Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Kafka Connect Deep Dive – JDBC Source Connector
One of the most common integrations that people want to do with Apache Kafka® is getting data in from a database. That is because relational databases are a rich source of events. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. From there these events can be used to drive applications, be streamed to other data stores such as search replicas or caches and streamed to storage for analytics.
I’ve written previously about the options available for doing this and different types of change data capture (CDC). Here, I’m going to dig into one of the options available—the JDBC connector for Kafka Connect. In this self-managed scenario, I’ll show how to set it up, as well as provide some troubleshooting tips along the way. For full details, make sure to check out the documentation.
What we’ll cover
- JDBC drivers
- Specifying which tables to ingest
- Incremental ingest
- Query-based ingest
- One connector or many?
- Why is there no data?
- Resetting the point from which JDBC source connector reads data
- Setting the Kafka message key
- Changing the topic name
- Bytes, Decimals, Numerics and oh my
- Working with multiple tables
Introduction
The JDBC connector for Kafka Connect is included with Confluent Platform and can also be installed separately from Confluent Hub. It enables you to pull data (source) from a database into Kafka, and to push data (sink) from a Kafka topic to a database. Almost all relational databases provide a JDBC driver, including Oracle, Microsoft SQL Server, DB2, MySQL and Postgres.
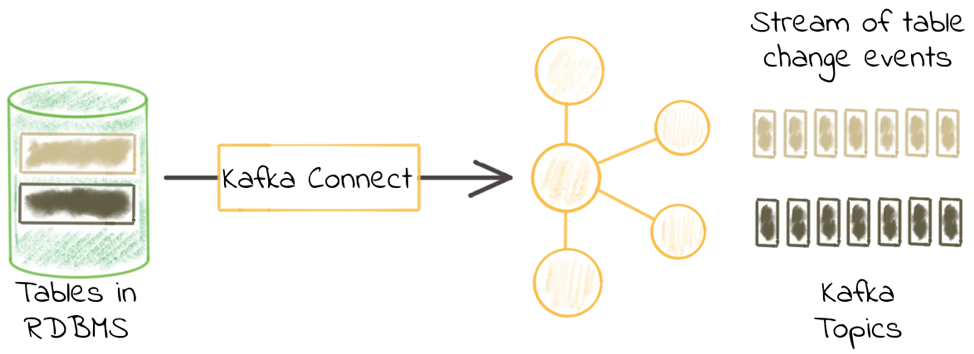
We’ll start off with the simplest Kafka Connect configuration, and then build on it as we go through. The example that I’ll work through here is pulling in data from a MySQL database. The database has two schemas, each with several tables:
mysql> SELECT table_schema, table_name FROM INFORMATION_SCHEMA.tables WHERE TABLE_SCHEMA != 'information_schema'; +--------------+--------------+ | TABLE_SCHEMA | TABLE_NAME | +--------------+--------------+ | demo | accounts | | demo | customers | | demo | transactions | | security | firewall | | security | log_events | +--------------+--------------+
Try it at home!
You can find the Docker Compose configuration and associated files for you to try this out yourself, with Postgres, MySQL, Oracle and MS SQL Server on GitHub.
JDBC drivers
Before we get to the configuration, we need to make sure that Kafka Connect can actually connect to the database—and we do this by ensuring that the JDBC driver is available to it. This video explains how. If you’re using SQLite or Postgres then the driver is already included and you get to skip this step. For all other databases, you need to put the relevant JDBC driver JAR in the same folder as the kafka-connect-jdbc JAR itself. Standard locations for this folder are:
- Confluent CLI: share/java/kafka-connect-jdbc/ relative to the folder where you downloaded Confluent Platform
- Docker, DEB/RPM installs: /usr/share/java/kafka-connect-jdbc/
- For tips on how to add a JDBC driver to the Kafka Connect Docker container, see here
- If the kafka-connect-jdbc JAR is located elsewhere, then use plugin.path to point to the folder containing it and make sure that the JDBC driver is in the same folder
You can also launch Kafka Connect with CLASSPATH set to the location in which the JDBC driver can be found. Make sure that it is set to the JAR itself, not just the containing folder. For example:
CLASSPATH=/u01/jdbc-drivers/mysql-connector-java-8.0.13.jar ./bin/connect-distributed ./etc/kafka/connect-distributed.properties
Two important things to remember:
- The plugin.path configuration option for Kafka Connect cannot be used to point to JDBC driver JARs directly if the kafka-connect-jdbc JAR resides elsewhere. Per the documentation, the JDBC driver JAR must be in the same location as the kafka-connect-jdbc JAR.
- If you are running a multi-node Kafka Connect cluster, then remember that the JDBC driver JAR needs to be correctly installed on every Connect worker in the cluster.
