[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
DevOps for Apache Kafka with Kubernetes and GitOps
Operating critical Apache Kafka® event streaming applications in production requires sound automation and engineering practices. Streaming applications are often at the center of your transaction processing and data systems, requiring them to be accurate and highly available.
As emerging technologies and engineering practices become standards for running these demanding systems, we will look at a new example project that weaves together Kubernetes, GitOps, and Confluent Cloud. Before we look closer at the project, let’s define some concepts that are often used in a modern DevOps environment around an event streaming platform.
Streaming applications on Kubernetes
More users are choosing to run streaming applications on top of Kubernetes. Kubernetes thrives as a container orchestration system when the application workloads are stateless and scale horizontally. Applications with these features allow them to work cooperatively and shift between nodes in a Kubernetes cluster.
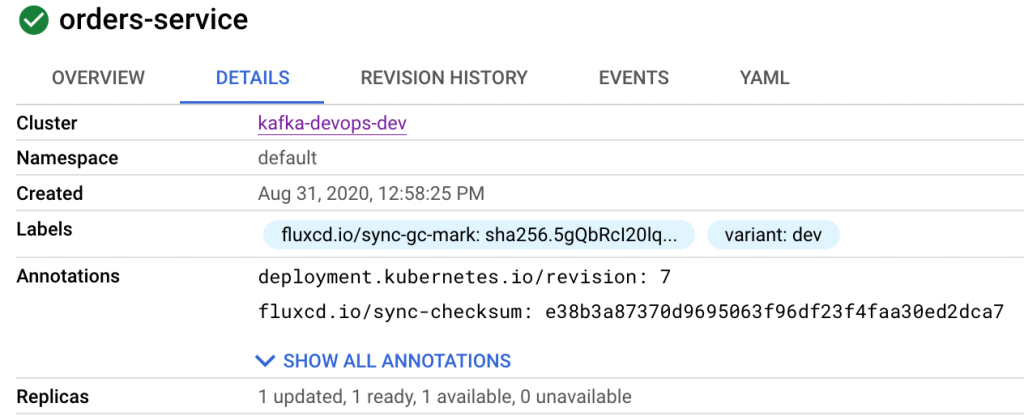
Streaming applications built on Kafka pair nicely with Kubernetes in both of these areas. The Kafka consumer group protocol allows streaming applications to scale up and down dynamically by adding or removing consumer applications to a consumer group.
Streaming applications most often have state, and maintaining state complicates the ability to scale horizontally. Kafka Streams applications benefit from built-in state restoration features, which allows workloads to move processing nodes. In Kafka Streams, state is stored in changelog topics, which allows state stores to be restored by replaying changelog topic events to rebuild the state. This capability allows Kafka Streams workloads to transition across compute nodes inside of the Kubernetes cluster.
Deploying streaming applications as Kubernetes Deployments allows you to leverage Kubernetes features that manage Pod replicas on your behalf and scale horizontally by managing simple configuration values.
Declarative resource management
When managing complex streaming applications on Kubernetes, the capability to reliably modify the deployed state of various systems is paramount. Additionally, you need the ability to quickly recover from failed deployments. With traditional scripted deployments, you might write deployment jobs that move a system from one state to another. This is an imperative approach to operations.
An example of an imperative operation to create a Deployment in Kubernetes might look like this:
kubectl create deployment --image=cnfldemos/orders-service:sha-844f538
With imperative commands, you are defining how you want resources to change to your desired state. This method of managing resources is useful for ad hoc operations; however, it does not scale well as you operate many systems that change often.
Kubernetes gives you the ability to utilize imperative and declarative operations with the preferred method being declarative. With declarative resource management, you define what state you want the resource to be in, and orchestration software drives the state of the resource to match your declaration. A declarative equivalent to the above command would be accomplished by defining a Kubernetes Deployment manifest with a YAML file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: orders-service
spec:
replicas: 1
containers:
- name: orders-service
image: cnfldemos/orders-service:sha-844f538
And applying this to the Kubernetes cluster with the apply command:
kubectl apply -f orders-service-deployment.yaml
Kubernetes utilizes a control loop process to drive the state of the system to match your desired declared state. This method simplifies your operations as you scale the number of resources and changes, as you do not have to maintain all of the instructions for how the system state changes, only the desired final state for each resource.
