Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper
At the heart of Apache Kafka® sits the log—a simple data structure that uses sequential operations that work symbiotically with the underlying hardware. Efficient disk buffering and CPU cache usage, prefetch, zero-copy data transfers, and many other benefits arise from the log-centric design, leading to the high efficiency and throughput that it is known for. For those new to Kafka, the topic—and its underlying implementation as a commit log—is often the first thing they learn about.
But the code for the log itself makes up a comparatively small part of the system as a whole. A far larger proportion of Kafka’s codebase is responsible for arranging partitions (i.e., logs) across the many brokers in a cluster, allocating leadership, handling failures, etc. This is the code that makes Kafka a reliable and trusted distributed system.
Historically, Apache ZooKeeper was a critical part of how this distributed code worked. ZooKeeper provided the authoritative store of metadata holding the system’s most important facts: where partitions live, which replica is the leader, and so forth. The use of ZooKeeper made sense early on—it is a powerful and proven tool. But ultimately, ZooKeeper is a somewhat idiosyncratic filesystem/trigger API on top of a consistent log. Kafka is a pub/sub API on top of a consistent log. This led those operating the system to tune, configure, monitor, secure, and reason about communication and performance across two log implementations, two network layers, and two security implementations, each with distinct tools and monitoring hooks. It became unnecessarily complex. This inherent and unavoidable complexity spurred a recent initiative to replace ZooKeeper with an internal quorum service that runs entirely inside Kafka itself.
Of course, replacing ZooKeeper is a sizable piece of work and last April we started a community initiative to accelerate the schedule and deliver a working system by the end of the year.
I just sat with Jason, Colin and the KIP-500 team and went through a full Kafka server lifecycle, produce, consume and all Zookeeper-free. Pretty darn sweet!
— Ben Stopford (@benstopford) December 15, 2020
So we’re very pleased to say that the early access of the KIP-500 code has been committed to trunk and is expected to be included in the upcoming 2.8 release. For the first time, you can run Kafka without ZooKeeper. We call this the Kafka Raft Metadata mode, typically shortened to KRaft (pronounced like craft) mode.
Beware, there are some features that are not available in this early-access release. We do not yet support the use of ACLs and other security features or transactions. Also, both partition reassignment and JBOD are unsupported in KRaft mode (these are anticipated to be available in an Apache Kafka release later in the year). Hence, consider the quorum controller experimental software—we don’t advise subjecting it to production workloads. If you do try out the software, however, you’ll find a host of new advantages: It’s simpler to deploy and operate, you can run Kafka in its entirety as a single process, and it can accommodate significantly more partitions per cluster (see measurements below).
The quorum controller: Event-driven consensus
If you opt to run Kafka using the new quorum controller, all metadata responsibilities previously undertaken by the Kafka controller and ZooKeeper are merged into this one new service, running inside the Kafka cluster itself. The quorum controller can also run on dedicated hardware should you have a use case that demands it.
