[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Kafkathon 2020: Hacking Event Streams Everywhere
As part of this year’s Kafka Summit, the Confluent Community team hosted a community hackathon named Kafkathon 2020. The event provided an opportunity for participants to learn, build, and showcase the projects that they have created to the world. In teams of no more than five, participants competed to solve an Apache Kafka® related challenge within 48 hours. Kafkathon 2020 provided an efficient way to:
- Deliver more awareness of cloud-native and serverless applications
- Bring the online Kafka community together for a team-building experience
- Encourage exploration of Confluent’s technology in a fun and interactive way
Below is a rundown of the winning teams and their projects.
First place: Kafka Socket – An easy way to look inside
By Alexandr Marchenko
Kafka Socket delivers an easy and safe way to access your Kafka cluster. It is a small Node.js application with a client library built by developers at Blizzard.
The challenge
The purpose of this project is to both provide a simple and secure way to enable developers to access Confluent Cloud without the risk of breaking something. Instead of trying to memorize commands, you can watch for messages going through Kafka by logging into Kafka Socket and see what is going on in real time. From an operations perspective, this is ideal because you do not need to give anyone access to a cluster.
As Confluent services begin to appear at random, the community has evolved to talk with one another via Kafka messages. In such a system, it is important to understand how everything works together and to be able to investigate bugs when the system as a whole does not work as expected.
The solution
Here is the basic idea behind Kafka Socket:
- Users visit the application
- A list of available topics is sent from the cluster and displayed in the UI
- Users click on one of the topics
- The frontend creates a dedicated WebSocket connection for the selected topic
- The backend creates a new consumer (or reuses an existing one) and starts broadcasting incoming messages to all connected users
- Each message is deserialized with Apache Avro and JSON as a fallback
The basic flow looks like this:
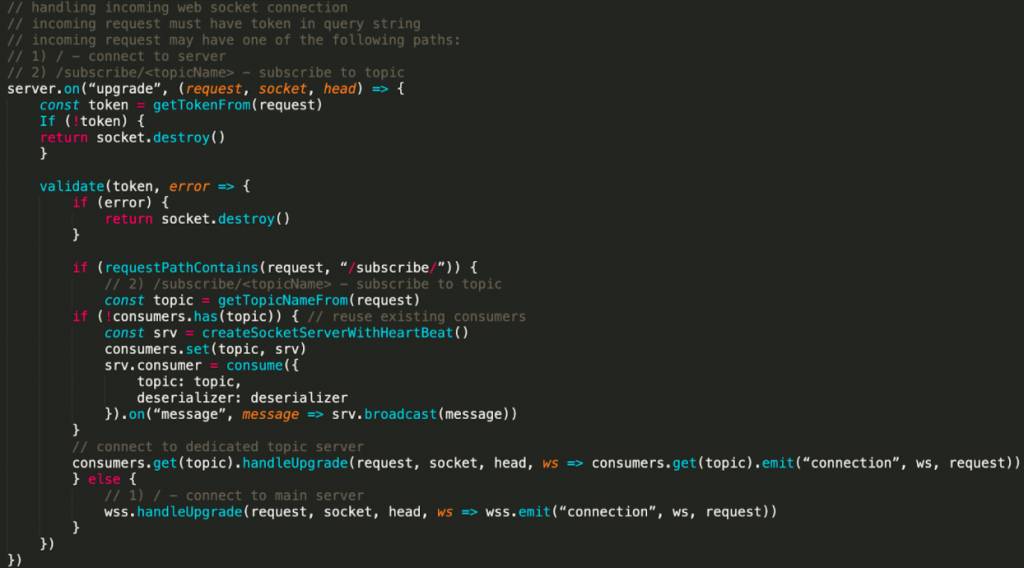
| ℹ️ | Note: You are not limited to a single WebSocket server instance on the backend. Servers are simply created when they are needed, which enables the ability to broadcast messages to all connected clients without filtering and managing their subscriptions. When there are no clients left, the socket server and its associated consumer are destroyed. |
Right before Kafka Summit, Confluent Developer Advocate Viktor Gamov hosted an episode of LiveStreams, where he discussed Kafka Summit and Kafkathon 2020. I was so excited to participate in the hackathon, but it was challenging because of the different time zone. I reached out to the community team, and their direction helped me get the answers I needed in order to participate. The greatest reward was having a good time at the event and the ability to take on-demand Kafka courses.
