Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Announcing the Azure Cosmos DB Sink Connector in Confluent Cloud
Today, Confluent is announcing the general availability (GA) of the fully managed Azure Cosmos DB Sink Connector within Confluent Cloud. Now, with just a few simple clicks, you can link the power of Apache Kafka® together with Azure Cosmos DB to set your data in motion.
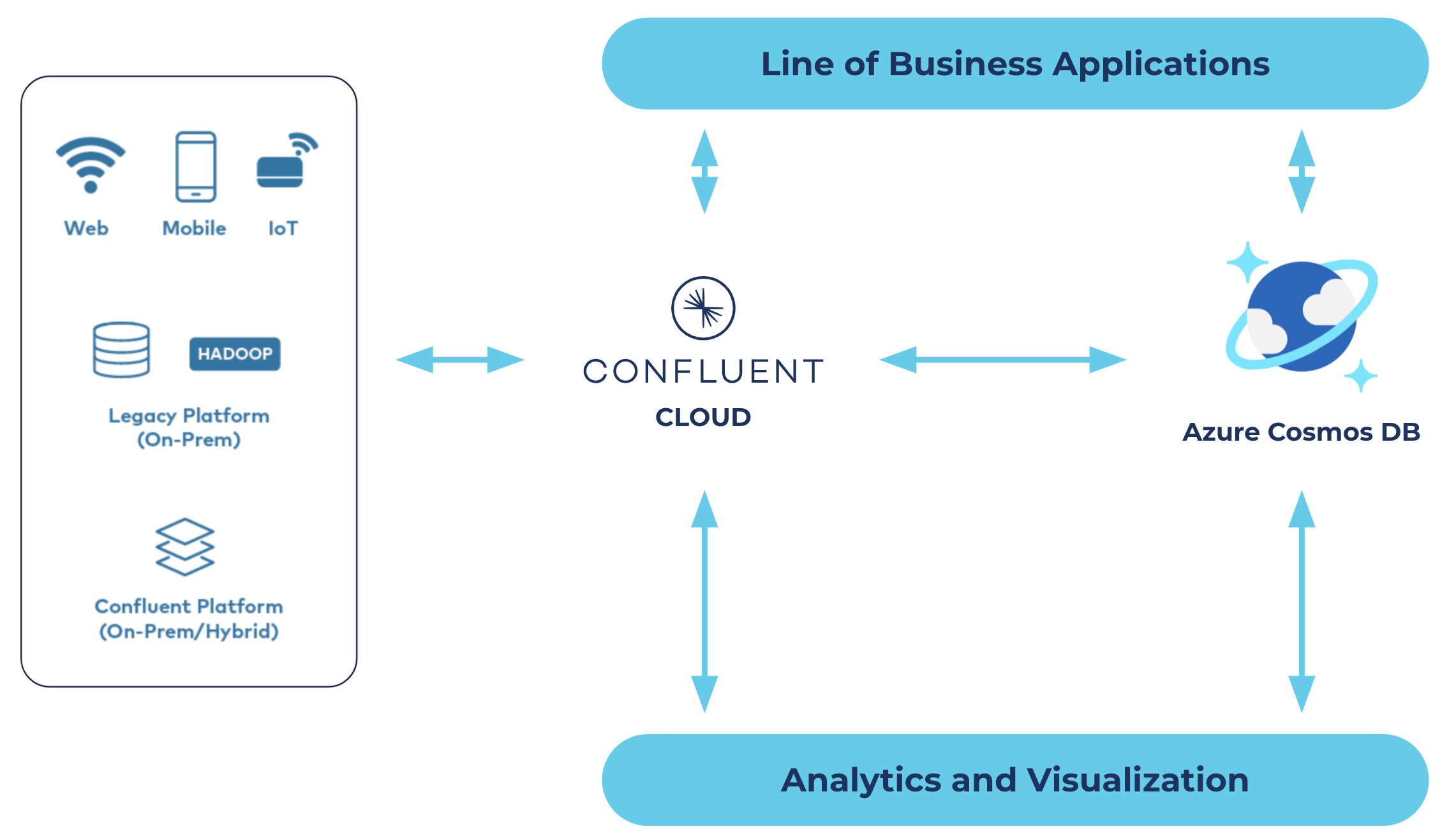 Confluent Cloud and Azure Cosmos DB overview
Confluent Cloud and Azure Cosmos DB overview
Our new fully managed connector eliminates the need for the development and management of custom integrations, and thereby reduces the overall operational burden of connecting your data between Confluent Cloud and Azure Cosmos DB.