No suitable driver found
A common error that people have with the JDBC connector is the dreaded error No suitable driver found, such as here:
{"error_code":400,"message":"Connector configuration is invalid and contains the following 2 error(s):\nInvalid value java.sql.SQLException: No suitable driver found for jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd for configuration Couldn't open connection to jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd\nInvalid value java.sql.SQLException: No suitable driver found for jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=admin for configuration Couldn't open connection to jdbc:mysql://X.X.X.X:3306/test_db?user=root&password=pwd\nYou can also find the above list of errors at the endpoint `/{connectorType}/config/validate`"}
There are two possible causes for this:
- The correct JDBC driver has not been loaded
- The JDBC URL is incorrectly specified
Checking that the JDBC driver has been loaded
Kafka Connect will load any JDBC driver that is present in the same folder as the kafka-connect-jdbc JAR file, as well as any it finds on the CLASSPATH. To troubleshoot this, increase the log level of your Connect worker to DEBUG, then look for the following:
- DEBUG Loading plugin urls: with an array of JARs including kafka-connect-jdbc-5.1.0.jar (or whichever version of the Confluent Platform you are running)
DEBUG Loading plugin urls: [file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/audience-annotations-0.5.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/common-utils-5.1.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/jline-0.9.94.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/jtds-1.3.1.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/kafka-connect-jdbc-5.1.0.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/mysql-connector-java-8.0.13.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/netty-3.10.6.Final.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/postgresql-9.4-1206-jdbc41.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/slf4j-api-1.7.25.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/sqlite-jdbc-3.25.2.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/zkclient-0.10.jar, file:/Users/Robin/cp/confluent-5.1.0/share/java/kafka-connect-jdbc/zookeeper-3.4.13.jar] (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
In this list of JARs, the JDBC driver JAR should be present. In the above output you can see the MySQL, Postgres and SQLite JARs. If your JDBC driver JAR is not there, then use the path provided of the kafka-connect-jdbc JAR and place it into the same folder.
- INFO Added plugin 'io.confluent.connect.jdbc.JdbcSourceConnector'—immediately after this, and before any other plugins being logged, you should see your JDBC driver being registered:
INFO Added plugin 'io.confluent.connect.jdbc.JdbcSourceConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: jTDS 1.3.1 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: com.mysql.cj.jdbc.Driver@7bbbb6a8 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: org.postgresql.Driver@ea9e141 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader) DEBUG Registered java.sql.Driver: org.sqlite.JDBC@236134a1 to java.sql.DriverManager (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader)
Ensure that your JDBC driver is included in the list of those registered. If it’s not, then you’ve not installed it correctly.
Note that you might see Registered java.sql.Driver for your driver elsewhere in the log, but for validation that it will be available to the JDBC connector, it must appear directly after the INFO Added plugin 'io.confluent.connect.jdbc message.
JDBC URL
The JDBC URL must be correct for your source database. If you get this wrong then Kafka Connect may have the right driver but won’t be using it if the JDBC URL is incorrectly specified. Below are some of the common JDBC URL formats:
| IBM DB2 | driver | jdbc:db2://<host>:<port50000>/<database> |
| IBM Informix | jdbc:informix-sqli://:/:informixserver=<debservername> | |
| MS SQL | driver | jdbc:sqlserver://<host>[:<port1433>];databaseName=<database> |
| MySQL | driver | jdbc:mysql://<host>:<port3306>/<database> |
| Oracle | driver | jdbc:oracle:thin://<host>:<port>/<service> or jdbc:oracle:thin:<host>:<port>:<SID> |
| Postgres | included with Kafka Connect | jdbc:postgresql://<host>:<port5432>/<database> |
| Amazon Redshift | driver | jdbc:redshift://<server>:<port5439>/<database> |
| Snowflake | driver | jdbc:snowflake://<account_name>.snowflakecomputing.com/?<connection_params> |
Note that whilst the JDBC URL will often permit you to embed authentication details, these are logged in clear text in the Kafka Connect log. For that reason, you should use the separate connection.user and connection.password configuration options, which are correctly sanitized when logged.
Specifying which tables to ingest
So now that we have the JDBC driver installed correctly, we can configure Kafka Connect to ingest data from a database. Here’s the most minimal of configs. Note that whilst it’s minimal, it’s not necessarily the most useful since it’s doing bulk import of data—we discuss how to do incremental loads later on in this post.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}'
With this config, every table (to which the user has access) will be copied into Kafka, in full. We can see that easily by listing the topics on the Kafka cluster with ksqlDB:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
mysql-01-accounts | false | 1 | 1 | 0 | 0
mysql-01-customers | false | 1 | 1 | 0 | 0
mysql-01-firewall | false | 1 | 1 | 0 | 0
mysql-01-log_events | false | 1 | 1 | 0 | 0
mysql-01-transactions | false | 1 | 1 | 0 | 0
Note the mysql-01 prefix. The full copy of the table contents will happen every five seconds, and we can throttle that by setting poll.interval.ms, for example, to once an hour:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_02",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-02-",
"mode":"bulk",
"poll.interval.ms" : 3600000
}
}'
Examining one of these topics shows a full copy of the data, which is what you’d expect:
ksql> PRINT 'mysql-02-accounts' FROM BEGINNING;
Format:AVRO
12/20/18 3:18:44 PM UTC, null, {"id": 1, "first_name": "Hamel", "last_name": "Bly", "username": "Hamel Bly", "company": "Erdman-Halvorson", "created_date": 17759}
12/20/18 3:18:44 PM UTC, null, {"id": 2, "first_name": "Scottie", "last_name": "Geerdts", "username": "Scottie Geerdts", "company": "Mante Group", "created_date": 17692}
12/20/18 3:18:44 PM UTC, null, {"id": 3, "first_name": "Giana", "last_name": "Bryce", "username": "Giana Bryce", "company": "Wiza Inc", "created_date": 17627}
12/20/18 3:18:44 PM UTC, null, {"id": 4, "first_name": "Allen", "last_name": "Rengger", "username": "Allen Rengger", "company": "Terry, Jacobson and Daugherty", "created_date": 17746}
12/20/18 3:18:44 PM UTC, null, {"id": 5, "first_name": "Reagen", "last_name": "Volkes", "username": "Reagen Volkes", "company": "Feeney and Sons", "created_date": 17798}
…
At the moment, we’re getting all of the tables available to the user, which is not what you’d always want. Perhaps we want to only include tables from a particular schema—the catalog.pattern/schema.pattern (which one depends on your RDBMS flavour) configuration controls this:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_03",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-03-",
"mode":"bulk",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo"
}
}'
Now we only get the three tables from the demo schema:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
[…]
mysql-03-accounts | false | 1 | 1 | 0 | 0
mysql-03-customers | false | 1 | 1 | 0 | 0
mysql-03-transactions | false | 1 | 1 | 0 | 0
[…]
It’s possible also to control the tables pulled back by the connector, using the table.whitelist (“only include”) or table.blacklist (“include everything but”) configuration. Here’s an example explicitly listing the one table that we want to ingest into Kafka:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_04",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-04-",
"mode":"bulk",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo",
"table.whitelist" : "accounts"
}
}'
As expected, just the single table is now streamed from the database into Kafka:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
mysql-04-accounts | false | 1 | 1 | 0 | 0
Since it’s just the one table, this configuration:
"catalog.pattern" : "demo", "table.whitelist" : "accounts",
…is the same as this one:
"table.whitelist" : "demo.accounts",
You can specify multiple tables in a single schema like this:
"catalog.pattern" : "demo", "table.whitelist" : "accounts, customers",
…or across multiple schemas:
"table.whitelist" : "demo.accounts, security.firewall",
Other table selection options are available including table.types to select objects other than tables, such as views.
