Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
What is Generative AI?
Generative artificial intelligence (GenAI) refers to AI models that generate new content such as text, images, audio, and videos based on the data they were trained on. GenAI relies on deep learning patterns combined with natural language processing algorithms to analyze patterns in large data sets to generate real-time, contextually relevant responses.
ChatGPT
Developed by OpenAI, ChatGPT is a conversational AI model that interacts with users in a human-like manner. It can answer questions, provide explanations, and engage in dialogue on a wide range of topics. By leveraging advanced natural language processing (NLP) capabilities, ChatGPT is used in customer service, education, and personal assistant applications, making sophisticated AI technology accessible to the general public.
GitHub Copilot
A collaborative project between GitHub and OpenAI, GitHub Copilot is an AI-powered code completion tool that assists developers by suggesting code snippets and entire functions in real time as they write code. It enhances productivity by reducing the amount of boilerplate code developers need to write and helps newcomers learn programming faster by providing context-aware suggestions. GitHub Copilot leverages large language models to understand and generate code across various programming languages.
Stable Diffusion
Stable Diffusion is an advanced AI model for generating high-quality images from textual descriptions. It utilizes diffusion models to create realistic and artistic visuals based on user prompts. This tool is particularly valuable for artists, designers, and content creators who need to generate visuals quickly and efficiently. By lowering the barrier to entry for visual content creation, Stable Diffusion empowers individuals and small businesses to produce professional-grade graphics without extensive resources or technical expertise.
How GenAI Works
GenAI starts with a prompt. A user submits a query, then GenAI produces meaningful and contextual content that’s precisely tailored for the user. To create these outputs, AI models combine two key components: deep learning patterns and natural language processing (NLP) algorithms.



Deep learning is a subset of machine learning that employs multi-layered neural networks to model complex patterns in data. It uses architectures like Convolutional Neural Networks (CNNs) for image processing and Recurrent Neural Networks (RNNs) for sequential data. Training involves adjusting weights through backpropagation and gradient descent, requiring large datasets and significant computational power. Deep learning excels in applications such as computer vision, natural language processing, and speech recognition, delivering state-of-the-art performance in tasks previously challenging for traditional machine learning methods.
GenAI generally leverages deep learning techniques. It can use CNNs for tasks like image and video generation and RNNs for certain sequential data tasks. However, for natural language processing, it primarily uses advanced neural network architectures known as transformers. Transformers excel at handling sequential data and capturing long-range dependencies. The transformer architecture, introduced in the paper 'Attention is All You Need' by Vaswani et al. in 2017, has become the foundation for many state-of-the-art NLP models, including those used in GenAI.
Transformers use vectors to represent words as numerical arrays. These vectors undergo transformations through self-attention, which calculates the importance of each word relative to others, and positional encoding, which adds sequence order. Multi-head attention and feed-forward layers refine these vectors for complex data processing and generation.



Models like GPT are pre-trained with transformers on massive text compilations to learn language patterns and then fine-tuned for specific tasks such as translation and summarization. This approach enhances contextual understanding and enables transfer learning, reducing the need for extensive labeled data. GenAI's generative capabilities allow it to create human-like text, answer questions, and simulate conversations, offering fine-grained control over text generation by adjusting input prompts or model parameters.
AI model generation is the process of creating and refining AI systems to perform specific tasks. Traditional AI models, often used for prediction, focus on analyzing historical data to forecast future outcomes. These models are typically employed in applications such as sales forecasting, risk assessment, and recommendation systems, where they identify patterns and make informed predictions or classifications based on past data.
What are LLMs?
The process of creating, refining, and optimizing AI models is integral to the development and enhancement of LLMs, enabling them to generate high-quality, contextually appropriate content and perform a broad range of language-related tasks.
LLMs used in GenAI use refined AI model generation processes. Here are some examples:
Pre-training
LLMs are initially trained on extensive datasets containing diverse and large amounts of text. This phase helps the model learn general language patterns, grammar, and contextual relationships.
