[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
ksqlDB Execution Plans: Move Fast But Don’t Break Things
The ksqlDB Engineering Team has been hard at work preparing ksqlDB for production availability in Confluent Cloud. This is the first in a series of posts that deep dives into the key improvements. For part 2 and 3, check out Consistent Metastore Recovery for ksqlDB using Apache Kafka® Transactions and Measuring and Monitoring a Stream Processing Cloud Service: Inside Confluent Cloud ksqlDB.
This post assumes some familiarity with ksqlDB and Kafka Streams. Specifically, it assumes you’re familiar with ksqlDB’s deployment model, the relationship between ksqlDB and Kafka Streams, and some basics about the Kafka Streams runtime. If you need some background, check out the linked blog posts and documentation:
Motivation
Our engineering team constantly delivers new functionality to ksqlDB. The easiest and fastest way for you to access these bleeding-edge features is to run ksqlDB in Confluent Cloud. At the same time, once you’ve got your ksqlDB queries up and running, it’s up to us to make sure that your deployment continues to function correctly as we upgrade it to the latest versions.
This is particularly challenging in the presence of persistent queries, which maintain their own internal state in repartition topics and changelogs. To illustrate the pitfalls, we’ll use the following optimization as a running example:
CREATE STREAM PAGEVIEWS (
PAGEID STRING,
USERID BIGINT
) WITH (KEY=’PAGEID’, VALUE_FORMAT=’JSON’, KAFKA_TOPIC=’PAGEVIEWS’);
CREATE TABLE COUNTS AS SELECT
PAGEID,
COUNT(*)
FROM PAGEVIEWS
GROUP BY PAGEID
EMIT CHANGES;
A naive execution of this query would re-partition the source stream to ensure that all records with a given PAGEID are counted by the same node:
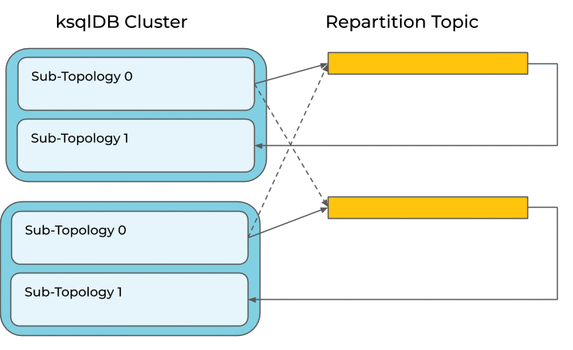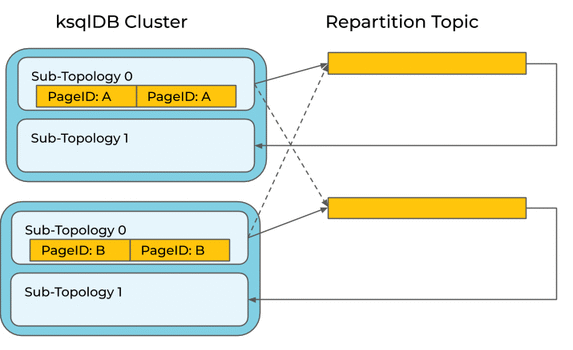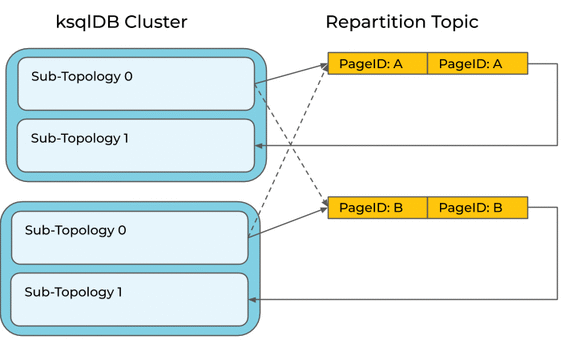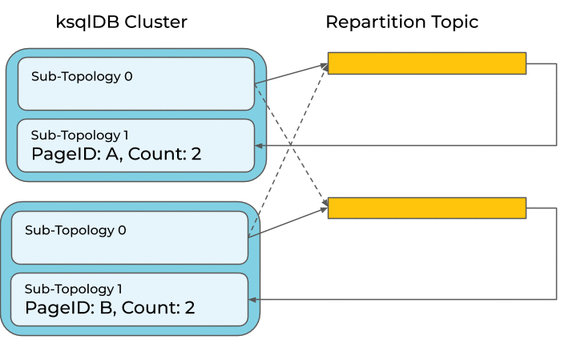
It would be smarter to leverage our knowledge that the source stream is already partitioned by PAGEID (we know this because the PAGEVIEWS DDL gives ksqlDB this hint). This means the query engine can optimize away this re-partition (in fact, we already do this, but this is a nice example that illustrates the problem).
