Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Getting Started with Rust and Apache Kafka
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark, which you are welcome to read about in my previous blog post explaining the story behind this open source example. As a next step, specifically for this article I’ve added SSL and combined some topics together, using the subject name strategy option of Confluent Schema Registry, making it more production like, adding security, and making it possible to put multiple kinds of commands on one topic. We will examine how the application works, and what was needed to change one of the components from Clojure to Rust. We’ll also take a look at some performance tests to see if Rust might be a viable alternative for Java applications using Apache Kafka®.
The bank application
The bank application simulates an actual bank where you can open an account and transfer money. Alternatively, you can get money into the system by simply depositing money with the push of a button. Either way, both are accomplished with event sourcing. In this case, that means a command is created for a particular action, which will be assigned to a Kafka topic specific for that action. Each command will eventually succeed or fail. The result will be put on another topic, in which case a failed response would contain a reason for the failure, and the successful response might contain additional information. Processing the commands can cause derived events—events that happened because a command was executed. This happens when money is successfully transferred from one bank account to another. In this example, the balance of two accounts have been changed, creating a balance-changed event and putting it on another topic.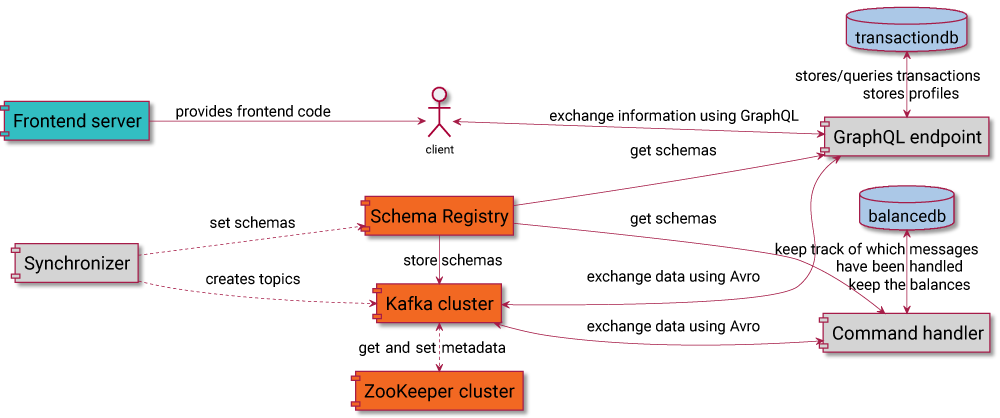
Here, the orange pieces are part of the Confluent Platform, while the gray ones are small Clojure or Rust applications. The blue parts represent PostgreSQL databases, and turquoise is a Nginx web server. All messages use a String for the key and Avro for the value. In this setup, the schemas are set with the synchronizer, which also creates the topics. This makes it easy to automate since all the components of the application are Dockerized, and it contains scripts for easily setting up and testing the application.
GraphQL is used to handle the interaction between frontend and backend. By filling out a form on the frontend, either a ConfirmAccountCreation or ConfirmMoneyTransfer event is sent to the backend, and the feedback is passed to the frontend again. The events are handled by the command handler, which is the part of the system that has been ported to Rust. Later, the changes in the frontend will be used to measure end-to-end latency.
Note that the picture does not display a module called Topology, which is included in all Clojure applications as a dependency and contains a description of both the schemas and the topics, along with information about which schemas are used for which topic. The Synchronizer needs this to set the schemas correctly in the Schema Registry, according to the TopicRecordNameStrategy. It allows for different schemas within one topic and for the Schema Registry to check if new schemas are compatible.
The schemas are also useful for generating specific Java classes. Using Java interop, these classes make working with the data in Clojure easier. They offer several functions that are included in Topology and can be used in different applications, such as getting a Java UUID from the fixed bytes ID in the schema. Also, there are several functions wrapping the Java clients for Kafka. Depending on environment variables and whether SSL is set or not, it takes care of setting the configuration (like the serializers) as well.
A short introduction to Rust
On May 15, 2015, the Rust Core Team released version 1.0 of Rust. Since then, it’s made it possible to build libraries, called crates in Rust, that are compatible with the latest version of Rust. This works because Rust strives to be backwards compatible. By building on top of the crates that already exist, crates with a higher level of abstraction can be created. Although Rust is a system programming language, you can indeed use it to write applications at a level that are relatively on par with that of Java.
