Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Unifying Streams and State: The Seamless Path to Real Time
More than ever before, people demand immediacy in every aspect of their lives. Expectations for how we shop, bank, and commute have completely evolved over the last decade. When you exit a ride from Lyft, you have a receipt barely after your foot hits the pavement. When you split the cost of dinner with a friend using Venmo, funds are transferred in seconds. It can feel as if a whole company is all hands on deck, just for you. Software is the driving force that makes this possible.
At Confluent, we believe this is a global phenomenon. Every company is becoming a software company. The key to offering these unique customer experiences is to embrace events and event stream processing. By capturing fine-grained information about what is happening in the world and acting on it in real time, businesses can begin to interact with their markets in a highly scalable, self-service manner.
Sometimes this manifests by introducing new kinds of automation. Ridesharing services like Lyft and Uber are the poster child for this model. There is no “operator” at headquarters manually matching up drivers and riders. Software automatically processes a stream of events and offers the gig to drivers who are nearby. As long as there are enough drivers and riders, there aren’t any real limits to how many customers can transact at the same time. Businesses in other domains, like retail, online gaming, and core banking, are leveraging a similar model.
In other cases, the self-service model allows for more hands-on intervention into what are otherwise opaque business processes. When a retail company launches an online marketing campaign, it can be 24 hours or more before any information is available about how effective the campaign actually is. By contrast, modern competitors process streams of events from their stores to create a tight feedback loop. Executives monitor key metrics for their campaigns in real time and make strategic changes as needed. Every reduced second of reaction time is an advantage during high-stakes holidays like Black Friday.
The pressure is on for all companies to make this transition. Seventy-three percent of people say that one extraordinary experience with a company raises their expectations for every other company. Stream processing and event-driven applications form the backbone of technology that offer the immediacy everyone wants.
But there’s a catch—it can be wildly expensive to build a business using these approaches.
Breaking the cognitive (and literal) bank
In spite of all the great properties of event-driven programming, it’s hard not to notice the complicated architectures that inevitably form around them in practice. In fact, developing a stream processing system can be a surprisingly punishing exercise. Separate systems need to be glued together to capture events from external sources, store them, process them, and serve queries against them to applications.
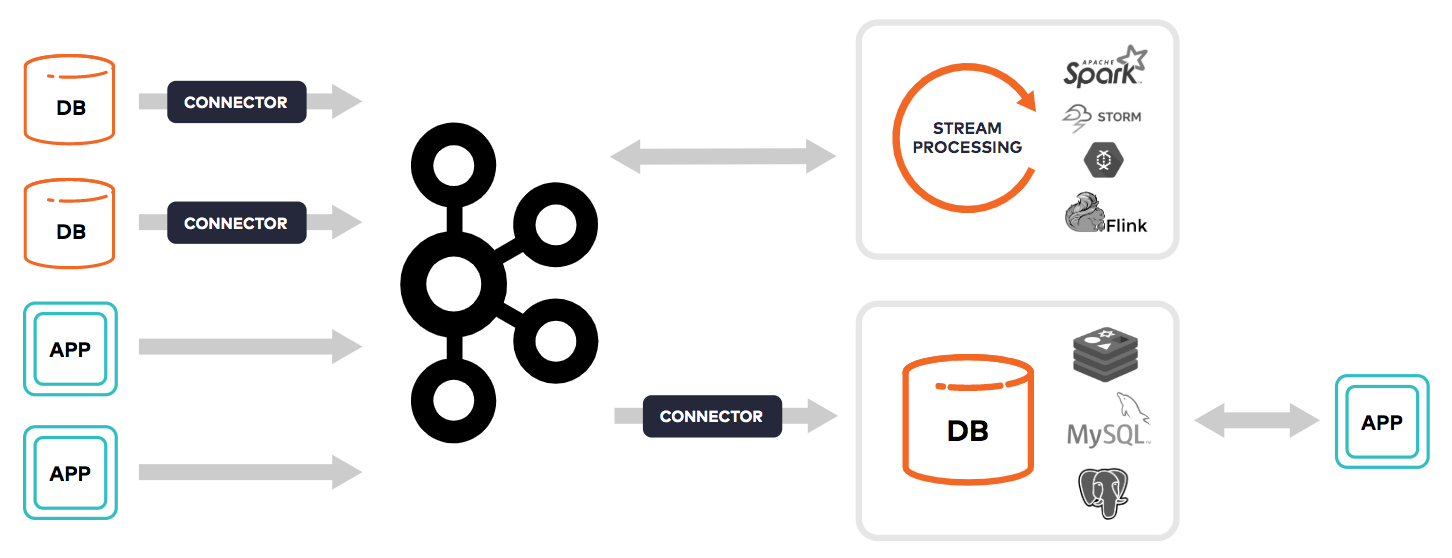
In practice, this amounts to running 3–5 separate, complicated distributed systems, each with different ways of scaling, monitoring, securing, and debugging. Every change requires you to think in these 3–5 different ways at the same time. It is completely exhausting. It falls on you to integrate and operate all of these as one. It’s like building a car out of parts, but none of the manufacturers talk to one another. This cognitive tax draws down your mental bank dedicated to your overriding imperative: Solve important business problems for your company.
