Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Spring for Apache Kafka – Beyond the Basics: Can Your Kafka Consumers Handle a Poison Pill?
You know the fundamentals of Apache Kafka®.
You are a Spring Boot developer working with Apache Kafka or Confluent Cloud.
You have chosen Spring for Apache Kafka for your integration.
You have implemented your first producer and consumer. It’s working…hooray!
You are ready to deploy to production. What could possibly go wrong?
Well…can your Kafka application handle a poison pill? 💊💀
Curious? Read this blog post and bring your Kafka project to the next level!
Kafka and the Confluent Platform at ING
At ING, we are front runners in Kafka. ING has been running Kafka and Confluent Platform in production since 2014. Initially, Kafka was leveraged in a couple of projects, but it eventually grew into one of the most important data backbones within our organization. The power of Kafka is used for a variety of use cases within ING.
At the time of this writing, ING is:
- Running 1,800+ topics in production
- Serving 450+ development teams
- Responsible for growing traffic by 1,100% in the last couple of years
- Increasing messages per second from 20K to 220K
- Offering self-service topic management to development teams
For more information about the Kafka journey at ING, watch the Kafka Summit talk by my colleagues Timor Timuri and Filip Yonov: From Trickle to Flood with Kafka@ING.
The quality of data produced to Kafka is extremely important to us, especially because we are running Kafka at scale. Data produced by one team can and will be consumed by many different applications within the bank. The lack of quality can have a huge impact on downstream consumers.
Apache Avro™ and the Confluent Schema Registry play a big role in enforcing a contract between the producer and the consumers by defining a schema to ensure we all “speak the same language” so that all other consumers can understand at any time.
I’ll share some important lessons learned from Kafka projects within ING and focus in particular on how to configure your application to survive the “poison pill” scenario.
What is a poison pill?
Before we deep dive into the code and learn how to protect our Kafka applications against poison pills, let’s look into the definition first:
A poison pill (in the context of Kafka) is a record that has been produced to a Kafka topic and always fails when consumed, no matter how many times it is attempted.
So a poison pill can come in different forms:
- A corrupted record (I have never encountered this myself using Kafka)
- A deserialization failure
Understanding serialization and deserialization
To better understand what a deserialization failure (aka a poison pill) is and how it occurs, we need to learn about serialization and deserialization first.
According to Wikipedia, serialization is “the process of translating data structures or object state into a format that can be stored or transmitted (for example, across a network connection link) and reconstructed later (possibly in a different computer environment). The opposite operation, extracting a data structure from a series of bytes, is deserialization.”
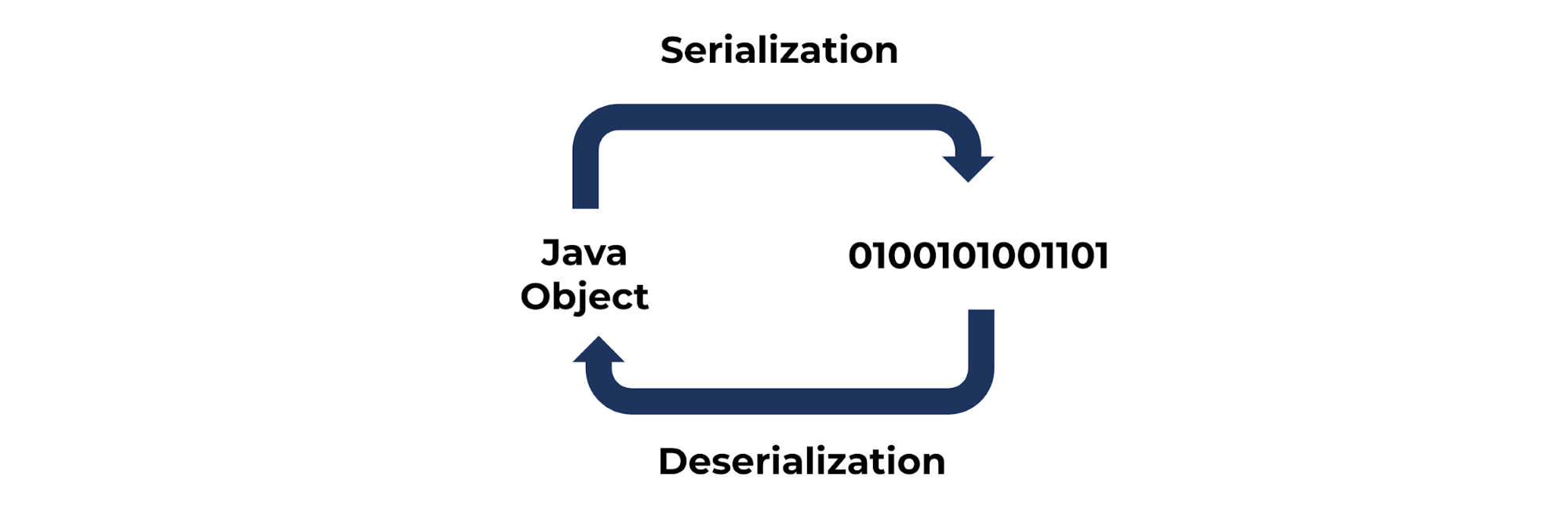
Serialization and deserialization are not limited to Java (objects). For the purposes of this blog post, I’ll focus on:
- The serialization of a Java object into a byte array that will be sent to a Kafka topic by the producer
- The deserialization of the consumed bytes from the Kafka topic into a Java object on the consumer side
What is the cause of a poison pill?
