[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Introducing Confluent for Kubernetes
We are excited to announce that Confluent for Kubernetes is generally available!
Today, we are enabling our customers to realize many of the benefits of our cloud service with the additional control and customization available from self-managing clusters on their private infrastructure. Confluent for Kubernetes provides a complete, declarative API-driven experience for deploying and self-managing Confluent Platform as a cloud-native system.
With Confluent for Kubernetes, we’ve completely reimagined Confluent Platform based on our expertise with Confluent Cloud to help you build your own private cloud Kafka service.
Whether you are an agile dev team that needs to get up and running quickly with Confluent Platform, or a central platform team that’s responsible for enabling your developer workforce to set data in motion, Confluent for Kubernetes can help you be successful by enabling you and your teams to:
- Achieve faster time to value and reduce operational burdens, utilizing our API-driven automation to deploy and manage in any private environment of your choice
- Reduce risk and costly resource investments, utilizing our packaged best practices to run a secure, reliable, and production-ready data-in-motion platform
- Operate efficiently everywhere, deploying to any private cloud to run data-in-motion workloads consistently and scaling to meet changing business demands with efficient use of resources
Download Confluent for Kubernetes
Select “Kubernetes” as your download format to get started.
Enabling the Confluent cloud-native experience everywhere
With the launch of Confluent for Kubernetes, Confluent brings a cloud-native experience for data in motion workloads in on-premises environments. Based on our expertise and learnings from operating over 5,000 clusters in Confluent Cloud, Confluent for Kubernetes offers an opinionated deployment of Confluent Platform that enhances the platform’s elasticity, ease of operations, and resiliency.
With Confluent Cloud, we provide a fully managed, cloud-native service for connecting and processing all of your data. Using a fully managed Apache Kafka® service, you don’t need to think about the infrastructure. Take scaling as an example—when you need more throughput, Confluent Cloud automagically:
- Spins up the infrastructure: compute, storage, and networking
- Deploys the required software: additional Kafka brokers, configured with reliability, security, and Tiered Storage
- Brings them up with no disruption to your operations: balances partition replicas to the new brokers and checks for any under-replicated partitions before validating the brokers as healthy
Now, what if you need to provide this cloud-native experience everywhere, spanning all of your use cases and environments?
You might have data accumulated on-premises that needs to be set in motion. You might have application architectures in your own datacenter environments that need to be transformed to a real-time paradigm. You might have regulatory requirements that mandate controls for data, systems, and applications to stay within your own isolated environments.
With Confluent for Kubernetes, you can achieve the same simplicity, flexibility, and efficiency of the cloud without the headaches and burdens of complex, Kafka-related infrastructure operations. And we provide all the components of a complete platform ready out of the box with enterprise-grade configurations, enabling you to deploy clusters in minutes and start setting data in motion.
Fully automate with declarative APIs
Focusing on what you want rather than how to get it is core to what being cloud native is all about. Fortunately, machines can be programmed to deal with the how.
A declarative API approach allows you to define the desired state of your infrastructure and applications, and then the underlying software and systems make it happen. If you are a platform team that manages a service for many developers in your organization, this approach frees you up to focus on higher-value activities that drive the business rather than managing the low-level infrastructure.
Confluent for Kubernetes provides high-level declarative APIs by extending the Kubernetes API through CustomResourceDefinitions to support the management of Confluent services and data plane resources, such as Kafka topics. As a user, you’ll interact with the CustomResourceDefinition by defining a CustomResource that specifies the desired state. Then Confluent for Kubernetes will take care of the rest.
Manage Confluent services
Confluent for Kubernetes provides a set of CustomResourceDefinitions to deploy and manage Confluent services: Kafka, ZooKeeper, Confluent Schema Registry, Kafka Connect, ksqlDB, and Confluent Control Center.
The declarative API enables you to leave the infrastructure handling to software automation, freeing you to focus solely on your real-time business applications:
- Scale up Kafka with a single change to the declarative spec. Confluent for Kubernetes then spins up the required compute, networking, and storage, starts the new brokers, and balances partitions onto the new broker.