But it’s not that simple. Consider an upgrade of a ksqlDB cluster to a new version that includes this optimization. If ksqlDB were to blindly apply the optimization to a running query, it might leave records behind in the repartition topic and compute the wrong count:
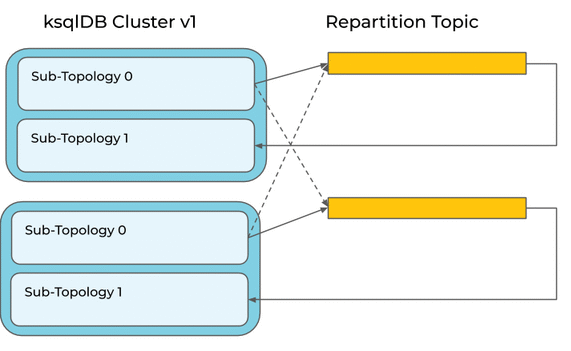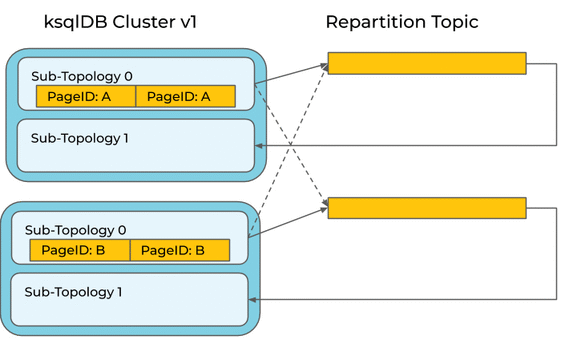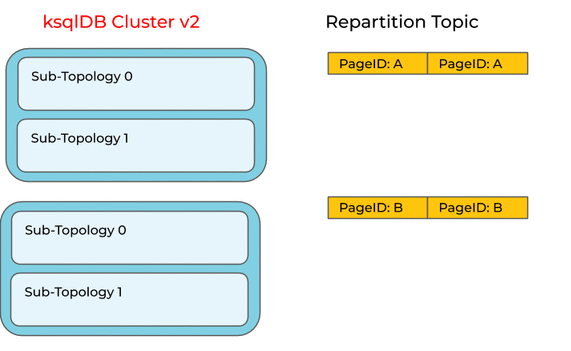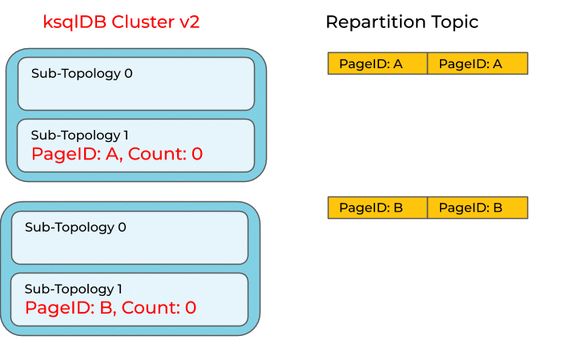
It would be better to keep the repartition for running queries, and only apply the optimization to new queries.
There are many features and optimizations in the pipeline with similar compatibility concerns: filter push-downs, switching to a more succinct data format for internal state, using a structured key on GROUP BY, optimizing join-order, and even tweaks to the language semantics are just a few examples. For each of these changes, it would be preferable to continue executing old queries in the old, legacy way, and only apply the improvements to new queries until the old queries can be migrated (we’ll talk more about this later).
But how can ksqlDB remember the way that older versions executed a given query?
Compatibility
Before diving into how ksqlDB solves this today, let’s discuss how we think about query compatibility, and then take a look at our earlier solution to this problem.
