[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Walmart’s Real-Time Inventory System Powered by Apache Kafka
Consumer shopping patterns have changed drastically in the last few years. Shopping in a physical store is no longer the only way. Retail shopping experiences have evolved to include multiple channels, both online and offline, and have added to a unique set of challenges in this digital era. Having an up to date snapshot of inventory position on every item is a very important aspect to deal with these challenges. We at Walmart have solved this at scale by designing an event-streaming-based, real-time inventory system leveraging Apache Kafka®. Furthermore, like any supply chain network, our infrastructure involved a plethora of event sources with all different types of data contributing to net change to inventory positions, so we leveraged Kafka Streams to house the data and a Kafka connector to take the data and ingest it into Apache Cassandra and other data stores.
Managing vast data sources
With Walmart’s inventory architecture, it was near impossible to mandate source teams to send events to the same schema. So, the team elected to implement a canonical approach to streamline data sources.
The primary goal was to accelerate delivery and simplify integration. With more than 10 sources of event streaming data, and one or more events likely derived from inventory data, this meant we needed a few sets of input data, such as item, store, quantity, and type of event. The responsibility to read and convert data into a common inventory was the duty of our central system. To do so, we developed a smart transformation engine, which would read input data from various source topics and convert it into a common inventory. The canonical data would then get streamed further down the system to become part of the debit/credit system, ultimately leading to the creation of an inventory state for an item store.
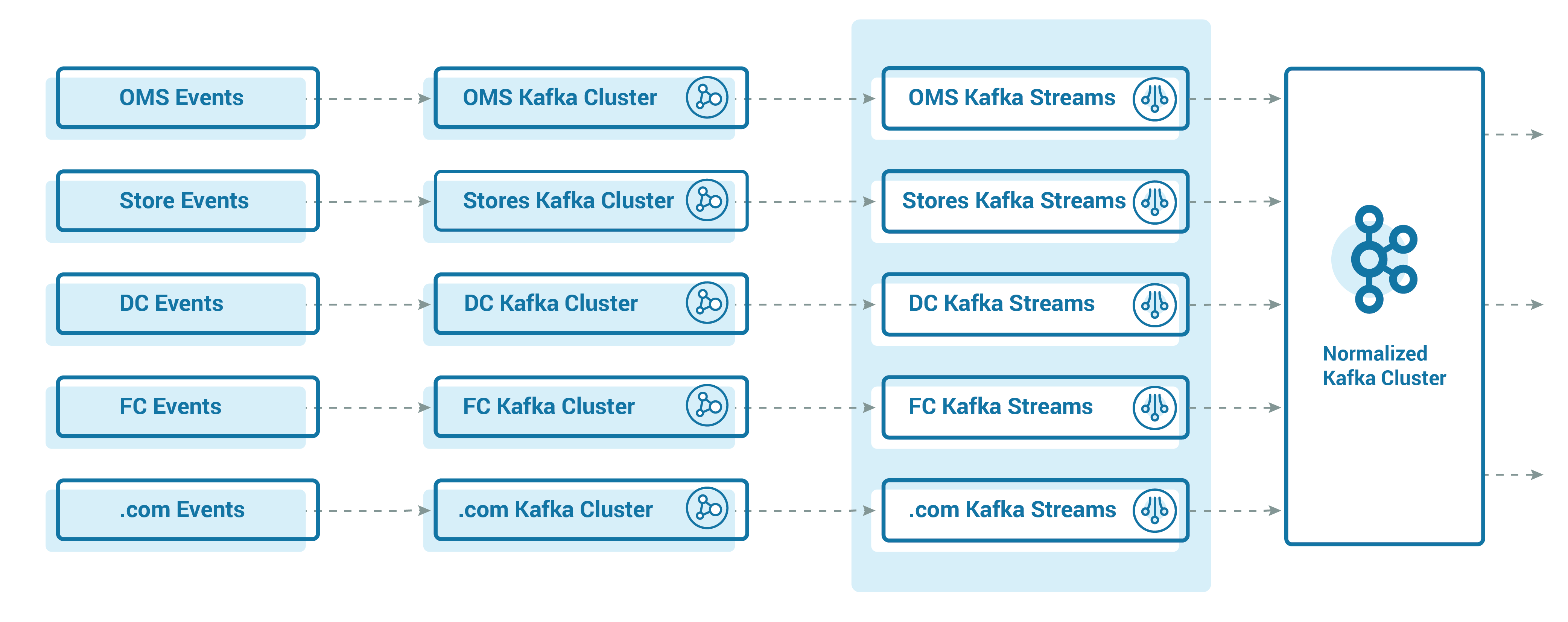
Achieving scale
Today, the ability to scale is a must-have feature of any event streaming architecture, or batch architecture for that matter. Kafka extends scalability through its partitions.
