Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
5 Years of Confluent Cloud Connectors: Exploring Your Top Connector Picks
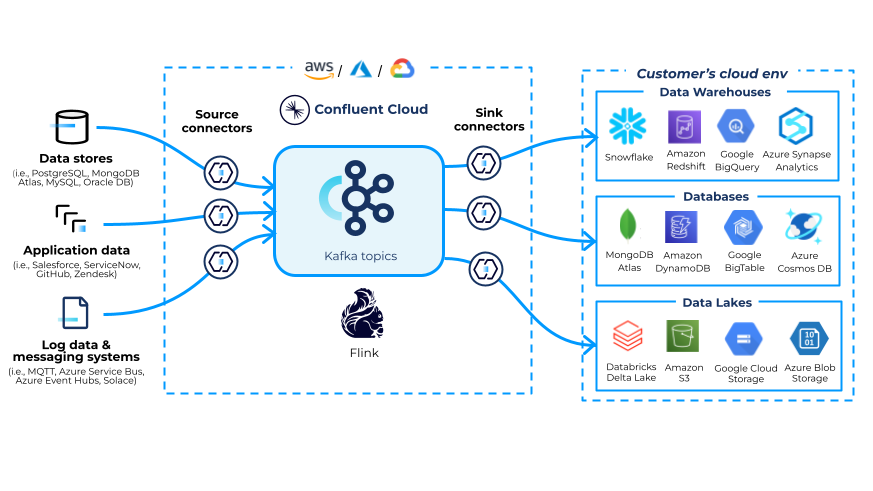
This summer marks five years since we announced our first fully managed connector on Confluent Cloud in 2019, the Amazon S3 Sink Connector. Since then, our connector offerings have not only expanded significantly but also enabled teams to send hundreds of petabytes of data throughput. Today, we support over 80 pre-built, fully managed connectors, custom connectors, and secure private networking.
Confluent’s connectors are built on the open source Kafka Connect framework, which continues to thrive with an active community. There are thousands of Connect GitHub repos and over 100 pull requests merged into the framework so far this year. If you’re looking to simplify data integrations with Apache Kafka®, our connectors—designed, built, and tested by Kafka experts—are an easy and reliable choice.
To celebrate this milestone, we're excited to share a look behind the scenes at our connector portfolio. We’ll walk through snapshots of interesting usage data and top connector rankings to help inspire your next use case. Continue reading to learn more!
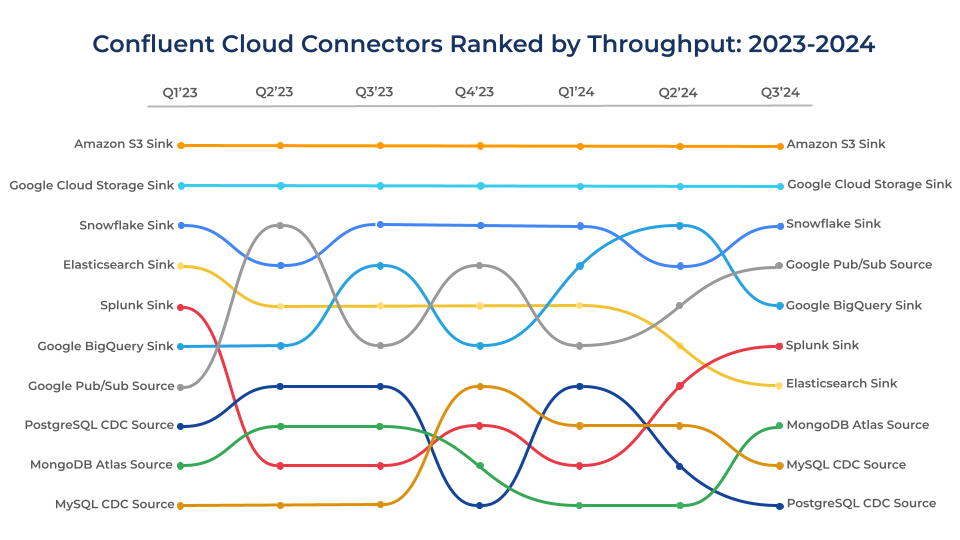
Top cloud connectors by throughput
Let’s start by examining Confluent’s fully managed connectors. If you don’t already know, leveraging fully managed connectors is the fastest, most efficient way to integrate your data systems and apps with Kafka by eliminating operational burdens. The graph below showcases some of our top cloud connectors by data throughput and how their rankings have evolved.
The Amazon S3, Snowflake, Google Cloud Storage, and Google BigQuery sink connectors consistently rank near the top of the list. Data lakes and warehouses are certainly popular destinations for streaming data, powering your organization’s analytics and informing real-time decision-making.
However, organizations often send all of their data to each of their downstream systems for cleaning and processing, turning what was real-time data into stale data, proliferating bad data, and racking up expensive, redundant processing costs. That’s why we recommend building reusable data products ready for any downstream consumer by governing and processing data as they are created. By shifting a portion of the downstream processing workload to Confluent, you can leverage Stream Governance to enforce high data quality and stream processing with Apache Flink®.
Popular connector combinations
Since connectors play a fundamental role in streaming data in and out of Kafka, organizations commonly use multiple connectors to build streaming data pipelines. Let’s take a look at the popularity of different connector combinations used by Confluent customers with the heat map below.