What does it mean for a persistent query to be compatible with an older ksqlDB version? At minimum, the results it publishes to its output topic should be consistent with the last results published by the previous iteration of that query. The current iteration of the query needs to restore any state saved in changelog topics, and pick up any records left behind in repartition topics.
One way to achieve this is to ensure that we always produce the same Kafka Streams topology (the same DAG of Kafka Streams operators) for a given query.
Alternative solution: Read vs. write defaults
Older ksqlDB versions solved this problem by writing flags, called compatibility-breaking configs, to the command topic to toggle compatibility-breaking behavior. Each compatibility-breaking config specifies a read default and a write default. The write default determines the value written to the command topic. The read default determines the value read from the command topic (if no value was written). By setting the respective defaults, we can turn new behavior off for old versions.
Let’s see how we would apply read-write defaults to our example. We could define a compatibility-breaking config called ksql.aggregation.repartition.avoid, and set the read default and write default to false and true, respectively. Then, in our query engine, we would write code like the following:
if (config.getBoolean(“ksql.aggregation.repartition.avoid”)) {
stream.groupByKey();
} else {
stream.groupBy(...);
}
It’s obvious that over time, this leads to spaghetti code, with mysterious switches scattered throughout. It becomes hard to understand old code and reason about new changes. Every time you make a change, you have to think carefully about the internal compatibility implications.
It’s also error prone. We rely on ksqlDB’s Query Translation Tests (QTTs) to catch regressions by comparing Kafka Streams topologies. Each QTT test case specifies a ksqlDB statement, data for input topics, and expected data for output topics (under the hood, QTT leverages the same framework as the ksql-test-runner tool). On each release, we save the current compatibility-breaking configs and Streams topology description for each test case. We then verify that the current ksqlDB version produces the same topology given the old configs. This is helpful but insufficient. Streams topology descriptions lack important information about each operation that should be validated. For example, a projection node doesn’t detail the expressions projected into its output.
Furthermore, our test suite won’t cover every case. This approach also requires adding a new case for every query on every release, which becomes very expensive as we move to weekly releases. And finally, there are some breaking changes (e.g., grammar changes) we’d like to support where we could not practically take this approach.
Execution plans
Execution plans aim to solve our compatibility problems in a maintainable and testable way.
The basic idea is this: instead of building a Kafka Streams topology directly, build up an internal specification that defines how ksqlDB should build the topology for a given query. Then build the topology from the spec, rather than building it from the original ksqlDB text. Remember, under the hood, ksqlDB compiles queries down into a Kafka Streams topology. If we can ensure that we’re building up the same Kafka Streams topology every time, we can guarantee that the resulting topology is compatible.
This internal spec, which we call an execution plan, is a DAG of steps. Each step is defined by its type, a list of source steps, and a set of type-specific parameters.
A step’s type defines an operation to perform on a stream or table. Examples of types include StreamSelect (project a stream), StreamFilter (filter a stream), StreamGroupBy (re-group a stream), and StreamAggregate (aggregate a grouped stream). Parameters determine how to execute the operator. For example, StreamSelect has a single parameter: the list of expressions to project.
ksqlDB builds the final Kafka Streams topology from the execution plan by building the steps, starting with the root. The output of building each step is an intermediate stream or table. Each step is built by building its source steps to get input streams and/or tables, and then applying its operator (using the step’s parameters) to the inputs to produce the output stream/table. Some steps, like StreamTableJoin, have multiple source steps (one for the stream and another for the table). There’s also a special kind of step, called a source, which doesn’t have a source step—its job is to initialize a stream or table from a Kafka topic.
So we’ve established that ksqlDB builds up an execution plan and then builds the final Kafka Streams topology from that. But how does this solve our original problem? The key is that execution plans are JSON serializable. To execute a query, the ksqlDB server first builds the execution plan from the ksqlDB statement. Then, instead of writing the ksqlDB statement and configs to its internal log (command topic), it serializes and writes the execution plan. On the other end, the statement executor consuming this log builds the final Kafka Streams topology from the execution plan.
This effectively splits up ksqlDB into two layers. The “upper” layer includes the grammar (except expressions), parser, logical planner, and physical planner. It can be evolved freely without worrying about breaking running queries because of an upgrade.
The “lower” layer includes the step implementations and utilities like the expression and predicate evaluators; it needs to be kept compatible across versions. However, this layer is much easier to reason about: each step is very limited in scope and can be considered independently. As long as every step always produces the same result given the same inputs, the resulting topology will be compatible. If you need to change a step type in an incompatible way, you can just define a new step type.