Fine-tuning
After pre-training, LLMs undergo a fine-tuning process where they are further trained on smaller, task-specific datasets. This step refines the model's abilities to perform specific tasks such as language translation, text summarization, or question-answering.
Iterative Improvement
The models are iteratively improved through cycles of training, evaluation, and adjustment. Feedback from their performance on various tasks is used to refine their parameters and enhance their accuracy and efficiency.
Specialization
In some cases, additional techniques like transfer learning are applied, where a pre-trained model is adapted to new tasks with minimal data. This specialization helps the model become more effective in particular applications.
What’s Different About GenAI: Reusable Foundation Models
Data engineering has evolved from mining historical data to a more real-time, prompt-based approach. Instead of relying on static data, GenAI uses prompts to pull relevant data in real time. This shift simplifies the process by eliminating the need for complex statistical functions, replacing them with a vector search. Vector searches, powered by machine learning, sift through unstructured data, offering a streamlined way to find relevant data points without the need for extensive data processing.
LLMs trained on generic, publicly available data can be enhanced with retrieval-augmented generation (RAG). RAG is an architectural pattern that integrates real-time, context-specific data to help LLMs at prompt time.
Traditional methods of training models on static data can lead to outdated results. For example, if flights are canceled due to a storm, an older model might not be aware of this recent development. In contrast, GenAI using an LLM-RAG pattern can access and utilize real-time data to generate more current and accurate responses.

Predictive Artificial Intelligence
Predictive Artificial Intelligence applies statistical models to forecast outcomes based on patterns from historical data. These models analyze past behaviors and trends to make informed predictions about future events.
Creating these models requires meticulous data engineering and feature engineering. Data engineers must curate and preprocess data, ensuring its quality and relevance. Feature engineering involves selecting and transforming variables that can effectively capture the underlying patterns within the data. This bespoke approach tailors machine learning models to meet specific use cases, optimizing their accuracy and reliability in making predictions.
Generative Artificial Intelligence
GenAI uses deep learning models to rapidly create tailored content from static data and real-time prompts. It employs reusable models (e.g., foundation models) trained on extensive, publicly available datasets. These models undergo end-to-end learning once, making them versatile and applicable across various use cases, optimizing the generation of new and relevant content.
Unlike traditional models that require extensive statistical analysis on specific data sets, foundation models such as LLMs rely on prompt-time data engineering. This approach leverages the vast amount of training data already incorporated into the model, reducing the need for bespoke data preparation.
The broad applicability of LLMs streamlines the development process, allowing for quicker deployment and adaptation across different domains and industries.
Why Generative AI is Important: Benefits
According to McKinsey, GenAI could add between $2.6 trillion to $4.4 trillion annually across various use cases. McKinsey predicts that "75 percent of the value that GenAI use cases could deliver falls across four areas: Customer operations, marketing and sales, software engineering, and R&D." GenAI offers numerous benefits that transform business operations, including:
GenAI revolutionizes the way work is done by automating tasks and quickly processing vast amounts of data, leading to improved decision-making. Tools such as chatbots and virtual assistants enhance customer service by providing real-time assistance, helping customers navigate product selections without human intervention. Rather than replacing people, GenAI enhances worker productivity, potentially doubling the efficiency of tasks. Most workers who leverage the technology may see at least 10% of tasks done twice as quickly. For instance, a sales team using GenAI could be twice as productive in certain tasks.
GenAI saves significant time and cost across various tasks such as text-to-speech audio, design and image creation, video production, music editing, coding, and 3D modeling. By performing low-level and time-consuming tasks, GenAI provides immediate insights for fast decision-making, improving efficiency, and reducing operating costs.
GenAI facilitates innovation, particularly in research-intensive industries, by lowering barriers. In the pharmaceutical industry, for example, GenAI can expedite research and development processes, reducing lead identification in drug discovery from months to weeks. In retail, GenAI enables businesses to personalize new offerings based on customer data, leading to improved customer satisfaction.
