Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Deploying Kafka Streams and KSQL with Gradle – Part 3: KSQL User-Defined Functions and Kafka Streams
Building off part 1 where we discussed an event streaming architecture that we implemented for a customer using Apache Kafka, KSQL, and Kafka Streams, and part 2 where we discussed how Gradle helped us address the challenges we faced developing, building, and deploying the KSQL portion of our application, here in part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. The repository’s README contains a bit more detail, but in a nutshell, we check out the repo and then use Gradle to initiate docker-compose:
git clone https://github.com/RedPillAnalytics/kafka-examples.git cd kafka-examples git checkout confluent-blog ./gradlew composeUp
We can then verify that the clickstream, clickstream_codes, and clickstream_users topics are all there:
./gradlew ksql:listTopics> Task :ksql:listTopics Name: _confluent-metrics, Registered: false, Partitions: 12, Consumers: 0, Consumer Groups: 0 Name: _schemas, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream_codes, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream_users, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: docker-connect-configs, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: docker-connect-offsets, Registered: false, Partitions: 25, Consumers: 0, Consumer Groups: 0 Name: docker-connect-status, Registered: false, Partitions: 5, Consumers: 0, Consumer Groups: 0
BUILD SUCCESSFUL in 1s 1 actionable task: 1 executed
KSQL user-defined functions
KSQL provides a nice collection of built-in SQL functions for use in functional transformation logic when doing stream processing, whether the need is scalar functions for working with data a row at a time or aggregate functions used for grouping multiple rows into one summary record of output. But like most SQL engines, there is often a need to write custom functions to reduce the complexity of certain SQL operations as repeatable design patterns.
In our case, we needed to encapsulate a series of string manipulation patterns that were consistent across many of our pipelines. While the CASE syntax now available since KSQL 5.2.2 would have handled our requirements, it didn’t exist yet in the version we were using. I wrote a function called DECODE(), which reminded many of us of our Oracle database days. For years, the Oracle database was also missing explicit CASE syntax, and the DECODE() function was a nice workaround until it was added.
The full code for building and testing our DECODE() function is included in the functions subproject directory, but for easy reference, we’ll have a look at a few snippets. We can see the @UdfDescription annotation on our Decode class, as well as the @Udf annotation on our DECODE() method. These two annotations imported from the io.confluent.ksql.function.udf package instruct the KSQL server to provide the method or methods in the class as UDFs. For brevity, we’re only showing the simplest of the three methods in the class:
@UdfDescription( name = "decode", description = """Given up to 3 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'.""") class Decode {@Udf(description = """Given 1 pair of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'.""") String decode(String expression, String search1, String text1, String defaultvalue, Boolean ignorecase = false) {
// If any of the expected values are null, then just return null <span style="color: #80c0ec;">if</span> (expression == <span style="color: #9577ff;">null</span> || search1 == <span style="color: #9577ff;">null</span> || text1 == <span style="color: #9577ff;">null</span>) <span style="color: #80c0ec;">return</span> <span style="color: #9577ff;">null</span> <span style="color: #80c0ec;">return</span> Utils.textMatch(expression, search1, ignorecase) ? text1 : defaultvalue} [...] }
We are using the Spock framework for writing our test specifications. Spock allows us to use the @Unroll annotation to define data tables for data-driven testing, defined using the where: clause in the spec below. @Unroll instructs Spock to take the single feature method with all the data variables, (defined with the # symbols) and expand (or “unroll”) it out to multiple methods. Although not demonstrated here, Spock also allows for iterables to serve as data tables, which can be provided by input files, SQL queries, etc. For brevity, we’ve only included the simplest of the Spock feature methods, but the rest are available in the repository:
@Shared Decode decode = new Decode()@Unroll def "When: #expression, #search, #text, #defaultValue; Expect: #result"() {
expect: decode.decode(expression, search, text, defaultValue) == result
where: expression | search | text | defaultValue || result 'KSQL Rocks!' | 'ksql rocks!' | 'yes' | 'no' || 'no' 'KSQL Rocks!' | 'KSQL Rocks!' | 'yes' | 'no' || 'yes' }
Let’s take a look at our build.gradle file to get an understanding of how Gradle builds and tests our UDFs. As before, we first apply a few Gradle plugins using the plugins{} closure:
plugins {
id 'groovy'
id 'com.adarshr.test-logger' version '1.7.0'
}
We used Groovy instead of Java to write our UDFs, so we’ve applied the groovy plugin. The Groovy compiler accepts Java as well as Groovy, and Gradle automatically adds the java plugin with the groovy plugin and compiles all Java and Groovy code together into the same JAR. So using Groovy in Gradle is a handy way to allow Groovy and Java in the same project.