Rust is a compiled language, so code needs to be compiled first in order to be executed. Several IDEs with support for Rust exist, but in this blog post, I only use the Rust plugin for IntelliJ IDEA. It behaves a lot like you were using Java, since it can auto-import, make it easy to rename functions, and has been validated. It’s also easy to run Clippy from IntelliJ, a linter that suggests improvements, which is especially useful while learning Rust. Most errors are caught when compiling the program. Debugging IntelliJ is impossible, so for the remaining errors, you either need helpful log statements or you need to inspect the code.
Clojure command handler
The command handler has two external connections to Kafka and PostgreSQL. The first version was written in Clojure using a separate Kafka consumer and producer with Java interop. Because Clojure is a functional language, it’s easy to define a function that’s taking the topics as well as the function itself for each event. Usually you’d use the default configuration, but linger.ms has been set to 100 for a higher throughput of the producer. This is the same value that is used by default with Kafka Streams.
The Java classes generated by the topology are holding the data. These classes are based on Avro schemas and are not idiomatic Clojure which is immutable. This way, you can use the Avro serializers from Confluent.
For all commands, first check whether the command was already processed earlier. If so, it should send the same response back. This is what the cmt and cac tables are used for. Using the UUID from the command, they try to find the entry; if they do, they send the same kind of response back as earlier.
If the command has not yet been performed, the command handler will make an attempt using the balance table. In the case of a ConfirmAccountCreation, it will generate a random new bank account number. In other cases, it will also generate a token and send a confirmation. With ConfirmMoneyTransfer, it will try to transfer money. Given this, it is important to validate the token send with the command, and make sure that the balance won’t drop below the minimum amount. If the money is transferred, it will also create a BalanceChanged event for every balance change.
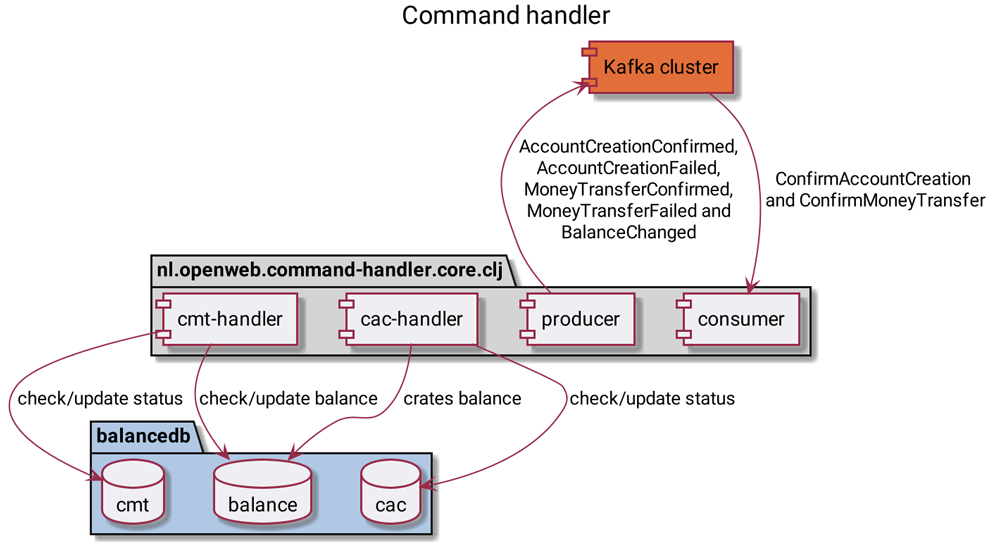
Similar to the Java main method, Clojure applications have a main function that starts the consumers for both ConfirmAccountCreation and ConfirmMoneyTransfer, which share the same producer. To connect to PostgreSQL, next-jdbc provides low-level access from Clojure to JDBC-based databases.
Rust libraries for Kafka
There are two libraries, or crates, for using Kafka in combination with Rust, which are called kafka and rdkafka. kafka is an implementation of the Kafka protocol in Rust, while rdkafka is a wrapper for librdkafka.