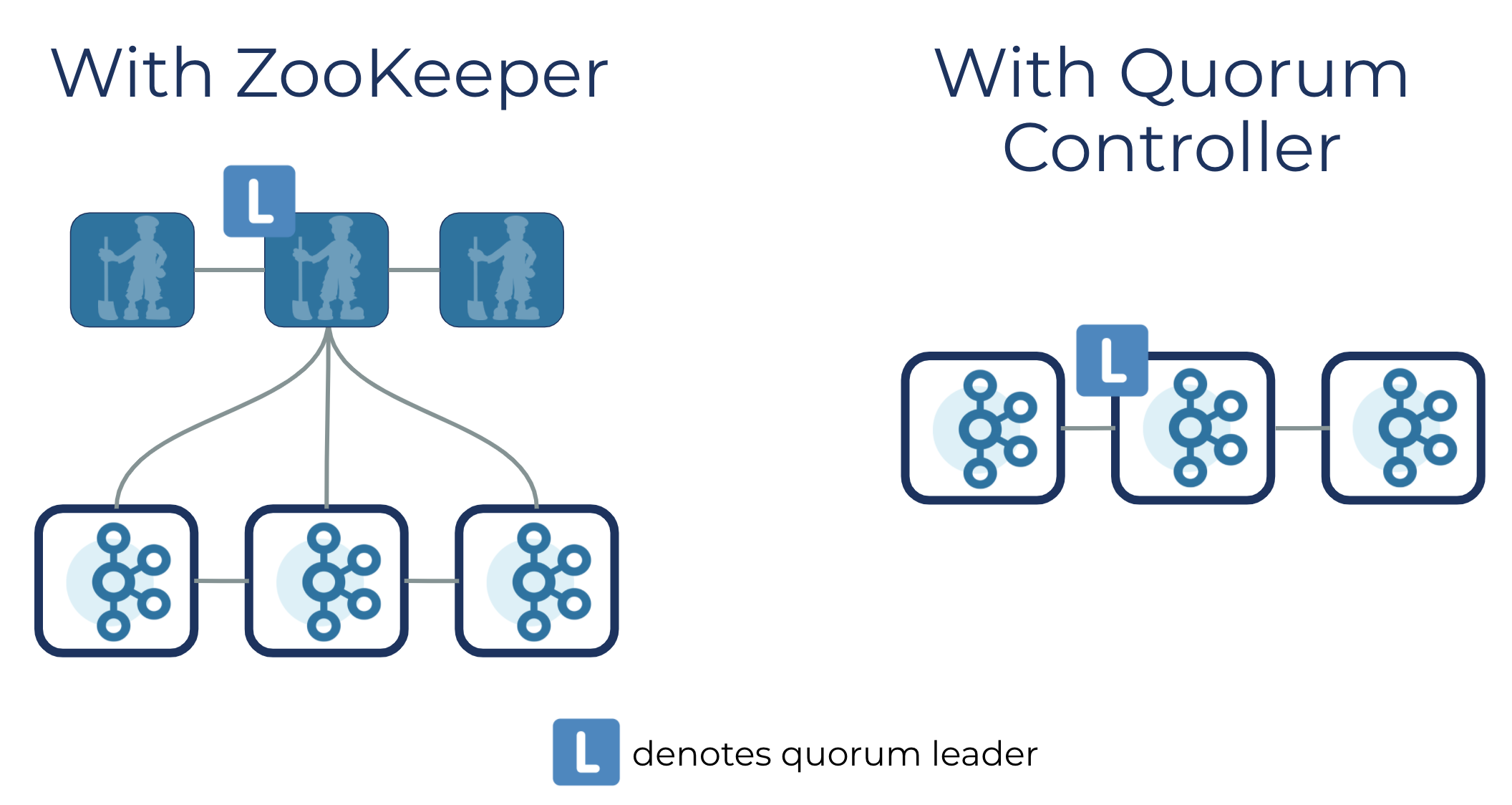
Internally, though, it gets interesting. The quorum controllers use the new KRaft protocol to ensure that metadata is accurately replicated across the quorum. This protocol is similar in many ways to ZooKeeper’s ZAB protocol, and to Raft, but has some important differences, one notable and befitting one being its use of an event-driven architecture.
The quorum controller stores its state using an event-sourced storage model, which ensures that the internal state machines can always be accurately recreated. The event log used to store this state (also known as the metadata topic) is periodically abridged by snapshots to guarantee that the log cannot grow indefinitely. The other controllers within the quorum follow the active controller by responding to the events that it creates and stores in its log. Thus, should one node pause due to a partitioning event, for example, it can quickly catch up on any events it missed by accessing the log when it rejoins. This significantly decreases the unavailability window, improving the worst-case recovery time of the system.
