Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Data Sharing Patterns with Confluent Schema Registry
Sharing metadata on the data you store in your Confluent cluster is paramount to allow for effective sharing of that data across the enterprise. As the usage of real-time data grows, it is a common evolutionary practice to enable servicing this data as a product within—and outside—the business. This evolution is commonly referred to as the “data mesh.”
Confluent’s Schema Registry allows organizations to ensure high data quality and safe data evolution as they set their data in motion and operationalize the data mesh.
Schema Registry ensures a proper data contract between the creators and consumers of this product; however, not all data products from a business unit are necessarily needed by all possible consumers of the organization as a whole.
To isolate for their own data needs, teams commonly deploy multiple Schema Registry clusters to serve their own contracts. Sharing these contracts with the business as a whole is then paramount for the success of the data product. This situation also arises when multiple business entities with their own Confluent deployments merge.
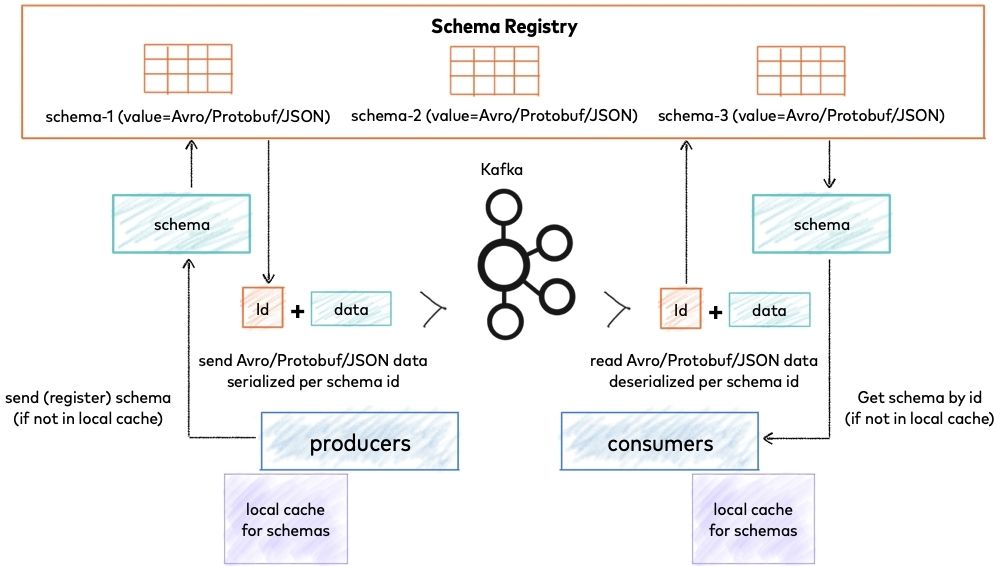
Source: Schema Registry overview
Schema registration and management
Confluent’s Schema Registry uniquely identifies a schema for an Apache Kafka® record through the use of “schema IDs.” These IDs are individually included in every message so that consumers such as Kafka clients, connectors, and ksqlDB queries understand what schema to reference in order to make sense of the data being consumed.
