Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Optimizing Supply Chains with Data Streaming and Generative AI
It’s a truism that global supply chains are complex. The process of sourcing raw materials, transforming them into finished products, and distributing them to customers encompasses numerous systems (e.g., ERPs, WMSs, and TMSs). All systems within “the supply chain” are trending in the same direction; they’re aiming to be more efficient, resilient, and agile.
Various technological developments have facilitated this directional trend. Advances in IoT sensor technology, cloud computing, and more recently, artificial intelligence, have all had an impact on supply chain systems and processes. At a more fundamental level, developments in data infrastructure have also been pivotal in the transformation of supply chains.
In this post, we’ll focus on one technology in particular—data streaming.
We’ll begin by giving an overview of the concept of data streaming, before explaining how it relates to different processes within the supply chain. We’ll then go a level deeper, exploring a high-level implementation of a use case, computer vision-aided AI stock monitoring.
What is data streaming?
Data streaming is a methodology for continuously collecting, transforming, and processing data as it is generated or received, making it available for real-time action or analysis. It differs from batch processing, which involves transforming data at periodic intervals (e.g., nightly).
Confluent is the leading enterprise-grade data streaming platform that leverages popular open source technologies, Apache Kafka® and Apache Flink®. Confluent enables organizations to stream, connect, process, and govern large volumes of heterogeneous data between different systems in real time, powering a limitless range of use cases across industries.
The role of data streaming in supply chain optimization
TL;DR: Data streaming is applicable to all stages of the supply chain.
To demonstrate, we’ve taken the following “Loop” framework from the supply chain research company, Zero100, and have mapped example applications of data streaming to each stage within it.
Innovate and plan
Accurate and timely demand forecasting requires the integration of multiple sources of data. Data streaming technologies are often used as a real-time integration layer for high volumes of data for organizations looking to improve the responsiveness to changes in demand. Walmart, for example, uses Confluent as the foundation of their real-time replenishment solution, processing billions of events daily across 100 million stock keeping units (SKUs). This enables them to automatically replenish items across a vast network of stores and distribution centers based on current stock levels, expected local demand, and other supply chain parameters.
Source
Real-time data streaming technologies are transforming how organizations approach supplier discovery and management in their supply chains, enabling more dynamic and intelligent sourcing decisions. GEP Worldwide leverages data streaming with Confluent as part of its AI-powered supply chain software platform; this includes a function which allows businesses to identify and connect with suppliers more effectively, based on previous sourcing patterns and behaviors.
Make
Confluent’s ability to reliably stream large volumes of heterogeneous data at scale with near-zero downtime makes it ideal for manufacturing applications like anomaly detection, yield management, and production control. Many organizations also use data streaming as the foundation of a predictive maintenance solution for factory equipment; sensor data (e.g., temperature, voltage, vibration, etc.) is synced to Confluent via an MQTT broker or similar, where it is processed and made available to a machine learning model. This model feeds a scoring application for the equipment, flagging it for investigation if it fails to meet a required performance threshold.
Move
Data streaming is fundamental to our most familiar transport-based applications. Uber and many food delivery applications, for example, rely on real-time data delivered by Apache Kafka to provide a positive customer experience. The same applies to transport management systems. Arcese, an Italian logistics company, uses Confluent to provide a track-and-trace service, accurate within a minute, to businesses which rely on JIT processes.
Sell
Data streaming is equally applicable to the “demand” side of the loop. Real-time data, for example, is essential for “in-session personalization” on e-commerce websites and apps; dynamic pricing, search result optimization, and personalized product recommendations all require the integration and processing of data in real time from various sources. U.K.-based electrical retailer, AO.com, increased conversion rates through their e-commerce site by 30% by delivering a hyper-personalized shopping experience to online customers with Confluent.
