Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Join Us at Google Next to See What’s Next for Confluent
Here at Confluent, we’re excited to once again be participating in Google Cloud Next, taking place from Oct 12-14, and we hope to see you at our virtual booth to hear more about what’s new at Confluent and how we can help your business.
The Google-Confluent partnership this year has continued to power new use cases for our joint customers. Just a few weeks ago, in recognition of the value we’re adding for customers, Confluent was named Google Cloud Technology Partner of the Year for the third year in a row. Our presence at Next this year will be bigger than ever: we’ll have three lightning talks, keeping things short and sweet, to accommodate the challenges of a virtual event. Below is a sneak peek of what you can expect to see from Confluent at Google Cloud Next.
Expanding customers’ analytic capabilities: Data Warehouse Modernization
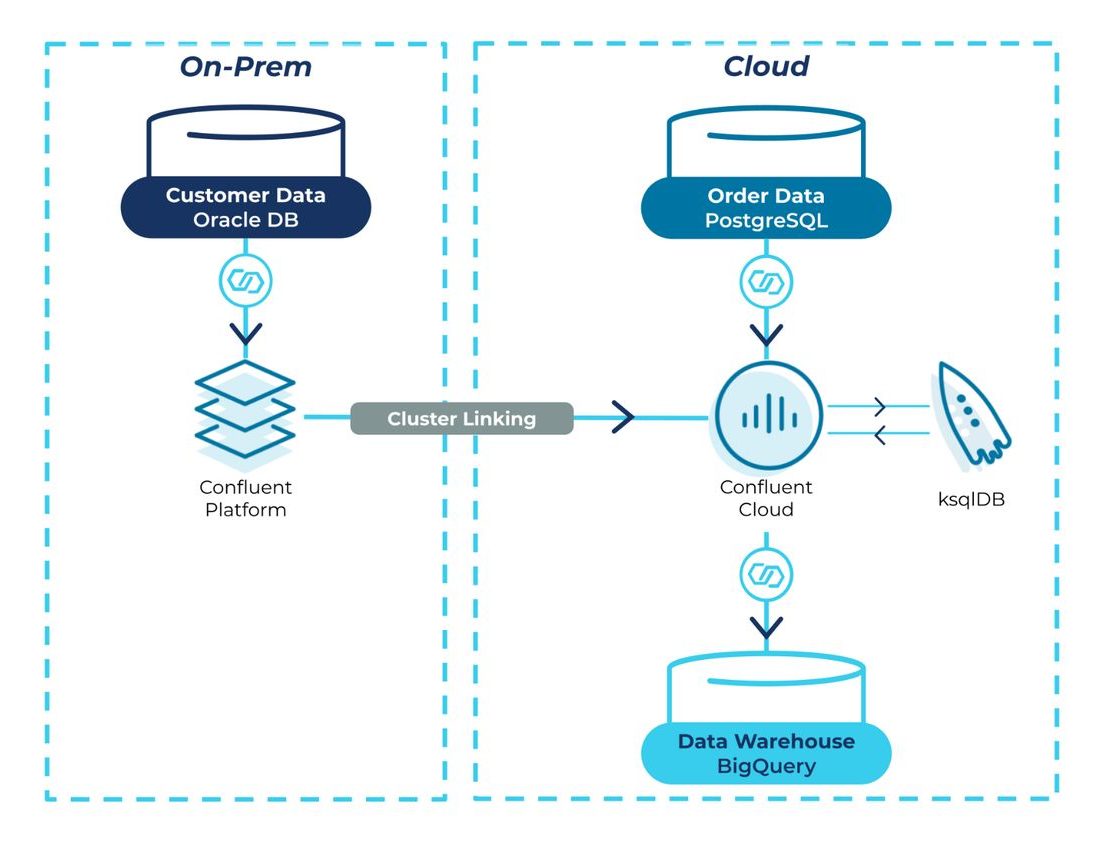
The journey to a cloud data warehouse can be long and complicated, requiring multi-year efforts spanning multiple teams and tools. There are a few main challenges that companies face with migration, such as high costs, no support for hybrid/multi-cloud environments, and a long path to analytics-ready data. However, at Confluent we’re taking a different approach, which Tim Berglund will outline during his Modernize Your Data Warehouse with Confluent talk.
In this session, Tim will demonstrate how to migrate from a legacy data warehouse hosted in Oracle to Google BigQuery through the use of Confluent, our connectors, and ksqlDB. You will leave with a clear understanding of how Confluent can help you and your team rapidly achieve your data warehouse modernization goals and how to get started.