Later, we will see this same declaration and control loop pattern used in the example project for managing less traditional resource types, like Confluent Cloud services and Kafka Connect configurations.
GitOps

Managing complex distributed systems on Kubernetes requires an approach that facilitates accurate automation. GitOps is a methodology for managing systems where you utilize a Git repository as the source of truth for declarations that define the desired state of your system. When you want to deploy a new application or change the deployed state of an existing application, you can modify declarations and commit them to the Git repository. Automated deployment software monitors the Git repository for changes and applies the desired changes to your system.
There are many benefits to this method of resource management, including:
- Using Git for deployment declarations allows you to leverage existing development workflows and tools, like pull requests (PRs) and code reviews. GitOps allows you to apply the same review and accept processes to deployment code that you use for application code.
- Having a clear history of the changes to your system in a Git log allows you to audit changes to the system and recover from dysfunctional deployments by reverting commits.
- The Git repository represents the desired state of the system. Automated systems can observe the current state of your system and detect divergence from the desired state, alerting when differences arise. When using Git as the source of truth for multiple environments (for example, dev and prod), you can also easily detect differences in the desired state across them.
The Operator pattern
 Kubernetes is designed to be extended, allowing for custom resource types and components to manage applications beyond what is provided natively by Kubernetes. The Operator pattern is used to encode automations that mimic “human operator” tasks, like backing up data or handling upgrades. An Operator should be coded to follow the control loop pattern described earlier, allowing these automation tasks to be defined following the same Declare → Apply method used for all other resources in your system.
Kubernetes is designed to be extended, allowing for custom resource types and components to manage applications beyond what is provided natively by Kubernetes. The Operator pattern is used to encode automations that mimic “human operator” tasks, like backing up data or handling upgrades. An Operator should be coded to follow the control loop pattern described earlier, allowing these automation tasks to be defined following the same Declare → Apply method used for all other resources in your system.
The Confluent Operator product follows this pattern and can be used for advanced operational management of the Confluent Platform. In the streaming-ops project, we are going to explore basic examples of the Operator pattern to manage cloud resources and Kafka Connect deployments.
The streaming-ops project
We’ve recently released a new example project that we hope will help our community if they choose to adopt modern DevOps processes and technologies. The streaming-ops project aims to simulate a production environment and explores modern techniques such as GitOps, secret management, and declarative Cloud-based resource management. This project is adopted from a popular microservices demonstration and is built and maintained by the developer relations team within Confluent.
I suggest you first explore the project by reading this blog post and evaluating the code in the repository. Later, you can opt to run a version yourself with your own forked GitHub repository and Kubernetes cluster. The project comes with usage instructions for running your own instance, including deploying a lightweight Kubernetes distribution locally or utilizing an existing Kubernetes cluster. Because the streaming-ops project uses a GitOps approach, it is required that you first fork the GitHub repository into your own account prior to using it with your own cluster.
