Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Preparing Your Clients and Tools for KIP-500: ZooKeeper Removal from Apache Kafka
As described in the blog post Apache Kafka® Needs No Keeper: Removing the Apache ZooKeeper Dependency, when KIP-500 lands next year, Apache Kafka will replace its usage of Apache ZooKeeper with its own built-in consensus layer. This means that you’ll be able to remove ZooKeeper from your Apache Kafka deployments so that the only thing you need to run Kafka is…Kafka itself. Kafka’s new architecture provides three distinct benefits. First, it simplifies the architecture by consolidating metadata in Kafka itself, rather than splitting it between Kafka and ZooKeeper. This improves stability, simplifies the software, and makes it easier to monitor, administer, and support Kafka. Second, it improves control plane performance, enabling clusters to scale to millions of partitions. Finally, it allows Kafka to have a single security model for the whole system, rather than having one for Kafka and one for Zookeeper. Together, these three benefits greatly simplify overall infrastructure design and operational workflows.
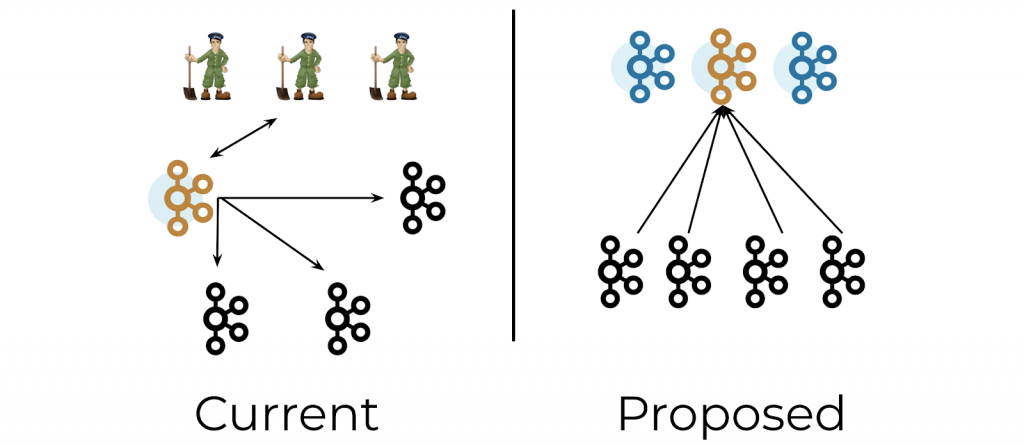
A significant milestone in this ZooKeeper removal effort was achieved in September 2020: The core Raft implementation, a distributed consensus algorithm, was merged into Apache Kafka (diffstat 15,744 additions and 88 deletions). While the Kafka community is making excellent progress on this front, you should begin to prepare your environment for ZooKeeper removal. This blog post walks through some of the key changes you can make now to ensure that all the Kafka tools, applications, and CLI commands are also ZooKeeper free.
How can you make these changes and validate them even though KIP-500 isn’t fully implemented yet? The changes discussed in this blog post use features available today and are related to how the tooling, apps, and CLI interact with the Kafka cluster that are not directly dependent on the KIP-500 changes to core Kafka. Specifically, right now, you can swing your tools from getting metadata from ZooKeeper over to getting metadata from the brokers instead. In the future, once you remove ZooKeeper from your deployment with KIP-500, these changes will be required, but the reasons to take advantage of the runway that you have now include the following:
- Over the years, Kafka has evolved away from ZooKeeper. In the latest Apache Kafka release (version 2.6.0 at the time of this writing), there is a public Kafka API for almost every operation that previously required direct ZooKeeper access. ZooKeeper-related configuration parameters or arguments in administrative tools have already been deprecated, and they may be entirely removed in the next major release. You need to check whether you have some long-forgotten (or not-forgotten-at-all) commands that still rely on ZooKeeper.
- It takes time to audit all of your Kafka tools, applications, and scripts to identify which ones are dependent on ZooKeeper, plan for the appropriate changes, and implement those changes.
- In some instances, especially if you are running older clients or brokers, you may need additional time to first upgrade the code before making changes. This step may be necessary to get the latest versions that have the required configuration parameters or arguments to connect to Kafka brokers instead of ZooKeeper.
- Using Kafka APIs is more secure. Whereas connecting to ZooKeeper bypasses Kafka security mechanisms such as ACLs, connecting directly to the Kafka cluster allows operators to better enforce security mechanisms.
- Use the runway to validate the new workflows, thereby avoiding unexpected surprises later.