Use
Data streaming is also key to enabling customer support teams to provide better service after a sale has been made. This is primarily through giving them greater context into a customer’s situation or history (i.e., by integrating and making data available from multiple sources), or facilitating the automation of manual tasks. Michelin, the French tire manufacturer, uses Confluent as the basis of their post-sale customer care (among many other applications); their event-driven architecture allows them to notify customers when a tire needs replacing, or to optimize routes for fuel efficiency.
Regenerate
Lastly, data streaming is broadly applicable to a range of supply chain ESG initiatives. Data streaming can be used as the basis of real-time, automated ESG monitoring (e.g., carbon emission tracking across fleets) or as the foundation of a product lifecycle management platform (e.g., associated with the European Union’s Digital Product Passport legislation). At a broader level, it can also be used to optimize an organization’s energy consumption. The software of Tesla’s Virtual Power Plant (VPP), for instance, is based on data streaming and enables both retail and industrial customers to generate, store, and distribute renewable energy in the most efficient way possible.
Example: Computer vision-aided AI stock monitoring
Having established data streaming's crucial role across the stages of the supply chain, let's delve into a high-level technical implementation of a specific use case.
In this example, a grocery business is looking to deploy a computer vision-aided stock monitoring solution for the shop floor. Their objective is to boost sales of fresh goods which are in a sellable but “suboptimal” condition (i.e., they’re deteriorating), while reducing waste and improving the efficiency of shop floor staff.