You have to be careful when filtering tables, because if you end up with none matching the pattern (or that the authenticated user connecting to the database is authorized to access), then your connector will fail:
INFO After filtering the tables are: (io.confluent.connect.jdbc.source.TableMonitorThread) … ERROR Failed to reconfigure connector's tasks, retrying after backoff: (org.apache.kafka.connect.runtime.distributed.DistributedHerder) java.lang.IllegalArgumentException: Number of groups must be positive
You can set the log level to DEBUG to view the tables that the user can access before they are filtered by the specified table.whitelist/table.blacklist:
DEBUG Got the following tables: ["demo"."accounts", "demo"."customers"] (io.confluent.connect.jdbc.source.TableMonitorThread)
The connector then filters this list down based on the whitelist/blacklist provided, so make sure that the ones you specify fall within the list of those that the connector shows as available. Don’t forget that the connecting user must be able to access these tables, so check the appropriate GRANT statements on the database side too.
Incremental ingest
So far we’ve just pulled entire tables into Kafka on a scheduled basis. This is useful to get a dump of the data, but very batchy and not always so appropriate for actually integrating source database systems into the streaming world of Kafka.
The JDBC connector gives you the option to stream into Kafka just the rows from a table that have changed in the period since it was last polled. It can do this based either on an incrementing column (e.g., incrementing primary key) and/or a timestamp (e.g., last updated timestamp).
A common practice in schema design is to have one or both of these present. For example, a transaction table such as ORDERS may have:
- ORDER_ID, a unique key (maybe the primary key) that increments for each new order
- UPDATE_TS, a timestamp column that is updated every time the row is updated
To specify which option you want to use, set the <mode option. Let’s switch to timestamp:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_08",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-08-",
"mode":"timestamp",
"table.whitelist" : "demo.accounts",
"timestamp.column.name": "UPDATE_TS",
"validate.non.null": false
}
}'
Now we get the full contents of the tables, plus any updates and inserts made to the source data:
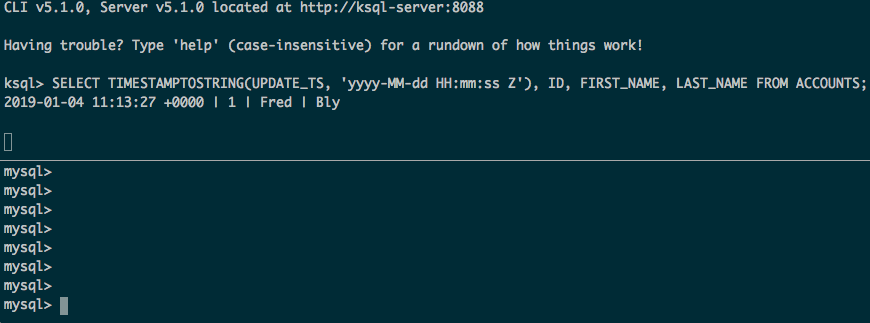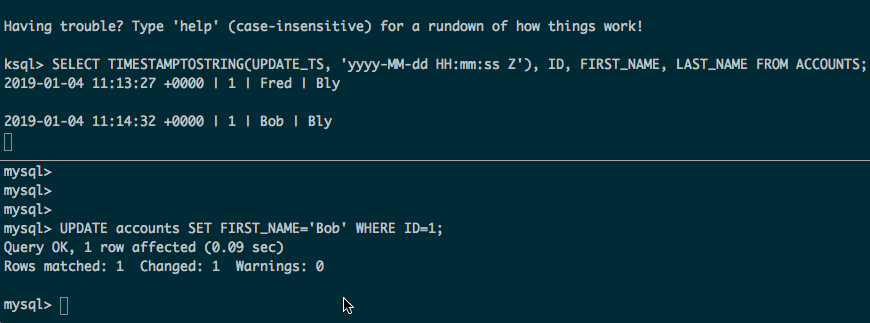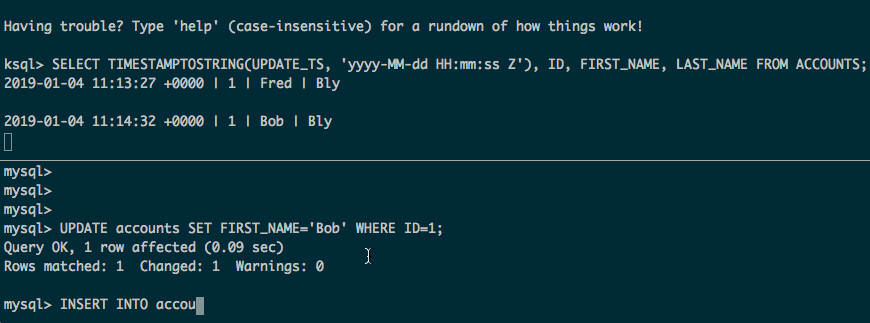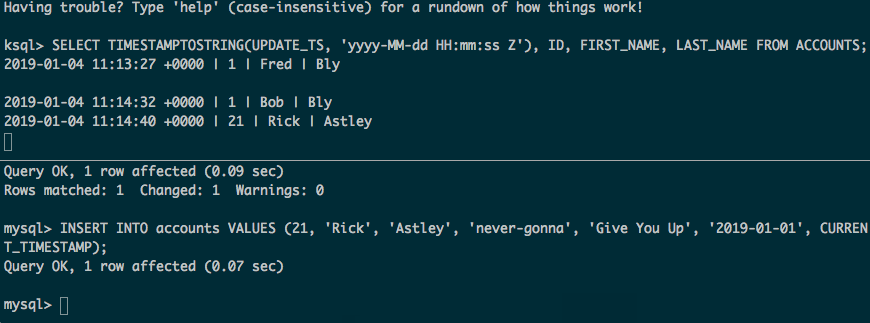
Some considerations:
- You can use either (timestamp/incrementing) or both (timestamp+incrementing) of these methods combined.
