[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Building a Machine Learning Logging Pipeline with Kafka Streams at Twitter
Twitter, one of the most popular social media platforms today, is well known for its ever-changing environment—user behaviors evolve quickly; trends are dynamic and versatile; and special and emergent events occur unexpectedly at any time. To keep pace, Twitter heavily invests in recommendation systems to power its products, including its home timeline ranking and ad prediction systems, just to name a few. Unfortunately, a stale model that is trained from old data can quickly become irrelevant. An up-to-date model is vital to a responsive, adaptive, and successful prediction system that leads to user satisfaction.
Twitter recently built a streaming data logging pipeline for its home timeline prediction system using Apache Kafka® and Kafka Streams to replace the existing offline batch pipeline at a massive scale—that’s billions of Tweets on a daily basis with thousands of features per Tweet. The new streaming pipeline significantly reduces the entire pipeline latency from seven days to about one day, improves the model quality, and saves engineering time. For an overview of the pipeline, please refer to the Streaming logging pipeline of home timeline prediction system blog post. The remainder of this blog post details the customized Kafka Streams join functionality that was custom-built to support the pipeline.
Machine learning logging pipeline
A machine learning (ML) logging pipeline is just one type of data pipeline that continually generates and prepares data for model training. In a nutshell, an ML logging pipeline mainly does one thing: Join. Feature-label joins are the most prevalent type and are typically left joins because real-world ML systems recommend many more items than those actually engaged by users.
There are other types of joins too. For example, features could be generated from different components or systems that need to be joined together to become the final feature set—such joins are typically inner joins. In a machine learning logging pipeline, you need roughly the same amount of “negative” training examples, which can’t be obtained by inner joins. This blog post focuses on the customized left join DSL that was built as an alternative to the Kafka Streams native join DSL.
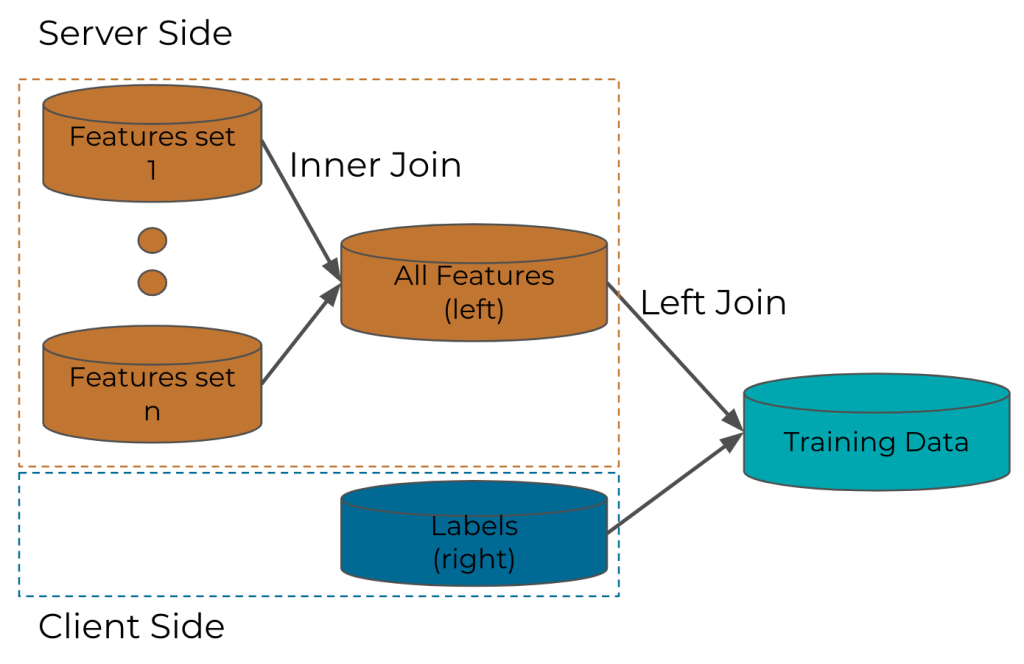 Figure 1. ML logging pipeline
Figure 1. ML logging pipeline
A Kafka Streams join DSL variant for the ML logging pipeline
Kafka and its ecosystem are not new to Twitter—this blog post discusses the move toward Apache Kafka from its in-house EventBus (which builds on top of Apache DistributedLog). Twitter also integrates Kafka Streams into Finatra—its core web server stack. Thus, it is very convenient for Twitter to build a ML logging pipeline using Kafka Streams as all the infrastructure provided by Finatra are immediately available. Moreover, Kafka’s excellent documentation and well-organized code make it fairly easy to be customized.