Groovy might be a preferred choice for writing UDFs with KSQL though, as it provides a bit of a shortcut related to data types. In Java, primitive data types and boxed data types are separate entities, therefore requiring separate overloaded methods for handling them—the MULTIPLY() function from the Confluent documentation is a good example. Notice that there are separate methods for handling the long and the Long data types. Groovy accepts primitives just like Java does, but it “autowraps” the primitives and automatically elevates them to boxed data types. This means that, with Groovy, we don’t have to write separate overloaded methods for primitives and boxed data types.
We’ve added the com.adarshr.test-logger plugin, which provides clear standard output for unit test executions. So now, let’s build a UDF artifact. We provide the functions: prefix to reference the subproject directory with our code. Notice that the functions:build task also executes the functions:test task as well, which runs our Spock specifications. Feel free to add the -i option at the end to get the info logging level for more detail:
==> ./gradlew functions:build> Task :functions:test
DecodeTest
Test When: KSQL Rocks!, ksql rocks!, yes, no; Expect: no PASSED Test When: KSQL Rocks!, KSQL Rocks!, yes, no; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, yes, no, true; Expect: yes PASSED Test When: KSQL Rocks!, KSQL Rocks!, yes, no, true; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, yes, no, false; Expect: no PASSED Test When: KSQL Rocks!, KSQL rocks!, yes, KSQL Sucks!, no, no, true; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, no, KSQL Rocks!, yes, no, false; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, no, KSQL Sucks!, no, yes, false; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, yes, KSQL Sucks!, no, KSQL, meh, no, no, true; Expect: yes PASSED Test When: KSQL Rocks!, KSQL rocks!, no, KSQL Rocks!, yes, KSQL, meh, no, no, false; Expect: yes PASSED Test When: KSQL, meh, KSQL rocks!, no, KSQL Sucks!, no, KSQL, meh, yes, no, false; Expect: yes PASSED Test When: KSQL, meh, KSQL rocks!, no, KSQL Sucks!, no, What's KSQL, no, yes, false; Expect: yes PASSED Test When: KSQL, meh, ksql rocks!, no, ksql, meh, yes, What's KSQL, no, no, true; Expect: yes PASSED Results: SUCCESS (13 tests, 13 successes, 0 failures, 0 skipped)
SUCCESS: Executed 13 tests in 778ms
BUILD SUCCESSFUL in 2s 7 actionable tasks: 6 executed, 1 up-to-date
The functions:build task built the JAR artifact with any Groovy and/or Java code inside, and we can see this artifact in the functions/build/libs directory:
==> zipinfo -h functions/build/libs/functions-1.0.0.jar Archive: functions/build/libs/functions-1.0.0.jar Zip file size: 5849 bytes, number of entries: 5
Notice that the JAR only includes the custom classes: five entries total. When deploying to KSQL, a UDF artifact needs to include all transitive dependencies, including the io.confluent.ksql.function.udf package and any other custom libraries we used. We need to build an uber JAR or fat JAR—one artifact that contains the custom classes plus any dependencies.