- The timestamp and/or ID column that you specify to be used must be present on all of the tables handled by the connector. If different tables have timestamp/ID columns of different names, then create separate connector configurations as required.
- If you only use incrementing IDs, then updates to the data won’t get captured unless the ID also increases on each update (very unlikely in the case of a primary key).
- Some tables may not have unique IDs, and instead have multiple columns which combined represent the unique identifier for a row (a composite key). The JDBC connector requires a single identifier column.
- The timestamp+incrementing option gives you the most coverage in terms of identifying both new and updated rows.
- Many RDBMS support DDL that declare an update timestamp column, which updates automatically. For example:
- MySQL:
CREATE TABLE foo ( … UPDATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ); - Postgres:
CREATE TABLE foo (
…
UPDATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Courtesy of https://techblog.covermymeds.com/databases/on-update-timestamps-mysql-vs-postgres/
CREATE FUNCTION update_updated_at_column() RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
NEW.update_ts = NOW();
RETURN NEW;
END;
$$;
CREATE TRIGGER t1_updated_at_modtime BEFORE UPDATE ON foo FOR EACH ROW EXECUTE PROCEDURE update_updated_at_column(); - Oracle:
- MySQL:
-
-
CREATE TABLE foo (
…
CREATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,
);
CREATE OR REPLACE TRIGGER TRG_foo_UPD
BEFORE INSERT OR UPDATE ON foo
REFERENCING NEW AS NEW_ROW
FOR EACH ROW
BEGIN
SELECT SYSDATE
INTO :NEW_ROW.UPDATE_TS
FROM DUAL;
END;
/
-
Query-based ingest
Sometimes you may want to ingest data from an RDBMS but in a more flexible manner than just the entire table. Reasons for this could include:
- A wide table with many columns, from which you only want a few of them in the Kafka topic
- A table with sensitive information that you do not want to include in the Kafka topic (although this can also be handled at the point of ingest by Kafka Connect, using a Single Message Transform)
- Multiple tables with dependent information that you want to resolve into a single consistent view before streaming to Kafka
This is possible using the query mode of the JDBC connector. Before we see how to do that there are a few points to bear in mind:
- Beware of “premature optimisation” of your pipeline. Just because you don’t need certain columns or rows from a source table, that’s not to say you shouldn’t include them when streaming to Kafka.
- As you’ll see below, the query mode can be less flexible when it comes to incremental ingest, so another approach to simply dropping columns from the source (whether to simply reduce the number, or because of sensitive information) is to use the ReplaceField Single Message Transform in the connector itself.
- As your query becomes more complex (for example, resolving joins), the potential load and impact on the source database increases.
- Joining data at source in the RDBMS is one way to resolve joins. Another is to stream the source tables into individual Kafka topics and then use ksqlDB or Kafka Streams to perform joins as required. The same is true for filtering and masking data—ksqlDB is an excellent way to “post-process” data in Kafka, keeping the pipeline as simple as possible.
Here, we will show how to stream events from the transactions table enriched with data from the customers table:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_09",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-09",
"mode":"bulk",
"query":"SELECT t.txn_id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;",
"poll.interval.ms" : 3600000
}
}'
You might notice that I’ve switched back to bulk mode. You can use one of the incremental options (ID or timestamp), but make sure that you include the appropriate ID/timestamp column (e.g., txn_id) in the select criteria:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_10",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-10",
"mode":"incrementing",
"query":"SELECT txn_id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id",
"incrementing.column.name": "txn_id",
"validate.non.null": false
}
}'
If you don’t include the column—even if it exists in the source table—then your connector will fail with an org.apache.kafka.connect.errors.DataException error (#561) or java.lang.NullPointerException error (#560). This is because the connector needs to have the value in the returned data so that it can store the latest value for the offset accordingly.
If you use the query option, then you cannot specify your own WHERE clause in it unless you use mode: bulk (#566). That is to say, using your own predicates in the query and getting Kafka Connect to an incremental ingest are mutually exclusive.
One connector or many?
If you need different configuration settings, then create a new connector. For example, you may want to differ:
- The name of the columns holding the incrementing ID and/or timestamp
- The frequency with which you poll a table
- The user ID with which you connect to the database
Similarly, if you have the same configuration for all tables, you can use a single connector.