The Kafka Streams library comes with a default join functionality that has the following attributes:
- It uses RocksDB as the local persistent storage to back up the states.
- It is fault tolerant by default, which is supported by the broker-side changelog topics that will fully restore the local state if the stores are wiped out.
- It has two flavors: LeftJoin and InnerJoin. The LeftJoin checks the right-side store, and if there are no matching records, it immediately emits the left-side record.
ML use cases, however, may have some special requirements:
- An ML logging pipeline may not require strict fault tolerance: Huge historical data restoration makes restarts bumpy and difficult to manage. (When we built the join library at Twitter, the Kafka Streams client we used was an older version: Kafka 2.2. Kafka 2.5 introduces cooperative rebalancing, which should mitigate the “stop the world” rebalancing problem, but we haven’t had a chance to try it out yet.) Although restoration is typically desired, this may not be the case for training examples—most models assume independent and identical distribution (i.i.d) of the examples, and moderating loss of the data is often tolerable.
- A customized behavior of the LeftJoin is required: In this case, the left side is served features while the right side is provided engagement labels. Labels usually arrive later than the features, and you need to wait before you emit the unmatched left-side records. It is also recommended that you keep the serving order for the records—an immediate delivery of the matched records. A delayed release of unmatched records may significantly distort the feature distributions if no shuffling is involved (which is likely the case for online training).
| Timestamps | Left | Right | InnerJoin | LeftJoin |
| 1 | null | |||
| 2 | null | |||
| 3 | A | |||
| 4 | a | (A,a) | ||
| 5 | B | (B,a) | ||
| 6 | b | [(A, b), (B, b)] | ||
| 7 | A | [(A, a), (A, b)] | ||
| Window Expire | [(A, [a, b]), (B, [a, b]), (A, [a, b])] |
Although Kafka Streams’ native join DSL doesn’t provide everything that is needed, thankfully it exposes the Processor API, which allows developers to build tailored stream processing components. Having a non-fault-tolerant state store can be achieved by defining a customized state store with the changelog topic backup disabled (please note this is not advised for an ML logging pipeline).
Having a customized LeftJoin requires building a key-value store to temporarily keep both joined and unjoined records sorted by the served order. To achieve this goal, two new state stores were introduced to the LeftJoin, in addition to two WindowStores on each side: a KeyValue state store (kvStore) on the left side and a JoinedIndicatorStore that is shared by both sides. The following describes the data models of the state stores:
- WindowStore (aka KeySortedStore):
- Underlying store type: WindowStore
- Key: The key of the WindowStore (both sides) consists of three parts. The WindowStore has the payload key of the record at the leading part of the composite key, followed by the timestamp of the record, which is in turn followed by a sequence number that mainly supports duplicated records. The payload key is used to match the records—two records with the same payload key become a matching pair; the timestamp determines whether the two records are in the same joining window. If two records have the same key and are within the same joining window, then they are matched and thus joined. Since the keys of RocksDB are sorted, the keys of the WindowStore are payload keys sorted and dubbed KeySortedStore. Also, the same payload keys with different timestamps and sequence numbers are stored adjacently on the physical drive. As a result, the WindowStore is very efficient for payload key matching. But the WindowStore also rearranges the original records with their timestamps.
- Value: The value of the WindowStore is the offset of the payload. This offset corresponds to the offset of the kvStore, see details below.