Both libraries offer a consumer and a producer but are a bit more low-level than the Java clients. Since you can’t add serializers, you need to wrap the clients for serialization. This is also helpful for defining how to handle errors. When a potential error is detected, most libraries return the Result<T, E> type. This indicates the possibility of an error, and it’s up to the user to decide what to do. Depending on the error, it will either be logged or the application will be terminated.
rust Some(security_config) => Consumer::from_hosts(brokers) .with_topic(topic.to_string()) .with_group(group.to_string()) .with_fallback_offset(FetchOffset::Earliest) .with_offset_storage(GroupOffsetStorage::Kafka) .with_security(security_config) .create() .expect("Error creating secure consumer"),
Above is an example of creating a consumer with the kafka library. Although the kafka library works with Apache Kafka 2.3, it does not have all the features from Kafka 0.9 and newer. For example, it’s missing LZ4 compression support, which depending on the Kafka configuration could make it unusable. In addition, the library has not been updated for almost two years. The configuration is easy and well typed, but also limited. Support for SSL is present but requires some additional code, not just setting properties.
rust let context = CustomContext; let consumer: ProcessingConsumer = ClientConfig::new() .set("group.id", group_id) .set("bootstrap.servers", brokers) .set("enable.auto.commit", "true") .set("enable.auto.offset.store", "false") .set("statistics.interval.ms", "0") .set("fetch.error.backoff.ms", "1") .set("auto.offset.reset", "earliest") .set_log_level(RDKafkaLogLevel::Warning) .optionally_set_ssl_from_env() .create_with_context(context) .expect("Consumer creation failed");
Above is an example of creating a consumer using the rdkafka library. The rdkafka library is based on librdkafka 1.0.0. Work is being done to support more features, and recently admin client functions were added. The crate offers three producer APIs and two consumer APIs, which are either synchronous or asynchronous. Because it’s based on librdkafka, the configuration is pretty similar to the Java client.
Using Schema Registry
For Java clients, using Schema Registry is fairly simple. Basically, it involves three parts:
- Include the correct Avro serializer depending on the type of client.
- Add some configuration, the minimum being the Schema Registry URL. To configure it, use the serializer from the first step.
- Most difficult of all, start using Avro objects for the data. One option is to have a separate Java project with the Avro schemas and generate the Java classes from there.
In lieu of serializers, I wrote some code to make the translation from bytes created by the Avro serializers for Java to something that Rust would understand, and vice versa. For making REST calls to Schema Registry, I used a Rust library based on curl and avro-rs for Avro serialization. Initially, I was happy when I got it to work, because the value in Rust would be of the type Value, which is sort of a generic record. Therefore, getting the actual values out was harder than it could have been, as seen in the code example. The values of a record are modeled as a vector, in which each part can be of multiple types. Make sure it is indeed an ID and that the Value matches the expected type Fixed, with 16 bytes. It would be easier if you could just get the ID property.
rust let id = match cac_values[0] { (ref _id, Value::Fixed(16, ref v)) => ("id", Value::Fixed(16, v.clone())), _ => panic!("Not a fixed value of 16, while that was expected"), };
Since the 2.0.0 version of schema_registry_converter, support was added for Confluent Cloud. Support for Protobuf and JSON Schema was added beyond Avro, as well as references. Also, the library is now async by default. All of the dependencies have also been updated, which made the hacky fix that we needed earlier redundant.
With the Confluent serializers, you can use specific Avro classes, as long as the classes matching the records are on the classpath. In Rust, it’s not possible to dynamically create data objects this way. That’s why if you want to use the specific class equivalent in Rust, you need a function that takes the raw values and the name and outputs a specific type.
Command handler in Rust
When rewriting the command handler in Rust, I tried to make it as similar in functionality to Java as possible, keeping as much of the configuration the same as possible. I also wanted to use the same producer to be shared for both processes. This is something that is easy on the JVM, as long as it’s thread safe, but it is a little harder with Rust, which does not have a garbage collector (unlike the JVM). Certain times on the JVM, an object will be checked for garbage collection eligibility, which comes down to whether or not it has non-weak references. In Rust, memory is freed as soon as the object is no longer referenced. For memory safety, the much-feared borrow checker that is part of the compiler ensures that an object is either mutable and not shared, or immutable and shared. In this example, we need a mutable producer that can be shared, which is isn’t allowed by the borrow checker. Luckily, there are several ways to work around this.
A multi-producer, single consumer FIFO queue communication allows you to use one producer from multiple threads. This is part of the standard library and makes it possible to send the same kind of objects from different threads to one receiver. With this intermediate construction, the actual Kafka producer can live in a single thread but still receive messages from multiple threads. Both consumer threads can write to the FIFO queue, and the single producer can read from the queue, solving the borrow checker problem. Diesel, an ORM and query builder, is used with the database.