The Developer Relations team at Confluent just went through the Kafka Tutorials and examples in GitHub to remove references to ZooKeeper from tooling, applications, and CLI commands wherever possible, and this blog post shares some of those changes:
- Configuring clients and services
- Kafka administrative tools
- REST Proxy API
- Getting the Kafka cluster ID
- Be Thorough
Configuring clients and services
Any Kafka client application or Confluent Platform component needs to talk to a Kafka cluster. This includes:
- Client applications: producers/consumers (written in any programming language), Kafka Streams applications, or ksqlDB applications
- Any service in the Confluent Platform: Kafka Connect, Confluent Replicator, Confluent REST Proxy, Confluent Schema Registry, Confluent Control Center, or Confluent Metrics Reporter (used with Control Center)
- Any CLI command (more on that in the next section)
They all need some configuration that specifies how to connect to the Kafka cluster. Particularly in older Kafka releases, this was provided via a ZooKeeper connection. Newer releases made it possible to connect to the Kafka brokers instead of ZooKeeper, but for backward compatibility, ZooKeeper connectivity was still permitted. So in your deployments, especially those that have been in production for a long time, it may be the case that there are older clients or services still configured to connect to ZooKeeper:
zookeeper.connect=zookeeper:2181
While Apache Kafka strives to always maintain backward compatibility across releases, this is not possible in a situation where a component is removed entirely. Therefore, to become ZooKeeper free, a configuration change may be required. We recommend auditing all client applications and services, and replacing the above configuration with the one below, to connect to the Kafka brokers instead of ZooKeeper:
bootstrap.servers=broker:9092
Schema Registry takes a slightly different form using the same parameters. Replace the ZooKeeper connection configuration parameter kafkastore.connection.url=zookeeper:2181 with the broker connection configuration parameter kafkastore.bootstrap.servers=broker:9092.
Kafka administrative tools
We mentioned command line tools in the previous section—these are “clients,” too. Examples of Kafka command line tools that need to talk to the Kafka cluster include but are not limited to:
- kafka-topics to inspect and act on the topics in a cluster
- kafka-configs to alter configs
- kafka-consumer-groups to act on consumer groups
- kafka-console-producer to produce Kafka messages
- kafka-console-consumer to consume Kafka messages
- kafka-reassign-partitions to move partitions (if you are not using Self-Balancing Clusters or Auto Data Balancer)
In older versions of Apache Kafka, you used to be able to pass in the --zookeeper argument with ZooKeeper connection information, for example:
kafka-topics --zookeeper zookeeper:2181 --create --topic test1 --partitions 1 --replication-factor 1
kafka-configs --zookeeper zookeeper:2181 --entity-type clients --entity-name --alter --add-config consumer_byte_rate=1024
However, since Kafka version 2.2.0, the --zookeeper argument has been deprecated in favor of performing all the same actions by connecting directly to the broker using the AdminClient (KIP-377). In the next major release of Kafka, the deprecated ZooKeeper argument will be removed entirely from many tools. Thus, it’s prudent to make the changes soon. The equivalent ZooKeeper-free commands are as follows:
kafka-topics --bootstrap-server broker:9092 --create --topic test1 --partitions 1 --replication-factor 1 --command-config
kafka-configs --bootstrap-server broker:9092 --entity-type clients --entity-name --alter --add-config consumer_byte_rate=1024 --command-config <properties to connect to brokers>
In the case of secured clusters, if the brokers are configured with SSL or SASL_SSL listeners, the administrative tools require extra security configurations to connect to the brokers. Provide the --command-config argument, as shown above, to point to the AdminClient connection properties file. Work with your security team to ensure that you have the appropriate SSL certificates.