Why is there no data?
Sometimes you might create a connector successfully but not see any data in your target Kafka topic. Let’s walk through the diagnostic steps to take.
- Has the connector been created successfully? Query the /connectors endpoint:
$ curl -s "http://localhost:8083/connectors" ["jdbc_source_mysql_10"]
You should expect to see your connector listed here. If it’s not, you need to create it and pay attention to any errors returned by Kafka Connect at this point.
- Check the status of the connector and its task[s]:
$ curl - s "http://localhost:8083/connectors/jdbc_source_mysql_10/status" | jq '.' { "name": "jdbc_source_mysql_10", "connector": { "state": "RUNNING", "worker_id": "kafka-connect:8083" }, "tasks": [ { "state": "RUNNING", "id": 0, "worker_id": "kafka-connect:8083" } ], "type": "source" }
You should expect to see the state as RUNNING for all the tasks and the connector. However, RUNNING does not always mean “healthy.”
- If the connector or tasks are FAILED—or if they’re RUNNING but not behaving as you’d expect—head over to the Kafka Connect worker output (here are tips on how to find it). This will show if there are any actual problems. Taking the example for the connector shown above, which is status RUNNING, the Connect worker log is actually full of repeating errors:
ERROR Failed to run query for table TimestampIncrementingTableQuerier{table=null, query='SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;', topicPrefix='mysql-10', incrementingColumn='t.id', timestampColumns=[]}: {} (io.confluent.connect.jdbc.source.JdbcSourceTask) java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'WHERE `t.id` > -1 ORDER BY `t.id` ASC' at line 1 at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120) - Here, it’s not entirely obvious what the problem is. Let’s bring up the config for the connector to check that the specified query is correct:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_10/config"|jq '.' { "connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector", "mode": "incrementing", "incrementing.column.name": "t.id", "topic.prefix": "mysql-10", "connection.password": "asgard", "validate.non.null": "false", "connection.user": "connect_user", "query": "SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;", "name": "jdbc_source_mysql_10", "connection.url": "jdbc:mysql://mysql:3306/demo" } - Running this query in MySQL works just fine:
mysql> SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; +------+-------------+--------+----------+----------------------+------------+-----------+----------------------------+--------+------------------------------------------------------+ | id | customer_id | amount | currency | txn_timestamp | first_name | last_name | email | gender | comments | +------+-------------+--------+----------+----------------------+------------+-----------+----------------------------+--------+------------------------------------------------------+ | 1 | 5 | -72.97 | RUB | 2018-12-12T13:58:37Z | Modestia | Coltart | mcoltart4@scribd.com | Female | Reverse-engineered non-volatile success |
- So it must be something that Kafka Connect is doing when it executes it. Since the error message references t.id, which we specify as the incrementing.column.name, maybe it’s got something to do with this. By increasing the logging verbosity of Kafka Connect to DEBUG, it’s possible to see the full SQL statement being run:
DEBUG TimestampIncrementingTableQuerier{table=null, query='SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id;', topicPrefix='mysql-10', incrementingColumn='t.id', timestampColumns=[]} prepared SQL query: SELECT t.id, t.customer_id, t.amount, t.currency, t.txn_timestamp, c.first_name, c.last_name, c.email, c.gender, c.comments FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; WHERE `t.id` > ? ORDER BY `t.id` ASC (io.confluent.connect.jdbc.source.TimestampIncrementingTableQuerier) - Looking at the prepared SQL query part of the line, you might spot this:
[…] FROM demo.transactions t LEFT OUTER JOIN demo.customers c on t.customer_id = c.id; WHERE `t.id` > ? ORDER BY `t.id` ASC
- Note the statement terminator (;) after c.id for the JOIN clause has a WHERE after it. The WHERE is appended by Kafka Connect to implement the requested incrementing mode but creates an invalid SQL statement.
- It’s always worth searching GitHub for issues relating to error that you’re seeing because sometimes it will actually be a known issue, such as this one here, which even after removing the statement terminator ends up being a known bug with the JDBC connector.
- If your connector exists and is RUNNING, and there are no errors in the Kafka Connect worker log, you should also check:
- What is the polling interval for the connector? Perhaps it is working exactly as configured, and it just hasn’t polled for new data since data changed in the source table. To check this, look in the Kafka Connect worker output for JdbcSourceTaskConfig values and the poll.interval.ms value.
- If you’re using incremental ingest, what offset does Kafka Connect have stored? If you delete and recreate a connector with the same name, the offset from the previous instance will be preserved. Consider the scenario in which you create a connector. It successfully ingests all data up to a given ID or timestamp value in the source table, and then you delete and recreate it. The new version of the connector will get the offset from the previous version and thus only ingest newer data than that which was previously processed. You can verify this by looking at the offset.storage.topic and the values stored in it for the table in question.
Resetting the point from which the JDBC source connector reads data
When Kafka Connect runs in distributed mode, it stores information about where it has read up to in the source system (known as the offset) in a Kafka topic (configurable with offset.storage.topic). When a connector task restarts, it can then continue processing from where it got to previously. You can see this in the Connect worker log:
INFO Found offset {{protocol=1, table=demo.accounts}={timestamp_nanos=0, timestamp=1547030056000}, {table=accounts}=null} for partition {protocol=1, table=demo.accounts} (io.confluent.connect.jdbc.source.JdbcSourceTask)
This offset is used each time the connector polls, using prepared statements and values for the ? placeholders that the Kafka Connect task passes:
DEBUG TimestampIncrementingTableQuerier{table="demo"."accounts", query='null', topicPrefix='mysql-08-', incrementingColumn='', timestampColumns=[UPDATE_TS]} prepared SQL query: SELECT * FROM `demo`.`accounts` WHERE `demo`.`accounts`.`UPDATE_TS` > ? AND `demo`.`accounts`.`UPDATE_TS` < ? ORDER BY `demo`.`accounts`.`UPDATE_TS` ASC (io.confluent.connect.jdbc.source.TimestampIncrementingTableQuerier)
DEBUG Executing prepared statement with timestamp value = 2019-01-09 10:34:16.000 end time = 2019-01-09 13:23:40.000 (io.confluent.connect.jdbc.source.TimestampIncrementingCriteria)
Here, the first timestamp value is the stored offset, and the second one is the current timestamp.