Drive analysis in real time: Build pipelines with Confluent and Dataflow
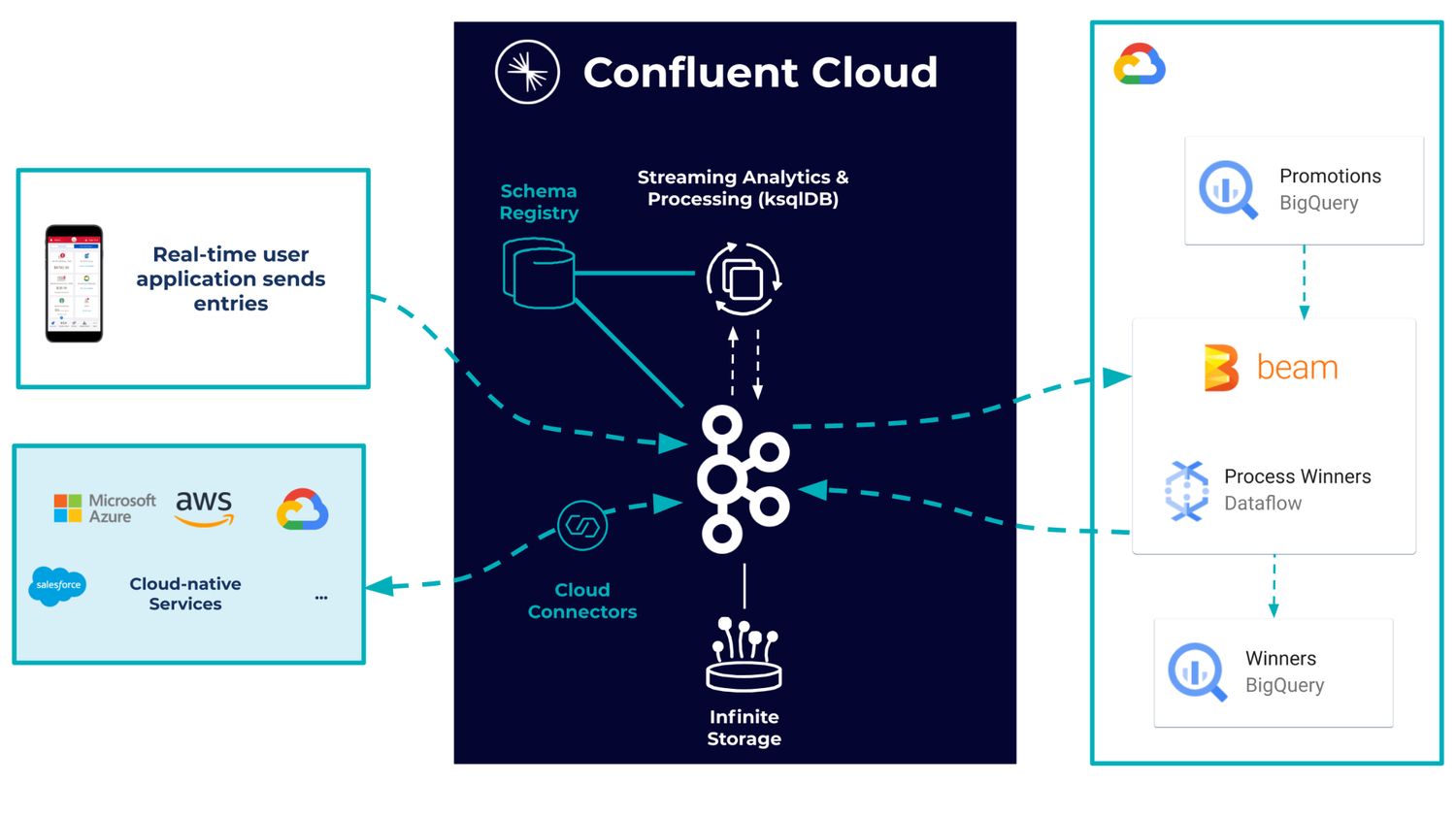
Part of the data in motion paradigm is that you need to be able to process streams of incoming data to react and respond in the moment. With Confluent you can do this either with our built-in stream processing client, ksqlDB, or with a vibrant ecosystem of external stream processing frameworks, such as Apache Beam running on Google Cloud Dataflow.
We hope you’ll join us for the Building Streaming Data Pipelines with Google Cloud Dataflow and Confluent Cloud session, where I will cover how easy it is to use Confluent Cloud as the data source of your Dataflow pipelines. We’ll get hands-on with the technology and walk through a real problem, helping you learn how to process the information that comes from Confluent in real time, make transformations on the data, and feed it back to your Kafka topics and other parts of your architecture.