There are numerous ways to do this with Gradle, but the easiest is using the com.github.johnrengelman.shadow plugin. We’ll add that plugin and configure the shadowJar task to be called instead of the standard jar task during a build. Note: These changes can be made to the build script in the repository by uncommenting out three lines.
plugins {
id 'groovy'
id 'maven-publish'
id 'com.adarshr.test-logger' version '1.7.0'
id "com.github.johnrengelman.shadow" version "5.0.0"
}
//customize ShadowJar
jar.enabled = false
shadowJar { classifier = '' }
tasks.build.dependsOn tasks.shadowJar
// mavenLocal publish
publishing {
publications {
shadow(MavenPublication) { publication ->
project.shadow.component(publication)
}
}
repositories {
mavenLocal()
}
}
group = 'com.redpillanalytics'
version = '1.0.0'
dependencies {
compile localGroovy()
compile 'org.slf4j:slf4j-simple:+'
compile 'io.confluent.ksql:ksql-udf:+'
testCompile 'org.spockframework:spock-core:1.2-groovy-2.5'
}
// confluent dependencies
repositories {
jcenter()
maven {
url "http://packages.confluent.io/maven/"
}
}
Now, we’ll build again (bypassing the test task just for brevity), publish, and take a look at the resulting JAR:
==> ./gradlew functions:build functions:publish --exclude-task testBUILD SUCCESSFUL in 3s 5 actionable tasks: 5 executed
==> zipinfo -h functions/build/libs/functions-1.0.0.jar Archive: functions/build/libs/functions-1.0.0.jar Zip file size: 11405084 bytes, number of entries: 7422
The JAR contains 7,422 entries, which indicates that it now has all transitive dependencies included. We deploy the JAR to the KSQL server by copying it from the Maven repository to the directory indicated by the ksql.extension.dir property. For our customer project, we used a Jenkins pipeline to perform the deployment steps, and we would take a similar approach in any production delivery pipeline.
In this post, I’ll demonstrate using the command line. In our ksql-server container, ksql.extension.dir points to the /etc/ksql-server/ext directory, so we need to copy the file to the container, restart our services, and then start or restart our KSQL pipelines from part 2 of this series. Note: When executing ./gradlew ksql:pipelineExecute, we might see the following error: error_code: 40001: Kafka topic does not exist: clickstream. The creation of our source topics is asynchronous in the restart of our environment…just wait a few seconds, and give it another go.
docker cp ~/.m2/repository/com/redpillanalytics/functions/1.0.0/functions-1.0.0.jar ksql-server:/etc/ksql-server/ext ./gradlew composeDown composeUp # wait 10 seconds or so ./gradlew ksql:pipelineExecute
Now we connect to our ksql-cli container to describe the new function:
docker exec -ti ksql-cli ksql http://ksql-server:8088 ksql> describe function decode;Name : DECODE Overview : Given up to 3 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Type : scalar Jar : /etc/ksql-server/ext/functions-1.0.0.jar Variations :
Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR) Returns : VARCHAR Description : Given 3 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR, BOOLEAN) Returns : VARCHAR Description : Given 1 pair of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, BOOLEAN) Returns : VARCHAR Description : Given 2 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR) Returns : VARCHAR Description : Given 2 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR) Returns : VARCHAR Description : Given 1 pair of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'. Variation : DECODE(VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, BOOLEAN) Returns : VARCHAR Description : Given 3 pairs of 'search' and 'text', return the first 'text' value where 'search' matches 'expression'. If no match, return 'defaultvalue'. 'ignorecase' defaults to 'false'.
We can use our new DECODE() function and enjoy CASE-like functionality:
ksql> select definition, decode(definition,\ 'Proxy authentication required','Bad',\ 'Page not found','Bad',\ 'Redirect','Good',\ 'Unknown') label \ from enriched_error_codes limit 5;Page not found | Bad Redirect | Good Not acceptable | Unknown Page not found | Bad Redirect | Good Limit Reached Query terminated ksql> exit Exiting KSQL.