Whilst not documented, it is possible to manually change the offset that a connector is using. This works across source connector types; in the context of the JDBC source connector, it means changing the timestamp or ID from which the connector will treat subsequent records as unprocessed.
The first thing to do is make sure that Kafka Connect has flushed the offsets, which happens periodically. You can see when it does this in the worker log:
INFO WorkerSourceTask{id=jdbc_source_mysql_08-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask)
Looking at the Kafka topics, you’ll notice internal ones created by Kafka Connect, of which the offsets topic is one of them. The name can vary:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
docker-connect-configs | false | 1 | 1 | 0 | 0
docker-connect-offsets | false | 1 | 1 | 0 | 0
docker-connect-status | false | 5 | 1 | 0 | 0
ksql> PRINT 'docker-connect-offsets' FROM BEGINNING;
Format:JSON
{"ROWTIME":1547038346644,"ROWKEY":"[\"jdbc_source_mysql_08\",{\"protocol\":\"1\",\"table\":\"demo.customers\"}]","timestamp_nanos":0,"timestamp":1547030057000}
When the Kafka Connect connector task starts, it reads this topic and uses the latest value for the appropriate key. To change the offset, we can simply insert a new value. The easiest way to do this is dump the current topic contents, modify the payload and replay it—for this I would use kafkacat because of the consistency and conciseness of options.
- Dump the current contents:
$ kafkacat -b kafka:29092 -t docker-connect-offsets -C -K# -o-1 % Reached end of topic docker-connect-offsets [0] at offset 0 ["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547030056000} );For multiple connectors, this will be more complicated, but here there is just one so I use the -o-1 flag, which defines the offset to return.
- Modify the offset as required. Here, we’re using mode=timestamp to detect changes in the table. The timestamp is 1547030056000, which, using something like an epoch timestamp conversion tool, can easily be converted and manipulated, to set it an hour earlier (1547026456000), for instance. Next, prepare the new message with this updated timestamp value:
["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547026456000}
- Send the new message to the topic:
echo '["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#{"timestamp_nanos":0,"timestamp":1547026456000}' | \ kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#When doing this process, you must also target the correct partition for the message. See this article for details.
- If you want to restart the connector from the beginning you can send a NULL message value (tombstone):
echo '["jdbc_source_mysql_08",{"protocol":"1","table":"demo.accounts"}]#' | \ kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#
- Restart the connector task:
curl -i -X POST -H "Accept:application/json" \ -H "Content-Type:application/json" http://localhost:8083/connectors/jdbc_source_mysql_08/tasks/0/restart
- You can also just bounce the Kafka Connect worker. Once restarted, all records in the source that are more recent than the newly set offset will be [re-]ingested into the Kafka topic.
There is work underway to make the management of offsets easier—see KIP-199 and KAFKA-4107.
Starting table capture from a specified timestamp or ID
As of Confluent Platform 5.5, when you create a connector using timestamp mode to detect changed rows, you can specify the timestamp to search for changes since. By default (in all versions of the connector), it will poll all data to begin with. If you’d like it to start from the point at which you create the connector, you can specify timestamp.initial=-1. You can also specify an arbitrary epoch timestamp in timestamp.initial to have the connector start polling data from that point.
If you’re on a version earlier than 5.5, or you’re using an incrementing ID column to detect changes, you can still get Kafka Connect to start from a custom point, using the method above. Instead of taking an existing offset message and customizing it, we’ll have to brew our own. The format of the message is going to be specific to the name of the connector and table that you’re using. One option is to create the connector first, determine the format and then delete the connector. Another option is to use an environment with the same source table name and structure except in which there’s no data for the connector to pull. Again, you should end up with the message format required.
Before creating the connector, seed the offsets topic with the appropriate value. Here, we want to capture all rows from the demo.transactions table with an incrementing ID greater than 42:
echo '["jdbc_source_mysql_20",{"protocol":"1","table":"demo.transactions"}]#{"incrementing":42}' | \
kafkacat -b kafka:29092 -t docker-connect-offsets -P -Z -K#
Now create the connector:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_20",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-20-",
"mode":"incrementing",
"table.whitelist" : "demo.transactions",
"incrementing.column.name": "txn_id",
"validate.non.null": false
}
}'
In the resulting Kafka Connect worker log, you’ll see:
INFO Found offset {{protocol=1, table=demo.transactions}={incrementing=42}, {table=transactions}=null} for partition {protocol=1, table=demo.transactions} (io.confluent.connect.jdbc.source.JdbcSourceTask)
…
DEBUG Executing prepared statement with incrementing value = 42 (io.confluent.connect.jdbc.source.TimestampIncrementingCriteria)
The Kafka topic is only populated with rows that have a txn_id greater than 42, just as we wanted:
ksql> PRINT 'mysql-20x-transactions' FROM BEGINNING;
Format:AVRO
1/9/19 1:44:07 PM UTC, null, {"txn_id": 43, "customer_id": 3, "amount": {"bytes": "ús"}, "currency": "CNY", "txn_timestamp": "2018-12-15T08:23:24Z"}
1/9/19 1:44:07 PM UTC, null, {"txn_id": 44, "customer_id": 5, "amount": {"bytes": "\f!"}, "currency": "CZK", "txn_timestamp": "2018-10-04T13:10:17Z"}
1/9/19 1:44:07 PM UTC, null, {"txn_id": 45, "customer_id": 3, "amount": {"bytes": "çò"}, "currency": "USD", "txn_timestamp": "2018-04-03T03:40:49Z"}
…
Setting the Kafka message key
Kafka messages are key/value pairs, in which the value is the “payload.” In the context of the JDBC connector, the value is the contents of the table row being ingested. The key in a Kafka message is important for things like partitioning and processing downstream where any joins are going to be done with the data, such as in ksqlDB.