While adding partitions is a step in the right direction, understanding the underlying hardware, filesystem type, available storage, memory, and more, is also essential.
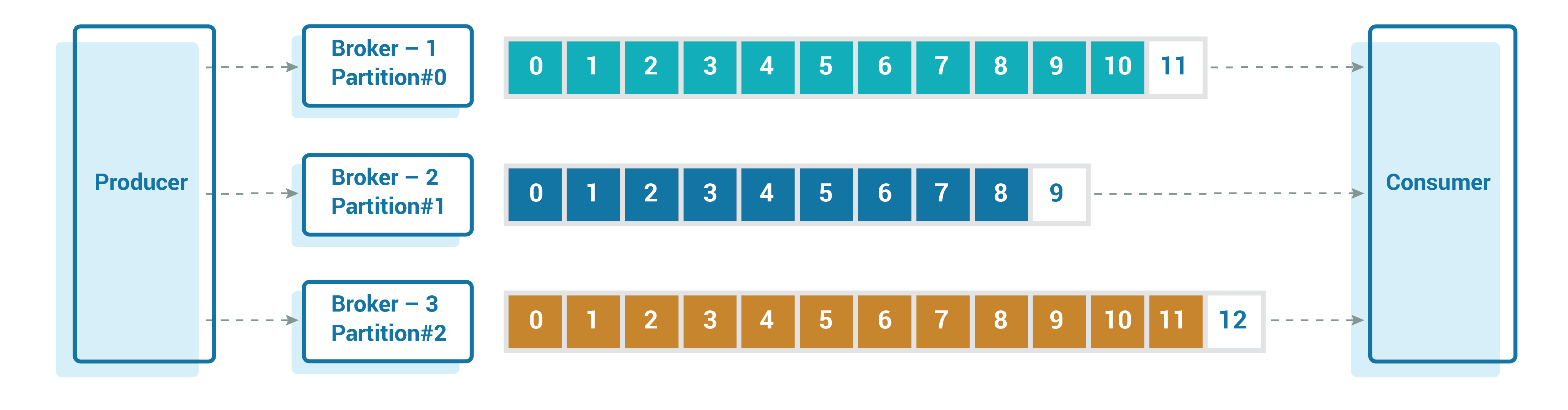
It’s important to understand the underlying physical space and configurations in order to increase partitions. Up until the latest versions of Kafka, partitions could not be split between multiple brokers and needed to point to a single location of storage in a broker, which could be a single mount point. In our case, we did it with multiple disks using RAID configurations. A log.dirs configuration defines the directories where Kafka will store the data.
Alongside increasing partitions, we also needed to make the producers capable of sending more data, and consumers capable of processing more of it. Producer scaling is pretty tricky. We needed to have a good compromise between latency per message and saving on network I/O. We adjusted the linger.ms and batch.size properties to make sure we had a sizable batch of data before we flushed the data to the Kafka broker. This is an area you will need to experiment with based on your own dataflow in order to set the right values while considering the overall SLA and network bandwidth.
The other parameter to take note of is acks. Setting acks to 0 is almost suicidal for a business-critical application like ours. We had a good compromise by setting acks=1, which allowed the leader to confirm before processing the next request in flight. In summary, be sure to take a close look at the most common producer configuration in line with your SLA needs and key business objectives around reliability.
Consumer scaling is no less trivial. It’s important to understand how many consumers or listeners (belonging to the same consumer group) you need to support the scale, which is reflected in the number of partitions. As Kafka allows only one consumer to read from one partition, we needed to make sure we had the number of consumers close to (equal to or slightly more than) the number of partitions. It’s also important to understand the hardware/server that the consumers in the consumer group are running on. We needed to know the number of cores that are available on those servers as each core would, in essence, be a single consumer thread for optimized performance.
Again, it’s important to experiment. We started with having the number of servers as the ceiling (number of partitions/number of cores per server). We checked the CPU, memory, and other resource usage, and then kept tuning to an optimum value in the vicinity of 50%. Be sure to base your call on your specific use case. It’s also important to understand the commit cycles through various settings like max.poll, records, session.timeout.ms, heartbeat.interval.ms, etc.
For more details on this topic, check out this blog post.