Kafka Streams
If you recall from part 1, we added Kafka Streams to our architecture for some final repackaging of our messages before sending them off to the different APIs in Oracle Warehouse Management Cloud (Oracle WMS Cloud):
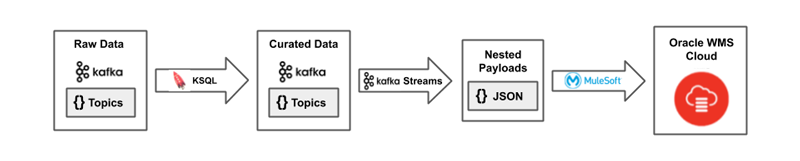
Figure 1. The packaging of payloads for Oracle WMS Cloud
Each individual Streams application was deployed as a standalone microservice, and we used the Gradle Application plugin to build and deploy these services. Our streams subproject directory contains a build.gradle file and a Kafka Streams class—we borrowed the WordCountLambaExample as our example service. The build script applies the Application plugin (and by extension the Java plugin) and defines mainClassName as the entry point for our application and applicationName as the custom application name:
plugins {
id 'application'
}
// application entry point mainClassName = 'WordCountLambdaExample' applicationName = 'wordcount-lambda-example'
// Default artifact naming. group = 'com.redpillanalytics' version = '1.0.0'
dependencies { compile 'org.slf4j:slf4j-simple:+' compile 'org.apache.kafka:kafka-streams:+' }
repositories { jcenter() }
The service can be run using the streams:run task, which compiles the JAR file, runs any tests defined in the source sets, launches a new JVM with all dependencies applied to the classpath, and starts and continues to run the application until a CTRL-C is issued:
==> ./gradlew streams:run -q
[main] INFO org.apache.kafka.streams.StreamsConfig - StreamsConfig values:
application.id = wordcount-lambda-example
[...]
[wordcount-lambda-example-client-StreamThread-1] State transition from PARTITIONS_ASSIGNED to RUNNING
[wordcount-lambda-example-client-StreamThread-1] INFO org.apache.kafka.streams.KafkaStreams - stream-client [wordcount-lambda-example-client] State transition from REBALANCING to RUNNING
<=========----> 75% EXECUTING [1m 42s]
> :streams:run
Running Streams using Gradle directly from the Git repository is not an ideal solution for a production microservice. Thankfully, the Application plugin can create distribution artifacts complete with start scripts that can be packaged up as part of the build process. They can also be published to a Maven repository just like other artifacts by adding the maven-publish plugin and configuring either the .zip or .tar files the plugin generates as our published artifact:
plugins {
id 'application'
id 'maven-publish'
}
// application entry point
mainClassName = 'WordCountLambdaExample'
applicationName = 'wordcount-lambda-example'
// mavenLocal publish
publishing {
publications {
streams(MavenPublication) {
artifact distZip
}
}
repositories {
mavenLocal()
}
}
// Default artifact naming.
group = 'com.redpillanalytics'
version = '1.0.0'
dependencies {
compile 'org.slf4j:slf4j-simple:+'
compile 'org.apache.kafka:kafka-streams:+'
}
repositories {
jcenter()
}
Now we can easily publish the distribution file along with our KSQL pipelines and UDFs:
==> ./gradlew streams:build streams:publish --console=plain > Task :streams:compileJava > Task :streams:processResources > Task :streams:classes > Task :streams:jar > Task :streams:startScripts > Task :streams:distTar > Task :streams:distZip > Task :streams:assemble > Task :streams:compileTestJava NO-SOURCE > Task :streams:processTestResources NO-SOURCE > Task :streams:testClasses UP-TO-DATE > Task :streams:test NO-SOURCE > Task :streams:check UP-TO-DATE > Task :streams:build > Task :streams:generatePomFileForStreamsPublication > Task :streams:publishStreamsPublicationToMavenLocalRepository > Task :streams:publishBUILD SUCCESSFUL in 2s 8 actionable tasks: 8 executed
Jenkins was again used in our production deployment for each microservice, which meant grabbing the artifact, unzipping it, and starting the application. I’ll again demonstrate just with the command line by creating a deployment directory, copying the artifact from Maven, unzipping it, and running the start script:
==> mkdir streams/build/deploy ==> cd streams/build/deploy ==> cp ~/.m2/repository/com/redpillanalytics/streams/1.0.0/streams-1.0.0.zip . ==> unzip -q streams-1.0.0.zip ==> ./wordcount-lambda-example-1.0.0/bin/wordcount-lambda-example [main] INFO org.apache.kafka.streams.StreamsConfig - StreamsConfig values: application.id = wordcount-lambda-example application.server = bootstrap.servers = [localhost:9092] [...] [wordcount-lambda-example-client-StreamThread-1] INFO org.apache.kafka.streams.KafkaStreams - stream-client [wordcount-lambda-example-client] State transition from REBALANCING to RUNNING
We can see that Streams has created the new topic clickstream-wordcount, as well as additional topics involved with managing state:
==> cd ../../../ ==> ./gradlew ksql:listTopics | grep wordcount Name: clickstream-wordcount, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: wordcount-lambda-example-KSTREAM-AGGREGATE-STATE-STORE-0000000003-changelog, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: wordcount-lambda-example-KSTREAM-AGGREGATE-STATE-STORE-0000000003-repartition, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0
Gradle analytics with Apache Kafka
Throughout this series, you’ve seen how Gradle can be used to build all things Kafka with both built-in functionality (mostly due to the plugin architecture) and plugins contributed by the community. Red Pill Analytics wrote and contributed the gradle-confluent plugin, but we’ve also contributed the gradle-analytics plugin that we believe is relevant to Kafka. This plugin is used to capture information about what’s going on inside of Gradle, capturing all the following information related to a build:
- Unique build ID for each Gradle invocation
- An added build tag that can be specified from any CI/CD server to group build IDs into jobs
- Git branch, commit, and committer details
- Task execution details, such as task name, task group, execution time, and result
- Test execution details, such as test name, test suite, execution time, and result.