By default, the JDBC connector does not set the message key. It can easily be done though using Kafka Connect’s Single Message Transform (SMT) feature. Let’s say we want to take the ID column of the accounts table and use that as the message key. Simply add this to the configuration:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_06",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-06-",
"poll.interval.ms" : 3600000,
"table.whitelist" : "demo.accounts",
"mode":"bulk",
"transforms":"createKey,extractInt",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id"
}
}'
Now if you use a tool such as kafka-avro-console-consumer to inspect the data, you’ll see that the key (the leftmost column prior to the JSON payload) matches the id value:
kafka-avro-console-consumer \
--bootstrap-server kafka:29092 \
--property schema.registry.url=http://schema-registry:8081 \
--topic mysql-06-accounts --from-beginning --property print.key=true
1 {"id":{"int":1},"first_name":{"string":"Hamel"},"last_name":{"string":"Bly"},"username":{"string":"Hamel Bly"},"company":{"string":"Erdman-Halvorson"},"created_date":{"int":17759}}
2 {"id":{"int":2},"first_name":{"string":"Scottie"},"last_name":{"string":"Geerdts"},"username":{"string":"Scottie Geerdts"},"company":{"string":"Mante Group"},"created_date":{"int":17692}}
…
If you want to set the key in the data for use with ksqlDB, you’ll need to create it as a string since ksqlDB does not currently support other key types. Include this in the connector configuration:
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
You can then use the data in ksqlDB:
ksql> CREATE STREAM ACCOUNTS WITH (KAFKA_TOPIC='mysql-06X-accounts', VALUE_FORMAT='AVRO'); ksql> SELECT ROWKEY, ID, FIRST_NAME + ' ' + LAST_NAME FROM ACCOUNTS; 1 | 1 | Hamel Bly 2 | 2 | Scottie Geerdts 3 | 3 | Giana Bryce …
Changing the topic name
The JDBC connector mandates that you include topic.prefix—but what if you don’t want that, or you want to change the topic name to some other pattern? SMT can help you out here too!
Let’s say we want to drop the mysql-07- prefix. A little bit of RegEx magic goes a long way:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_07",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-07-",
"poll.interval.ms" : 3600000,
"catalog.pattern" : "demo",
"table.whitelist" : "accounts",
"mode":"bulk",
"transforms":"dropTopicPrefix",
"transforms.dropTopicPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropTopicPrefix.regex":"mysql-07-(.*)",
"transforms.dropTopicPrefix.replacement":"$1"
}
}'
Now the topic comes through as just the table name alone:
ksql> LIST TOPICS;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
----------------------------------------------------------------------------------------------------
accounts | false | 1 | 1 | 0 | 0
Bytes, Decimals, Numerics and oh my
This is quite an in-depth subject, but if you’re here from Google, quite possibly you just want the TL;DR:
- "numeric.mapping": "best_fit" is probably the setting that you want to be using if you have NUMERIC/NUMBER data in your source.
- You can use the query option in the JDBC connector to CAST data types from your source table if required.
- If a field is exposed as the JDBC DECIMAL type, then numeric.mapping will not work.
- MySQL stores all numerics as DECIMAL.
- MS SQL, will store DECIMAL and NUMERIC natively, so you will have to cast DECIMAL fields to NUMERIC.
- In Oracle, make sure that you specify a precision and scale in your NUMBER fields. For example, NUMBER(5,0), not NUMBER.
- NUMERIC and DECIMAL are just treated as NUMBER, as is INT.
