[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Apache Mesos, Apache Kafka and Kafka Streams for Highly Scalable Microservices
Apache Kafka and Apache Mesos are very well-known and successful Apache projects. A lot has happened in these projects since Confluent’s last blog post on the topic in July 2015.
- Microservices emerged as modern paradigm and architecture for many new projects.
- Container technologies like Docker and orchestration frameworks like Kubernetes took over in software architectures and became beloved by development and operations teams.
- Confluent evolved to a streaming platform with additional component around Kafka’s core messaging features, including Connect, Streams, the REST Proxy, Schema Registry, KSQL, Control Center, and others.
- Mesosphere’s DC/OS established itself as the de facto standard for Mesos deployments.
This blog post discusses how to build a highly scalable, mission-critical microservice infrastructure with Apache Kafka, its Streams API, and Apache Mesos respectively in their vendor-supported platforms from Confluent and Mesosphere.
Microservices and Apache Kafka
The Microservices paradigm establishes many benefits like autonomous teams and agile, flexible development and deployment of business logic. However, a Microservice architecture also creates many new challenges, like increased communication between distributed instances, the need for orchestration, new failover requirements, and resilient design patterns.
Confluent for Microservices is a great resource for getting started if you want to learn more about how the Apache Kafka ecosystem can help you in building a scalable, mission-critical microservice architecture. A short summary can be found in the five-minute video, Microservices Explained by Confluent.
Hint: We talk a lot about the sometimes misleading buzzword “microservices.” This does not mean that you could or should only build very small services. There are always trade-offs between small services and bigger applications. Size your application for your requirements and build anything in between a very small, independent microservice and a big monolith. It needs to be as agile and autonomous as you need it in your scenario. The following sections mostly use the term ‘microservice’ even though this can also be a ‘bigger application.’
The next section explains what Apache Mesos is and its relation to Mesosphere and DC/OS.
Apache Mesos and Mesosphere’s DC/OS
Apache Mesos is a cluster manager that provides efficient resource isolation and sharing across distributed applications or frameworks. It sits between the application layer and the operating system. This makes it easy and efficient to deploy and manage applications in large-scale clustered environments. Apache Mesos abstracts away data center resources to make it easy to deploy and manage distributed applications and systems.
DC/OS is a Mesosphere-backed framework on top of Apache Mesos. As a datacenter operating system, DC/OS is itself a distributed system, a cluster manager, a container platform, and an operating system. DC/OS has evolved a lot in the past couple of years, and supports new technologies like Docker as its container runtime or Kubernetes as its orchestration framework.
As you can imagine from this high-level description, DC/OS is an first-class choice infrastructure to realize a scalable microservice infrastructure. The following shows Mesos’ architecture and the relation to other components of a microservice architecture:
- Master (with Zookeeper under the hood) controls the distribution of computing resources
- Frameworks like Marathon or Chronos manage and schedule different distributed tasks
- Executors run the defined tasks like a cluster of Kafka brokers or several Kafka Streams microservice instances
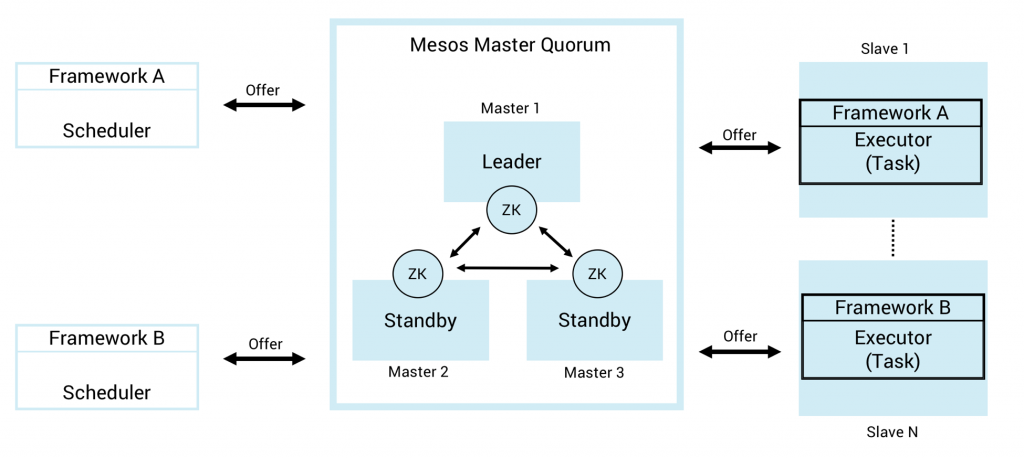
The following sections describe how to leverage Mesos and DC/OS to build highly scalable microservices with the Kafka ecosystem.