Top connectors used together, ranked by number of Confluent orgs:
MongoDB Atlas Source + MongoDB Atlas Sink
MongoDB Atlas Source + PostgreSQL CDC Source
Amazon S3 Sink + Snowflake Sink
PostgreSQL CDC Source + Snowflake Sink
MongoDB Atlas Source + Snowflake Sink
MongoDB Atlas Source + Amazon S3 Sink
SQL Server CDC Source + Snowflake Sink
PostgreSQL CDC Source + Amazon S3 Sink
Amazon S3 Sink + HTTP Sink
MongoDB Atlas Source + Google BigQuery Sink
At the top, we have the largest number of Confluent organizations using both the MongoDB Atlas Source and Sink connectors. Because it isn’t a typical architectural pattern to build a streaming pipeline to and from the same data system, these organizations are likely using the source and sink connectors in different pipelines, leveraging multiple instances of MongoDB Atlas, or enriching the data streaming in from MongoDB with other data sources.
Other popular connector combinations are less surprising. Many organizations are building pipelines from their operational databases to cloud data warehouses, data lakes, and databases for real-time ingestion. Compared to batch ETL jobs, streaming data pipelines ensure that your downstream systems are populated with real-time changes from source systems and continuously act as a source of truth to inform business decisions.
An emerging use case is building streaming data pipelines to vector stores leveraging connectors, Stream Governance, and Flink as part of a real-time retrieval augmented generation (RAG) implementation. To learn how to hydrate your vector database with the freshest data, be sure to check out our upcoming webinar on how to build a real-time RAG architecture with Confluent.
Popular single message transforms (SMTs)
Data rarely comes in a form that’s immediately useful, so we recommend using Flink to clean, process, and enrich your data streams. Kafka Connect also comes with single message transforms (SMTs) to make it convenient to perform minor, real-time data adjustments within the source or sink connector. You can also use multiple SMTs in a chain to apply transformations in order.
These are the most commonly configured SMTs on our fully managed connectors:
InsertField – Insert field using attributes from the record metadata or a configured static value.
TopicRegexRouter – Update the record topic using the configured regular expression and replacement string.
ReplaceField – Filter or rename fields.
ExtractField – Extract the specified field from a Struct when schema is present, or a Map in the case of schemaless data. Any null values are passed through unmodified.
TimestampConverter – Convert timestamps between different formats such as Unix epoch, strings, and Connect Date and Timestamp types.
You can find SMTs in the advanced configurations section of connector configurations. To learn more about SMTs and see an example in action, refer to the blog here.
First connectors deployed on Confluent Cloud
Feeling inspired and want to get started with fully managed connectors? These are the top choices for developers deploying their first connector on Confluent Cloud:
Datagen Source Connector (for development and testing)
The Datagen connector is a great place to start to quickly get sample data into Kafka for testing, but integrating your actual data sources and sinks should soon follow. To make that more seamless, we’ve streamlined the connector configuration workflow to reduce friction by adding instant configuration validations to check that your inputs are correct before proceeding to the next step. This saves you time instead of waiting for the connector to fail. In most scenarios, your cloud connector will be up and running within seconds of launching.
If you’re currently self-managing connectors, we’ve also made it seamless to migrate your connector workload to fully managed connectors with custom offset management so that you can easily cutover without duplicate data.
Most downloaded connectors on Confluent Hub
Beyond cloud connectors, organizations with on-prem and hybrid deployments may require self-managing certain connectors in their own environment due to security requirements. Confluent Hub is home to hundreds of connector plugins where you can filter by licensing type and check your deployment options.
In recent months, here are the top 10 most downloaded connectors on Confluent Hub:
The JDBC connector is the most searched and downloaded connector on Confluent Hub. It’s a Java API that streams data between relational databases and Kafka, providing a simple and flexible way to unlock data from a wide variety of databases without custom code. However, there are limitations with this connector when working with database-specific data types and issues with out-of-order messages. For a more reliable and robust alternative, Debezium CDC connectors, also high on the list, provide real-time change data capture.
A new connector gaining popularity is the Apache Iceberg® Sink Connector for writing data from Kafka to Iceberg tables. Iceberg tables have emerged as the de facto open-table standard for storing large datasets in lakehouses, with many other data companies and open source projects building an ecosystem around it. To make this even more seamless, Confluent announced our vision and early access program for Tableflow, enabling users to easily materialize Kafka topics and schemas in Iceberg tables.
Summary
This blog post explored the rankings of popular connectors across Confluent Cloud and Confluent Hub and dove deep into select connector types, common use cases, and fully managed connector features. We also covered our perspective on leveraging stream processing and governance to build reusable data products and our vision for Tableflow to sink data from Kafka to Iceberg tables easily.
If you want to learn more about connectors, be sure to register for the upcoming webinar where you can learn how to build GenAI apps faster with Confluent connectors.
Ready to get started? If you haven’t done so already, sign up for a free trial of Confluent Cloud to explore new features. New sign-ups receive $400 to spend within Confluent Cloud during their first 30 days. Use the code CL60BLOG for an additional $60 of free usage.*
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based on services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache®, Apache Kafka®, and Apache Flink® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by using these marks. All other trademarks are the property of their respective owners.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Optimizing Serverless Stream Processing with Confluent Freight Clusters and AWS Lambda
This blog outlines how to build cost-effective, high-throughput serverless streaming applications using Confluent Cloud Freight clusters for data ingestion and AWS Lambda functions for processing.


{kind=link}
{kind=link}

Confluent for VS Code Simplifies Real-Time Data Streaming Projects for Developers
We’re excited to announce that Confluent for VS Code is now Generally Available with Confluent Cloud and Confluent Platform! This integration with Visual Studio Code is open source, readily accessible on the VS Code Marketplace, and supports all forms of Apache Kafka® deployments.