For all three libraries—rdkafka sync, rdkafka async, and Rust-native kafka—each has examples that make them easy to use. You will not handle more cases of errors than you would with Java clients. At the same time, getting to the actual data within the records may involve some lift, especially in the rdkafka library since it is wrapped in an Ok(Ok(Record)) for a potential error reading a response from Kafka or a problem with the record itself.
Running applications with Docker
Even more so now that Kubernetes is popular, running applications with Docker provides a nice way to deploy applications, as Docker images can easily be run on different platforms.
Creating a Docker image to run a Java application is easy. Once you have compiled a JAR, it can run on any JVM of the corresponding version independent of the platform, though the images can get quite big because you need a JVM.
With Rust, it’s slightly more complicated since by default it will compile for the current environment. In the case of rdkafka, I used the standard Rust Docker image, based on Debian, to create a production build executable of the code and a slim Debian image for the actual image. For the native one, I used the clux/muslrust for building, compiling everything statically and FROM scratch to generate a very small image of 9.18 MB for the actual image. Despite the risks involved with maintaining a Docker image, this is beneficial not only due to its size but also because it’s more secure than building on top of several other layers, which might have security issues.
Part of the configuration for both the JVM and Rust variants can be set using environment variables. It falls back to default values when they are not present to run them more easily without Docker.
By keeping the names for the Docker image the same, only a few changes are needed to run the open bank application with Rust instead of Clojure. With Docker builders, you don’t even need to have Rust installed locally. The environment variables for Kafka, ZooKeeper, and SSL are different, but everything else keeps working exactly the same because the script for creating the certificates also creates non-keystore variants for the command handler.
Performance-testing transactions
All tests were run by first executing the prepare.sh script in the branch to test. To start the actual test, I restarted the laptop, and 10 tests were done in succession using loop.sh 10. The laptop used for the benchmarks was an Apple MacBook Pro 2008 with 2.6 Ghz i7 and 16 GB of memory. Docker was configured to have 9 CPUs and 12 GB memory. To measure CPU and memory, some code was added to lispyclouds/clj-docker-client. The CPU scores in the test are relative to amount used for Docker. So a value of 11% means about 1 CPU of the nine available is spending all of its time on that process.
Benchmarking is hard, especially on a whole application. The test focused on end-to-end latency and measured it by adding or subtracting money from the opened account, followed by a check every 20 ms to see if the balance was properly updated. This occurs every second, with a timeout of five seconds. If the expected update does not show up within five seconds five times, the test is stopped.
While testing the latency, the load on the system is increased by letting the heartbeat service produce more messages. The additional load value in the diagrams are only the heartbeat messages. The actual number of messages will be about triple that, because for every heartbeat message generated, there is also a command and a result message. Every 20 seconds, parts of the system are measured for CPU and memory use. The raw data of the performance tests can be found on GitHub or online via the background tab.
End-to-end latency while increasing load with different implementations of the command handler
The most important statistic when comparing latencies remains highly debated. While average latency does provide some information, if some of the responses are really slow, it can still hinder the user experience a lot. Because some users will have to wait long to see some results. The 99th percentile latency reveals within what time 99% of the calls were returned.
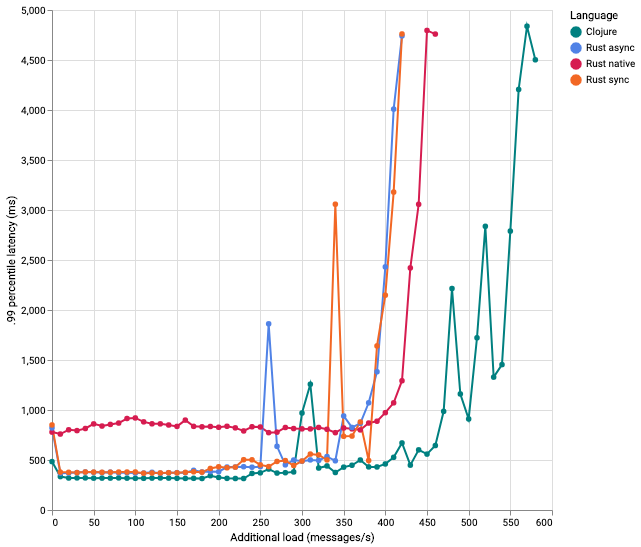
As shown above, there are some spikes, which could be explained by small hiccups in one of the tests that bring the score up. For Rust native, code was added to simulate the behavior of linger.ms for the producer, and .poll(ms) for the consumer. The main reason for doing this was that on an earlier, similar kind of test, it would already fail at about 220 messages. It sent every message individually, so this was expected. With the refreshed code, you can send all available messages, sleep a little, then send all available messages again. This is simple using the FIFO queue, but you do lose some time, because all available messages need to be serialized before being sent.