Benefits of Kafka and Confluent on DC/OS
DC/OS adds several benefits for deployment, management and monitoring of the various components from the Kafka ecosystem:
- Automated provisioning and upgrading of Kafka components like Kafka Broker, Kafka Connect, Confluent REST Proxy, Confluent Schema Registry, Confluent Control Center or any Kafka Producer / Consumer application using the Java / Go / .NET / Python Clients, the Kafka Streams API, or using KSQL.
- Unified management and monitoring of multiple Kafka clusters on one infrastructure + multi-tenancy
- Elastic scaling, fault tolerance and self-healing of Kafka components, including Kafka specific features like a so called Kafka VIP Connection to be used as one static bootstrap server url for the Kafka cluster
Let’s now look at a practical example of how to set up a Kafka and microservices infrastructure on DC/OS to leverage all these benefits. This is separated into two parts: 1) setting up the Kafka infrastructure and 2) running Kafka-Streams-based microservices.
Apache Kafka and Confluent Components on DC/OS
All Kafka and Confluent infrastructure components are available in DC/OS’ catalog. You can start a new Kafka cluster with one click in the web UI or CLI command—or do specific configuration to customize the setup and cluster size for your project requirements. Other components from the Kafka ecosystem like Kafka Connect, Confluent REST Proxy, Confluent Schema Registry, or Confluent Control Center can be set up the same way.
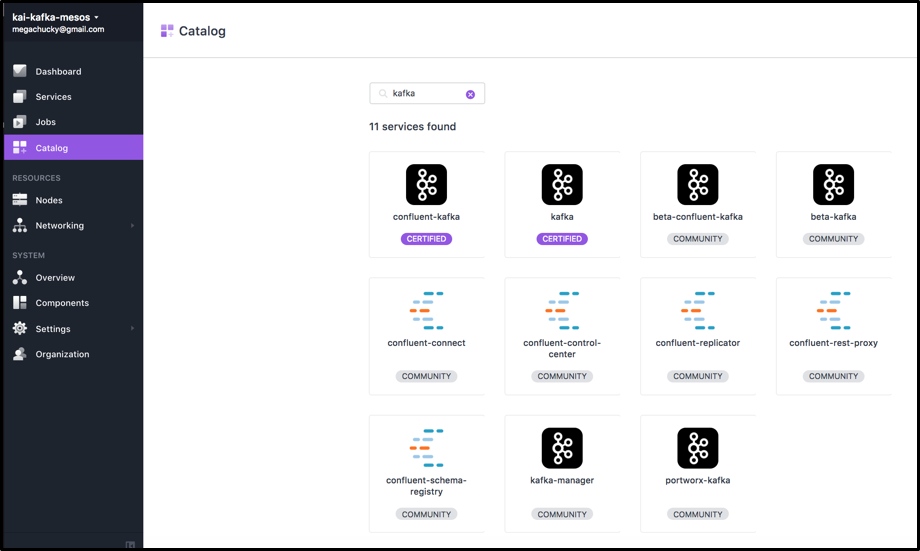
DC/OS provides you with one static “Kafka VIP connection URL.” Even if your dynamic cluster setup changes over time because of scaling up or down, failures, or rolling upgrades, you do not need to change the bootstrap address of any Kafka clients.