Let’s use our running example to take a look at how all of this works in practice. Our example query will result in an execution plan that looks something like the following:
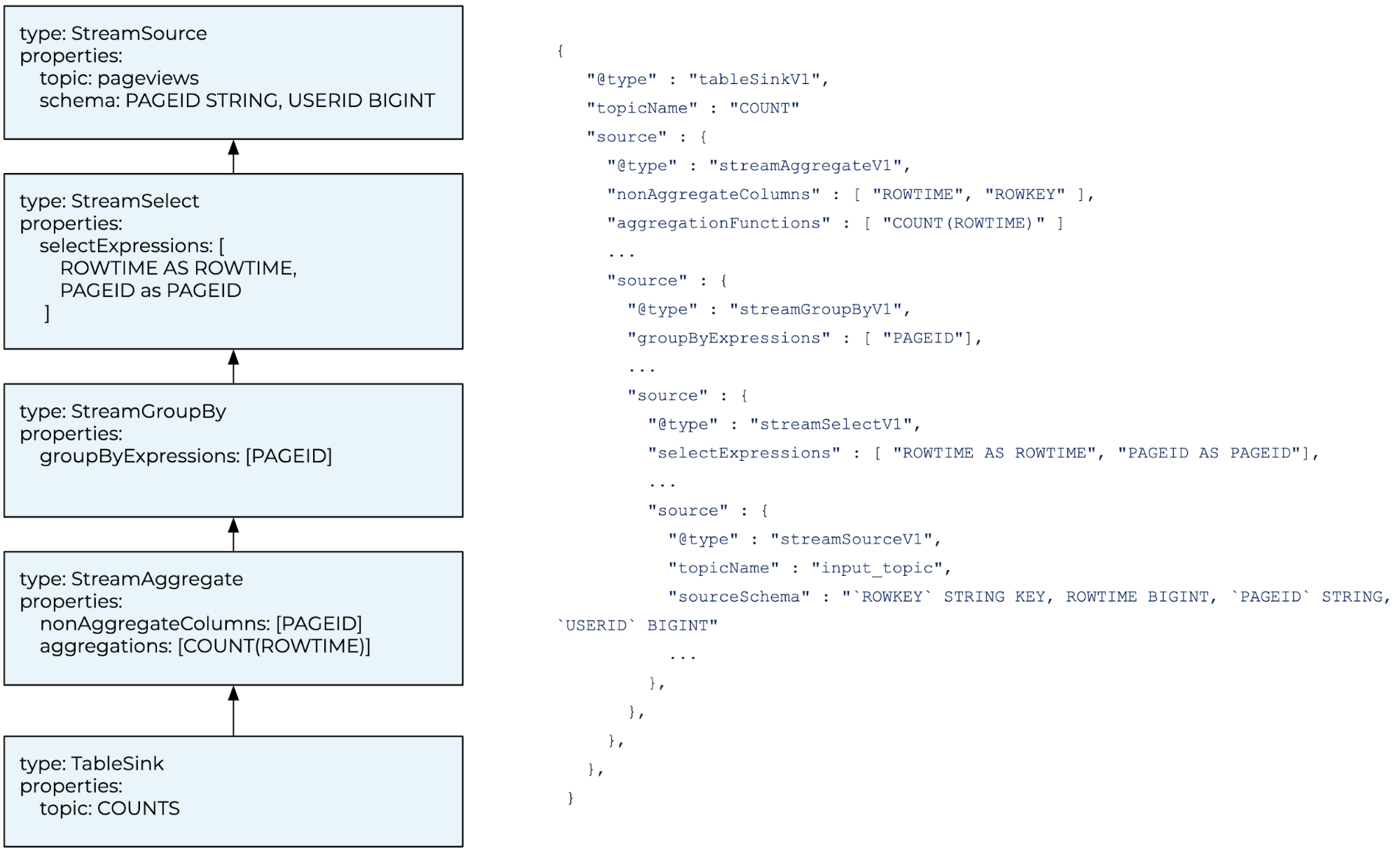
The ksqlDB server serializes this plan to JSON and writes it out to the command topic. On the other end, the cluster runs a single statement executor per ksqlDB node that consumes the command topic. Each statement executor consumes the serialized plan and builds the final Kafka Streams topology from it, as described above.