Because building and maintaining these systems is so complicated, stream processing tends to only get used for the most important problems with the highest budgets. You need deep pockets to recruit and retain a team of extraordinarily skilled distributed systems engineers. According to the Dice 2019 Tech Salary Report, Apache Kafka® was the second-highest paid tech skill in the United States in 2018.
But this is more than just a salary dilemma. Your time is zero sum and needs to be weighed against the opportunity cost of all other things you could be doing. It’s a reminder of the same crucial question we all ask ourselves in the 13th hour of debugging why two distributed services aren’t communicating properly: “Is this really the best place for me to be spending my time?” When your day is filled with stitching different systems together, it’s easy to wonder whether the whole event streaming model is really worth it.
Does that mean that stream processing systems and the self-service business models that they support are forever off limits to companies that don’t want to empty their wallets and clear their product roadmaps?
We don’t think so.
Out of the event streaming tar pit
If every company is becoming a software company, then stream processing will inevitably be made easy enough to become mainstream. In fact, we think that many of the foundational elements needed to make this happen already exist today. That’s why we built ksqlDB, the event streaming database purpose-built for stream processing applications.
The idea is that an event streaming database can offer one SQL query language to work with both streams of events (asynchronicity) and point-in-time state (synchronicity). It requires no separate clusters for event capture, processing, or query serving, meaning it has very few moving parts. There is one mental model for working across the entire stack. Scaling, monitoring, and security can also follow a uniform approach.
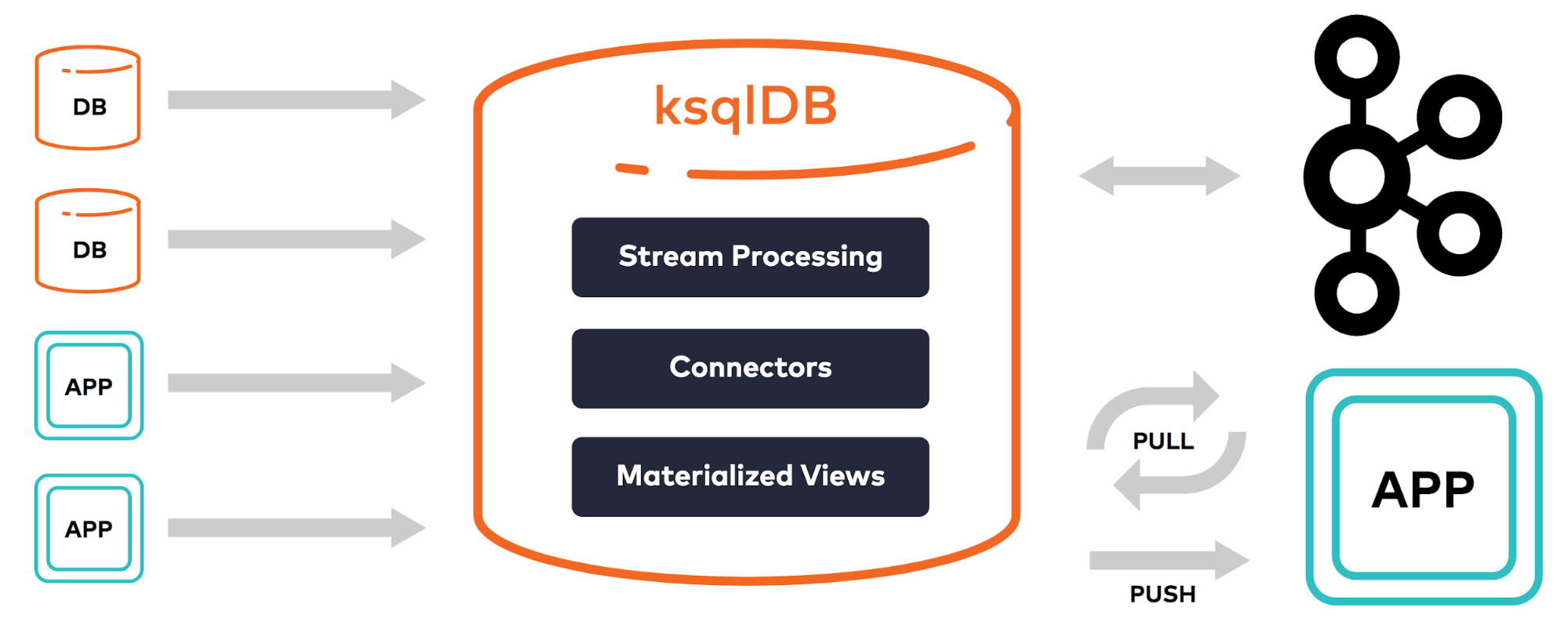
ksqlDB is not an island. It integrates out of the box with the 100+ existing Kafka connectors to move data between source and sink data systems. It cleanly communicates with Schema Registry to make schemas globally available to any third party components. It has a first-class presence in Confluent Control Center, giving you a bird’s-eye view of everything that is happening. To top it off, it’s available as a fully managed service in Confluent Cloud.
All of this amounts to spending less time and money on the low-level details of constructing a sound stream processing architecture. In other words, if working with an event at a time using Kafka is the hard way, ksqlDB is becoming the easy way.
Theory meets practice
What does this buy you in the real world? What exactly is an event streaming database good for? From a technical point of view, ksqlDB focuses on making it inexpensive to create data pipelines (sometimes called streaming ETL) and build/serve asynchronously materialized views.
