[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Implementing Message Prioritization in Apache Kafka
Users of messaging technologies such as JMS and AMQP often use message prioritization so that messages can be processed in a different order based on their importance. It doesn’t take much imagination to see where this can be useful—call center companies will want to handle the most severe cases first, then others; airline companies give preference to their service treats to customers with higher status, and telecommunication companies would probably give their most loyal customers a better renewal promotion.
One of the misconceptions that developers have when they first encounter Apache Kafka® is that it is just another messaging system, just like the ones they’re familiar with. By extension from that, they get disappointed when they find that Kafka doesn’t offer message prioritization.
Now, as anyone who has spent a moderate amount of time around Kafka will know, Kafka itself is an event streaming platform. Those words may sound fancy but they are important because they describe what Kafka is and by inference what it isn’t. This gives us a starting point for understanding why Kafka doesn’t support message prioritization—and how we can implement something which is almost as good as a technology that does.
Why doesn’t Kafka support message prioritization?
As an event streaming platform Kafka is focused on data streams and how to efficiently capture, store, process, and deliver these data streams to different applications. While exploring the key differences between messaging and event streaming platforms is out of scope of this blog post, there is one thing that we can agree on without needing to go into all the details: Given that Kafka is not messaging, you shouldn’t expect features like message prioritization from it.
Storage
Kafka is built around the core concept of a commit log. This is a data structure that organizes data in a form of a journal where new records are always appended to the tail of the journal and each record is assigned a position number that acts as its unique key. Through time, this journal can have many concurrent readers to read the data back and forth. In order for the commit log to ensure that all readers are reading the same data regardless of their cursor position (beginning, middle, or tail of the journal), all records must be immutable.
Being immutable here means that the record content cannot be changed, nor its position within the commit log altered. The latter is very important because it is the purpose of a commit log to capture facts—events that happened at a given point in time. Changing the position of a record is changing the circumstance that caused the event to happen and therefore invalidates one of the core guarantees that makes Kafka such a powerful platform to build distributed applications such as microservices. If it wasn’t for the commit log for example—there would be no way to implement design patterns such as event sourcing and CQRS.
Consumers
Now, let’s briefly discuss how other messaging technologies handle message prioritization. Most of them have a feature where brokers can change the order of messages given a piece of information stored on each message (JMS 1.1, for example, has the special header called JMSPriority). With this feature in place, consumers do not need to process the messages in the order that they were actually written but according to how the consumers want to process them. The bottom line here is that brokers have to adopt an extra responsibility for a need coming from the consumers.
In Kafka, the individual consumer, not the broker, must process the messages in the order that best suits them. This is one of Kafka’s strengths: The need for one consumer to process records in another order doesn’t affect other consumers of the log. The role of Kafka (and thus the commit log) is to ensure that messages are immutable, so in the context of message prioritization, we clearly have a dilemma here.
Taking a closer look at Kafka’s design
Messages in Kafka are organized into topics. Topics provide a simple abstraction such that as a developer you work with an API that enables you to read and write data from your applications. Under the hood it is actually a little bit more nuanced than this; messages are in fact written to and read from partitions.
Partitions play a critical role in making Kafka such a fast and scalable distributed system. Kafka is super scalable because instead of storing all the data in a single machine (known as the broker), it automatically distributes the data over available brokers in a cluster using a divide-and-conquer storage strategy. This is accomplished by breaking down topics into multiple parts (hence the name partition) and spreading those parts over the brokers. These partitions are used in Kafka to allow parallel message consumption. Having more partitions means having more concurrent consumers working on messages, each one reading messages from a given partition.
Kafka is also extremely fault tolerant because each partition can have replicas. Those replicas are hosted by different brokers. The replica brokers fetch records from the leader much in the same way consumer applications work. This means that in the event of a broker failure, partitions on the failed broker are available from the replicas. In other words, there is zero data loss in the face of failure.
In nutshell, without partitions Kafka wouldn’t be able to provide scalability, fault tolerance, and parallelism. Therefore, we have to consider partitions as a key component in any application design, including when we look at dealing with message prioritization.