Our joint investments in hybrid: Confluent and Anthos
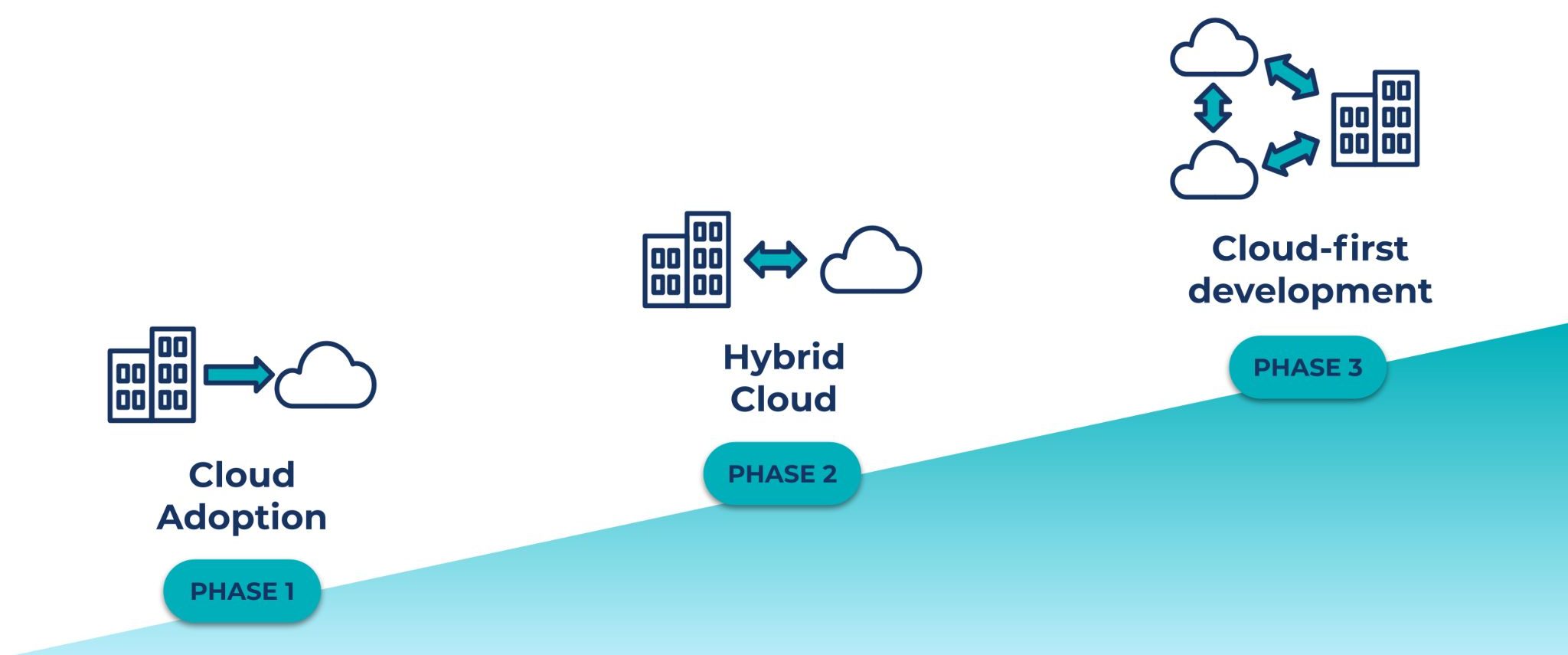
Google, Accenture, and Confluent have a shared understanding of the importance of helping customers unite and connect data that lives on-premises and in the public Cloud. Enterprise cloud strategies are better viewed as long-term journeys, not one-time migrations. Regardless of where you and your organization are in that process, we want to help you on your path.
To get started, join my talk The Future of Hybrid Data Infrastructure, Confluent on Anthos. There, I will explain how Anthos and Confluent can deliver a complete and seamless hybrid cloud experience for modernizing and developing cloud-native applications on Kubernetes. You will walk away with sample architectures and success stories to help bring the unification of your on-premises and cloud environment into reality.
We hope you’ll join us and the rest of the Google Cloud community at this conference. Stop by our virtual booth and engage with us, ask questions, and tell us about your experience. If you haven’t done so already, go register for Google Cloud Next. See you there!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Scaling the Streaming Stack: Introducing the Sell with Confluent Partner Program
Sell with Confluent is our new reseller engagement model, designed to empower partners with streamlined quoting, automated incentives, and scalable growth.



Simplify Real-Time Context Engineering for Snowflake Intelligence With Confluent
Power Snowflake Cortex agents with real-time, trustworthy context using Confluent Intelligence, Streaming Agents, and the Real-Time Context Engine.