Data pipelines are a perennially useful concept, powering event-driven microservices, analytics, and data normalization. They form the spine of business systems that, for example, manage SaaS license distributions, alerts on stock price fluctuations, and trigger next steps on home loan applications.
Materialized views, on the other hand, increasingly make it easier to build applications because applications themselves are becoming increasingly event driven. It’s now a common design pattern for an application to “pull” its current state once on load, and then have the server “push” events about the latest state as they occur. This query/subscribe model has been popularized through RxDB’s reactive queries, OrientDB’s live queries, and RethinkDB’s changefeeds. GraphQL is following suit by debating a specification for first-class live queries, too.
This design pattern is applicable to a huge number of business use cases. For example, it can be used to:
- Create dynamically updating maps of geospatial activity, like vehicle position on a ridesharing app
- Plot out real-time updates to graphs that monitor anything from stock prices to server health
- Update an online scoreboard for an MLB game moments after each play
- Build real-time market places, dynamically reflecting inventory as customers browse the store site
- Reconcile the state of many connected devices, like a to-do app on an iPhone and Macbook Pro
- Build collaborative applications, like a chat system
With traditional architectures, many of these applications are hard to build and maintain. ksqlDB, surrounded by a battle-tested set of Confluent products, makes this within reach for companies that don’t want to break the bank.
Seeing is believing
Beautiful concepts only matter if they work in the real world. But see for yourself! In this demo, we build an end-to-end streaming data pipeline powered by Confluent Cloud.
What’s next
Maybe you’re wondering whether it’s really worth it to spend so much time jamming event streaming components together like pieces of a jigsaw puzzle. After all, it’s important that you and your best people are free to work on things that matter. Rarely is connecting and maintaining infrastructure the most important thing to be doing.
We think that there’s a better way forward. By gracefully fitting together the core elements of event streaming and stream processing, ksqlDB can help every company become a software company.
If you’re interested in what this might look like with Confluent, you can request a free TCO assessment and we’d be happy to provide that for you:
To learn more, check out the Cost-Effective page as part of Project Metamorphosis.
Further reading
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.