The consumer of the topic should configure the correct deserializer to be able to deserialize the bytes of the producer’s serialized Java object.
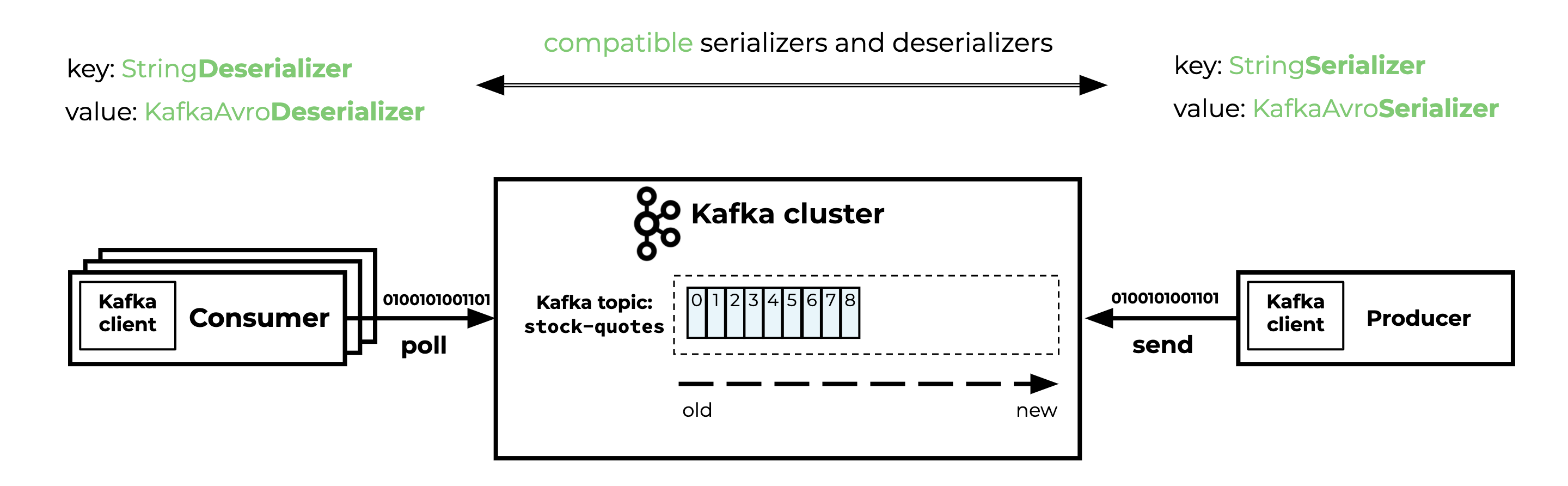
As long as both the producer and the consumer are using the same compatible serializers and deserializers, everything works fine.
You will end up in a poison pill scenario when the producer serializer and the consumer(s) deserializer are incompatible. This incompatibility can occur in both key and value deserializers.
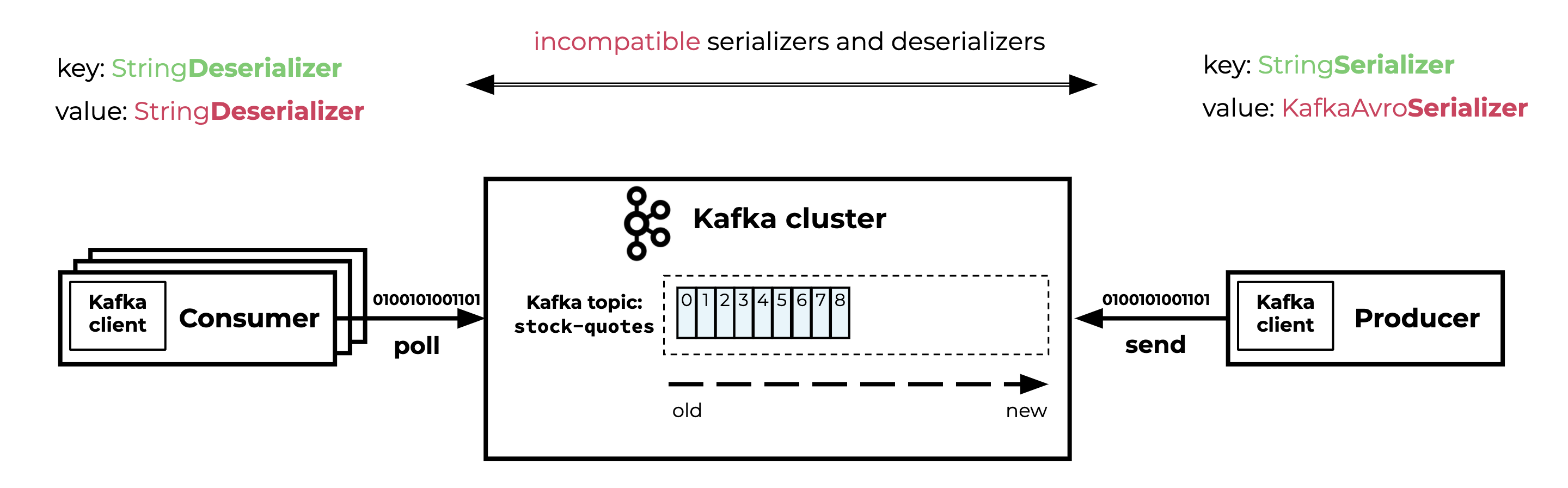
In real-life projects, I’ve encountered poison pills in scenarios where:
- The producer changed the key or value serializer and kept producing data to the same Kafka topic. This caused deserialization issues for all consumers of the topic.