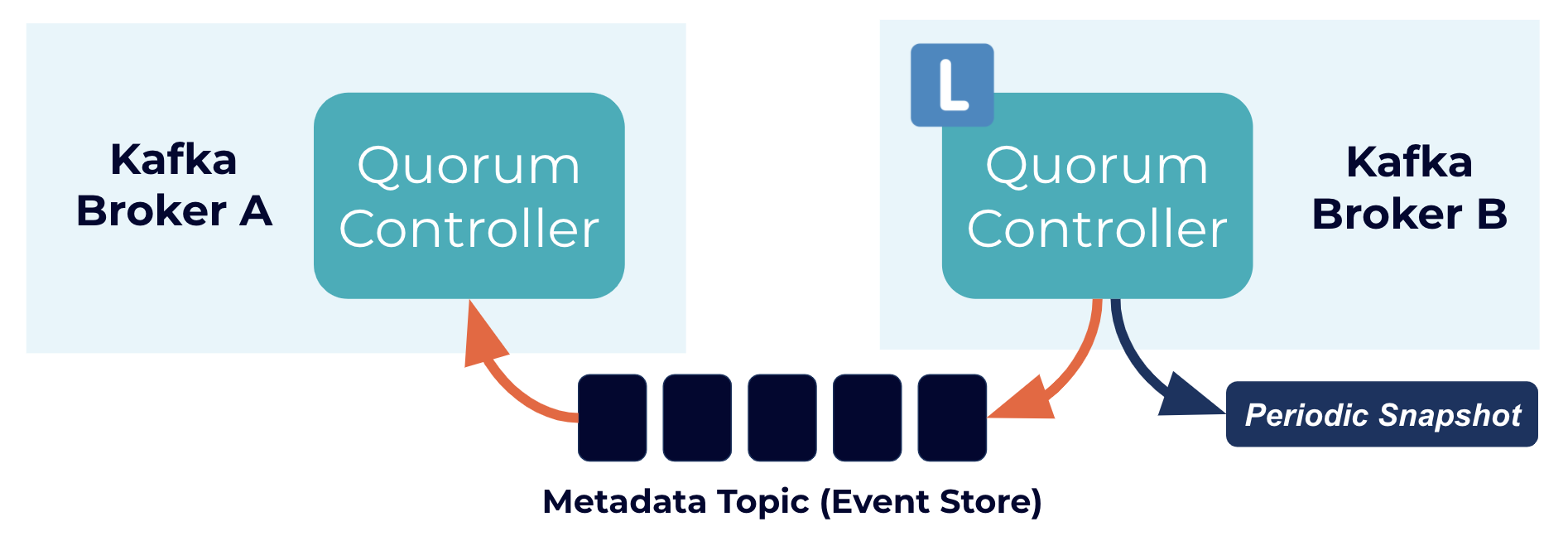
Event-driven consensus internals
The event-driven nature of the KRaft protocol means that, unlike the ZooKeeper-based controller, the quorum controller does not need to load state from ZooKeeper before it becomes active. When leadership changes, the new active controller already has all of the committed metadata records in memory. What’s more, the same event-driven mechanism used in the KRaft protocol is used to track metadata across the cluster. A task that was previously handled with RPCs now benefits from being event-driven as well as using an actual log for communication. A pleasant consequence of these changes—and ones that were very much baked into the original design—is that Kafka can now support many more partitions than it previously could. Let’s discuss that in more detail.
Scaling Kafka up: Supporting millions of partitions
The number of partitions that a Kafka cluster can support is determined by two properties: the per-node partition count limit and the cluster-wide partition limit. Both are interesting, but to date, metadata management has been the main bottleneck for the cluster-wide limitation. Previous Kafka Improvement Proposals (KIPs) have improved the per-node limit, although there is always more that can be done. But Kafka’s scalability depends primarily on adding nodes to get more capacity. This is where the cluster-wide limit becomes important as it defines the upper bounds of scalability within the system.
The new quorum controller is designed to handle a much larger number of partitions per cluster. To evaluate this, we ran tests similar to those run previously in 2018 to publicise Kafka’s inherent partition limits. These tests measure the time taken by shutdown and recovery, which is an O(#partitions) operation for the old controller. It is this operation that places an upper bound on the number of partitions that Kafka can support in a single cluster today.
