aren’t central to why you’re using these technologies in the first place.
There is a better way. At Confluent, we think everyone can experience and leverage the value Apache Kafka was designed to provide without needing to become an expert in performing complex sequences of low-level operations. We think you should care about what you want rather than how to get it and that machines can be programmed to deal with the how. This concept is the core of what it means to be cloud native. The Cloud Native Computing Foundation (CNCF) has their definition, and you can watch Confluent Co-Founder and CEO Jay Kreps expound on what cloud native means for data systems in his Kafka Summit keynote. But the central idea that these definitions all share is that you, as a user, should focus on what needs to be true of a system to realize the greatest value from it. If it’s truly cloud native, then the system will intelligently and automatically figure out how to fulfill its purpose, so that you don’t have to.

To make this more concrete, let’s look at a few of the attributes of a cloud-native system and what they mean for Kafka:
- You want your Kafka clusters to be reliable and healthy. You don’t want to worry about how to heal it when some unforeseen infrastructure failure happens. A cloud-native platform will intelligently detect if a process fails and will automatically restart processes or reschedule onto a new machine, reattach disk if necessary, and determine when the new process is ready to begin accepting connections.
- You want your Kafka clusters to be elastic—able to scale up or down in a single click, single command, or single API call according to demand. You don’t worry about how to actually grow or shrink your cluster. A cloud-native platform will automatically generate configuration, schedule and run new broker processes, and ensure data is balanced across Kafka brokers so that the cluster can be efficiently utilized. The platform will automatically perform the necessary steps when going in the reverse direction, shrinking a cluster.
- You want your Kafka clusters to be secure, conforming to common principles of secure systems—all data in flight is encrypted, all data at rest is encrypted, and processes execute with the least privileges necessary to successfully function. You don’t have to worry about how to accomplish all these things. A cloud-native platform will encrypt all data by default, manage keys and credentials, and configure components, ensuring secure network communications automatically and by default.
Cloud-native event streaming with Confluent Cloud and Confluent Operator
At Confluent, we’re excited about bringing the event streaming paradigm and the cloud-native data system paradigm together. That’s why we started talking about with Project Metamorphosis, back in May of 2020. That’s also why we’re excited to sponsor KubeCon + CloudNativeCon North America this year.
Two ways we’re bringing these paradigms together are through fully managed Apache Kafka as a service with Confluent Cloud and Confluent Operator for Kubernetes, which gives you a cloud-native experience for self-hosted Confluent Platform.
With Confluent Cloud, you can experience what it’s like to get the complete event streaming platform on demand, including Kafka clusters but also ksqlDB applications, Confluent Schema Registry, and managed connectors. Zero effort is spent dealing with how servers are created, configured, restarted, or upgraded.
For use cases that can’t use a fully managed service today, the principles of cloud-native software still apply. So, while our software can’t plug an unplugged power cord in your datacenter back in, there’s a lot that we can automate in code to deliver a cloud-native experience for self-hosting users. That’s where the Confluent Operator for Kubernetes comes in, letting you focus more on defining what shape the platform should take to serve your use case and less on how to get there.
To see the power of a truly cloud-native platform with Confluent Operator and Kubernetes, check out the demo below. It shows how easy it can be to solve a common developer problem: replicating an issue impacting your production environment in an ephemeral test environment with nearly identical configuration and data as your production environment, fixing the issue, and then promoting the fix to production.
Confluent Operator: Intelligent automation to make cloud-native event streaming easy
Built to power Confluent Cloud, Confluent Operator for Kubernetes was released in early 2019. As Kubernetes continues its rapid growth, especially for stateful workloads, we’ve seen adoption of Confluent Operator grow as well. Knowing that Confluent Operator powers Confluent Cloud provides a level of confidence right out of the box for those who self-host Confluent Platform on their own Kubernetes clusters. However, there’s another, more fundamental reason why we’re seeing not only the Confluent Operator catch on for event streaming data systems but also the Operator pattern in general being applied to all data systems.
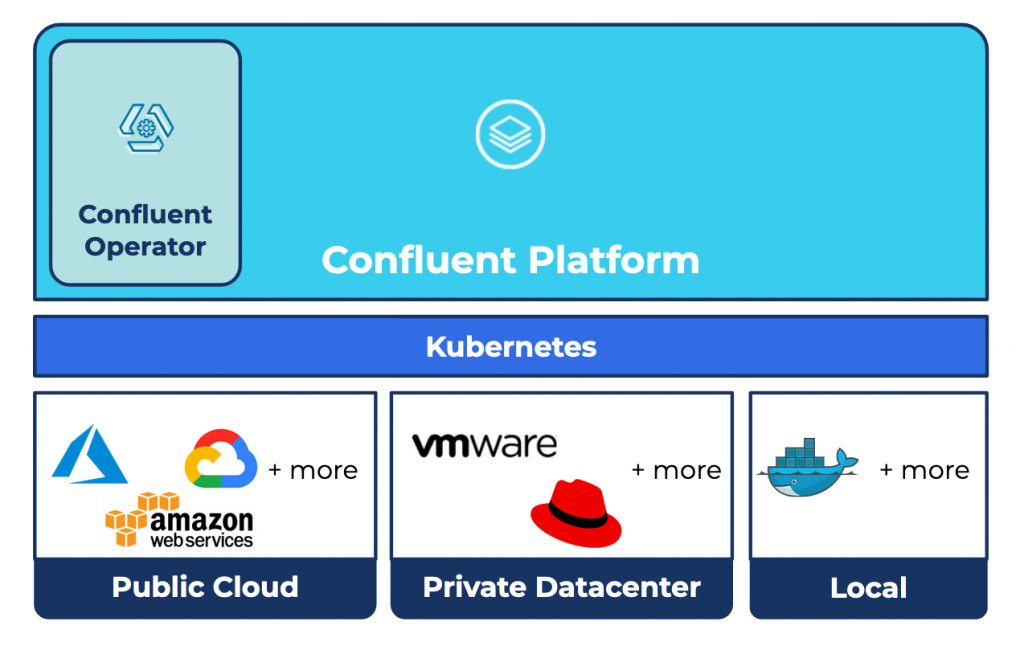
Let’s take a deeper look at what the Operator pattern is in the Kubernetes ecosystem and see why it has become an industry standard.