But what do partitions even have to do with message prioritization? Well, quite a lot! First, because partitions are the unit of read and write and how messages are actually stored, we must keep this in mind while thinking about how to sort messages in a given order. Messages are spread over multiple brokers, so any implementation that you might come up with will have to first collect those messages from the brokers to then sort them out. This makes the code extremely complex.
Kafka’s consumer API certainly provides the means to accomplish this. It is not a problem of a client not exposing the required APIs. The problem is that most of us don’t want the hassle of having to keep track of where messages are in order to work with them. Keeping track of messages can be complicated when partitions are in constant movement—whether it is due to rebalancing, restoration from replicas, or just because someone decided to increase the number of partitions, and therefore their location had to be changed. Writing code to keep track of messages can easily become a nightmare as you need to foresee virtually all possible scenarios that Kafka’s clustering protocol has to offer.
Code simplicity is a right that you get to have with Kafka. In most cases, the code that you write to fetch messages from topics will be a combination of subscribe() and consumer.poll(), which requires no awareness whatsoever about partitions. Giving up this simplicity considerably increases the chances of creating code that is both hard to read and maintain, as well as easily broken when new releases of Kafka become available.
Sometimes there is not even a chance to change anything because you might be working with frameworks that were built on top of Kafka’s client API, such as Kafka Streams, Kafka Connect, and the Spring Framework. These frameworks expose other primitives of reading messages that make handling partitions directly impossible, as these frameworks will likely encapsulate the low-level details.
Another aspect regarding partitions in Kafka is how consumers handle high-load scenarios. Using one consumer to process messages from a topic certainly works, but there will be a time where the rate of messages being produced may surpass the rate of messages being processed, and the consumer will certainly fall behind. Luckily, Kafka provides the concept of consumer groups. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group receives messages from a different subset of the partitions in the topic.
Using consumer groups helps with high-load scenarios using a simple yet powerful construct. There is only one problem though: All consumers within the consumer group will process the messages without any notion of priority. This means that even if we add some information on each message (such as a special header entry just like JMS 1.1), the consumers won’t be able to use this information correctly because they will be working on a different subset of partitions. Moreover, these consumers may be executing on different machines so coordinating the execution of all of them will become by itself another distributed system problem to solve.
Ideally, we should separate messages by priority using different consumer groups. Messages with higher priority would fall into one group while messages with less priority would fall into another group, and then each group could have a different number of consumers to work on messages. However, this is not how Kafka works. Using different consumer groups won’t split the messages among the consumer groups. Instead, it will broadcast the same messages to the consumer groups, thus generating redundancy.
In summary, Kafka’s architecture makes it even harder to implement message prioritization. While this may look like a bad thing at first, it doesn’t mean that it is impossible. The next section is going to discuss a pattern that will help implement message prioritization.
The bucket priority pattern: A “good enough” solution
Message prioritization is usually about sorting messages based on their priority so that messages with higher priority are processed first. A naive solution to this problem would be to gather all the messages first and then sort them in a given order, so that messages with higher priority come first. This solution has one problem: It requires the consumer layer to periodically wait for messages from different partitions to arrive to sort them out. This is a requirement because as mentioned earlier, messages may reside in different partitions and the partitions may reside in different brokers, so ultimately messages will be coming from different places.
The problem here is that now the consumer has to buffer messages prior to their processing. This is batching, which removes the advantage of continuously processing data streams. Moreover, high-load scenarios usually require the usage of multiple partitions, and this introduces a new challenge in the architecture. Using multiple partitions forces the consumer layer now to keep a buffer containing messages from all partitions. If only one consumer is being used, this buffer can be a local cache. However, high-load scenarios often require multiple consumers, with each one reading from a single partition. Therefore, this buffer will have to be kept outside the consumer layer, becoming a new layer to be maintained.
What if instead of sorting the messages, we simply group them into different buckets when we produce the message? Messages with higher priority would fall into one bucket while messages with lower priority would fall into another. This eliminates the need to buffer messages for the sake of sorting because now messages are in specific buckets—each one with their own priority. Consumers can simply read from the buckets without worrying about sorting because the priority has been expressed in terms of grouping.