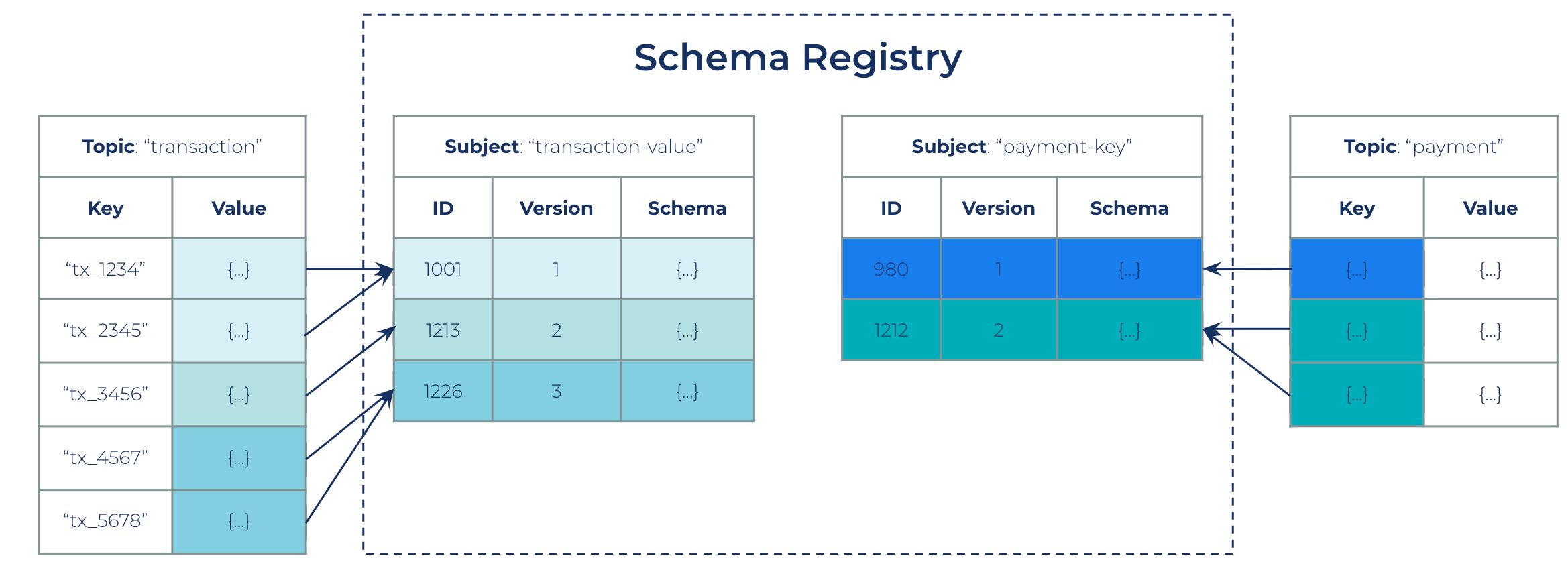
Internally, these monotonically increasing IDs are assigned by the Schema Registry and, by default, start from “0.” Allowing these contracts to coexist in multiple Schema Registry deployments involves:
- Ensuring the IDs are non-overlapping
- Ensuring the schema definitions are unique
- Ensuring uniqueness in subject naming
There are multiple ways to tackle these guarantees, and we will discuss them in the following patterns:
- Hub to spoke
- Spoke to hub
- Disaster recovery
Hub to spoke: Data sharing
The “hub to spoke” pattern involves utilizing a single Schema Registry globally in an organization. The data sharing component involves only replicating schemas that are needed (or all) by the “spokes,” or individual business units that wish to consume by utilizing a specific data contract.
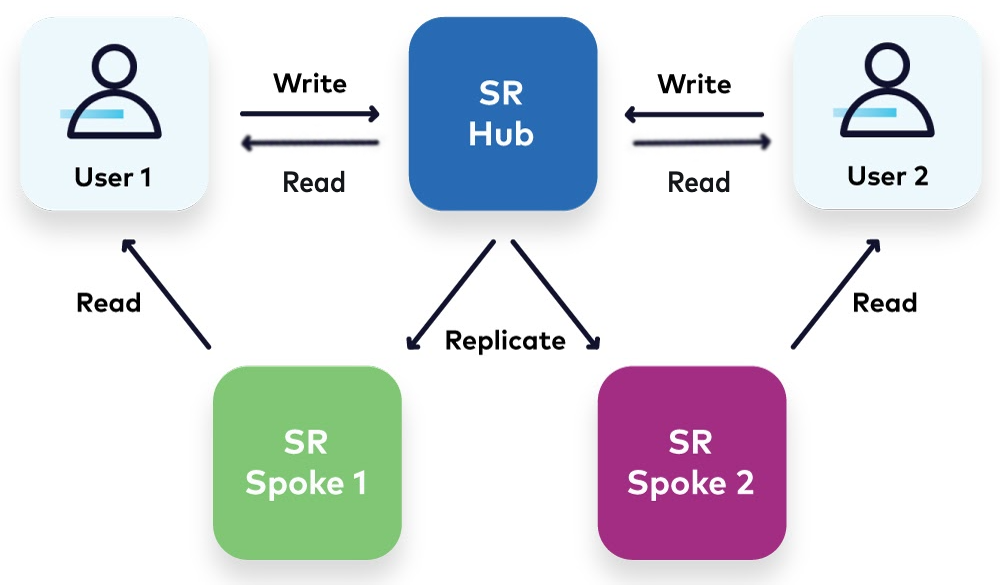
Global ID Space
With this design, we achieve:
- A single source of truth: All schema registration happens at the “hub,” so there is no fear of overlapping schema IDs or subject naming conflicts as Schema Registry provides an ever-increasing ID for new schemas and prevents subject collision.