The previous implementation, as Jun Rao explained in the post referenced above, could achieve 200K partitions, with the limiting factor being the time taken to move critical metadata between the external consensus (ZooKeeper) and internal leader management (the Kafka controller). With the new quorum controller, both of these roles are served by the same component. The event-driven approach means that controller failover is now near-instantaneous. Below are the summary numbers for a cluster running 2 million partitions (10x the previous upper bound) executed in our lab: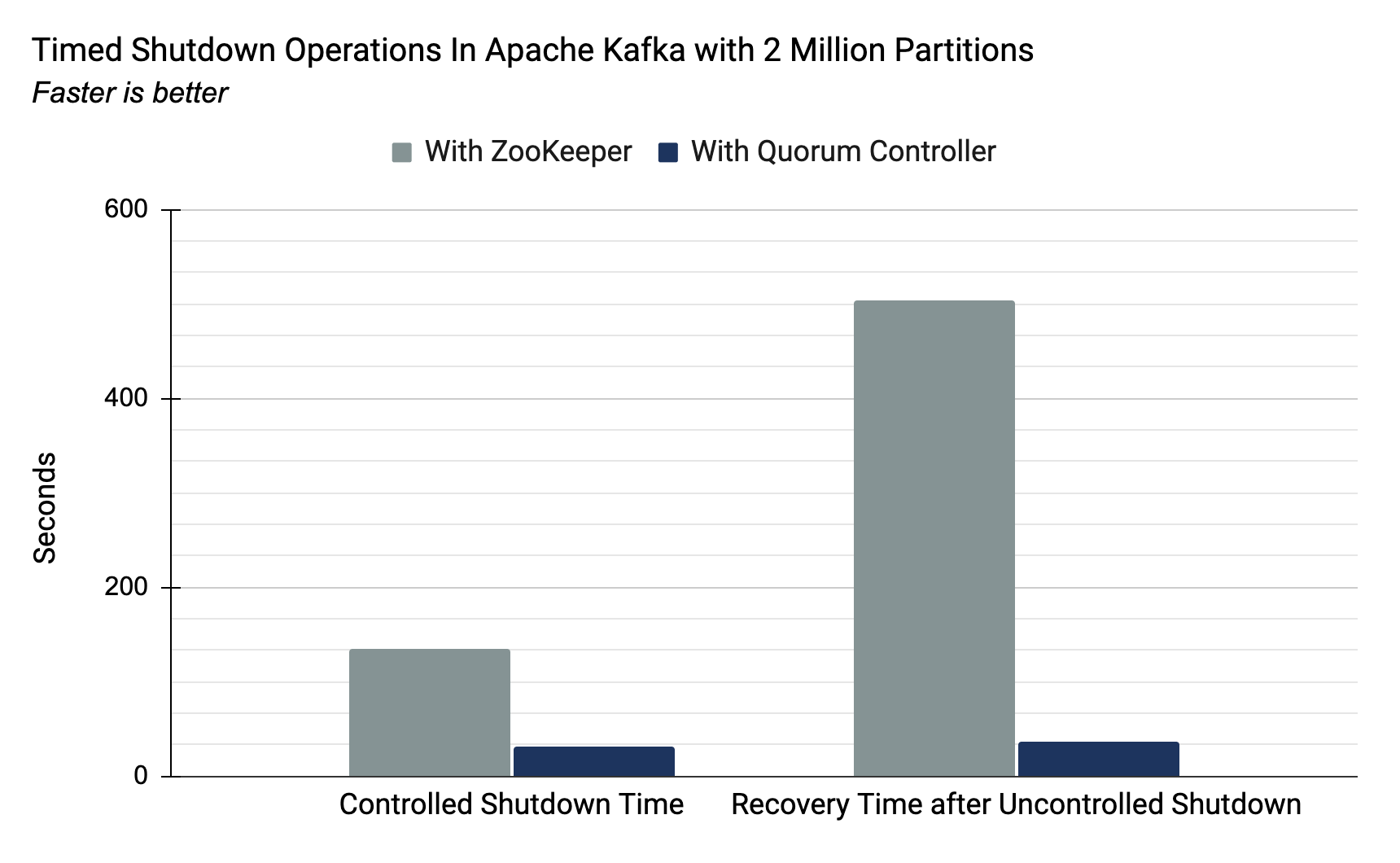
| With ZooKeeper-Based Controller | With Quorum Controller | |
| Controlled Shutdown Time (2 million partitions) |
135 sec. | 32 sec. |
| Recovery from Uncontrolled Shutdown (2 million partitions) | 503 sec. | 37 sec. |
Both measures for controlled and uncontrolled shutdown are important. Controlled shutdowns impact common operational scenarios, such as a rolling restart: the standard procedure for deploying software changes while maintaining availability throughout. Recovery from uncontrolled shutdowns is arguably more important as it sets the recovery time objective (RTO) of the system, say, after an unexpected failure, such as a VM or pod crashing or a data centre becoming unavailable. While these measures are only indicators of broader system performance, they directly measure the well-known bottleneck that ZooKeeper’s use imposes.