But how would you effectively implement prioritization? Each bucket could have different sizes. A higher-priority bucket could have a size that is bigger than the others and therefore fit more messages. Also, higher-priority buckets could have more consumers reading messages from it than others. So when these two approaches are combined, we can reasonably solve the problem of prioritization by giving priority buckets a higher chance of getting processed first.
Besides using the logic about bucket size and different number of consumers per bucket, another approach could be executing the consumers in an order that gives preference to higher-priority buckets first. With consumers knowing which buckets to work on, the consumers could be executed in an order that would first read from the buckets with higher priority. As these buckets become nearly empty, then the consumers of buckets with less priority would be executed.
Figure 1 gives a summary about what has been discussed so far. There are two buckets: one called Platinum and another called Gold. The Platinum bucket is obviously bigger than Gold and thus can fit more messages. Also, there are four consumers working on the Platinum bucket, whereas there are only two consumers working on the Gold bucket. Conceptually, messages in the Platinum bucket will either be processed first and/or faster than any message ending up in the Gold bucket.
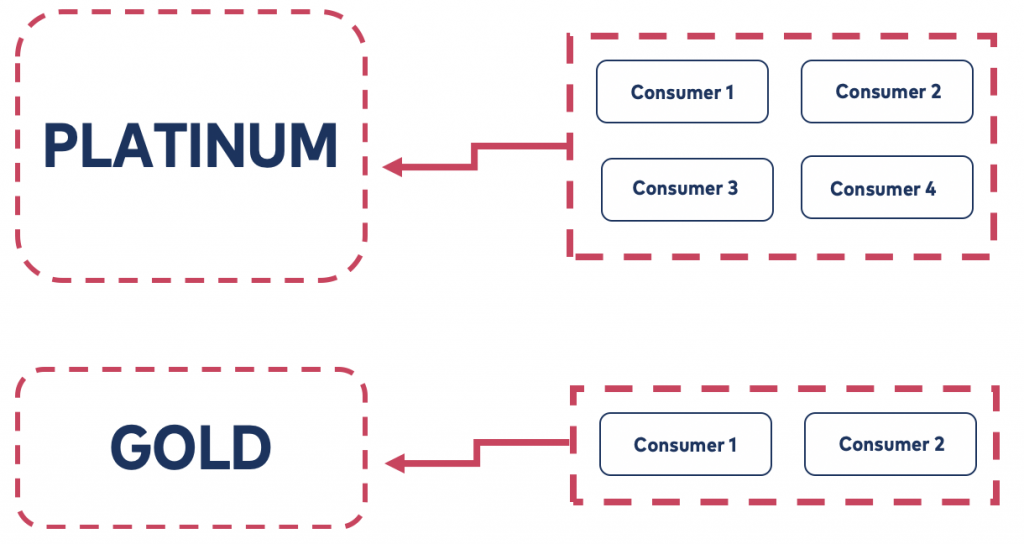 Figure 1. Summary of the message prioritization solution
Figure 1. Summary of the message prioritization solution
In order to make this happen, three questions need to be addressed:
- How to come up with the concept of a bucket?
- How will each message end up in the right bucket?
- How will each consumer process the right bucket?
Ideally, the broker should take care of this, but as we discussed above this runs contrary to the design principles and architectural contracts around which Kafka is built. This therefore leaves us with the logical conclusion that if something must be changed, it has to happen on both the producer and consumer sides.
On the producer, there has to be a process that inspects each message. Based on information stored in the message, it decides which bucket to use. For the consumer, there has to be a process that during bootstrap inspects a configuration that dictates which bucket to use. Based on this information, the consumer only polls messages from the appropriate bucket, though each consumer has to be aware of the rebalancing process because if triggered, the partitions might be reassigned.
Implementing the bucket priority pattern
How do you introduce these processes in the producer and the consumer without having to write code for it? Thanks to Kafka’s pluggable architecture, there are ways to insert this type of process in a declarative manner.