gradle-analytics is also extensible: It can be used inside of other custom plugins to capture information specific to that plugin, and in the case of gradle-confluent, it captures all the different KSQL script executions. gradle-analytics is applied to the build.gradle file only in the root project directory, where it captures activity about that project and all subprojects. It can then send that activity to cloud services like AWS Kinesis, Amazon S3, Cloud Pub/Sub, or Google Cloud Storage and a few JDBC sources. And of course, it can send data to Kafka.
gradle-analytics is applied to the project in our repository, and we’ve been generating JSON data files about task execution activity, test results, and all of our KSQL executions. The files are generated inside the build/analytics directory, with a separate subdirectory for each unique build ID:
==> ls -l build/analytics/ total 0 drwxr-xr-x 5 stewartbryson staff 160 Mar 27 07:23 045575c0-0904-45b1-a78a-0cb59fc5d840 drwxr-xr-x 5 stewartbryson staff 160 Mar 27 07:14 0d6157f1-8050-4342-bfc3-11437b7c304f drwxr-xr-x 4 stewartbryson staff 128 Mar 27 07:26 23a497ca-7c80-478e-9708-e0e88860c153 drwxr-xr-x 4 stewartbryson staff 128 Mar 27 07:26 379578e8-cd91-476c-b952-c1b325695be7 drwxr-xr-x 4 stewartbryson staff 128 Mar 27 07:28 46d54622-ab7f-4259-a124-b96b9f5e192f [...]
We can configure one or more analytics sink destinations. In our case, we’ve configured Kafka, and the JSON data files are written using a simple Kafka producer:
plugins {
// facilitates publishing build activity to streaming and analytics platforms
// including Kafka
id 'com.redpillanalytics.gradle-analytics' version "1.2.3"
}
analytics.sinks {
kafka {
servers = 'localhost:9092'
acks = 'all'
}
}
Now we can use the producer task to write our Gradle activity to Kafka:
./gradlew producer --console=plain> Task :kafkaSink 47 analytics files processed.
> Task :producer
BUILD SUCCESSFUL in 2s 2 actionable tasks: 2 executed ==>
And we can see our new Kafka topics generated:
==> ./gradlew ksql:listTopics | grep gradle Name: gradle_build, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: gradle_ksqlstatements, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: gradle_task, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: gradle_test, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0
Conclusion
I recently spoke at Kafka Summit New York, where I boiled this three-part series down to a 40-minute talk. At least two of my attendees are now using Gradle to build some part of their Kafka event streaming application. Another attendee who spoke to me after the session asked if I plan on porting the gradle-confluent plugin to Maven, which emphasizes how difficult it can be for some organizations to consider using anything else. I understand inertia, but Gradle is a powerful and modern build tool, and I hope this blog series helps convert a few Kafka-based build pipelines.
Interested in more?
Download the Confluent Platform and learn about ksqlDB, the successor to KSQL.
Other articles in this series
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.