Note that the controlled and uncontrolled measurements are not directly comparable. The uncontrolled shutdown case includes the time taken for new leaders to be elected, while the controlled case does not. This disparity is deliberate to keep the controlled case in line with Jun Rao’s original measurements.
Scaling Kafka down: Kafka as a single process
Kafka has often been perceived as heavyweight infrastructure and the complexity of managing ZooKeeper—a second, separate distributed system—is a big part of why this perception exists. This often leads projects to opt for a lighter-weight message queue when they are starting out—say a traditional queue like ActiveMQ or RabbitMQ—and moving to Kafka when their scale demands it.
This is unfortunate because the abstraction that Kafka provides, formed around a commit log, is just as applicable to the small-scale workloads you might see at a startup as it is to the high-throughput ones at Netflix or Instagram. What is more, if you want to add stream processing, you need Kafka and its commit log abstraction, whether it’s using Kafka Streams, ksqlDB, or another stream processing framework. But because of the complexity of managing two separate systems—Kafka and Zookeeper—users often felt they had to choose between scale or ease of getting started.
This is no longer the case. KIP-500 and the KRaft mode provide a great, lightweight way to get started with Kafka or use it as an alternative to monolithic brokers like ActiveMQ or RabbitMQ. The lightweight, single-process deployment is also better suited to edge scenarios and those that use lightweight hardware. Cloud adds an interesting, tangential angle to the same problem. Managed services like Confluent Cloud remove the operational burden entirely. So, whether you’re looking to run your own cluster, or have it run for you, you can start small and grow to (potentially) massive scale as your underlying use case expands—all with the same infrastructure. Let’s see what that looks like for a single-process deployment.
Taking ZooKeeper-less Kafka for a spin
The new quorum controller is available in trunk today in experimental mode and is expected to be included in the upcoming Apache Kafka 2.8 release. So what can you do with it? As mentioned, one simple but very cool new feature is the ability to create a single process Kafka cluster as the short demo below shows.
Of course, if you want to scale that out to support higher throughputs and add replication for fault tolerance, you just need to add new broker processes. As you know, this is an early access release of the KRaft-based quorum controller. Please don’t use it for critical workloads. Over the next few months, we’ll be adding the final missing pieces, performing TLA+ modeling of the protocol, and hardening the quorum controller in Confluent Cloud.
You can try the new quorum controller out for yourself right now. See the full README on GitHub.
The team behind it
This has been (and continues to be) a huge effort that would not have been possible without the Apache Kafka community and a group of distributed systems engineers who worked tirelessly during a pandemic to go from zero to a working system in about nine months. We want to extend a special thank you to Colin McCabe, Jason Gustafson, Ron Dagostino, Boyang Chen, David Arthur, Jose Garcia Sancio, Guozhang Wang, Alok Nikhil, Deng Zi Ming, Sagar Rao, Feyman, Chia-Ping Tsai, Jun Rao, Heidi Howard, and all members of the Apache Kafka community who have helped make this happen.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