Now let’s look at how you would implement our example optimization. There’s actually nothing to do beyond using a StreamGroupByKey operator instead of a StreamGroupBy! When you ship the new code, ksqlDB builds the old query from its original plan and continues to generate the same topology. At the same time, any new queries that can leverage the optimization will have it applied. You’re freed from worrying about whether a change will break queries that are already running. You can more quickly develop the feature, and we can confidently ship it to Confluent Cloud when it’s ready.
Testing
Execution plans essentially define an internal API that decouples the building of the Kafka Streams topology from the ksqlDB engine. This, of course, comes at a cost—we need to make sure that we don’t break this internal API. We do this using two types of tests (in addition to the usual unit testing of step type implementations and utilities).
Schema verification
The first type of test generates a JSON Schema for execution plans and validates that it’s kept compatible. The current schema is checked into the ksqlDB codebase. On every build, we generate the schema and validate that it’s compatible with the last saved schema. If the schema has changed in a compatible way, we update it. To validate compatibility, we currently just check that the schemas are equal. There is planned work to update this check to leverage the new JSON Schema support in Confluent Schema Registry, which includes a validator for backward compatibility.
Input/output verification
The second type of test builds on the QTT suite. Each QTT test case specifies a ksqlDB statement, a set of Kafka topics, input data for those topics, and expected outputs. To test execution plans, we’ve extended the QTT suite with the following tests:
- PlannedTests: for each QTT case, we generate and commit a planned test case. A planned test case includes the Execution Plan generated by ksqlDB, as well as the generated Kafka Streams topology description and the schemas of all internal topics. To execute a planned test case, build the Kafka Streams topology from the saved plan, and execute it against the QTT inputs. The test validates the output data, the schemas of all internal topics, and the Kafka Streams topology against the committed copy.
- PlannedTestsUpToDate: for each QTT case, we make sure to have a planned test case for the current Execution Plan that ksqlDB generates. If we don’t, you must generate and commit a new planned test case.
This gives us a powerful suite of tests to verify that ksqlDB continues to consume and execute legacy plans correctly.
Future work
Execution plans are just the first step in a larger journey of enabling the ksqlDB Engineering Team to evolve ksqlDB over time. Let’s briefly take a look at some of the enhancements in this domain that are in the pipeline.
One of the advantages I’ve alluded to in this blog post is that execution plans let us make changes to the ksqlDB grammar and semantics without breaking queries that are already running. However, such changes could be breaking for users that leverage our API in their applications. We refer to this as breaking external compatibility. We still want changes that break external compatibility to be opt in. The ability to build a flow that allows you to choose between versions that are externally incompatible and to opt into upgrades across externally incompatible versions is currently under active development.
Execution plans make compatibility much easier to reason about and manage. However, any solution based on keeping legacy behavior around will add debt over time. In this case, we’ll wind up with a large set of step types that are no longer used by the engine for new queries, and at some point, we’ll want a way to migrate a query’s internal state so that it can be executed using a current topology. We wouldn’t want to do this on every release or upgrade (that would be operationally too expensive and hard to do without workload impact), but it would be good to have a mechanism that lets us do such migrations as appropriate. This would also be an important step toward providing a way to evolve your queries.
Summary
We’ve learned about how Confluent guarantees that users’ ksqlDB persistent queries continue to function correctly as we continuously ship the latest, greatest features.
We’ve covered the main compatibility challenges that persistent queries pose, looked at our historical solution and its problems, and deep dived into execution plans, our solution for managing compatibility in a maintainable way. We’ve also taken a peek at some of the related problems we’ll be tackling next. If you’d like to stay abreast of all the cool new stuff we’re working on, check out our open design proposals. Community contributions are of course welcome, and if working on a hosted streaming database sounds exciting to you, we’re hiring!
I hope that this has given you some insight into one of the unique challenges our engineering team has had to solve to ship ksqlDB reliably and frequently in Confluent Cloud. To continue reading, see the next posts in our series: Consistent Metastore Recovery for ksqlDB using Apache Kafka Transactions and Measuring and Monitoring a Stream Processing Cloud Service: Inside Confluent Cloud ksqlDB.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.