GenAI opens up opportunities for small and medium-sized businesses (SMBs) that find a new niche, helping close content, technology, and human resource gaps with large enterprises. SMBs can adapt in agile ways, much like a turning speedboat versus an aircraft carrier. GenAI accelerates this process, allowing SMBs to optimize resources and respond rapidly to market changes and opportunities.
GenAI is an especially powerful toolkit for creative endeavors. It can instantly generate a storyboard for a movie and refine it based on live feedback. The same applies to marketing content creation or determining new product features to add. GenAI surfaces immediate recommendations for what to do with a project. The speed and completeness of the information provided by GenAI streamline the decision-making process, leading to more effective strategies and better outcomes. This capability enables businesses and teams to meet evolving market demands, with faster and more comprehensive development processes.
GenAI simplifies the process of acquiring knowledge. Instead of searching multiple search engines or scrolling through countless reviews or documents, users can query GenAI. The quality of content produced by GenAI is constantly improving. For example, traditionally, high-quality videos took weeks to produce with high production costs and crew involvement. Now, creating high-quality videos takes moments. This enables individuals to execute large-scale and expensive projects quickly and also refine them with GenAI for faster, better results. Post-processing also helps ensure accuracy.
Challenges and Considerations
Despite its immense potential, the adoption of GenAI poses several challenges:
Hallucinations can be compelling, articulate, thorough, and wrong. When wrong, these can have significant consequences–including legal repercussions–to business ops and reputation.
Understanding how GenAI works, building, and integrating it into existing workflows takes time and resources. Early adopters exist, but there is a significant gap before the entire developer population can implement GenAI effectively. Bridging this knowledge gap requires understanding advanced AI capabilities, how large language models (LLMs) work, the type of data needed to train models, and how to build patterns like retrieval-augmented generation (RAG). Continuous education on concepts like RAG is essential for AI adopters.
GenAI is only as good as the data set it is trained on. To prevent knowledge gaps and hallucinations, the model needs access to more data sets, such as real-time, domain-specific data, proprietary data within an organization, customer data including PII, in order to generate meaningful and accurate responses. However, data is often spread across databases, data warehouses, SaaS applications, message queues, and file systems, creating rigid enterprise data architectures with tightly coupled producers-consumers, point-to-point connections, and batch processing. These complexities, along with data governance and security issues, contribute to stale, low-quality data.
Staying updated on the latest AI technologies and best practices is essential for successful adoption. To navigate GenAI’s ever-changing landscape, users need to discern which LLM, language processor, vector database, and vector embedding to use. In addition to the many options available, new ones are constantly coming into the market.
There are also tradeoffs between using smaller versus big-name tools. While smaller tools offer flexibility, concerns exist around the need for rewriting existing components. On the other hand, big-name tools may offer robustness, but their slower pace in implementing new features could be a disadvantage.
Developing custom AI tools can have significant business impacts, particularly regarding AI governance, enterprise data management, and legal and privacy issues. For example, if a customer service AI chatbot provides false answers or reveals sensitive information, it could lead to customer dissatisfaction, churn, and potential litigation, damaging the brand and reputation. Similarly, job sites using LLMs to analyze resumes must address data privacy concerns. Ensuring AI governance, security, and trustworthiness is crucial to mitigating these risks.
While organizations can leverage an LLM as a starting point, they need people and technology resources to build and support customer-facing GenAI applications. The availability of AI-specialized architects, developers, and data engineers is uneven across regions. Ensuring access to these skilled professionals is crucial for the successful implementation and maintenance of GenAI solutions.
GenAI Use Cases
GenAI finds broad application across many industries and use cases. Here are some examples of popular real-time GenAI use cases:
Semantic Search
GenAI enhances search capabilities by understanding the context and semantics of queries, delivering more accurate and relevant results.
Customer Service
GenAI-powered chatbots and virtual assistants provide real-time assistance, efficiently answering customer queries and resolving issues, which improves overall customer satisfaction.
Content Discovery & Recomendation
GenAI personalizes content recommendations based on user preferences and behavior, boosting user engagement and satisfaction.