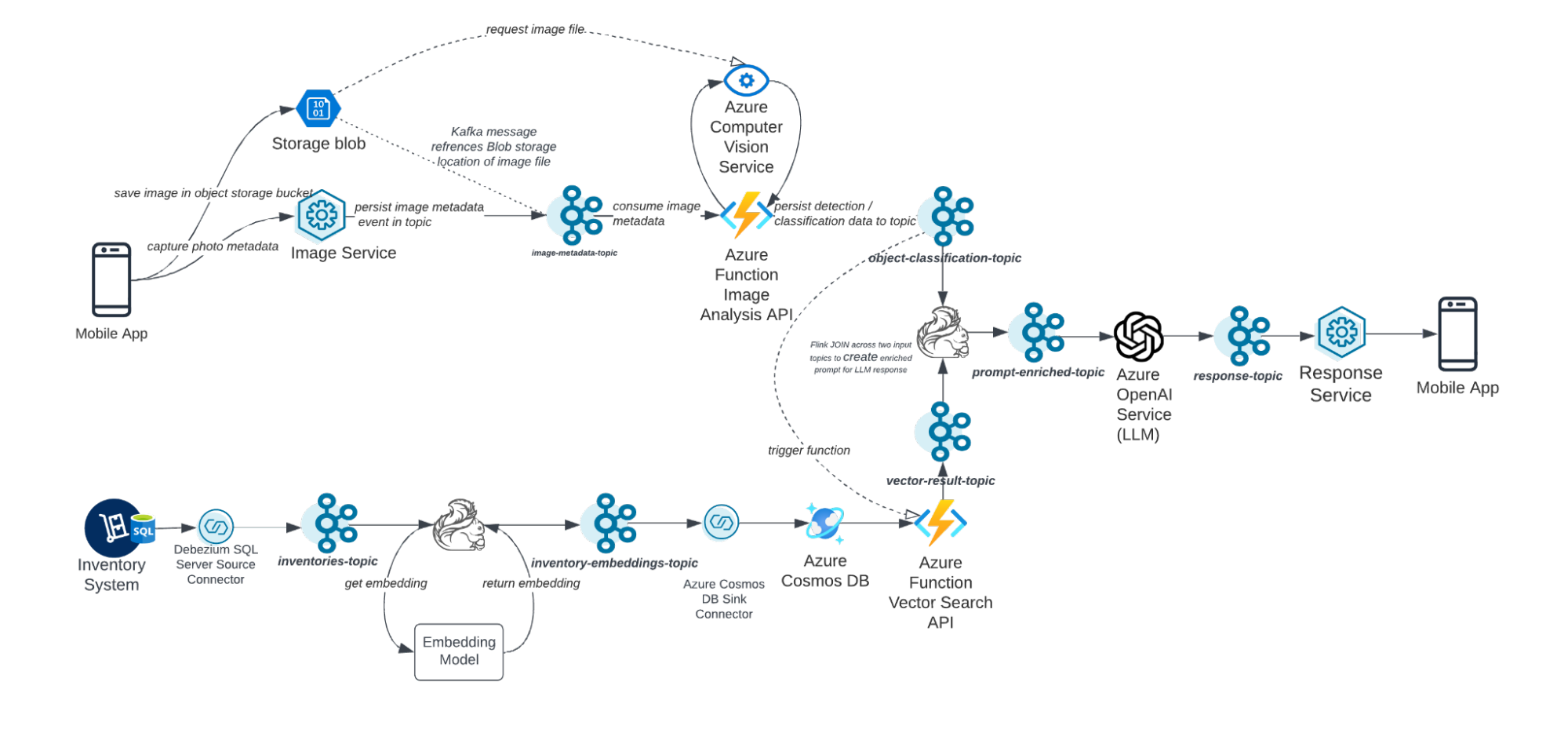
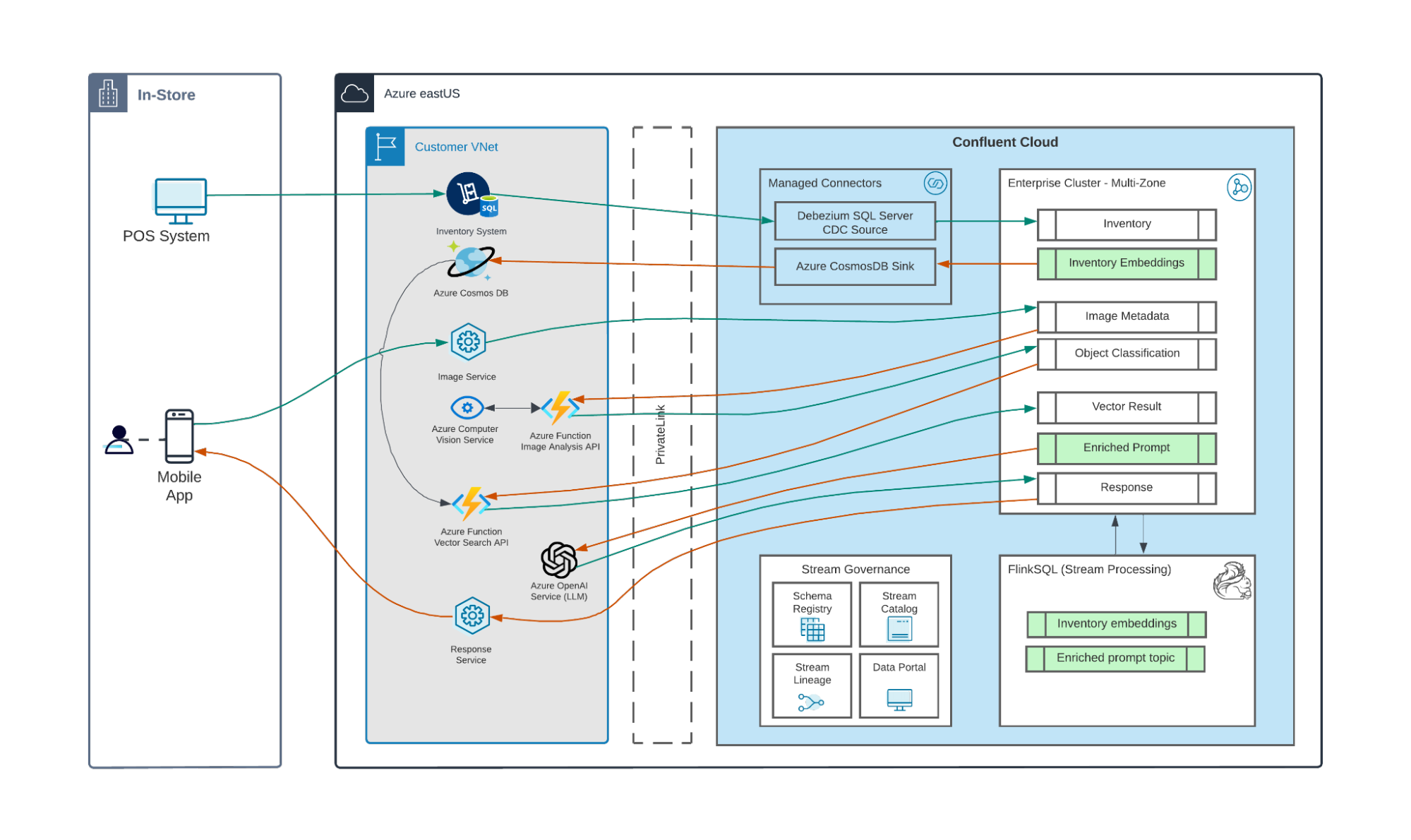
In this solution, shop assistants are equipped with a mobile device that allows them to take photos of products and receive instructions on what to do with them. Here’s a conceptual diagram of the flow of data in this solution, as well as a high-level reference architecture.
According to this flow, shop assistants use a GenAI-enabled mobile application that analyzes and synthesizes information. They first take a photo of a product or group of products. The photo’s data is streamed via Confluent to Microsoft Azure’s AI’s Vision service, which scans, identifies, and classifies (i.e., quality grades) the product in the image.
Using stream processing with Apache Flink® on Confluent, the output of Azure’s Image Analysis API is joined with real-time inventory data, which has been streamed from a SQL Server database, turned into vector embeddings using Flink AI Model Inference, and synced to a vector database in Azure Cosmos DB to enable retrieval-augmented generation (RAG). At the time of the prompt (i.e., as soon as the shop assistant submits the photo), relevant real-time inventory data is retrieved from the vector store and adds context that enables the large language model (LLM) to provide better guidance to store assistants.
The result is a prompt-enriched-topic that is sent to OpenAI via an API call, which returns a response to the shop assistant’s device. This response instructs the shop assistant on what to do with the item. Their options include: Keep, Remove (Waste), Remove (Donate), Remove (Re-use, e.g., as a primary ingredient for another product), or Discount.