- The consumer configured the wrong key or value deserializer.
- A different producer, using a different key or value serializer, started producing records to the Kafka topic.
Example project
Curious how to cause a poison pill in your local development environment? But more important, learn how to protect your consumer application by applying the configuration explained in this blogpost yourself.
You can find the example project on GitHub.
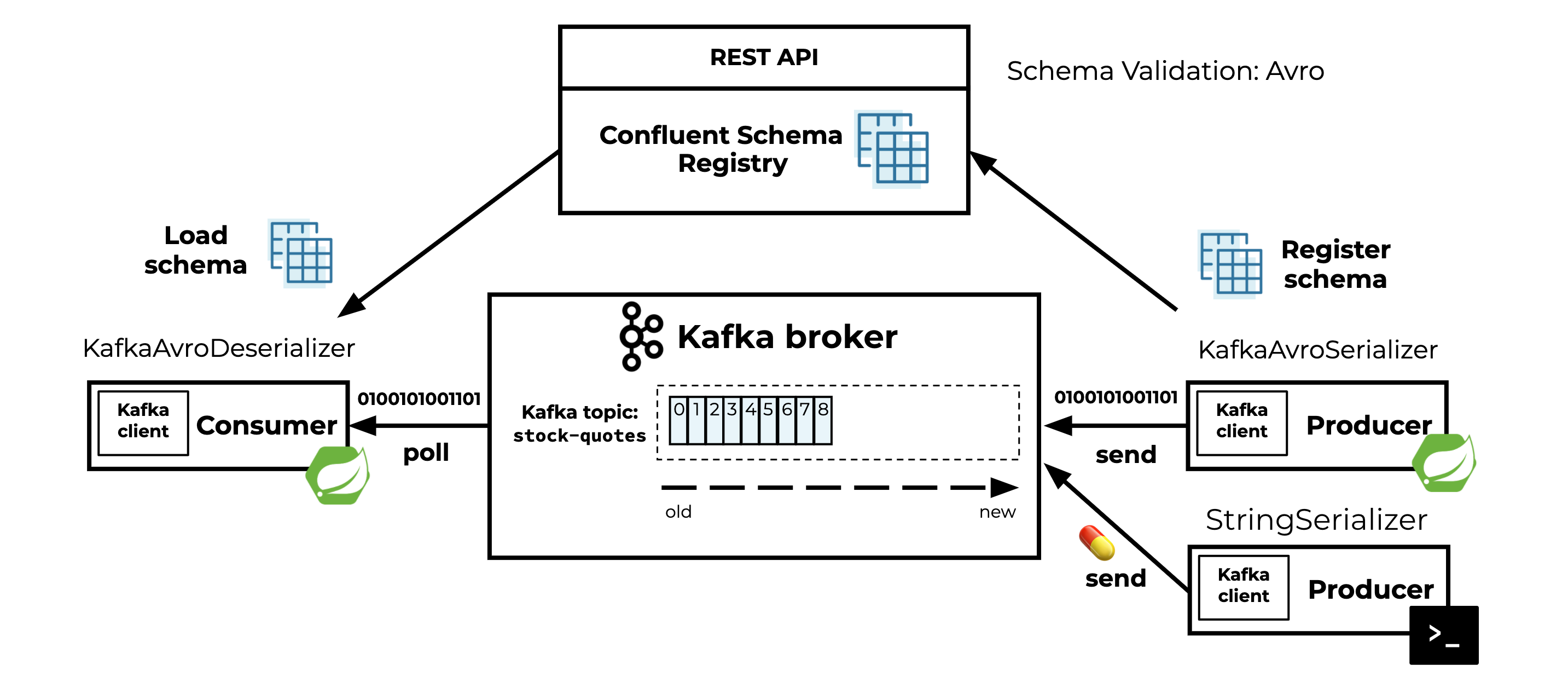
In this example project, I use the following:
- A Spring Boot application where the Kafka producer produces structured data to a Kafka topic stored in a Kafka cluster
- A Spring Boot application where the Kafka consumer consumes the data from the Kafka topic
Both the Spring Boot producer and consumer application use Avro and Confluent Schema Registry. A command line producer (not using Avro) is used to produce a poison pill and trigger a deserialization exception in the consumer application.