Second place: From Home and Beyond
By Edgar Madrigal
The challenge
This simple scenario happens every other day at GBS Corp. Every time there is a new record inserted into Database 1, a notification is sent via a Kafka message, and then that message is stored in Database 2. Most of the data flows through a Kafka topic and is tested through a full cycle of the whole application. When you are executing lots of processes and all you need to do is create a report out of the Kafka topic, it will be ideal to test just the consuming part.
The solution
This project, created by Carlos Obregón, Eduardo Diaz, Adrián Obregón, Jose Babb, and myself utilizes Voluble to generate fake data that helps its users explore the tool and present a data-oriented solution to our Quality Assurance team.
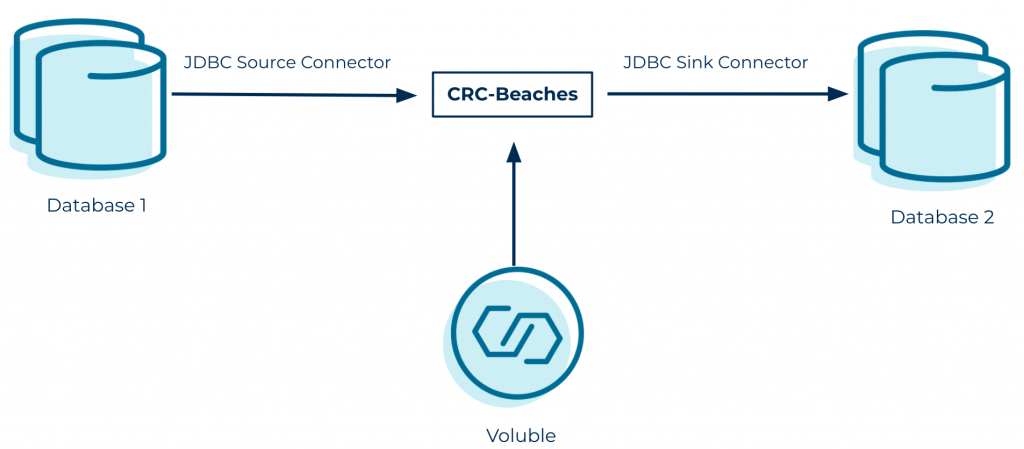
Because the main idea behind Kafkathon is to encourage creativity and provide opportunities for hands-on experience with Kafka and event streaming, we ran the solution on our computers (Windows 10/macOS Catalina).
Although most of us were able to set up the solution, Windows 10 proved to be a challenge. Only four out of five of us were able to run the stack correctly. This was mainly due to command translation issues between Bash and PowerShell.
When the Kafkathon started, our team was initially hesitant to ask questions. Most of the other participants appeared to be seasoned experts who were skilled in Kafka and Kafka Connect, but everybody provided awesome feedback on our project. We got a lot of help from the other teams at Kafkathon as well as from Confluent. On that note, Confluent Principal Product Manager Michael Drogalis was a great resource when it came to sharing his understanding of Voluble and how it generates data. We had to add some transformations along the way because it all appeared in text. Once that was done, we were able to connect (pun intended) all the pieces together.
My teammates Adrián Obregón, Carlos Obregón, Eduardo Díaz, Jose Soto also attended Kafka Summit and shared their knowledge with the rest of the Kafkathon project members. They were reminded that when challenges come, having synergy with their team enables them to create great solutions.
Conclusion
The Confluent Community team encourages Kafkathon participants to continue working on their projects by awarding them vouchers to complete the Confluent Certification Program and learning on-demand courses. If you have yet to start a new project, we have a promo code for you too! You can use DEV20Cert for 20% off Confluent certification and training.
The mission of the Community team is to engage and educate the Kafka community in new and exciting ways, and hackathons are just one way we strive to achieve this with our community members around the world. The Confluent team will be community sponsors at Hack Off v3.0 on December 12th–13th, 2020, and at HackDavis on January 16th–17th, 2021. We hope to see you there!
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



The Current Status of Current
Find out what’s next for Current 2026—including the role of the event in the growing data streaming community and updates to plans for Asia-Pacific and United States events.



Context-Driven AI Reigned Supreme at Current New Orleans
Catch up on Current New Orleans—and how executives, architects, developers, and data engineers alike learned about why AI should be powered by event-driven, context-rich data streams.