On the producer side, there are partitioners. This built-in concept used behind the scenes by the Kafka producer to decide which partition to write the message to. Kafka provides a default partitioner and so you may even be unaware that the partitioner can be customised.
On the consumer side, there are assignors. This is another built-in concept used behind the scenes by the Kafka consumer to decide how partitions will be assigned to consumers. Just like what happens with the producer and the default partitioner, Kafka provides a default assignor so again we may be blissfully unaware that it even exists!
Both partitioners and assignors can be changed declaratively, which gives you a chance to introduce the aforementioned process without forcing them to change their main code. This leads us to a final question: How do you come up with the concept of buckets?
Defining Buckets
Buckets can simply be groups of partitions. A bucket can be composed by a certain number of partitions and, depending on this number, will express its size. A bucket can be deemed larger than others because it has more partitions belonging to it. In order for this to work, both the producer and the consumer need to share the same view about how many partitions each bucket will contain. We express this sizing using a common notation.
Expressing in terms of numbers could work. For example, a topic with six partitions could be broken down into four partitions for a bucket with a higher priority and two partitions for a bucket with less priority. But what if someone increases the number of partitions in the topic? This would force us to stop the execution of our producers and consumers, make the change in the configuration, and then re-execute them again.
A better option would be to express the size of each bucket using a percentage. Instead of statically specifying the number of partitions for each bucket, we could say that the bucket with higher priority has 70% of allocation and the bucket with lower priority has 30%. In the previous example of the topic with 6 partitions, initially the bucket with higher priority would have 4 partitions and the bucket with lower priority would have 2 partitions. But if someone increases the number of partitions from 6 to 12, for example, the bucket with higher priority now would have 8 partitions and the bucket with lower priority would have 4 partitions. Figure 2 below shows what this looks like for the producer.
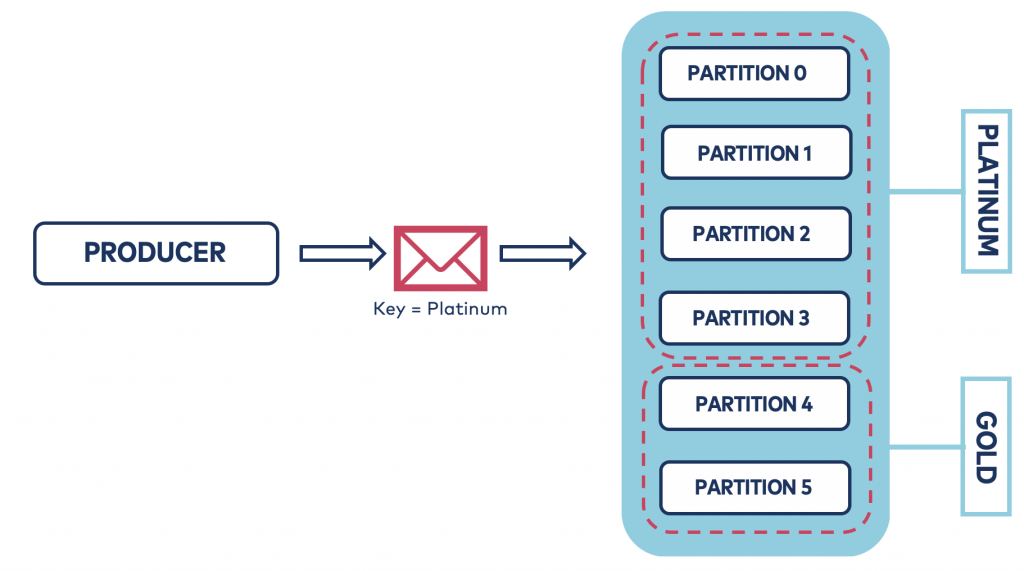 Figure 2. Bucket priority pattern implemented in the producer
Figure 2. Bucket priority pattern implemented in the producer
The partitioner could use the message key to decide which bucket to use. Using keys is preferable because it frees you from having to design your message payload with extra information that has nothing to do with your domain model.