Having got that out of the way, here’s an explanation as to what’s going on…
Kafka Connect is a framework that is agnostic to the specific source technology from which it streams data into Kafka. The data that it sends to Kafka is a representation in Avro or JSON format of the data, whether it came from SQL Server, DB2, MQTT, flat file, REST or any of the other dozens of sources supported by Kafka Connect. This is usually a transparent process and “just works.” Where it gets a bit more interesting is with numeric data types such as DECIMALS, NUMBER and so on. Take this MySQL query, for example:
mysql> SELECT * FROM transactions LIMIT 1; +--------+-------------+--------+----------+----------------------+ | txn_id | customer_id | amount | currency | txn_timestamp | +--------+-------------+--------+----------+----------------------+ | 1 | 5 | -72.97 | RUB | 2018-12-12T13:58:37Z | +--------+-------------+--------+----------+----------------------+
Pretty innocuous, right? But behind the scenes, that amount column is a DECIMAL(5,2):
mysql> describe transactions; +---------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+--------------+------+-----+---------+-------+ | txn_id | int(11) | YES | | NULL | | | customer_id | int(11) | YES | | NULL | | | amount | decimal(5,2) | YES | | NULL | | | currency | varchar(50) | YES | | NULL | | | txn_timestamp | varchar(50) | YES | | NULL | | +---------------+--------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)
And when ingested to Kafka using the JDBC connector’s default settings, it ends up like this:
ksql> PRINT 'mysql-02-transactions' FROM BEGINNING;
Format:AVRO
1/4/19 5:38:45 PM UTC, null, {"txn_id": 1, "customer_id": 5, "amount": {"bytes": "ã\u007F"}, "currency": "RUB", "txn_timestamp": "2018-12-12T13:58:37Z"}
So our DECIMAL becomes a seemingly gibberish bytes value. By default, Connect will use its own DECIMAL logical type, which is serialised to bytes in Avro. We can see this by looking at the relevant entry from the Confluent Schema Registry:
$ curl -s "http://localhost:8081/subjects/mysql-02-transactions-value/versions/1"|jq '.schema|fromjson.fields[] | select (.name == "amount")'
{
"name": "amount",
"type": [
"null",
{
"type": "bytes",
"scale": 2,
"precision": 64,
"connect.version": 1,
"connect.parameters": {
"scale": "2"
},
"connect.name": "org.apache.kafka.connect.data.Decimal",
"logicalType": "decimal"
}
],
"default": null
}
When consumed by Connect’s AvroConverter, this will work fine and be preserved as a DECIMAL (and can also be deserialised as a BigDecimal in Java), but for other consumers deserialising the Avro, they just get the bytes. This can also be seen when using JSON with schema enabled, and the amount value is a Base64-encoded bytes string:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "bytes",
"optional": true,
"name": "org.apache.kafka.connect.data.Decimal",
"version": 1,
"parameters": {
"scale": "2"
},
"field": "amount"
},
…
},
"payload": {
"txn_id": 1000,
"customer_id": 5,
"amount": "Cv8=",
…
So whether you’re using JSON or Avro, this is where the numeric.mapping configuration comes in. By default, it is set to none (i.e., use Connect’s DECIMAL type), but what people often want is for Connect to actually cast the type to a more compatible type appropriate to the precision of the number. See the documentation for a full explanation.
This option doesn’t support DECIMAL types currently, so here’s an example of the same principle shown in Postgres with a NUMERIC type:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_postgres_12",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:postgresql://postgres:5432/postgres",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "postgres-12-",
"numeric.mapping": "best_fit",
"table.whitelist" : "demo.transactions",
"mode":"bulk",
"poll.interval.ms" : 3600000
}
}'
The resulting data looks like this:
ksql> PRINT 'postgres-12-transactions' FROM BEGINNING;
Format:AVRO
1/7/19 6:27:16 PM UTC, null, {"txn_id": 1, "customer_id": 5, "amount": -72.97, "currency": "RUB", "txn_timestamp": "2018-12-12T13:58:37Z"}
You can see more details of this, along with examples from Postgres, Oracle and MS SQL Server here.
Working with multiple tables
If there are multiple tables from which to ingest data, the total ingest time can be reduced by carrying out the work concurrently. There are two ways to do this with the Kafka Connect JDBC Connector:
- Define multiple connectors, each ingesting separate tables.
- Define a single connector, but increase the number of tasks that it may spawn. The work for each Kafka Connect connector is carried out by one or more tasks. By default, there is one per connector, meaning that data is ingested from the database by a single process.
The former has a higher management overhead, but does provide the flexibility of custom settings per table. If all the tables can be ingested with the same connector settings, then increasing the number of tasks in a single connector is a good way to do it.
When increasing the concurrency with which data is pulled from the database, always work with your friendly DBA. It may be quicker for you to run a hundred concurrent tasks, but those hundred connections to the database might have a negative impact on the database.
Below are two examples of the same connector. Both are going to pull in all the tables that the user has access to in the database, a total of six. In the first connector, the maximum number of tasks is not specified and so is the default of one. In the second, we specify to run at most three tasks ("tasks.max":3).
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}'
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_11",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/demo",
"connection.user": "connect_user",
"connection.password": "asgard",
"topic.prefix": "mysql-11-",
"mode":"bulk",
"tasks.max":3
}
}'
When you query the Kafka Connect REST API for a connector, you can see how many tasks are running for each connector and the tables that they’ve been assigned. The first connector has a single task responsible for all six tables:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_01/tasks"|jq '.'
[
{
"id": {
"connector": "jdbc_source_mysql_01",
"task": 0
},
"config": {
"tables": "`demo`.`NUM_TEST`,`demo`.`accounts`,`demo`.`customers`,`demo`.`transactions`,`security`.`firewall`,`security`.`log_events`",
…
}
}
]
The second connector has three tasks, to which each has two tables assigned:
$ curl -s "http://localhost:8083/connectors/jdbc_source_mysql_11/tasks"|jq '.'
[
{
"id": {
"connector": "jdbc_source_mysql_11", "task": 0
},
"config": {
"tables": "`demo`.`NUM_TEST`,`demo`.`accounts`",
…
}
},
{
"id": {
"connector": "jdbc_source_mysql_11", "task": 1
},
"config": {
"tables": "`demo`.`customers`,`demo`.`transactions`",
…
}
},
{
"id": {
"connector": "jdbc_source_mysql_11", "task": 2
},
"config": {
"tables": "`security`.`firewall`,`security`.`log_events`",
…
}
}
]
Where to go from here
If you want to get started with Kafka connectors quickly so you can set your existing data in motion, check out Confluent Cloud today and the many fully managed connectors that we support. You can also use the promo code 60DEVADV to get $60 of additional free usage.* With a scales-to-zero, low-cost, only-pay-for-what-you-stream pricing model, Confluent Cloud is perfect for getting started with Kafka right through to running your largest deployments.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents With Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