- Pre-registration checks: The hub Schema Registry ensures that if two schemas that are attempted to be registered are equal, the same Schema ID is assigned to both of them.
To use this pattern, we recommend the use of the Schema Registry Authorizer to prevent anyone involved in schema registration from corrupting the “hub” registry. This pattern notably allows the “hub” to read/write, but the “spoke” to be read-only. Having a global ID space promotes the reuse of schema IDs across the organization. This also allows for a high level of redundancy of metadata in the Schema Registry, a practice that may help disaster recovery efforts within the organization.
We recommend thinking through this pattern when beginning the journey to establish strong data contracts for your data in motion platform, as it may be difficult to migrate after the fact.
Spoke to hub: Data aggregation
The “spoke to hub” pattern allows business units to enforce their own contracts and have control over their Schema Registry deployments. The data aggregation component involves replicating the schemas needed (or all) for the data product to be presented to the “hub,” or any other business unit that wishes to be a consumer of this data product.
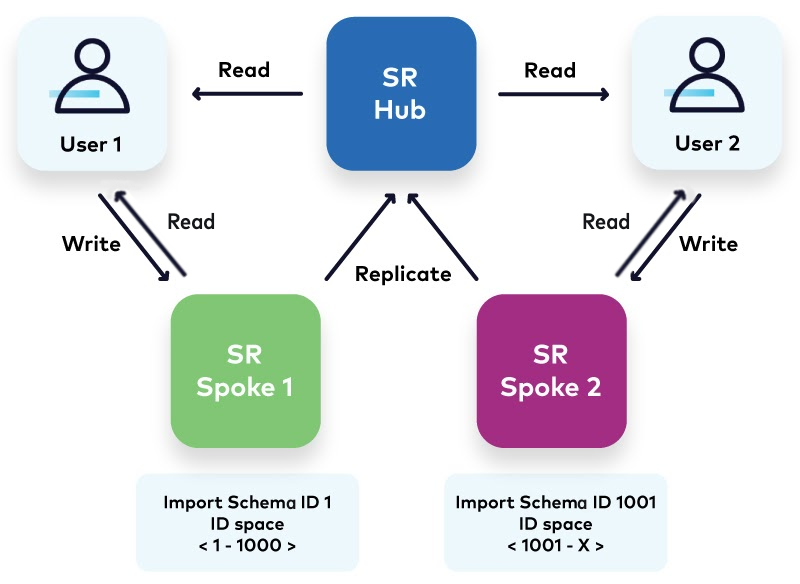
With this design, we need to establish:
- ID namespacing: Schema Registry allows for “bumping” the starting point of schema registrations, allowing each Schema Registry to reserve an “ID namespace” for registration of their local data contracts. This strategy involves enabling mutability in Schema Registry and importing a dummy subject with a predefined ID of choice. Upon successful import, the predefined ID serves as the starting point for the monotonically increasing schema IDs that Schema Registry generates for all subsequent registrations and modifications. There is a sample script for automating the bumping of Schema Registry IDs.
- Schema collision prevention: When two spokes have the same schema, it is not possible to allow them to point to two different IDs. Precaution must be taken when aggregating schema registries to not use the same schema in multiple sources, as per the data mesh standard of maintaining shared objects in the core domain.
- Schema naming standards: Avoid future conflicts by setting naming standards for schemas registered in spokes when they wish to contribute back to the aggregate Schema Registry.