Serialization and deserialization in the context of Kafka
Now you understand the fundamentals of serialization and deserialization. It’s time to talk about serialization and deserialization in the context of Kafka.
The conversion from the Java object to a byte array is the responsibility of a serializer. The conversion from a byte array to a Java object that the application can deal with is the responsibility of a deserializer.
I’ll explain this by walking through the producer, the Kafka cluster, and the consumer.
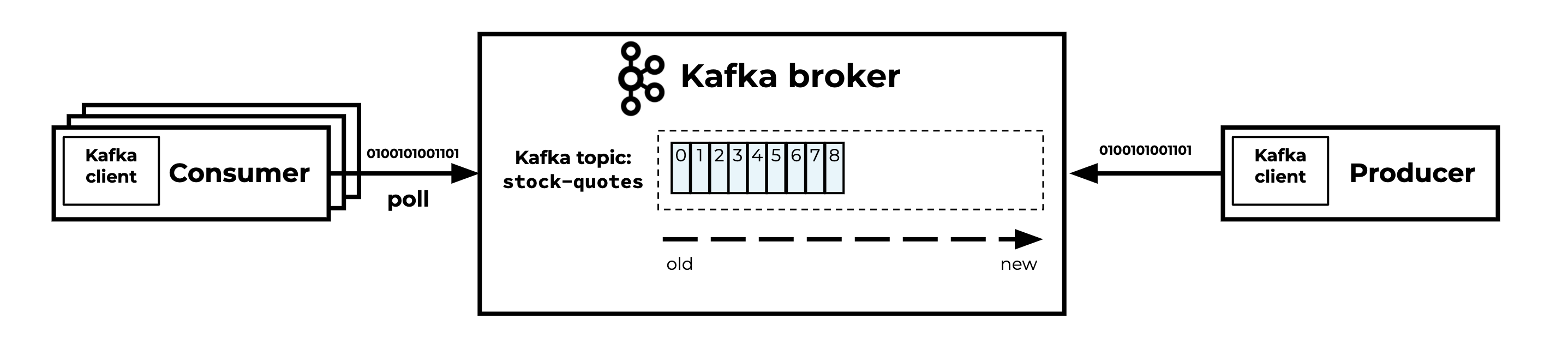
Kafka producer, cluster, and (multiple) consumers
The producer is responsible for:
- Serializing the key and value of the record into bytes
- Sending the record to the Kafka topic
The data that ends up on the Kafka topics are just bytes.
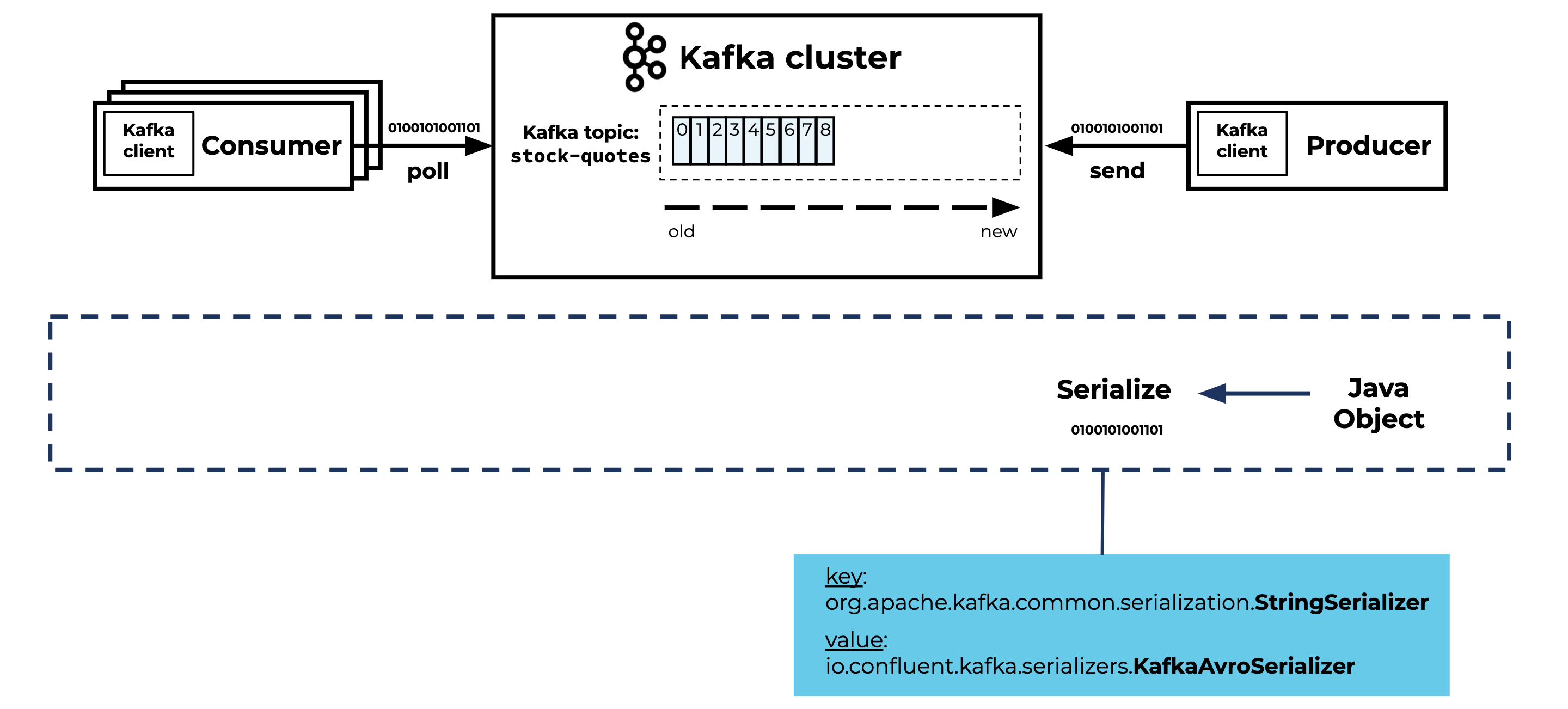
Before the producer can start sending records to the Kafka topic, you have to configure the key and value serializers in your application. Here is an example of the Kafka producer application.yml configuration for the key and value serializers, using Spring Boot and Spring Kafka:
spring:
kafka:
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
In this example, I’m using the StringSerializer and KafkaAvroSerializer, but there are many different Serializer classes to choose from. These are provided by:
- Apache Kafka (in the kafka-clients JAR)
- Confluent (in the kafka-avro-serializer JAR)
- Spring Kafka (in the spring-kafka JAR)
Choose the serializer that fits your project. You can even implement your own custom serializer if needed.
The Kafka cluster is responsible for:
- Storing the records in the topic in a fault-tolerant way
- Distributing the records over multiple Kafka brokers
- Replicating (one or multiple copies of) the records between various Kafka brokers
The Kafka cluster is not responsible for:
- Type checking
- Schema validation
- Other constraints you are used to when working with, for example, a SQL database
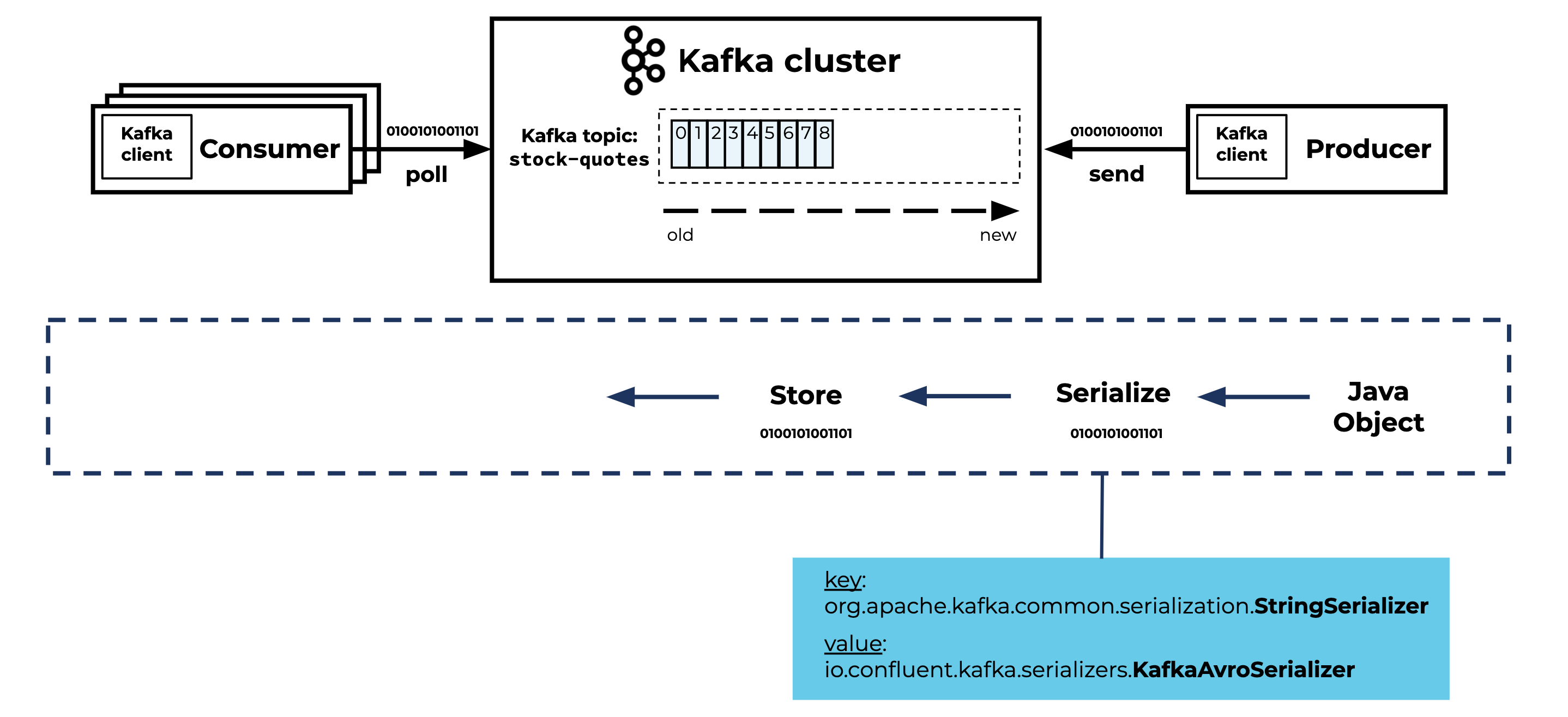
Kafka is not even aware of the structure of the data. Records in Kafka topics are stored as byte arrays. Kafka is designed to distribute bytes. That’s one of the reasons Kafka is fast and scalable.
