Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Agentic AI Research Assistant
Harness the capabilities of agentic AI to autonomously gather, analyze, and synthesize information. With an event-driven architecture (EDA), Confluent’s data streaming platform helps you leverage real-time data to build and scale AI agents that execute complex research workflows and deliver tailored, high-quality insights.
Unlock agility, precision, and efficiency with the future of intelligent research
One of the key challenges in creating an AI research agent lies in designing a flexible yet scalable architecture that avoids rigid dependencies. Traditional monolithic systems struggle with bottlenecks and tightly coupled components, which hinder scalability and agility.
Confluent’s data streaming platform helps create agentic AI systems in environments that require seamless integration across distributed systems and teams, allowing MLOps, data engineers, and application developers to work independently and collaboratively on a common operating model. Key benefits include:
Resilience and efficiency in handling complex real-world workflows
Ensuring AI insights flow into tools like customer data platforms (CDPs), CRMs, analytics, and more
Use of real-time data for action and analysis, allowing new events to trigger updates
Faster iteration cycles and ability to evolve systems with new agentic AI tools
Time savings from automated workflows and quality research, allowing users to focus on higher-level decision-making
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud:
Reference Architecture
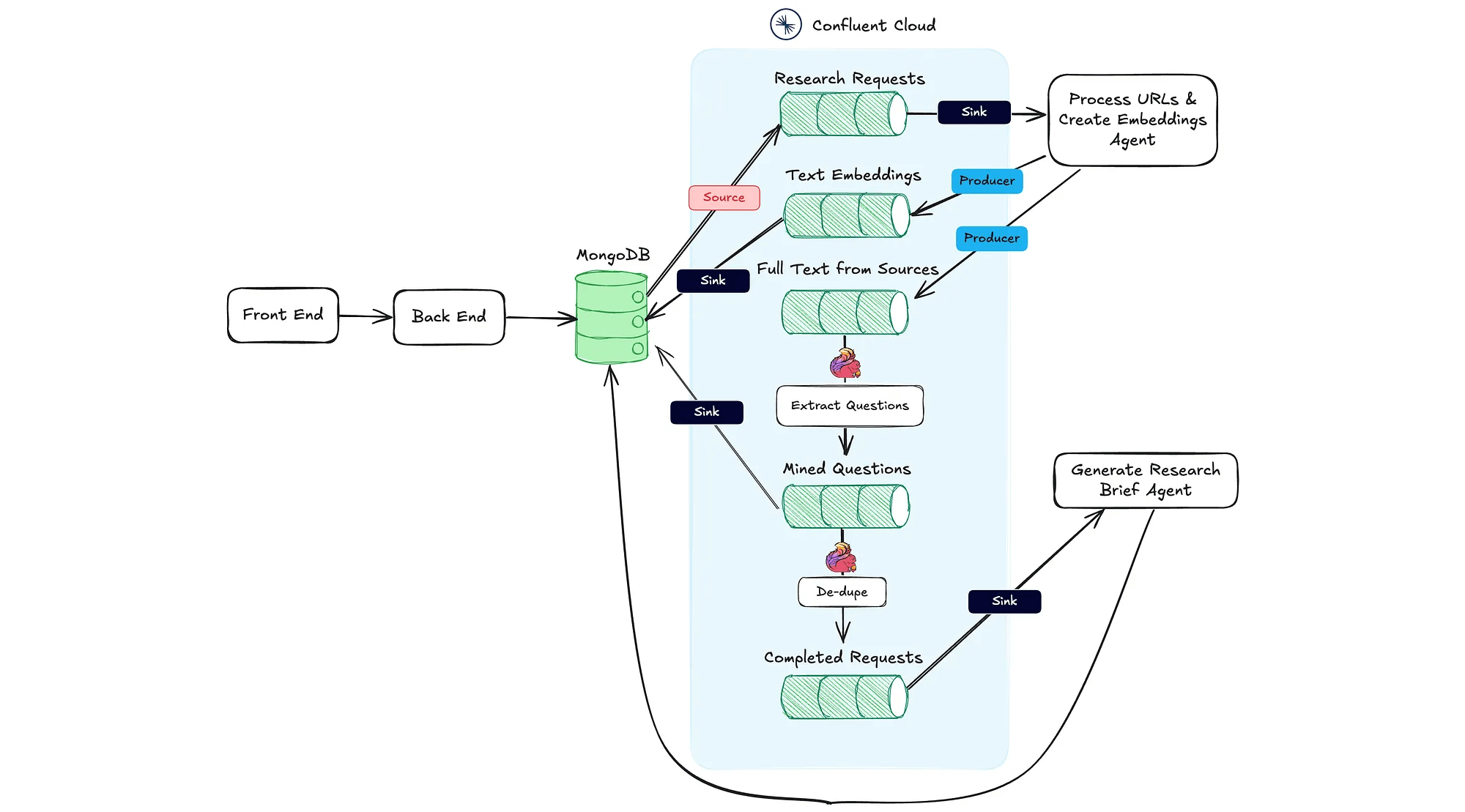
Architecture from the web application to the agentic workflow:
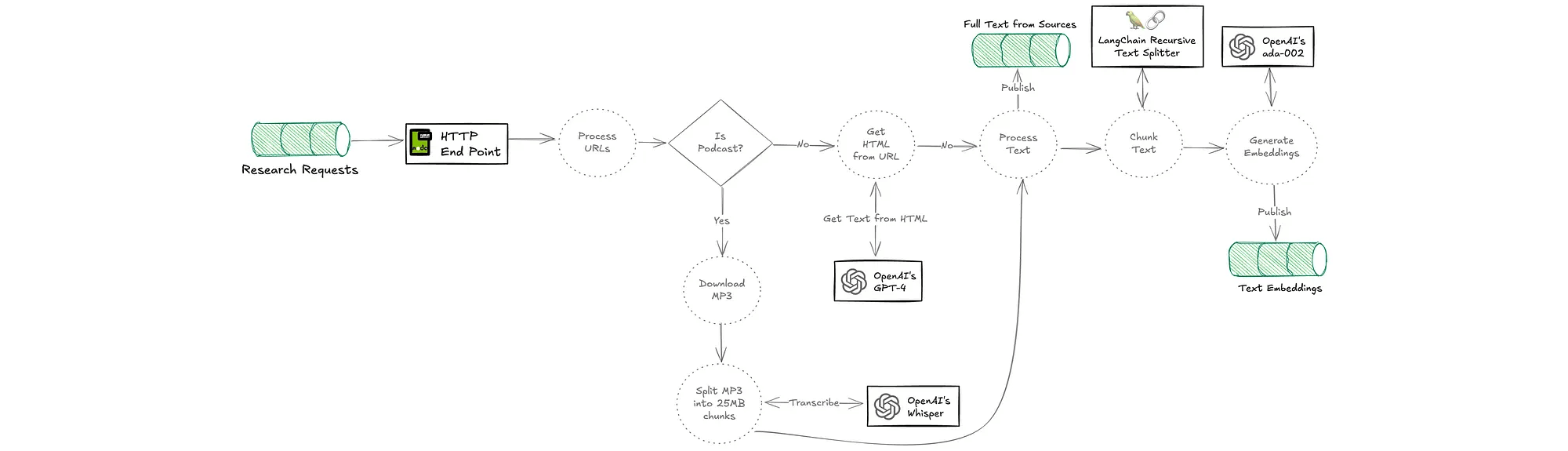
Flow for the agent that processes URLs and creates vector embeddings from the web application:
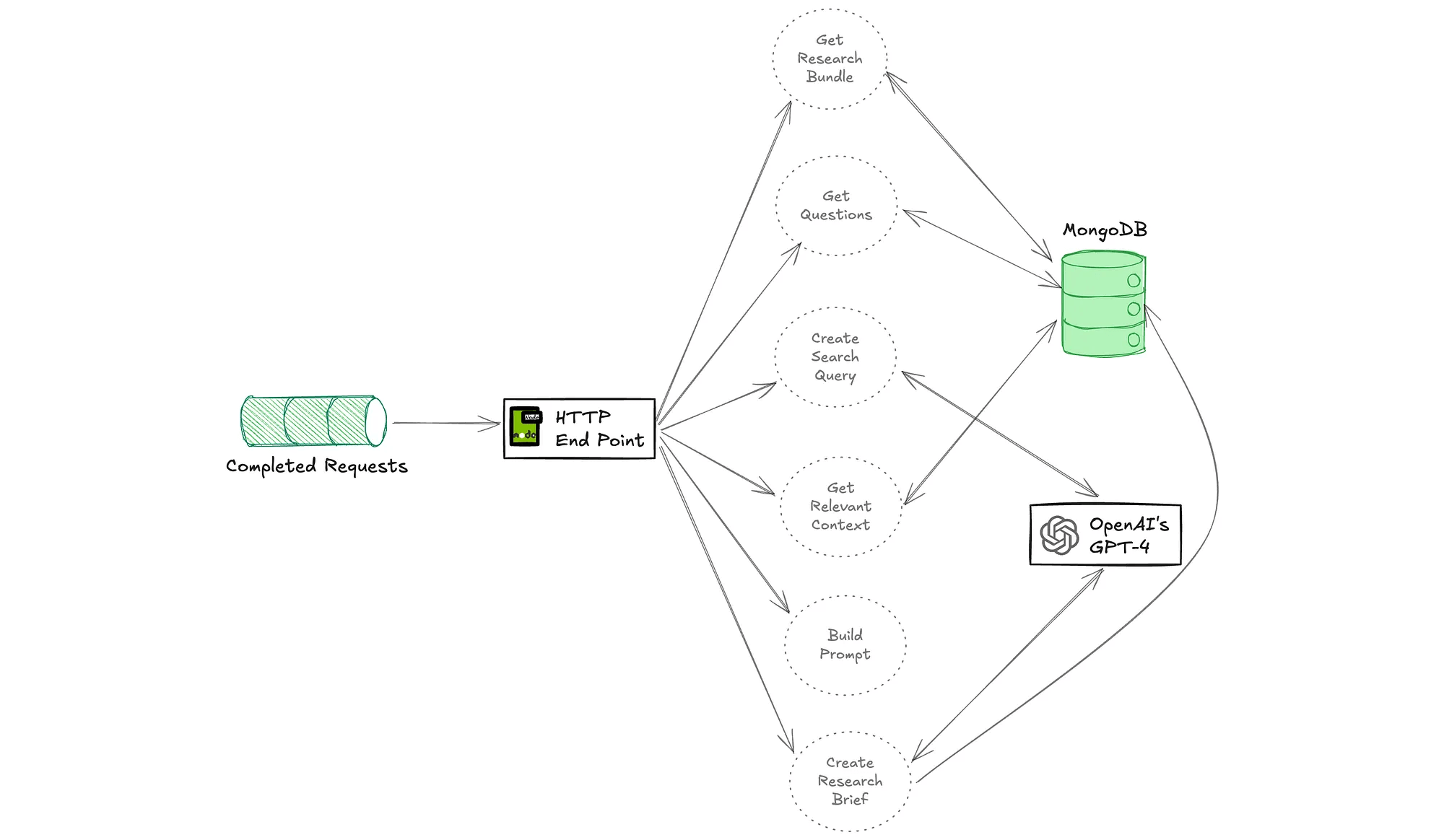
Flow for the agent that generates a research brief:
Continuously ingest real-time data from heterogeneous data source material such as guest name, company, topics to focus on, and reference URLs like blog posts and existing podcasts. Then sink outputs to a vector database like MongoDB. Use Confluent’s large portfolio of 120+ pre-built connectors (including change data capture) to quickly connect data systems and applications.
Use Flink stream processing to extract and generate questions from research materials using an LLM (OpenAI in this case), and track when all research materials have been processed, which triggers the research brief generation.
Leverage Stream Governance to ensure data quality, trustworthiness, and compliance. Schema Registry helps define and enforce data standards that enable data compatibility at scale, allowing AI agents to effectively process, interpret, and act on information across diverse systems.