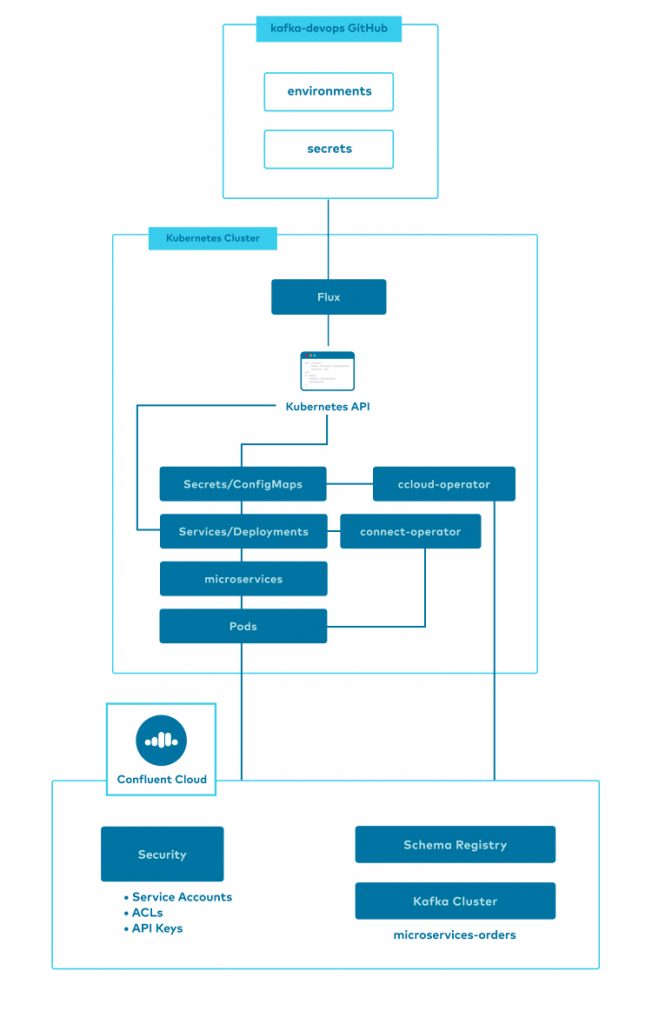
This diagram shows a high-level view of the project components. The remainder of this blog post will explain the technologies and techniques used by streaming-ops to manage a microservices-based streaming application on Kubernetes targeting Confluent Cloud.
Deployments with Flux
Deploying software using a fully automated solution has become standard for modern software development organizations. As explained above, the GitOps methodology for deploying software has many benefits, and the streaming-ops project uses the popular Flux controller to facilitate the GitOps workflow.
As part of the streaming-ops setup process, the Flux controller is deployed into the Kubernetes cluster and connected to the Git repository with a deploy key. Flux is configured to watch certain folders within the Git repository, polling for changes on a continuous loop. Flux will apply changes to the Kubernetes cluster when commits to the repository modify the declarations within the monitored folders.

In addition to the automation benefits, Flux and GitOps enable you to utilize a PR-based deployment model. In this model, all changes to the running system must pass through your typical code review process, and branches on these repositories can be protected to prevent accidental deployments. To modify the state of a deployed system, you can make changes to the declaration files on a feature branch and submit a PR, where the code is reviewed and approved by administrators of the system. Once the PR is accepted and the code changes are merged, Flux detects the changes automatically and then executes the required resource changes via the Kubernetes API.
| ℹ️ | See the streaming-ops documentation on using a PR workflow for scaling Deployments. |
Graduated environments
It is a best practice for critical applications to be validated in test environments prior to being deployed into production. Managing graduated environments (dev → stag → prod, for example) is a common practice for validation and requires careful organization of resource declarations.
To support multiple environments, the streaming-ops project utilizes the Kustomize tool built into kubectl. Kustomize supports the ability to patch YAML declarations, which allows manifests to be customized per environment prior to deployment.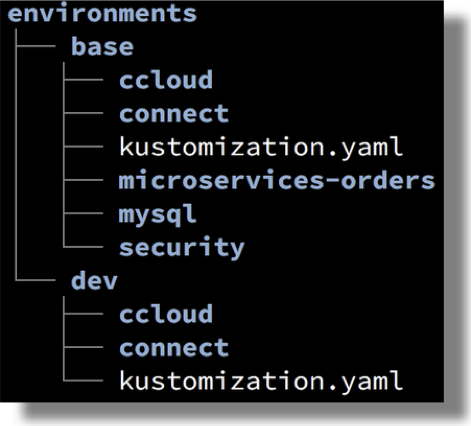
Kustomize allows us to reduce code duplication by defining the majority of declarations and configuration within a base environment. Environment-specific deviations from base are defined in much smaller patch files within named environment folders. See the streaming-ops source files for details.
The streaming-ops project follows the pattern of a single Kubernetes cluster per environment (dev, stag, prod); each Kubernetes cluster has Flux deployment that manages only the single environment to which it’s deployed. Flux invokes Kustomize as part of its deployment process to facilitate the patching of YAML, building the final state of each environment before deployment. As of now, streaming-ops only defines a single environment (dev), but we plan to add additional environments with examples for overriding behaviors in the future.