“Kafka makes up a central component in many microservice architectures today. We are excited to work with the Confluent team to make the Cosmos DB Sink connector available in Confluent Cloud. With Kafka’s rich ecosystem of source and sink connectors for a plethora of data stores, microservices can easily communicate with each other and downstream services, while operating independently on a database that best fits their immediate function.” -Abinav Rameesh, Senior Product Manager, Microsoft
Before we dive into the Azure Cosmos DB Sink Connector, let’s recap what Azure Cosmos DB is and what it does.
What is Azure Cosmos DB and how does Confluent make it better?
Azure Cosmos DB is a fully managed NoSQL database offering with financially backed latency and availability SLAs, enabling apps to run at scale. Azure Cosmos DB has been adopted by many industry leaders for various use cases including fast and scalable IoT device telemetry, real-time retail services, and critical applications with distributed users. Confluent’s fully managed connector is the easiest means to prepare the data that brings these use cases to life with Azure Cosmos DB, no matter where the data comes from or where it needs to land.
Azure Cosmos DB Sink Connector for Confluent Cloud in action
Many Azure Cosmos DB customers use Azure Cosmos DB as part of their database migration or database modernization. Let’s look at how you can create a CDC pipeline between Oracle Database and Azure Cosmos DB with Confluent’s self-managed connector for the Oracle CDC Source and fully managed Azure Cosmos DB Sink.

Unlock data from Oracle databases to drive more innovative real-time customer experiences
Demo scenario
Your company—we’ll call it Blue Mariposa—is a big Oracle shop and runs Oracle databases to store almost everything related to the business. Blue Mariposa plans to build various applications including a real-time recommendation engine based on customers’ data and order data. You might be able to build a few applications directly on top of your existing Oracle databases, but since the company plans to build out hundreds or thousands of real-time applications, getting the required data directly from the transactional Oracle databases would not be ideal. The company decided to adopt Azure Cosmos DB and is looking for a scalable way to move data from Oracle Databases and other sources to Azure Cosmos DB.
Confluent’s Oracle CDC Source Connector can continuously monitor the original database and create an event stream in the cloud with a full snapshot of all of the original data and all of the subsequent changes to data in the database, as they occur and in the same order. The Azure Cosmos DB Sink Connector can continuously consume that event stream and apply those same changes to Azure Cosmos DB.
Using Oracle CDC Source
You can run the connector with a Kafka Connect cluster that connects to a self-managed Kafka cluster, or you can run it with Confluent Cloud.
For our example, we’re using a Kafka cluster running on Azure in Confluent Cloud. You can follow the steps I outlined in my previous blog post Oracle CDC Source Premium Connector is Now Generally Available to run a self-managed Oracle CDC Source Connector against Confluent Cloud.
Once the connector is running, as new records are coming to the Oracle tables MARIPOSA_CUSTOMERS, MARIPOSA_ORDERS, and MARIPOSA_ORDERDETAILS, the connector captures raw Oracle events in the oracle-redo-log-topic and writes the change events to table-specific topics.
- MARIPOSA_CUSTOMERS writes to ORCL.ADMIN.MARIPOSA_CUSTOMERS
- MARIPOSA_ORDERS writes to ORCL.ADMIN.MARIPOSA_ORDERS
- MARIPOSA_ORDERDETAILS writes to ORCL.ADMIN.MARIPOSA_ORDERDETAILS
Using Azure Cosmos DB Sink
Now that we have streams of all of the data from the Oracle tables in Confluent Cloud, we can put it to use. In our scenario, we were required to send these records to Azure Cosmos DB, and we’ll do that using the Azure Cosmos DB Sink Connector. Because we’re using Confluent Cloud, we can take advantage of the fully managed connector to accomplish this.
As of this writing, the Azure Cosmos DB and the Kafka cluster must be in the same region. Since the Kafka cluster used in this demo is running on Azure US Central, Azure Cosmos DB is also created in US Central with SQL API.