- kvStore (aka TimeSortedStore):
- Underlying store type: KeyValueStore
- Key: The kvStore has the timestamp at the leading part of the composite key, followed by the offset of the record, which is in turn followed by the payload key. With the timestamp as the leading part, all records in the kvStore are of timely order (because all keys are sorted in RocksDB). The kvStore is also referred to as the TimeSortedStore. The offset part is mainly used for storing duplicated records.
- leftjoinValue: The value of the kvStore is the payload value.
- JoinedIndicatorStore (shared by both sides):
- Underlying store type: WindowStore
- Key: The composite key is JoinedKey, left-side Event Timestamp, and SequenceNumber
- Value: The value of the JoinedIndicatorStore is the joined right-side event
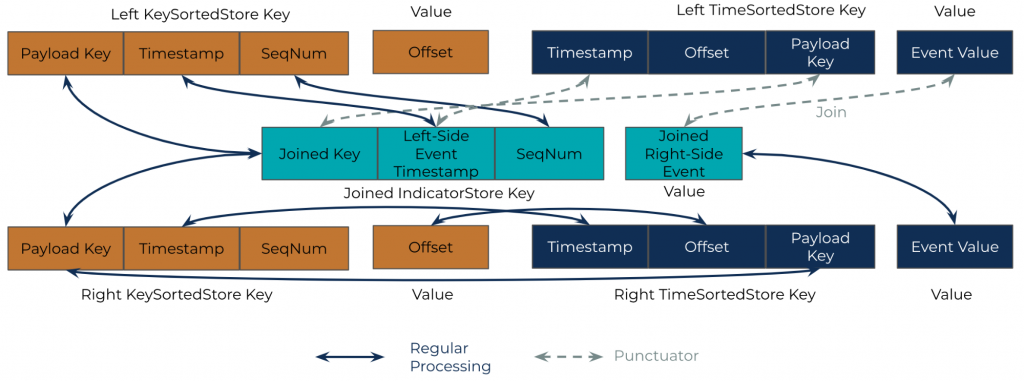 Figure 2. Data model of state stores for LeftJoin
Figure 2. Data model of state stores for LeftJoin
The following details the procedures of the left join:
The normal processor. When a left or right record comes in, it is always put into both the KeySortedStore and TimeSortedStore. The relationship of the fields can be seen from the right-side stores in Figure 2. Specifically, the payload key of the KeySortedStore corresponds to the payload key of the TimeSortedStore; the timestamp field of the KeySortedStore corresponds to the payload key of the TimeSortedStore; and the offset, which is the value of the KeySortedStore, corresponds to the offset of the TimeSortedStore as part of the key.
At the same time, the procedure looks up the other side of the KeySortedStore to find whether there is a match. If there is a match, then put the payload key, left-side timestamp, and right-side payload value into the JoinedIndicatorStore. The following describes how the fields mapping between KeySortedStore and TimeSortedStore helps: If the join occurs on the right side, then you have the payload value already and can directly insert it to the JoinedIndicatorStore. But if the join occurs on the left side, then you need to first fetch the fields from the right-side KeySortedStore as that’s how records are matched. Then, fetch the corresponding payload value from the TimeSortedStore by the fields in the KeySortedStore and finally insert the payload value to the JoinedIndicatorStore.
The records in the JoinedIndicatorStore won’t be emitted immediately—instead, they will be checked and potentially emitted in the left-side punctuator (see details below). The timestamp of the JoinedIndicatorStore is always the left-side timestamp—this is because you will need to use the left-side record’s timestamp to fetch the JoinedIndicatorStore in the punctuator (details below). Also, the value of the JoinedIndicatorStore is always the right-side payload value. Again, this is because there will be a punctuator that periodically runs on the left side. There, you can fetch the left-side payload value by querying the left-side kvStore.