Controlling secrets
In order to operate securely, services and applications require secret data like passwords, keys, and tokens. Managing this sensitive data requires strong policies, procedures, and technologies. The streaming-ops project utilizes Bitnami Sealed Secrets for this purpose; however, there are many other vendors providing solutions in this space that are worth evaluating.
Secret data should never be stored in cleartext in public or private code repositories. This requirement can complicate the deployment of secret data as you are often forced to maintain secrets in a specialized service and deploy them independent of the applications that utilize them.
Using the Sealed Secrets controller deployed inside of your Kubernetes cluster, secret data is encrypted using public-key encryption. Only the controller is able to decrypt the secret, making the encrypted version safe to store in the Git repository along with your other resource declarations. This process allows you to manage secret data using the same declarative GitOps methodology that you use for all your other resources.
Secrets are managed using the following multi-step process:
- The Sealed Secrets controller is installed into your Kubernetes cluster, which advertises a public key
- Temporary Kubernetes Secret manifests are created using raw secret data
- The temporary Secret manifests are “sealed” (encrypted) using the public key provided by the secrets controller and the temporary Secret manifests are deleted
- The Sealed Secret is committed to the Git repository (it is safe to do so because only the secret controller can decrypt this value)
- Flux observes this new Sealed Secret and installs it into the Kubernetes cluster
- The Secret controller observes the new or modified Sealed Secret and decrypts the value, installing it as an opaque Secret into the Kubernetes cluster
After this final step is complete, the Kubernetes cluster contains standard Kubernetes Secret resources with the decrypted values. Applications and services are now able to use the Secrets from built-in Kubernetes features like volume mounts and environment variable mappings.
Before using Sealed Secrets in production, be sure to review the Bitnami documentation for more important details on managing secrets as well as the Kubernetes role-based access controls (RBAC) for further protection of secret data inside the cluster.
Confluent Cloud Operator
Managing Cloud resources using the same model as you do for your Kubernetes-based applications reduces friction in your operational process. The streaming-ops project accomplishes this by implementing an abbreviated Operator pattern solution, the ccloud-operator.
| ℹ️ | ccloud-operator is not a supported Confluent product and is provided as a reference if you are looking for methods to manage Confluent Cloud resources with Kubernetes. |
The ccloud-operator utilizes the Confluent Cloud CLI and shell scripts built into a Docker image to implement a Kubernetes Operator style (Declare → Apply) solution from the command line. Using the shell-operator project enables us to build basic event-driven scripts, called hooks, which run inside the Kubernetes cluster, reacting to changes in Kubernetes resources. This allows us to declare basic Kubernetes ConfigMap resources, which defines the Confluent Cloud services we want to manage, and respond to changes to the resources automatically.
| ℹ️ | This project utilizes Confluent Cloud for Apache Kafka and Confluent Schema Registry. In order to run a copy of the streaming-ops project, you will need a Confluent Cloud account. When signing up for a new account, use the promo code DEVOPS200 to receive an additional $200 of free usage (see details). |
The first step in building a shell-operator is to define what Kubernetes resources you wish to monitor. ccloud-operator defines this in a shell script function that is invoked by the shell-operator runtime during a config phase on startup.
function common::get_config() {
cat <<EOF
configVersion: v1
kubernetes:
- name: ConnectConfigMapMonitor
apiVersion: v1
kind: ConfigMap
executeHookOnEvent: ["Added","Deleted","Modified"]
labelSelector:
matchLabels:
destination: ccloud
namespace:
nameSelector:
matchNames: ["default"]
jqFilter: ".data"
EOF
}
Here, we are telling the shell-operator runtime that the ccloud-operator wants to monitor Kubernetes ConfigMaps when they are added, deleted, or modified, defined in the default namespace, and have a label matching destination=ccloud. Additionally, we are expressing to the runtime that we are only interested when the .data field of the ConfigMap is modified, allowing us to skip metadata changes to the resource and only respond when the actual configuration data has been changed.