The two rdkafka clients don’t appear to be different, which makes sense since most of the code is the same, and the advantage of async might only prove relevant for high loads.
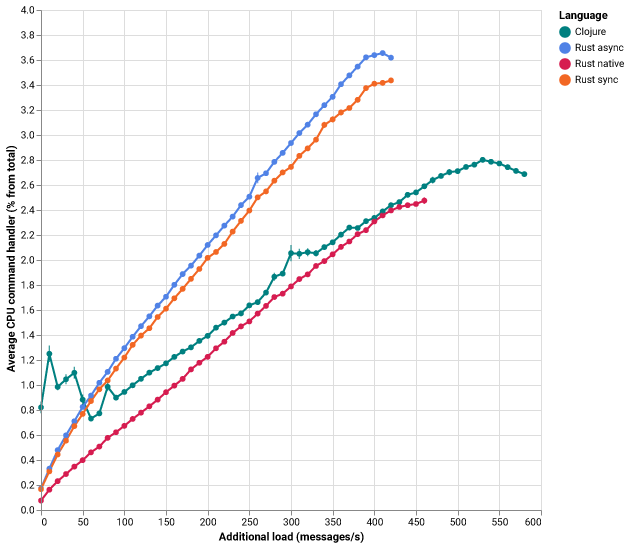
CPU load command handler
When you look at the CPU load of the command handler below, you see a lot of load at the start for Clojure. This makes sense as the JIT compiler is generating and optimizing bytecode. The async client needs more memory and significantly more CPU than the sync variant. The rdkafka library requires more CPU than both Clojure and Rust native, which might either be because of C with Rust interop, or because the Rust rdkafka library is not very efficient. Aside from the initial starting spike for Clojure, all the languages are pretty linear in relation to load.
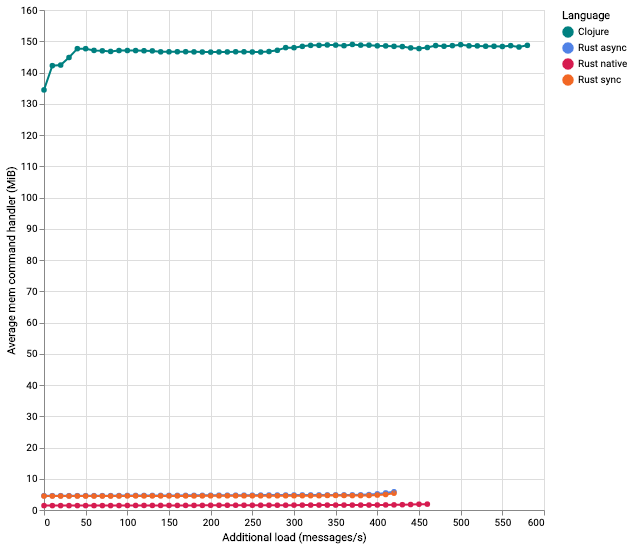
Memory needed for the command handler
Here, we see some big differences. While Clojure goes up quickly to 150 MiB, the rdkafka clients only need about 5 MiB, and the native implementation only needs 2 MiB. The big difference is in the small runtime of Rust, which doesn’t use a garbage collector. The Clojure implementation needs relatively little memory. In an earlier test, another JVM implementation with Kotlin and Spring Boot was using about twice as much memory as Clojure.
Summary
I hope my experience of writing a service in Rust and comparison of its performance to functionally equivalent JVM ones are useful to you. As you can see, Rust can be used as a replacement to Java applications that use Kafka, and you can use Schema Registry in almost the same way you’d use it on a JVM.
As usage of Rust becomes increasingly prominent, the ecosystem will likely continue improving even more. I personally really enjoyed working with Rust and would like to keep making contributions that help take things forward.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with the leading distribution of Apache Kafka. In addition, learn how to get started with Scala and Kafka.
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