Agents (Task Automation)
GenAI automates routine tasks such as scheduling, data entry, and report generation, thereby increasing operational efficiency and allowing employees to focus on more strategic activities.
Logistics Optimization
GenAI improves logistics by analyzing and optimizing supply chain operations. It helps in route planning, inventory management, and demand forecasting, ensuring timely deliveries and reducing operational costs. This enhances the overall efficiency and reliability of logistics and supply chain networks. Significant investments are being made in GenAI-enabled logistics, but this use case hasn't yet seen the same success as other applications.
Additional GenAI use cases include:
GenAI is used for tasks like writing and summarizing text, generating code, and creating chatbots. It helps computers understand and respond to human language more effectively.
GenAI can transcribe spoken words, making it easier to input information without typing. Similarly, it can generate audio from text. GenAI can also analyze sounds to detect patterns or issues, such as determining the purity of metals or diagnosing engine problems by listening to specific noises, offering valuable applications in industries like manufacturing and logistics.
GenAI can produce images and videos, quickly visualizing concepts and generating new creative content. In retail, it assists in training warehouse robots. In the automotive industry, it aids self-driving cars by gathering and processing live image data from many cars driving on different roads, enhancing navigation capabilities and reducing the need for extensive model training. Live data feeds from cars can train LLMs to visually recognize objects like cars, pedestrians, and trees.
Synthetic data expedites the testing process and accelerates the training of machine learning models. Enabling quicker development cycles, synthetic data serves as a rapid and efficient method for prototyping and building applications.
For robotics and manufacturing, synthetic data helps create a digital twin of a factory for testing process flows. This optimizes interactions between humans and robots and identifies potential bottlenecks in manufacturing inefficiencies, such as machine placement issues causing delays. This knowledge enables adjustments to enhance overall production, including relocating machines to minimize disruptions and mitigate risks (e.g., eliminating the cross-traffic risk of a human running into a robot).
Synthetic data also aids time-motion studies to optimize factory output. These studies involve direct and continuous observation of tasks to reduce production costs, a method initially pioneered by Ford. Traditionally, time-motion studies require significant human time and effort. In contrast, machine learning can run numerous scenarios autonomously, providing the most optimized flow for manufacturing lines, air traffic control, or airport construction. For instance, machine learning insights might indicate the need for larger landing lanes on the east side of a terminal, informing airport design based on accumulated data.
For information privacy, GenAI can generate synthetic data without breaching trust, privacy or security. This synthetic data allows for sharing with business partners for testing and integration purposes, without exposing sensitive information like personal identifiable information (PII). Additionally, generating data schemas provides a clear understanding of how the data will be used and processed.
GenAI creates realistic 3D models for virtual prototyping and testing real-world scenarios in various industries. In urban planning, GenAI simulates traffic flows to predict congestion patterns and optimize transportation routes. In manufacturing, it simulates production processes to identify potential bottlenecks before they occur. For logistics, GenAI minimizes delays through rapid analysis of real-time data, dynamically adjusting shipping routes based on real-time weather, traffic, or delays to identify the most efficient, cost-effective, and shortest land and sea routes.
Types of Generative AI Models
GenAI relies on neural networks to identify patterns within existing data to generate new, original content. It uses foundation models, such as LLMs, which are trained on vast amounts of unlabeled data. There are different types of GenAI models, including:
Diffusion Models
Diffusion models create high-quality outputs, including life-like imagery and coherent sentences. These models train by adding noise to a dataset and then reverse the process through progressive denoising, learning to recognize and generate data by reversing this noising process.
Generative Adversarial Networks (GANs)
A type of deep learning architecture, GANs consist of two neural networks that work together to produce realistic data samples. One network generates data (the generator), while the other evaluates it (the discriminator). In competing against one another, GANs continually improve, creating increasingly authentic outputs.
Variational Autoencoders (VAEs)
VAEs compress input data into a latent space—a compact representation of essential features—and then reconstruct it. They generate new data samples by sampling from this latent space, allowing for the creation of novel and diverse outputs.