After initialization, the shell-operator runtime will invoke the ccloud-operator scripts whenever there are existing ConfigMaps matching the given configuration. This is called the Synchronization phase and allows Operators to apply changes from resources that were added or modified while the Operator was not running.
After these first two phases, subsequent changes to the filtered Kubernetes resources will result in further invocations of the scripts in the Operator. This is the Event phase. This diagram summarizes the process:
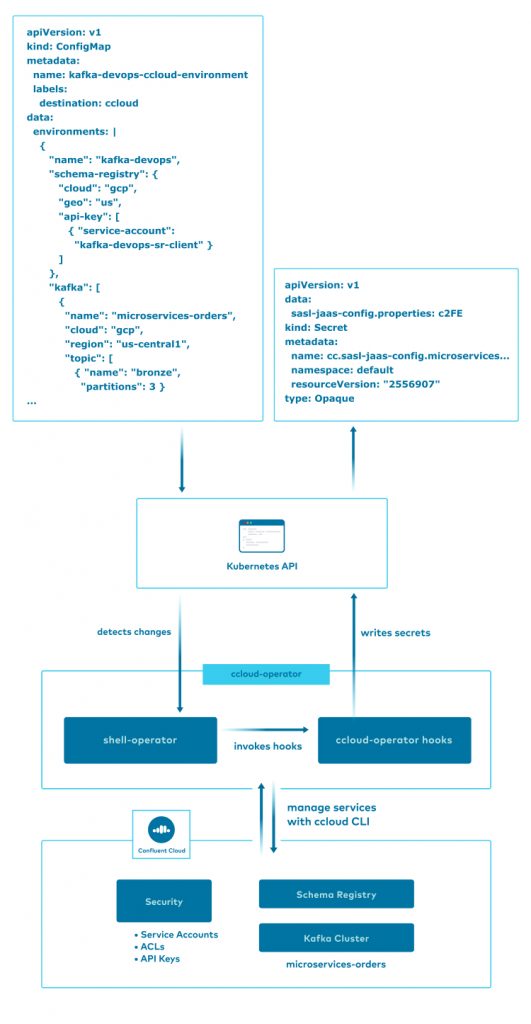
The ccloud CLI provides us with very common create, read, update, and delete (CRUD) imperative commands for controlling our Confluent Cloud resources. We need the ability to utilize these commands within the Kubernetes Declare → Apply model, so we’ve written the ccloud-operator scripts to operate idempotently. Each Confluent Cloud resource supported by ccloud-operator has an associated script that takes a block of JSON and applies that definition to Confluent Cloud. This allows you to use JSON to declaratively define your Confluent Cloud resources within a Kubernetes ConfigMap. The ccloud-operator will perform the necessary work to enable the appropriate resources and services. The following is a snippet of the JSON inside the ConfigMap, which defines the topics showing how to configure partition count and other topic configurations:
"topic": [
{ "name": "bronze", "partitions": 3 },
{ "name": "gold", "partitions": 3 },
{ "name": "silver", "partitions": 3 },
{ "name": "connect-configs", "partitions": 1, "config": "cleanup.policy=compact" },
...
The ccloud-topic.sh hook script is responsible for managing Kafka topics. It will enumerate the list of topics in a given JSON block and apply that topic to the associated Kafka cluster. Using bash and the ccloud CLI, we can update the topic configuration in a series of commands.