Maximizing the underlying database
After implementing all of the required steps to achieve scale and reliability, we needed to ensure that we didn’t choke the system at the end. It is important to have a database table designed to store your data with the right amount of partitions. We had a case where we needed to make sure that no two consumer threads updated the inventory for the same item store, which could create deadlocks or even unreliable data. For example, what if one thread/consumer is reading an item store and updating the value of inventory in a Cassandra table/column family of 20, and then a subsequent thread updates to 22? To manage this, we implemented a partition strategy whereby each item store always goes to a specific partition. As a result, we ensured that only one consumer deals with that item store combination.
Choosing the right partitioning strategy in Cassandra can also help minimize latency. If your use case needs updates to existing records in the database, then you can align your Kafka partitioning strategy with your Cassandra partitioning strategy. It is also recommended that you make sure to have the right database size to handle an increase in the scale of data coming through Kafka.
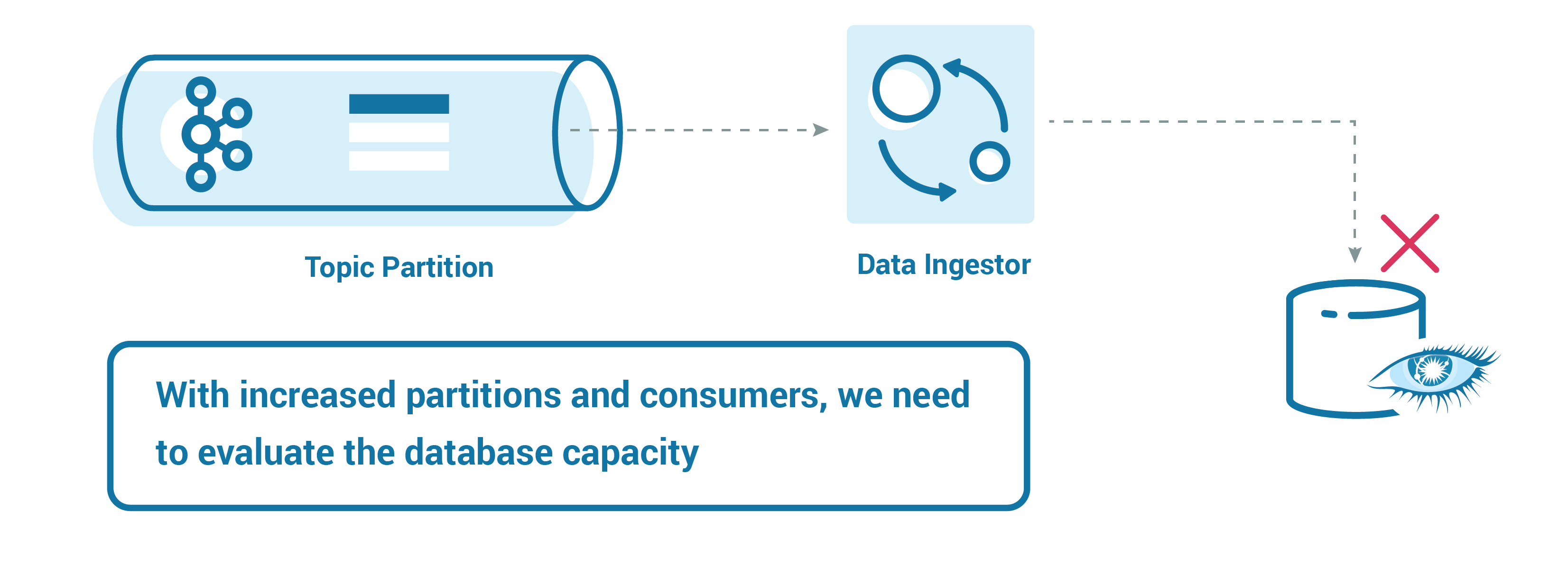
Depending on the type of database you leverage, consider the access pattern of the data at scale, which is the factor that matters most.
Kafka is at the heart of Walmart’s inventory backend architecture, and works exceptionally well with the right tooling in place. For more on Kafka at Walmart, watch my Kafka Summit presentation.
Disclaimer: the views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy or position of Walmart Inc. Walmart Inc. does not endorse or recommend any commercial products, processes, or services described in this blog.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



3 Strategies for Achieving Data Efficiency in Modern Organizations
The efficient management of exponentially growing data is achieved with a multipronged approach based around left-shifted (early-in-the-pipeline) governance and stream processing.



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.