The consumer is responsible for:
- Polling the Kafka topic
- Consuming records from the topic in micro-batches
- Deserializing the bytes into a key and value
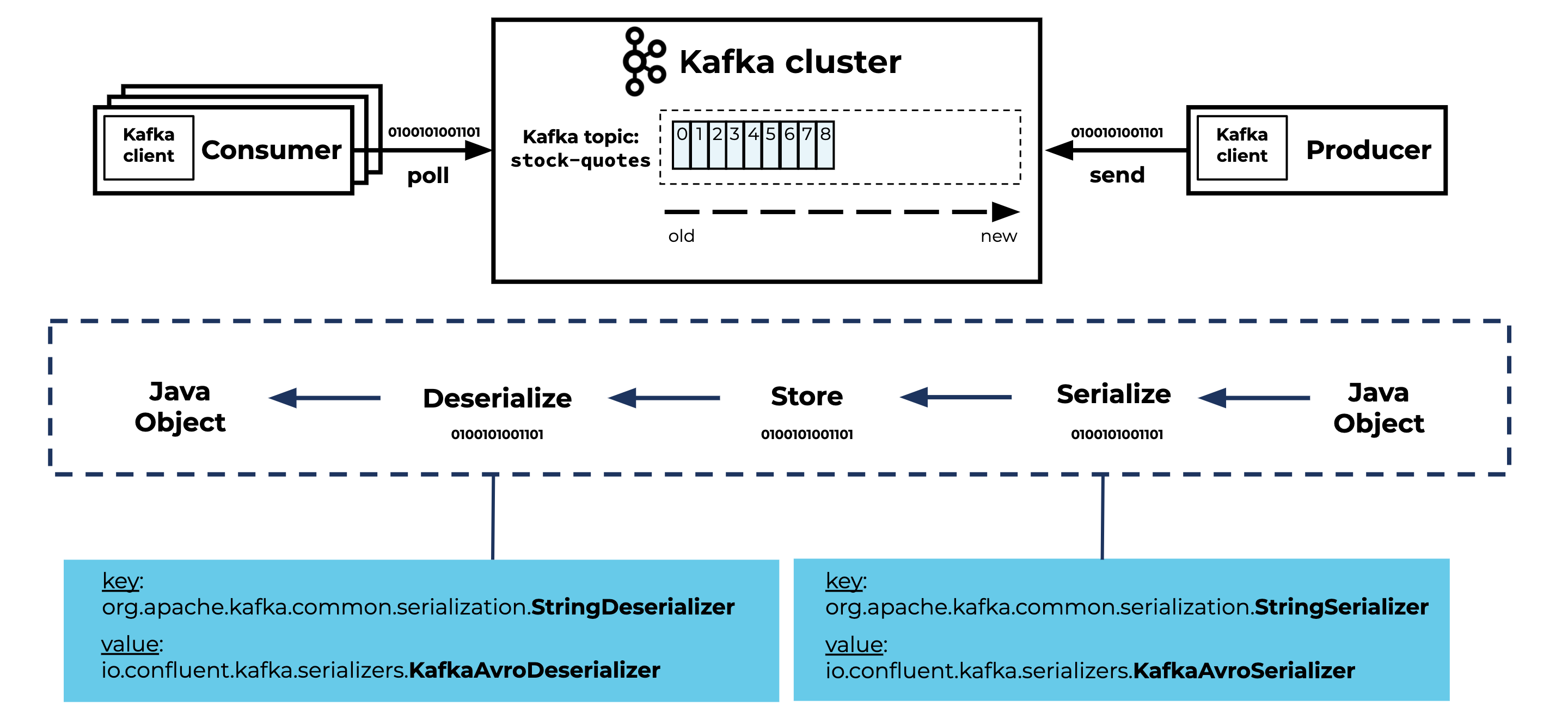
Before the consumer can start consuming records from the Kafka topic, you have to configure the corresponding key and value deserializers in your application. Here is an example of the Kafka consumer configuration application.yml for the key and value serializers using Spring Boot and Spring Kafka:
spring:
kafka:
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
As with serializers, there are many deserializers to choose from.
What can go wrong if I don’t protect my application against poison pills?
The impact of not being able to handle a poison pill in your consumer application is big. Let’s walk through what happens:

- The consumer application is consuming from a Kafka topic.
- At some point in time, the application can’t deserialize a record (it encounters a poison pill).
- The consumer is not able to handle the poison pill.
- The consumption of the topic partition is blocked because the consumer offset is not moving forward.