First, we create the new topic (if it doesn’t already exist) with the given name, partition count, and configuration values using the parameters passed to the bash function:
ccloud kafka topic create "$name" --if-not-exists --cluster "$kafka_id" $partition_flag $config_flag
If the topic already exists, we want to determine if anything has changed from the desired to the current, so we capture the current full description of the topic in JSON:
result=$(ccloud kafka topic describe $name --cluster "$kafka_id" -o json)
This JSON allows us to compare the current topic configuration to the desired and update the values if necessary. You can do this with a little bash scripting, the jq JSON processor, and the ccloud CLI:
function ccloud::topic::update() {
local name kafka_id config current_config
local "${@}"
diff=
while IFS=',' read -ra cfgs; do
for c in "${cfgs[@]}"; do
IFS='=' read -r key value <<< "$c"
current_value=$(echo "$current_config" | jq -r '."'"$key"'"')
[[ "$current_value" != "$value" ]] && diff=true
done
done <<< "$config"
[[ "$diff" == "true" ]] && {
echo "topic: $name updating config"
ccloud kafka topic update $name --cluster $kafka_id --config $config
} || echo "topic: $name no change"
}
Another feature built into the ccloud-operator is management of service accounts, ACLs, and API keys. When ccloud-operator creates a new API key for a resource, it writes back to the Kubernetes API the API key secret in a Kubernetes Secret manifest so that other applications can use it to properly connect to the services. This allows applications to connect using basic Kubernetes configuration features, and the secret data is never exposed outside of the Kubernetes cluster. The ccloud-api-key.sh hook script is responsible for managing the Confluent Cloud API keys inside the cluster. Here is a bash snippet that shows the code it uses to write an API Key as a Secret to the cluster, applying various labels that make the Secret easier to use:
local result=$(kubectl create secret generic "$secret_name" --from-literal="ccloud-api-key"="$ccloud_api_key" --dry-run=client -o yaml | kubectl label -f - --dry-run=client -o yaml --local resource_id=$resource_id --local service_accont=$service_account --local service_account_id=$sa_id --local key=$key --local category=$category | kubectl apply -f -)
Because the API key is created on the fly by the ccloud-operator, this script uses kubectl create to build a Kubernetes manifest with parameters and then apply it by passing the resulting YAML to the kubectl apply command.
| ℹ️ | Be sure to review Kubernetes RBAC procedures for properly controlling secret data within the cluster. |
Kafka Connect deployments
Kafka Connect is a popular component in the Kafka ecosystem. Connect allows you to integrate your event streaming platform with various external systems with minimal to no custom code required. Managing Kafka Connect workers and connectors is a common task for operating event streaming systems.
Connect workers run in a cooperative cluster, making them ideal for the dynamic, horizontal scalability features built into Kubernetes. Additionally, Connect workers serve an HTTP API for connector configuration management, making them good candidates for Kubernetes Services.
| ℹ️ | Confluent Cloud supports an array of managed connectors, freeing you from the operational burden of Kafka Connect workers. If your use case is supported by one of the available connectors, we suggest that you use the managed service. For demonstration purposes, this project manages its own cluster to connect to a local database. |
In streaming-ops, we have deployed a Kafka Connect cluster into Kubernetes to demonstrate management of workers, connectors, and management of secret data required for connector configurations.
The Connect cluster is deployed as a Kubernetes Deployment and Service. Here is a snippet of the declaration:
apiVersion: v1 kind: Service metadata: name: connect labels: app: connect-service spec: selector: app: connect-service ports: - protocol: TCP port: 80 targetPort: 8083 --- apiVersion: apps/v1 kind: Deployment metadata: name: connect-service spec: replicas: 1 selector: matchLabels: app: connect-service ...
This Deployment will maintain a configurable number of identical worker Pods for the Connect cluster, replacing instances that fail or become unresponsive. Scaling the Connect cluster is a simple matter of changing the value in the spec.replicas field, reviewing the code, and pushing the change to the master branch. Flux will observe the changed resource and apply it to the Kubernetes API, where Kubernetes then completes the work of scheduling the additional Pods on your behalf.
| ℹ️ | The streaming-ops project uses standard Kubernetes Deployments to deploy a Kafka Connect cluster. Confluent Operator can be used for advanced operational use cases of Kafka Connect on Kubernetes. In a future version of streaming-ops, we may integrate Confluent Operator to highlight these capabilities. |
Defining a Service for Connect allows us to expose the worker Pods as a single network service using a common name and load balancer to route traffic between the workers. On top of helping with traffic routing, this makes configuring clients much easier as we can refer to the pool of Connect workers using the single, well-known domain name connect. For example, the following is valid from a shell inside the Kubernetes cluster within the default namespace:
bash-5.0# curl -s http://connect/connectors | jq [ "jdbc-customers" ]
Now that we have a Connect cluster, we want to deploy and manage Kafka connectors on it. In order to manage Connector configurations using a Declare → Apply workflow, we have built another simple operator.