Consumers must be assigned to the partitions belonging to the buckets they want to process. For instance, if there are 4 consumers and all of them want to process messages from a certain bucket, then all partitions from that bucket must be distributed among the consumers no matter what—even in the event of a rebalancing.
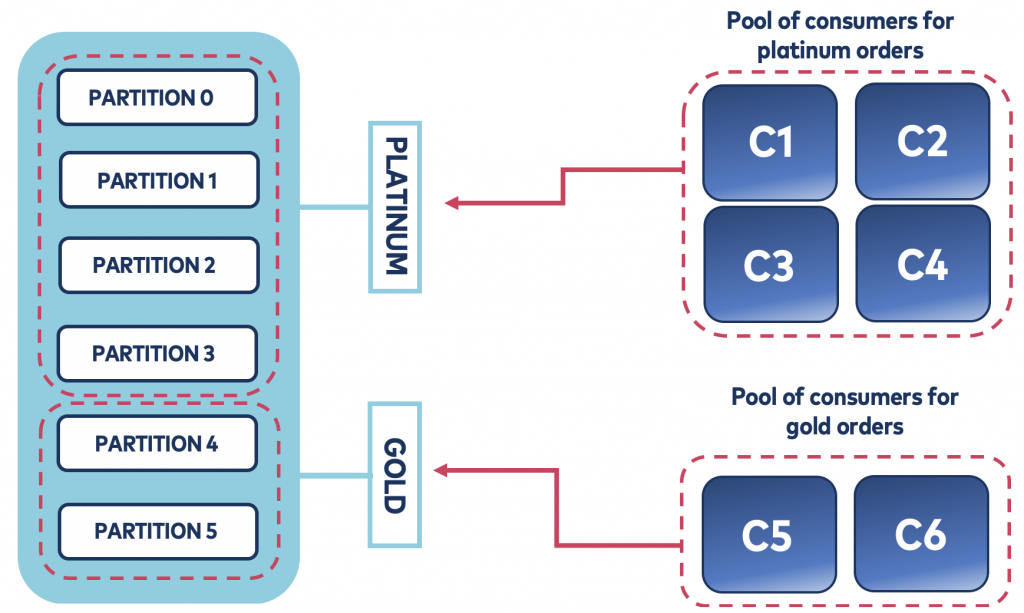 Figure 3. Bucket priority pattern implemented in the consumer
Figure 3. Bucket priority pattern implemented in the consumer
There is no better way to explain how to implement the bucket priority pattern than by using an example. The complete code described here is available on GitHub.
Suppose we want to treat orders with priority. High-priority orders should be processed faster than low-priority ones. In order to achieve this, we need to include the bucket priority pattern implementation as a dependency.
There are a couple options available to bring this dependency into your code. The simplest one is using jitpack.io, which automatically pulls code from GitHub and installs it as a module on to your local Maven repository. Another option is to clone the repo that contains the code and build and install the dependency manually.
<dependency>
<groupId>com.riferrei.kafka.core</groupId>
<artifactId>bucket-priority</artifactId>
<version>${bucket.priority.version}</version>
</dependency>
Once you have the dependency, it is time to modify your producer and consumer applications to use it. Let’s start with the producer. As you may know, in order to instantiate a producer in Kafka, you need to provide a set of configurations as shown below:
KafkaProducer<String, String> producer = new KafkaProducer<>(configs)
Along with the configurations that are mandatory and the ones that you may want to set explicitly, to use the bucket priority pattern, you need to set these ones:
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, BucketPriorityPartitioner.class.getName()); configs.put(BucketPriorityConfig.TOPIC_CONFIG, "orders-per-bucket"); configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold"); configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%"); producer = new KafkaProducer<>(configs);
The first property changes the partitioner to the bucket priority pattern, which is the partitioner that does the magic. The second property specifies that the topic orders-per-bucket is the one that should have buckets. This is necessary because in Kafka, topics are specified in the message and not in the producer. Thus, a producer can send messages to different topics. The third property defines the buckets.