Autoregressive Models
Autoregressive models predict the next element in a sequence by analyzing previous inputs from the same sequence. These models are commonly used in tasks like text generation, where each word is generated based on the preceding words. These models are often used in tasks like predicting the next word in a sentence.
Recurrent Neural Networks (RNNs)
RNNs are a type of neural network architecture designed to process sequential data by retaining information from previous steps, making them well-suited for tasks involving time-series or sequential data. These models were the go-to before transformer models with a high accuracy rate in tasks like text prediction. Although they're used alongside LLMs for their combined strengths, they are not as efficient as transformers.
Transformer Models
Transformer models are a type of neural network architecture known for their self-attention mechanism and natural language processing ability. These models serve as the basis for GPT, Claude, Llama, and Gemini, and blend RNNs within LLMs. Typically trained on public data, these models understand context and predict future elements in a sequence with high accuracy.
Building Generative AI with Confluent



Data Augmentation: Often, the first step in building a GenAI application is developing and populating a vector store for retrieval-augmented generation (RAG). Confluent plays a crucial role in this process. Let's first address data augmentation and how you can build a real-time contextual knowledge base for your GenAI applications.
Confluent simplifies the integration of disparate data across your enterprise through our comprehensive connector strategy. With over 120 connectors, Confluent facilitates real-time data sourcing and synchronization. For example, if you need to integrate data from S3 and Salesforce, Confluent has pre-built connectors to seamlessly ingest and integrate this data into Confluent. This capability ensures that the latest versions of your proprietary data, whether related to customers or business operations, are instantly accessible to power your GenAI applications.


Given that these data streams often contain raw information, processing is essential to refine the data into a more usable format. Stream processing allows you to transform, filter, and aggregate individual streams into views suitable for various access patterns.
Next, you can use Flink SQL model functions to handle data chunking and embeddings using a vector embedding service, which then passes the processed data to a vector store. Confluent has built native integrations with leading vector stores such as MongoDB, Pinecone, Weaviate, Zilliz, and others.
Prepare data for a real-time knowledge base and contextualization in LLM queries
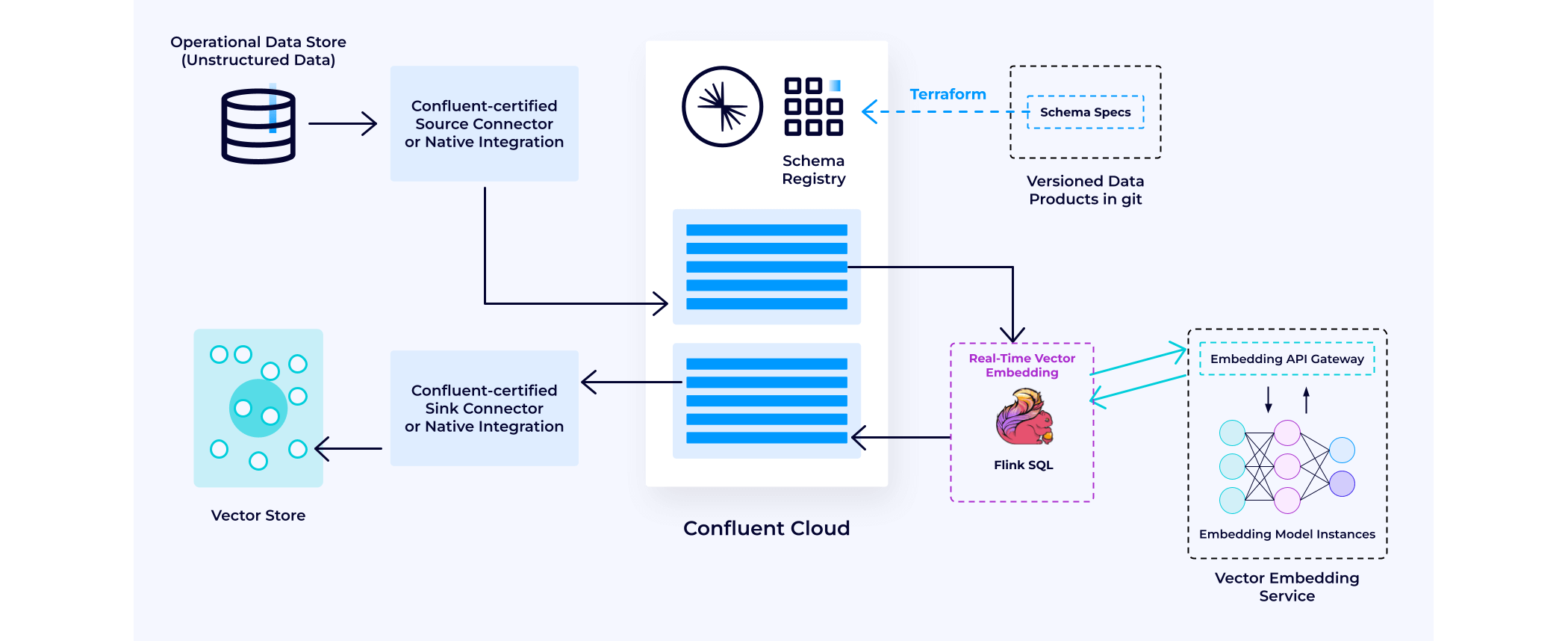
This pattern allows for continuous real-time updates to the vector store. It enables you to populate and maintain a vector database without cumbersome point-to-point batch ETL processes, which inherently delay information.