REST Proxy API
The REST Proxy performs Kafka administration actions, topic management, and produce and consume actions. If you have been using the REST proxy for a few years, it’s possible that there is some older code using v1 of the API, which depends on ZooKeeper. For example, you may have some code that consumes from a Kafka topic with v1:
curl -X GET -H “Accept: application/vnd.kafka.binary.v1+json" \
http://rest-proxy:8082/consumers/cg1/instances/ci/topics/test1
To become ZooKeeper free, update these commands to v2 or v3 of the REST Proxy API, which has no dependency on ZooKeeper. API v2 has been available since around 2017 and API v3 since September 2020. Both are supported in the REST interface embedded within Confluent Server. The v2 command equivalent to the above is this:
curl -X GET -H “Accept: application/vnd.kafka.binary.v2+json" \
http://rest-proxy:8082/consumers/cg1/instances/ci/records
Getting the Kafka cluster ID
Each Kafka cluster has a unique and immutable ID. For an administrator, knowing the Kafka cluster ID is useful in a variety of scenarios, including monitoring, auditing, log aggregation, and troubleshooting. Typically, an administrator would get the Kafka cluster ID from the broker log file or from the metadata.properties file, which resembles what is shown below:
# #Thu Oct 01 07:38:31 EDT 2020 broker.id=0 version=0 cluster.id=8pOERRLSQkGcV2LE5ExJsQ
If you’re not a Kafka administrator or don’t have access to the broker logs, you might be using the AdminClient’s describeCluster() functionality or the Kafka administrative tools with TRACE level logging enabled to get the Kafka cluster ID. However, you also may have relied on the method of getting the cluster ID from ZooKeeper using the zookeeper-shell command:
zookeeper-shell zookeeper:2181 get /cluster/id
To be ZooKeeper free, you can no longer use zookeeper-shell; instead, use any of the other methods mentioned above or wait for KIP-595, which will introduce a new Kafka administrative command, kafka-metadata-quorum, to provide the cluster ID.
If you are running Confluent Server, by default it runs an HTTP server on port 8090, which you can customize with the configuration parameter confluent.http.server.listeners. The Confluent CLI can retrieve the Kafka cluster ID from this HTTP endpoint:
confluent cluster describe --url http://broker:8090 --output json
The output of the Confluent CLI command resembles this:
{
"crn": "8pOERRLSQkGcV2LE5ExJsQ",
"scope": [
{
"type": "kafka-cluster",
"id": "8pOERRLSQkGcV2LE5ExJsQ"
}
]
}
Work with your IT team to ensure all the networking and firewalls allow you to connect to the brokers. You don’t want networking connectivity issues to catch you by surprise.
Be thorough
In summary, these are the areas to prepare for ZooKeeper removal:
| With ZooKeeper | Without ZooKeeper | |
| Configuring clients and services | zookeeper.connect=zookeeper:2181 | bootstrap.servers=broker:9092 |
| Configuring Schema Registry | kafkastore.connection.url=zookeeper:2181 | kafkastore.bootstrap.servers=broker:9092 |
| Kafka administrative tools | kafka-topics --zookeeper zookeeper:2181 ... | kafka-topics --bootstrap-server broker:9092 … --command-config <properties to connect to brokers> |
| REST Proxy API | v1 | v2 or v3 |
| Getting the Kafka cluster ID | zookeeper-shell zookeeper:2181 get /cluster/id | kafka-metadata-quorum or view metadata.properties or confluent cluster describe --url http://broker:8090 --output json |
Review your Kafka deployment thoroughly, because sometimes a self-managed Kafka deployment evolves over time or transfers between people or between teams, which results in losing track of what is implemented where. Whether you are still administering your Kafka cluster through scattered scripts, have runbooks, or are practicing GitOps—it is essential to perform the following:
- Review client configurations and tooling to identify all ZooKeeper parameters and arguments
- Check for possible ZooKeeper dependencies in order of service bringup. For example, if you are using Docker, check the depends_on configuration to see where the ZooKeeper container is a prerequisite, and verify whether it has to be or not
- Look for indirect ZooKeeper dependencies, such as runbooks that use ZooKeeper as a jump host to issue commands on another host
Bonus: By removing all ZooKeeper configurations from your tools and services, they become more Confluent Cloud ready. Confluent Cloud is a fully managed Apache Kafka service in which you don’t have access to ZooKeeper anyway, so your code becomes a bit more portable. Or, to flip this around, you can use Confluent Cloud to verify that your tools really do not depend on ZooKeeper 😉
If you’d like to get started, use promo code C50INTEG to get an additional $50 of free Confluent Cloud usage to try it out.*
There are lots of exciting changes coming with ZooKeeper removal in 2021, and until KIP-500 lands next year, you have lots of runway to start preparing now!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



A Distributed State of Mind: Event-Driven Multi-Agent Systems
This article explores how event-driven design—a proven approach in microservices—can address the chaos, creating scalable, efficient multi-agent systems. If you’re leading teams toward the future of AI, understanding these patterns is critical. We’ll demonstrate how they can be implemented.



Building High Throughput Apache Kafka Applications with Confluent and Provisioned Mode for AWS Lambda Event Source Mapping (ESM)
Learn how to use the recently launched Provisioned Mode for Lambda’s Kafka ESM to build high throughput Kafka applications with Confluent Cloud’s Kafka platform. This blog also exhibits a sample scenario to activate and test the Provisioned Mode for ESM, and outline best practices.