Kafka Connect Operator
Connector configurations are defined in JSON and managed via the Connect worker HTTP API, which makes them well suited to the Declare → Apply model of Kubernetes. This is accomplished in streaming-ops using another shell-operator tool called connect-operator.
| ℹ️ | connect-operator is not supported by Confluent and serves as a reference if you are looking for methods to manage Kafka Connect resources with Kubernetes. |
The connect-operator allows you to declare your Kafka Connect configuration using a standard Kubernetes ConfigMap. In streaming-ops, an example of this declaration is provided in the customers-jdbc-source-config.yaml file.
On startup, the connect-operator indicates to the shell-operator runtime that it is interested in monitoring ConfigMaps, which are decorated with a destination label that have a value of connect. Here is how the filter is declared to the shell-operator:
configVersion: v1
kubernetes:
- name: ConnectConfigMapMonitor
apiVersion: v1
kind: ConfigMap
executeHookOnEvent: ["Added","Deleted","Modified"]
labelSelector:
matchLabels:
destination: connect
namespace:
nameSelector:
matchNames: ["default"]
jqFilter: ".data"
When ConfigMaps matching this filter are added, deleted, or modified in the Kubernetes API, the scripts inside connect-operator are invoked and passed the modified declarations. The connect-operator performs three important functions:
- Materializes the JSON connector configuration at deploy time with variables provided by Kubernetes, allowing for templated configuration of variables like secrets, connection strings, and hostnames
- Determines if desired Kafka Connect configurations require an update based on the actual current configuration, preventing unnecessary calls to the Connect REST API
- Manages connectors by adding, updating, or deleting them utilizing the Connect REST API
| ℹ️ | In a future version of the streaming-ops project, the more secure externalized secrets solution for Kafka Connect will be utilized. See the Kafka Connect security documentation for more details. |
This high-level diagram illustrates the workflow:
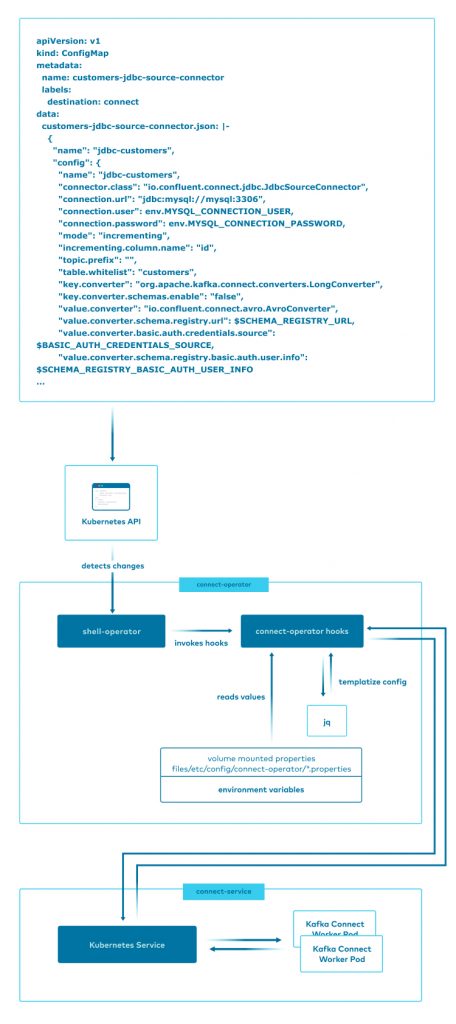
For additional details on how the connect-operator works see the streaming-ops documentation.
Summary
The goal of the streaming-ops project is to provide a modern production-like environment for Kafka users to harvest ideas that they can apply to their own environments. We intend to expand on the project and explore other operational use cases and solutions. If you have an idea for a concept that we can cover, please file a GitHub issue inside the streaming-ops project. Finally, we are also operating a version of the streaming-ops deployment in our own Kubernetes cluster so that we can build and learn from the operational challenges our users face. Please feel free to participate by filing pull requests with our project so that we can learn together.
To view similar resources provided by Confluent, see our examples, cp-demo, and Kafka Tutorials.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