The punctuator. There is a periodic procedure called the punctuator that runs in the left-side procedure. The left-side punctuator basically waits until the window closes for a left-side record and emits the corresponding matched records in the JoinedIndicatorStore. The above process is fulfilled by range-scanning the left-side TimeSortedStore and then point querying the JoinedIndicatorStore. Field mapping helps here: The payload key of TimeSortedStore corresponds to the joined key in the JoinedIndicatorStore while the timestamp corresponds to the timestamp. Thus, you can efficiently fetch records from both stores. Finally, in the punctuator, you can also clean up the expired records in the left-side TimeSortedStore. Cleanup of the KeySortedStore and JoinedIndicatorStore is taken care of by Kafka Streams’ WindowStore.
Performance-wise, since the WindowStore contains only minimal data, the point matching query is super fast. Because the timestamp in the kvStore is sorted, the range scan in the periodic procedure is also efficient. An efficient implementation is critical since the join library needs to handle up to millions of events per second for Twitter’s traffic level.
A study of the impact of consumer lag
This section discusses how consumer lag and potentially the loss of data could impact the data quality of the logged data, which could in turn impact the success of the business. For example, Twitter has more than sufficient events and because the ML training data is i.i.d., a tiny portion of data loss is tolerable. However, this may not be true for other use cases or other organizations that have a different requirement.
The focus of this discussion is on the customized left join as it has more implications than the inner join. The discussion is split into two possible scenarios:
-
- Left-side consumer lag: See the diagram below.
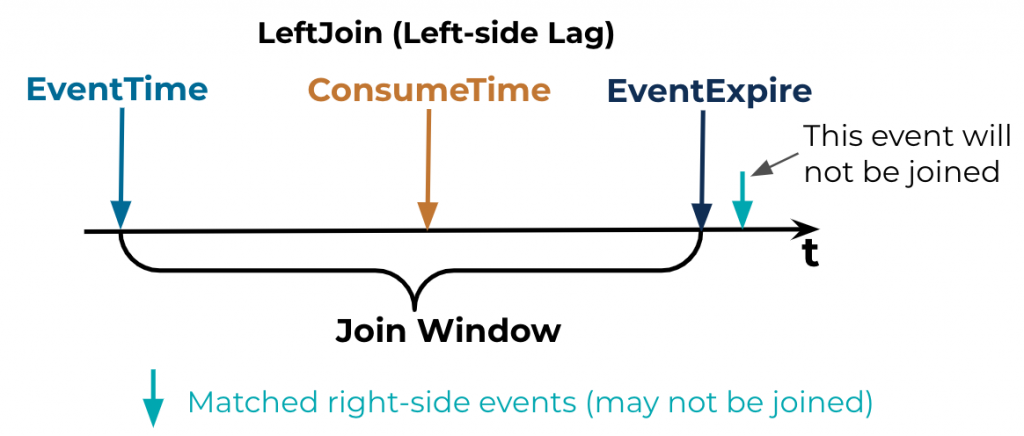
Here, the left join uses the event timestamp, not the consumption timestamp, for matching. That means, as long as the left-side event is consumed within its joining window, it will be joined with all right-side matching events. Also, matching right-side events that arrive later than the consumption timestamp will also be joined (this is the normal case). The diagrams below illustrate the process. The conclusion: Left-side consumer lag during service runtime is okay as long as the event is consumed within its join window, which can almost be guaranteed.
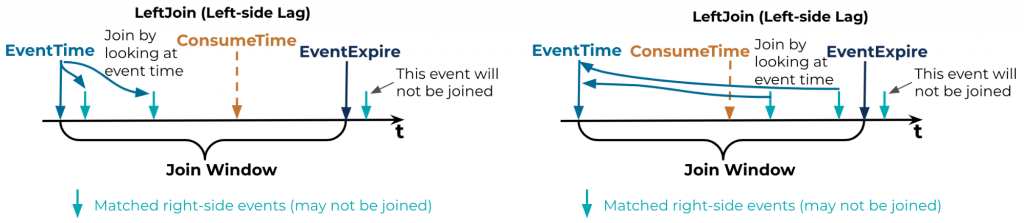
- Left-side consumer lag: See the diagram below.