With this use case built on Confluent, retail organizations avoid blanket rules for stock monitoring (e.g., “Remove any items that have been on display x no. of days”), and leverage GenAI to reduce waste, boost sales, and improve shop floor efficiency.
The importance of data streaming to supply chains
The evolution of supply chains toward increased efficiency, resilience, and agility is based on technical advancements, and data streaming is at the forefront of this transformation. As we’ve shown, data streaming is applicable to each “stage” of the supply chain, from product development and sourcing through to distribution and product regeneration. With Confluent’s data streaming platform, organizations are able to reliably stream and process large volumes of heterogeneous data from multiple sources in real time, creating “data products” that are reusable across business divisions. As supply chains continue to grow in complexity, data streaming will only play a greater role in creating a more responsive, sustainable supply chain ecosystem.
Further resources
Webpage: Revolutionizing Retail with Real-Time Data Streaming | Confluent
Webpage: Real-Time Inventory in Retail
Webpage: Powering In-Store Personalization with Data Streaming | Confluent
Online talk: How Dollar General Leverages Streaming Pipelines in Retail
Online talk: Apache Kafka® + Machine Learning for Supply Chain – Confluent
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache®, Apache Kafka®, and Apache Flink® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by using these marks. All other trademarks are the property of their respective owners.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.


{kind=link}
{kind=link}

Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.