All of this is built on the event-driven architecture pattern. This means that once your corporate knowledge is encoded in a vector store, it can be semantically related to future prompts in an accessible pattern. When new prompts arrive, Confluent can identify the most relevant corporate knowledge and supply it to the LLM, enhancing future responses.
4 Steps to Build a GenAI Application
LLM-enabled applications typically follow these four steps. Here's a summary of each step and how Confluent is used:
Data Augmentation
This involves preparing data to ensure your GenAI app can access the most recent and up-to-date dataset and contextualize that data in LLM queries. It’s about building a real-time knowledge base for your GenAI applications.
Confluent continuously ingests and processes data streams from various data sources to create a real-time knowledge base. In this phase, a tool like Flink SQL can call a vector embedding service to augment the data with vectors. The processed data is then stored in a vector database using a sink connector. This setup enables retrieval-augmented generation (RAG) against the vector database with continuously updated information.
Inference
This step focuses on contextualizing user queries and ensuring your GenAI applications can effectively handle those responses.
In Confluent, a consumer group takes the user question and prompt from the Kafka topic and enriches it with private data from the vector store database. This process involves inspecting the user's query and using it to perform a vector search within the vector database, adding relevant results as additional prompts. For instance, in the case of flight cancellations, a KNN (k-nearest neighbors) search can identify the next best available flight options. This enriched and contextually relevant data is then sent to an LLM service, which generates a comprehensive response.
Workflows
This involves parsing natural language, synthesizing high-quality information, and applying contextual reasoning on the fly.
To enable GenAI applications to break a single natural language query into composable multipart logical queries and ensure real-time information availability, reasoning agents are often used. This approach is more effective than processing the entire query at once. In such workflows, a chain of LLM calls is used, with reasoning agents deciding the next action based on the prompt output, allowing for seamless interaction and data retrieval.
Post-processing
This step enforces business logic and compliance requirements with more transparent models to ensure the LLM has returned a reasonable and trustworthy answer.
Many organizations are not yet comfortable trusting LLM outputs directly. In automated workflows, every application includes a step to enforce business logic and compliance requirements. Using an event-driven pattern, the GenAI workflow can be decoupled from post-processing, allowing independent development and evolution. Confluent helps validate LLM outputs, enforcing business logic and compliance requirements to ensure trustworthy answers. This enhances the reliability and accuracy of AI-driven workflows.
Additional Resources
Get Started
Get started free with Confluent Cloud to start building a real-time, contextualized, and trustworthy knowledge base for your GenAI use cases.