Hint: Apache Mesos and Apache Kafka both rely on Apache Zookeeper as a distributed coordination service. By default, new Mesos services like a Kafka cluster use the built-in Zookeeper provided by Mesos master nodes. However, Separated Zookeeper clusters are recommended in large deployments. The following shows Exhibitor (a management UI for Zookeeper) used by Mesos by default. It includes configuration for DC/OS and Kafka brokers:
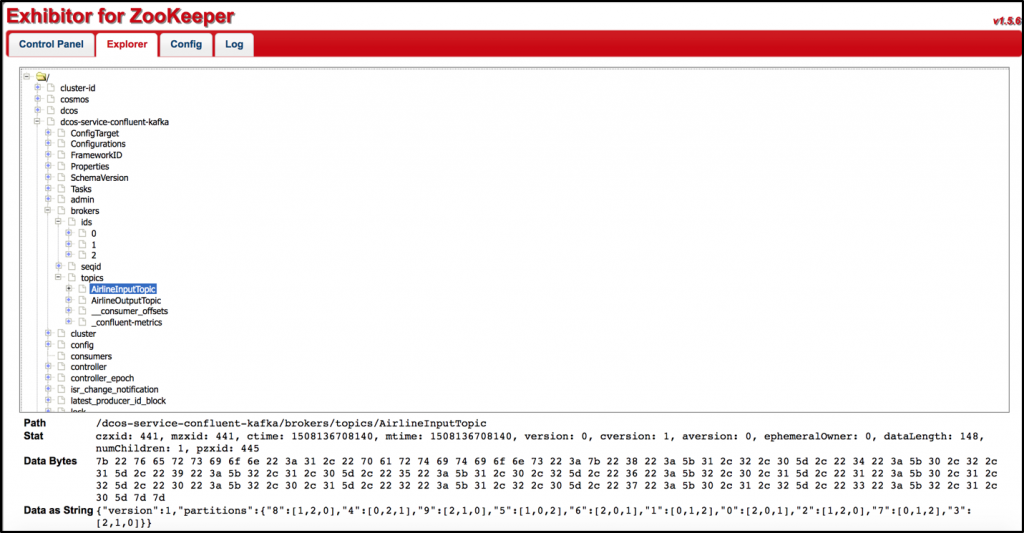
After the Kafka cluster and other optional components like the Confluent Schema Registry are set up and run, you can deploy your Kafka Streams microservices.
Kafka Streams Microservices on DC/OS
The Kafka Streams API is a JAR dependency added to a conventional Java application. Therefore, it can be added to any JVM application or microservice to build lightweight, but scalable and mission-critical stream processing logic. No need for a separate big data cluster like Hadoop or Spark. Kafka Streams can run as standalone applications, within a larger web application, or even in a legacy monolith. The application package is deployed to DC/OS via its container runtime (either Mesos runtime or Docker engine) and managed by a Marathon scheduler:
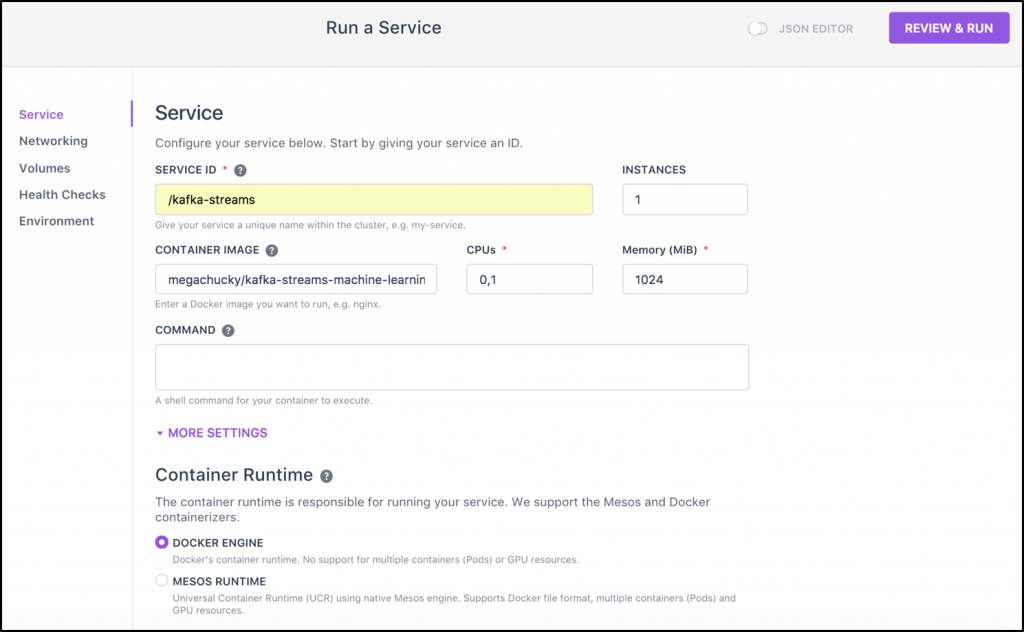
DC/OS supports Kubernetes in the meantime. Therefore, you could run Kafka brokers natively on Mesos while your Kafka Streams microservices are deployed and managed by Kubernetes.
You can scale the microservice up and down manually, via scripting and thresholds, or using Marathon’s Autoscaling add-on. Kafka Streams automatically balances the incoming messages from Kafka topics to all existing instances (by default via round-robin). If an instance fails, Kafka Streams automatically moves the load to the other instances without any data loss. This allows to build highly scalable and mission-critical microservices. With the introduction of Exactly-Once-Semantics (EOS) in Kafka 0.11 (https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/), you can also build transactional business logic without much hassle.