There are no limits about how many buckets you can have—you just need to separate them by a comma. Finally, the fourth property defines the allocation for each bucket in terms of percentage. Each allocation is associated with the buckets defined in the third property given the order that they are specified—so the Platinum has 70% of allocation and the bucket Gold has 30%.
For this example, let’s say that the topic orders-per-bucket has 6 partitions. In this case, the bucket Platinum will have 4 partitions and the bucket Gold will have 2. To verify, implement the following code on your producer:
for (;;) {
int value = counter.incrementAndGet();
final String recordKey = "Platinum-" + value;
ProducerRecord<String, String> record =
new ProducerRecord<>("orders-per-bucket", recordKey, "Value");
producer.send(record, (metadata, exception) -> {
System.out.println(String.format(
"Key '%s' was sent to partition %d",
recordKey, metadata.partition()));
});
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
}
}
If you execute this code, you will see that all records sent will be distributed among the partitions 0, 1, 2, and 3, because they belong to the bucket Platinum. This will happen because all messages are being generated using a key that contains the desired bucket name. Changing the key value to add the string Gold will instruct the partitioner to use only the partitions 4 and 5.
The consumer has to use a similar strategy, though the configuration options are slightly different. Here are the properties that need to be set:
configs.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, BucketPriorityAssignor.class.getName()); configs.put(BucketPriorityConfig.TOPIC_CONFIG, "orders-per-bucket"); configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold"); configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%"); configs.put(BucketPriorityConfig.BUCKET_CONFIG, "Platinum"); consumer = new KafkaConsumer<>(configs);
Unlike the producer that had to change the partitioner, the consumer needs to change the assignor, and this is accomplished by specifying the property partition.assignment.strategy. All the other options are the same regarding the topic, the bucket definition, and the bucket allocation. But consumers also need to specify which bucket they intend to use to process messages. Hence, this is why there is a fifth property in the list.
In order to verify if the consumer processes, only messages from the bucket Platinum implement the following code:
consumer.subscribe(Arrays.asList("orders-per-bucket"));
for (;;) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("[%s] Key = %s, Partition = %d",
threadName, record.key(), record.partition()));
}
}
You will notice that the consumer only processes messages belonging to the Platinum bucket. This is true even if you execute multiple instances of the consumer. The code was written to support executing multiple consumers, each one on its own thread, so you can play around with this to check how the bucket priority pattern will behave. In the example above, we have a topic called orders-per-bucket where the first 4 partitions have been assigned to the Platinum bucket as its allocation was set to 70%. This means that if you execute 4 consumers targeting that bucket, then each one of these consumers will read from each partition.
What if one of the consumers dies and triggers a rebalancing? If this happens, then the bucket priority pattern will assign the partitions to the remaining consumers using the same logic, which is to assign only the partitions allocated to the bucket that the consumers are interested in. Note, however, that the bucket priority pattern doesn’t ensure stickiness, because its goal is to ensure that buckets are assigned to their right consumers.
It would make no sense, for instance, to assign a partition that belongs to the bucket Platinum to a consumer that dictated in the configuration that it is interested in the bucket Gold only because that partition had been assigned to that particular consumer.
Another interesting characteristic of the bucket priority pattern is that regardless of which bucket the consumers are interested in, they can all belong to the same consumer group. This ensures that from Kafka’s standpoint, your consumers will cohesively represent the same application, though they can now have the freedom to process only the portions of the topic that represent the group of data that matters the most.
Conclusion
Message prioritization is one of the most popular topics discussed in social forums and in the Confluent community. However, due to Kafka’s architecture and design principles there is no out-of-the-box feature to support it. This post explained why Kafka doesn’t support message prioritization and also presented an alternative for this in a form of a pattern that uses the concept of custom partitioning and assignors provided by Kafka.
Start building with Apache Kafka
If you want more on Kafka and event streaming, you check out Confluent Developer to find the largest collection of resources for getting started, including end-to-end Kafka tutorials, videos, demos, meetups, podcasts, and more.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