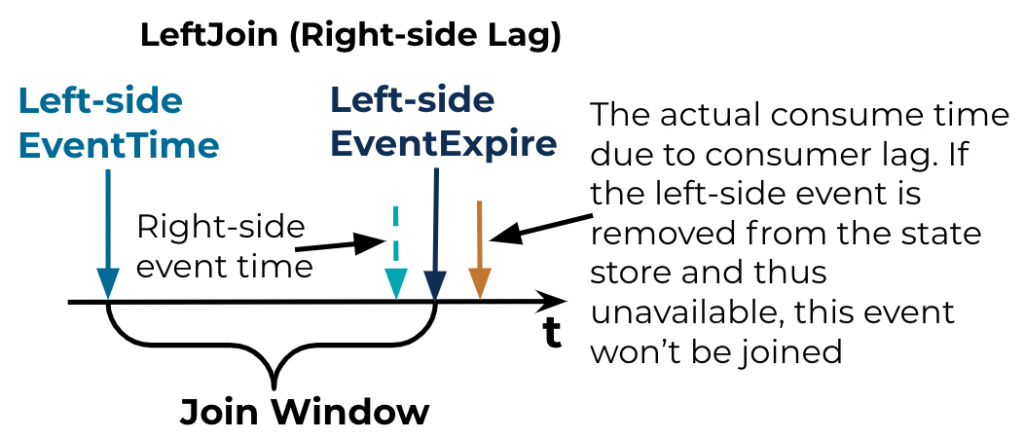
- Right-side consumer lag: This case is different and tricky. For each left-side event, there could be none, one, or many right-side events that match; therefore, there might be none, one, or many joined events being emitted after the left-side event’s join window expires. If a right-side event is supposed to be consumed before the left-side event’s join window expires in order to be joined (green-dashed arrow in the diagram), but is actually consumed after the join window expires due to the consumer lag, then that event may not be joined. This is mainly a result of when the sweeper of the WindowStore (which is controlled by Kafka Streams, not the customized join, and which cannot be controlled by the library) does its work when the punctuator removes the left-side event from the kvStore.
-
- If, and only if, the left-side event is not removed from the WindowStore and the event is not removed from the kvStore, plus the event is consumed and put into both state stores, then the two events will be joined and emitted.
- Otherwise, the events will not be joined.
Conclusion
This blog post discussed the customized Kafka Streams join DSL that supports the ML-specific logging pipeline at Twitter. The details of the join DSL are presented and the impact of consumer lag is also examined. Overall, the customized join DSL is a major win to Twitter’s ML logging pipeline:
- It reduces the entire pipeline’s latency from seven days to one day
- It performs better with up-to-date data
- Tons of engineering time is saved.
In the future, Twitter would like to try the cooperative rebalancing that was introduced in Apache Kafka 2.5, hoping to reinforce the entire pipeline even more.
Say Hello World to event streaming
Learn how to use Apache Kafka the way you want: by writing code. Apply functions to data, aggregate messages, and join streams and tables with Kafka Tutorials, where you’ll find tested, executable examples of practical operations using Kafka, Kafka Streams, and ksqlDB.
Twitter’s home timeline streaming logging pipeline was developed by Peilin Yang, Ikuhiro Ihara, Prasang Upadhyaya, Yan Xia, and Siyang Dai. We would like to thank Arvind Thiagarajan, Xiao-Hu Yan, Wenzhe Shi, and the rest of Timelines Quality team for their contributions to the project and this blog post. We would also like to give a special shoutout to leadership for supporting this project: Xun Tang, Shuang Song, Xiaobing Xue, and Sandeep Pandey. During development, Twitter’s Messaging team has provided tremendous help with Kafka, and we would like to thank Ming Liu, Yiming Zang, Jordan Bull, Kai Huang, and Julio Ng for their dedicated support.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.