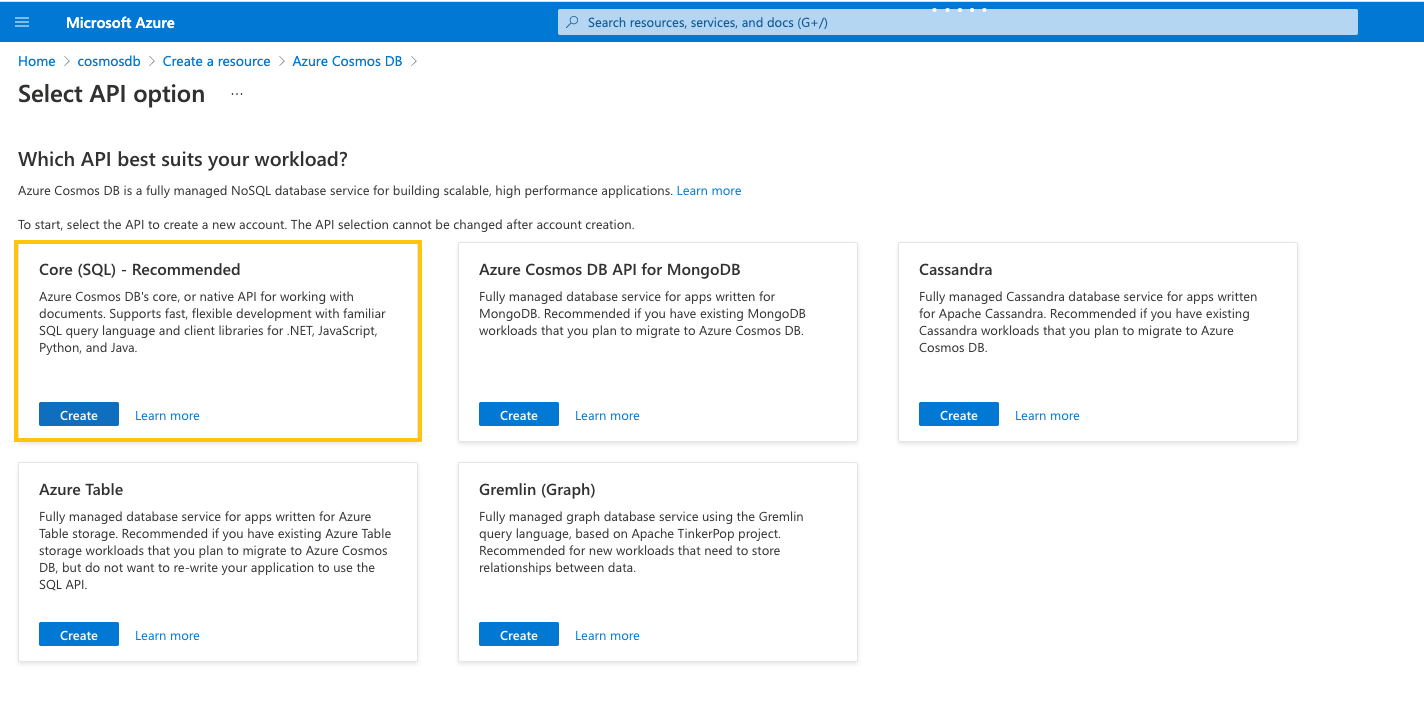
Azure Cosmos DB has a requirement; it requires all records to have an id field in lowercase. We understand that not every record would have this field, so we came up with a few handy id strategies users can leverage.
- FullKeyStrategy: Uses the record key as id
- KafkaMetadataStrategy: Uses a concatenation of the kafka topic, partition, and offset as id (${topic}-${partition}-${offset})
- ProvidedInKeyStrategy: Uses the id field found in the key object as id
- ProvidedInValueStrategy: Uses the id field found in the value object as id
Let’s look at how these strategies work with the following Kafka record.
| Kafka record key | {“id”: 123, “timestamp”: “1626996461000”} |
| Kafka record value | { “Id”: “456”, “first name”: “Giannis”, “last name”: “Antetokounmpo”, “Country”: “Greece” } |
| Kafka topic | ORCL.ADMIN.MARIPOSA_ORDERDETAILS |
| Partition | 0 |
| Offset | 20 |
| id strategy | id value in Cosmos DB |
| FullKeyStrategy | {“id”: 123, “timestamp”: “1626996461000”} |
| KafkaMetadataStrategy | ORCL.ADMIN.MARIPOSA_ORDERDETAILS-0-20 |
| ProvidedInKeyStrategy | 123 |
| ProvidedInValueStrategy | 456 |
Once containers are created in Cosmos DB, you can create a fully-managed Cosmos DB Sink Connector with a few clicks. Three topics will be mapped to the following containers in Cosmos DB.
- ORCL.ADMIN.MARIPOSA_CUSTOMERS maps to customers
- ORCL.ADMIN.MARIPOSA_ORDERS maps to orders
- ORCL.ADMIN.MARIPOSA_ORDERDETAILS maps to orderdetails
Heading over to Azure Cosmos DB, you’ll see the containers customers, orders, orderdetails, and tables are being populated with data.
You now have a working CDC pipeline from an Oracle database through to Cosmos DB using Confluent’s self-managed Oracle CDC Source Connector and fully managed Azure Cosmos DB Sink Connector.
Learn more about the Azure Cosmos DB Sink Connector
To learn more about Azure Cosmos DB Sink Connector, please register for the online talk, where we will feature a demo and a technical deep dive.
If you’d like to get started with Confluent Cloud, sign up in Azure Marketplace and get a free trial of Confluent Cloud.*
Further reading
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...