- The consumer will try again and again (very rapidly) to deserialize the record but will never succeed. So your consumer application will end up in an endless loop trying to deserialize the failing record.
- For every failure, a line is written to your log file…oops!
java.lang.IllegalStateException: This error handler cannot process 'SerializationException's directly; please consider configuring an 'ErrorHandlingDeserializer' in the value and/or key deserializer
at org.springframework.kafka.listener.SeekUtils.seekOrRecover(SeekUtils.java:145) ~[spring-kafka-2.5.0.RELEASE.jar!/:2.5.0.RELEASE]
at org.springframework.kafka.listener.SeekToCurrentErrorHandler.handle(SeekToCurrentErrorHandler.java:103) ~[spring-kafka-2.5.0.RELEASE.jar!/:2.5.0.RELEASE]
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.handleConsumerException(KafkaMessageListenerContainer.java:1241) ~[spring-kafka-2.5.0.RELEASE.jar!/:2.5.0.RELEASE]
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:1002) ~[spring-kafka-2.5.0.RELEASE.jar!/:2.5.0.RELEASE]
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) ~[na:na]
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[na:na]
at java.base/java.lang.Thread.run(Thread.java:834) ~[na:na]
Caused by: org.apache.kafka.common.errors.SerializationException: Error deserializing key/value for partition stock-quotes-avro-1 at offset 69. If needed, please seek past the record to continue consumption.
Caused by: org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
What are the consequences?
Your consumer application can quickly write gigabytes of log files to disk if you don’t notice in time. You might also ship the logs automatically to a log aggregation tool like the ELK stack (Elasticsearch, Logstash, and Kibana).
In case you don’t have proper monitoring in place, at some point, you might “eat” all of your server disk space. And in the worst-case scenario, you might also have other services running on the same machine, and they will start reporting as unhealthy because of a full disk!
How can you survive a poison pill scenario?
There are a couple of ways to survive the poison pill scenario:
- 👎 Wait until the retention period of the Kafka topic has passed. If your Kafka topic has a retention policy configured, you can wait until that time has passed to make sure that the poison pill is gone. But you’ll also lose all of the records that were produced to the Kafka topic after the poison pill during the same retention period. In real-life scenarios, this is a no-go!
- 👎 Change the consumer group. You can change the consumer group and start consuming from the head of the log (start consuming the next record written to the topic). In this case, you won’t consume the records between the poison pill and the last written record in the topic. So this is a no-go as well!
- 👎 Manually/programmatically update the offset. You can do this, but it’s not trivial. You have to know the offset of the poison pill and start consuming the next record after the poison pill. What if there is another poison pill down the line?
- 👍 Spring Kafka to the rescue! Configure the ErrorHandlingDeserializer. This is the way to go. Read on to learn how to configure your consuming application.
Solving the problem using Spring Kafka’s ErrorHandlingDeserializer
From the Spring Kafka reference documentation:
When a deserializer fails to deserialize a message, Spring has no way to handle the problem, because it occurs before the poll() returns. To solve this problem, the ErrorHandlingDeserializer has been introduced. This deserializer delegates to a real deserializer (key or value). If the delegate fails to deserialize the record content, the ErrorHandlingDeserializer returns a null value and a DeserializationException in a header that contains the cause and the raw bytes. When you use a record-level MessageListener, if the ConsumerRecord contains a DeserializationException header for either the key or value, the container’s ErrorHandler is called with the failed ConsumerRecord. The record is not passed to the listener.
The idea behind the ErrorHandlingDeserializer is simple, but the first time I had to configure it, it took me some time to wrap my head around.
For both our key and value deserializers, configure the ErrorHandlingDeserializer provided by Spring Kafka.
The ErrorHandlingDeserializer will delegate to the real deserializers (key and value). We have to “tell” the ErrorHandlingDeserializer:
- The key deserializer class (spring.deserializer.key.delegate.class)
- The value deserializer class (spring.deserializer.value.delegate.class)
In this example:
- spring.deserializer.key.delegate.class is the StringDeserializer
- spring.deserializer.value.delegate.class is the KafkaAvroDeserializer
Here how you can configure the ErrorHandlingDeserializer in your application.yml:
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
# Configures the Spring Kafka ErrorHandlingDeserializer that delegates to the 'real' deserializers
key-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
value-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer
properties:
# Delegate deserializers
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializer
spring.deserializer.value.delegate.class: io.confluent.kafka.serializers.KafkaAvroDeserializer
Now, when either the key or value delegate fails to deserialize a poison pill, the ErrorHandlingDeserializer returns a null value and adds a DeserializationException in a header containing the cause and the raw bytes.
If the ConsumerRecord contains a DeserializationException header for either the key or the value, the container’s ErrorHandler is called with the failed ConsumerRecord, and the record is not passed to the listener (the class or method annotated with @KafkaListener).
By default, the container’s error handler is the SeekToCurrentErrorHandler. By configuring the LoggingErrorHandler, we can log the content of the poison pill.
Here is an example to configure the LoggingErrorHandler:
@Configuration
@EnableKafka
public class KafkaConfiguration {
/**
* Boot will autowire this into the container factory.