As mentioned before, distributed systems are hard. Each of these popular data systems tend to have a community behind them, maintaining and evolving the project. Each of these independent communities could build their own higher-level tooling to alleviate some of the operational burden. This approach would address one dimension of the operational complexity, but it doesn’t address the fact that each system is different. That means operators still need to learn and manage a bunch of different tools, and they need to worry about how to integrate with platform-level concerns such as logging, monitoring, and credential management in a different way for each tool.
What if there were a way for these communities to deliver a cloud-native experience for their data systems in a way that didn’t require them to each solve some common problems in slightly different ways, but instead provided a consistent management experience across the board? What would that sweet spot look like? It would look like a runtime for distributed workloads and a framework for defining how to orchestrate specific data systems on this runtime, with the following attributes:
- The runtime should be popular, so that the communities who build data systems know that if they build a distribution of their project targeting the runtime, then it will be usable by a large set of potential users
- The runtime should be powerful enough to handle a lot of the generic business logic of managing compute, network, storage resource, and process scheduling and management so that the data system communities don’t need to reinvent solutions to this generic problem
- The framework should be flexible enough for the data system communities to leverage the power of the runtime while also being able to execute their own, potentially arbitrarily complex business logic that’s specific to how their distributed system needs to be managed
- The framework should result in a consistent interface such that the tooling and UX is consistent even though the business logic under the hood for managing the different data systems can be idiosyncratic
With Kubernetes as the runtime and the Operator pattern as the framework, we have a solution to the above as an industry. Kubernetes provides a RESTful API for resource objects like Pods, Services, PersistentVolumes, and StatefulSets. When you perform a CRUD operation on one of these resources, Kubernetes API controllers receive a change data event and can react accordingly. This results in the desired containers running on Kubernetes worker nodes with the required storage and networking resources provisioned through the infrastructure and assigned as needed to those containers.
Using an Operator, really just means doing two things:
- Extending the API with new CustomResourceDefinitions (CRDs), which are different from the built-in resource definitions for things like Pod and StatefulSet.
- Adding a custom controller that implements special business logic when you perform a CRUD operation on the new resource. Usually, these custom controllers translate high-level intent from a custom resource specification into specifications for built-in Kubernetes resources.
For example, with the Confluent Operator, your Kubernetes cluster is enriched with a new high-level API resource called a KafkaCluster. When the Operator sees a new one of these being created, it translates it into various Service and StatefulSet objects. If you later update your KafkaCluster, the Operator updates the underlying Service and StatefulSet objects in a way that encapsulates Confluent’s deep knowledge of operating Kafka in production. Kubernetes’ built-in controllers for handling Services and StatefulSets take over from there, orchestrating load balancers, containers, persistent disks, and so on. There’s a lot going on here, but as a user, all you have to do to initiate the update is perhaps change a version number in your KafkaCluster specification. You can use the same tools you would use to manage any other workloads that you run on Kubernetes.
The Operator pattern on Kubernetes is the state of the art for our industry because of how well this approach satisfies the four attributes mentioned above. This is why you see companies like Confluent, Elastic, MongoDB, Redis Labs, DataStax, and so on all providing Operators. None of these companies need to reinvent container schedulers. You get to choose among Kubernetes distributions and vendors; a Kubernetes cluster is usually just a click away on any of the major cloud providers. Furthermore, whether you’re using a Redis Operator or a Kafka Operator, and whether your Kubernetes clusters are on prem or in your own public cloud accounts, your management workflow consistently centers around the same, simple command: kubectl apply.
As we continue to evolve Confluent Operator, you can expect an increasingly cloud-native experience, automating away more and more of the operational toil of managing an event streaming platform, as well as an increasingly Kubernetes-native experience, providing you with a greater ability to leverage the power of Kubernetes and integrating better with the rich Kubernetes ecosystem.
Join us at KubeCon!
Confluent Cloud and Confluent Operator define a new future for how the world can accelerate the value achieved with Kafka. We hope you’re as excited as we are about the future of cloud-native data systems and the journey we’re on as the event streaming and cloud-native paradigms evolve closer together.
If you’d like to discuss these topics further, we’d love to hear from you. Come join us at KubeCon North America!
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...