The following picture shows a possible architecture using Marathon as Mesos framework with three Kafka brokers and five Kafka Streams microservice instances:
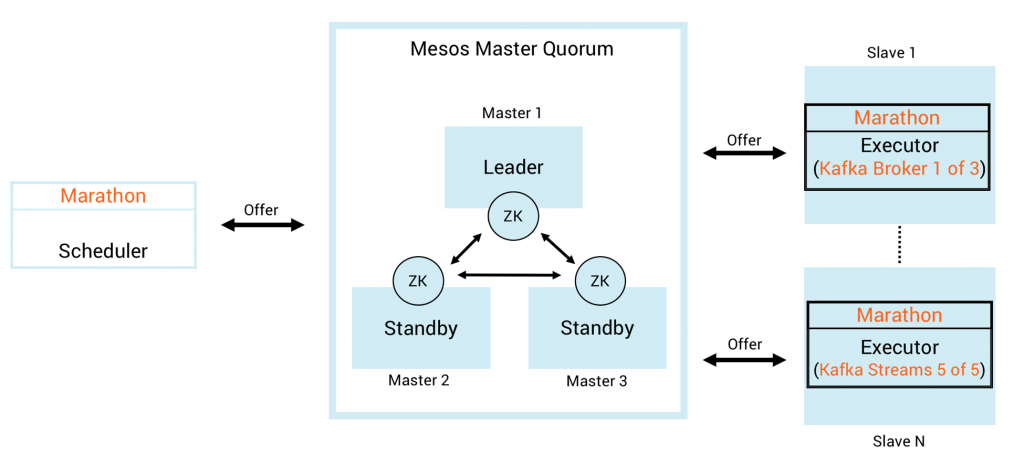
Everything described above is also true for KSQL, Confluent’s SQL streaming engine for Apache Kafka. Under the hood, a KSQL engine also uses Kafka Streams. Therefore, you can run and scale it via Docker, Kubernetes or DC/OS the same way as a Kafka Streams microservice.
Hint: If you want to deploy and test your own Kafka Streams microservices on DC/OS, please be aware that Mesosphere’s Kafka Client (which is used in most examples and tutorials on the web) is no longer maintained and was last updated two years ago. It does not support Kafka’s Streams API, as it uses Kafka version 0.9. Kafka is backwards-compatible between brokers and clients, but Kafka Streams messages require timestamps. Thus, you need a newer Kafka Client. I created a Docker image using the same Dockerfile, but replacing Kafka 0.9 with version 0.11. Note that you can use any other Kafka Client, including Confluent’s Docker image. If you do not want to worry about security (e.g. firewalls and open ports), but just play around, you can start the Kafka Client within DC/OS environment using the command “dcos node ssh –master-proxy –leader” to connect and then run your Kafka Client (e.g. “docker run -it confluentinc/cp-kafka”).
Scalable Kafka Streams Microservices on DC/OS in Action
The following 15min screencast shows how to deploy, manage and scale Kafka brokers and Kafka Streams microservices on a DC/OS cluster:
Highly Scalable Microservices with Mesos and Kafka Ecosystem
Successful microservice architectures require a highly scalable streaming infrastructure combined with a cloud-native platform which manages the distributed microservices. Apache Kafka offers a highly scalable, mission critical infrastructure for distributed messaging and integration. Kafka’s Streams API allows to embed stream processing into any application or microservice to add lightweight but scalable and mission-critical stream processing logic.
Mesosphere’s DC/OS enable management of both—Kafka / Confluent infrastructure components and Kafka Streams microservices—to leverage many built-in benefits like automated provisioning, upgrading, elastic scaling, unified management, and monitoring.
Want to try this out with your own Kafka Streams microservices? Get started with the following resources:
- DC/OS: AWS CloudFormation script to set up a DC/OS cluster in 5min in your region
- Kafka / Confluent: “1 click deployment” via DC/OS Catalog – search for ‘Kafka’ and start a Kafka cluster and other Confluent components
- Kafka Streams: Develop and deploy your Kafka Streams microservices and scale them up and down on DC/OS
- Video recording from MesosCon Europe 2017 in Prague about Apache Kafka and Kafka Streams on DC/OS
- Advanced Confluent configuration on DC/OS is described in this Confluent white paper
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...