Notably, this strategy allows the “spokes” to be read/write, but the “hub” to be read-only. This pattern allows each “spoke” to implement their own security measures, and to choose which schemas to expose to the business as a whole. A note on this pattern is that there should be planning around schema capacity, as the registry allows for setting the starting point, but not the ending point, and you are limited by INT_MAX on-prem (2147483647).
We recommend thinking through this pattern early in the journey along with establishing strong data contracts for your data in motion platform, as it may be difficult to onboard multiple tenants to a core if their identification collides.
Disaster recovery data replication
The “disaster recovery (DR)” pattern allows business units to have a disaster recovery option for Schema Registry failures. This allows the DR cluster to be used as a read-only site while not being failed over and can be safely used to share data.
With this design, the previous limitations are non-existent, as the DR Schema Registry is an exact replica of the Schema Registry used by the business unit. This design requires all schema data to be replicated to the DR Schema Registry cluster, disallowing selective exposure of data contracts.
Data sharing tooling
Supporting the previously presented patterns requires robust and effective data replication between schema registries. Confluent and the Kafka community have developed multiple options that can help.
Confluent Schema Linking and contexts
Confluent’s Schema Linking is now available in preview on Confluent Cloud and in Confluent Platform 7.0. Schema Linking allows for aggregation and disaster recovery patterns to be handled seamlessly and should be considered the de facto standard when made GA.
In the hub to spoke pattern, the hub ensures all schemas registered are uniquely named and identified, thereby preventing challenges when sharing with spoke schema registries. Additionally, Schema Linking allows for “exporters,” which provide the ability to continuously sync schemas from the hub to the spoke as they are registered to a specific context.
In the spoke to hub pattern, the spoke can utilize the power of contexts and exporters to sync back schemas registered at the spoke into the hub without fear of collisions by registering schemas within a separate context on the hub. This eliminates the need for ID namespacing.
Furthermore, Schema Linking enables schema aggregation independent of the data sharing mechanism and addresses existing gaps in the aggregation, backup, staging, and migration of schemas within and across Confluent Platform and Confluent Cloud clusters.
Check out this Schema Linking demo and Stream governance for exciting new developments.
Confluent Replicator
Confluent’s Replicator is the battle-tested way of performing replication of data. It comes with Schema Translation, which replicates all the schemas from the source Schema Registry.
Confluent Replicator does not allow for selective replication of schemas, and any architecture would require an active/passive replication setup.
In the hub to spoke pattern, all spokes would be required to store all schemas from the hub, and any security concern can be alleviated by enabling the Schema Registry Authorizer in the spokes.
In the spoke to hub pattern, all schemas from every spoke would have to go back to the hub, and proper precautions would have to be taken to avoid ID, schema naming, and schema definition collisions.
Additionally, Confluent Replicator cannot replicate between two Confluent Cloud schema registries.
Apache Kafka MirrorMaker 1 and 2
Kafka provides an open source method of replication called MirrorMaker (Note: MirrorMaker 1 is deprecated in the latest version of Apache Kafka).
MirrorMaker allows replicating the underlying “_schemas” topic, enabling other schema registries to read this replicated topic and make the schemas available.
MirrorMaker suffers from the same limitations as Confluent Replicator, but it additionally does not ensure registration constraints at the target, which may cause corruption in the schemas.
Open source tooling
There are a couple of available tooling options for schema replication:
- ccloud-schema-exporter
- Benefits: This OS tooling supports selective migration of schemas and works with Confluent Cloud Schema Registry.
- Limitations: This tool is implemented as a pure REST endpoint solution, disallowing it to replicate singular compatibilities of the subjects in the source Schema Registry. There is no enterprise support for this tooling.
- schema-registry-transfer-SMT
- Check out Transferring Avro Schemas Across Schema Registries with Kafka Connect to learn the benefits and limitations of the SMT.
Summary
This blog post presented the different architectural patterns utilized when creating a data sharing culture within an organization. It is possible to merge schema data via multiple tooling and patterns in order to maintain a data contract between the creation business unit and the consuming team.
To get started with Confluent Schema Registry, try it out fully managed on Confluent Cloud, which now includes the brand-new Confluent Stream Governance feature. Get started with a free trial of Confluent Cloud and use the code CL60BLOG to get an additional $60 of free usage.*
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...