*/
@Bean
public LoggingErrorHandler errorHandler() {
return new LoggingErrorHandler();
}
}
To make a long story short, the ErrorHandlingDeserializer ensures that the poison pill is handled and logged. The consumer offset moves forward so that the consumer can continue consuming the next record.
Hooray—you survived the poison pill scenario!
Here’s an example of a log message (some lines omitted for readability) proving that a poison pill has been handled:
ERROR 249817 --- [ntainer#0-0-C-1] o.s.kafka.listener.LoggingErrorHandler : Error while processing: ConsumerRecord(topic = stock-quotes-avro, partition = 0, leaderEpoch = 0, offset = 2420, CreateTime = 1591374339091, serialized key size = -1, serialized value size = 4, headers = RecordHeaders(headers = [RecordHeader(key = springDeserializerExceptionValue, value = [-84, -19, 0, 5, 115, 114, 0, 69, 111, 114, 103, 46, 115, 112, 114, 105, 110, 103, 102, 114, 97, 109, 101, 119, 111, 114, 107, 46, 107, 97, 102, 107, 46, 107, 97, 102, 107, 97, 46, 75, 97, 102, 107, 97, 69, 120, 99, 101, 112, 116, 105, 111, 110, 36, 76, 101, 118, 101, 108, 0, 0, 0, 0, 0, 0, 0, 0, 18, 0, 0, 120, 114, 0, 14, 106, 97, 118, 97, 46, 108, 97, 110, 103, 46, 69, 110, 117, 109, 0, 0, 0, 0, 0, 0, 0, 0, 18, 0, 0, 120, 112, 116, 0, 5, 69, 82, 82, 79, 82, 0, 117, 114, 0, 2, 91, 66, -84, -13, 23, -8, 6, 8, 84, -32, 2, 0, 0, 120, 112, 0, 0, 0, 4, 112, 105, 108, 108])], isReadOnly = false), key = null, value = null)
org.springframework.kafka.listener.ListenerExecutionFailedException: Listener failed; nested exception is org.springframework.kafka.support.serializer.DeserializationException: failed to deserialize; nested exception is org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.decorateException(KafkaMessageListenerContainer.java:1882) ~[spring-kafka-2.5.0.RELEASE.jar:2.5.0.RELEASE]
at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.pollAndInvoke(KafkaMessageListenerContainer.java:1045) ~[spring-kafka-2.5.0.RELEASE.jar:2.5.0.RELEASE]
... 4 common frames omitted
Caused by: org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
Warning: If you are using Spring Kafka’s BatchMessageListener to consume and process records from a Kafka topic in batches, you should take a different approach. Check out the Spring Kafka reference documentation for details.
Publishing to a dead letter topic
In many cases, logging the deserialization exception is good enough but makes examining a poison pill harder later on. Since Spring Kafka 2.3, you can configure a ErrorHandlingDeserializer in combination with a DeadLetterPublishingRecoverer and SeekToCurrentErrorHandler to publish the value of the poison pill to a dead letter topic.
Here is an example to configure it:
@Configuration
@EnableKafka
public class KafkaConfiguration {
/**
* Boot will autowire this into the container factory.
*/
@Bean
public SeekToCurrentErrorHandler errorHandler(DeadLetterPublishingRecoverer deadLetterPublishingRecoverer) {
return new SeekToCurrentErrorHandler(deadLetterPublishingRecoverer);
}
/**
*
* Configure the {@link DeadLetterPublishingRecoverer} to publish poison pill
* bytes to a dead letter topic:
* "stock-quotes-avro.DLT".
*
*/
@Bean
public DeadLetterPublishingRecoverer publisher(KafkaTemplate bytesTemplate) {
return new DeadLetterPublishingRecoverer(bytesTemplate);
}
}
This gives you the flexibility to consume the poison pill and inspect the data. Spring Kafka will send the dead letter record to a topic named <originalTopicName>.DLT (the name of the original topic suffixed with .DLT) and to the same partition as the original record.
Be aware that your consumer application becomes a producer as well so you need to configure the key and value serializers in your configuration (application.yml):
spring:
kafka:
producer:
# Important!
# In case you publish to a 'dead letter topic' you consumer application becomes
# a producer as well! So you need to specify the producer properties!
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.ByteArraySerializer
Main takeaways
- Expect the unexpected
- Prepare your Spring Boot consumer applications to be able to handle a poison pill by configuring the Spring Kafka ErrorHandlingDeserializer
- Leverage the DeadLetterPublishingRecoverer to inspect and recover poison pills after the fact
- If you are writing a producer application, don’t change its key and/or value serializers
- Leverage Avro and the Confluent Schema Registry to enforce a contract between the producer and the consumers by defining a schema
- Restrict write access to your Kafka topics. Make sure that no one except your producers can produce data
If you’d like to learn more, check out my Kafka Summit talk, where I discuss this topic in more detail. To get started with Spring using fully managed Apache Kafka as a service, you can sign up for Confluent Cloud and use the promo code SPRING200 for an additional $200 of free Confluent Cloud usage.*
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