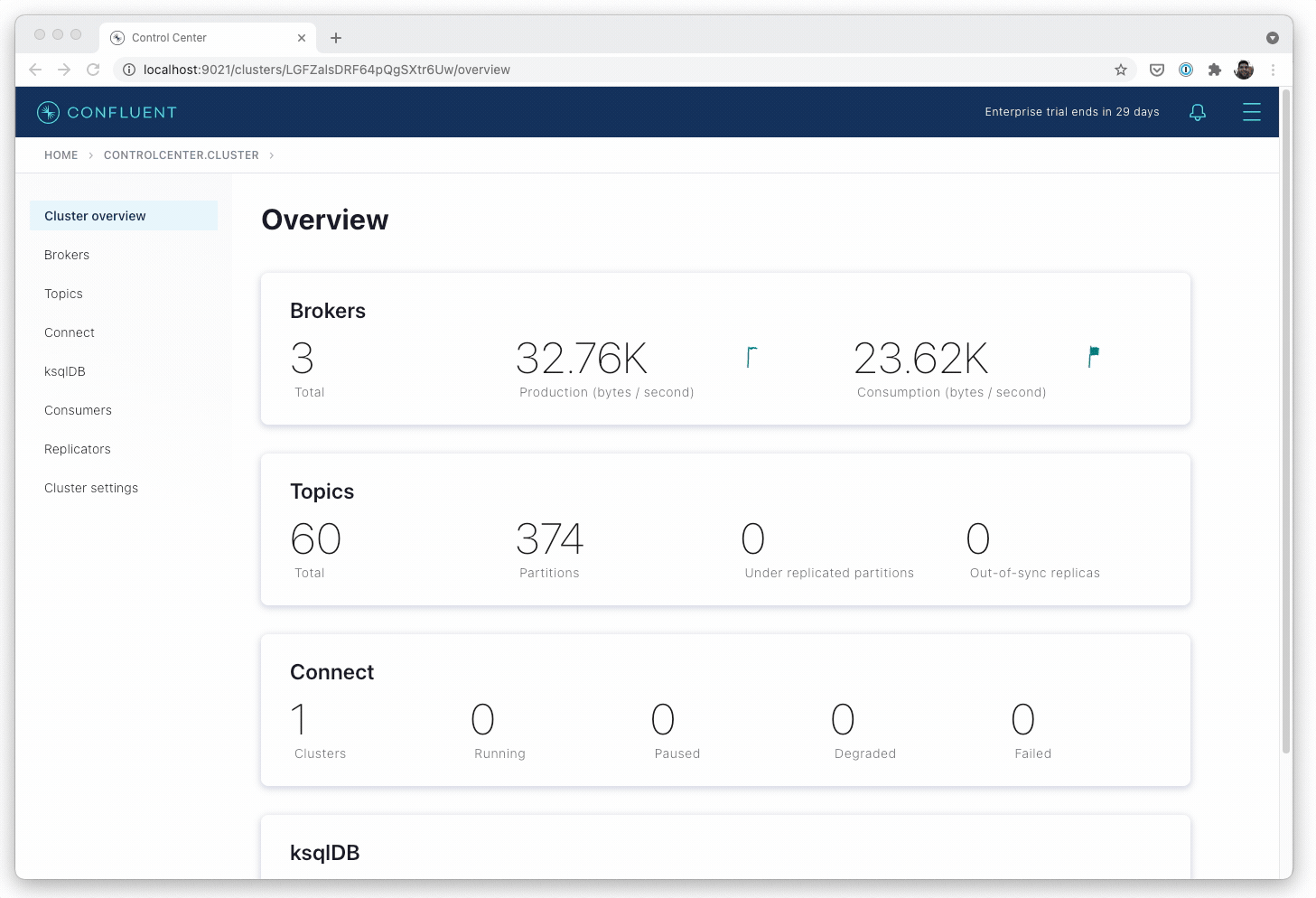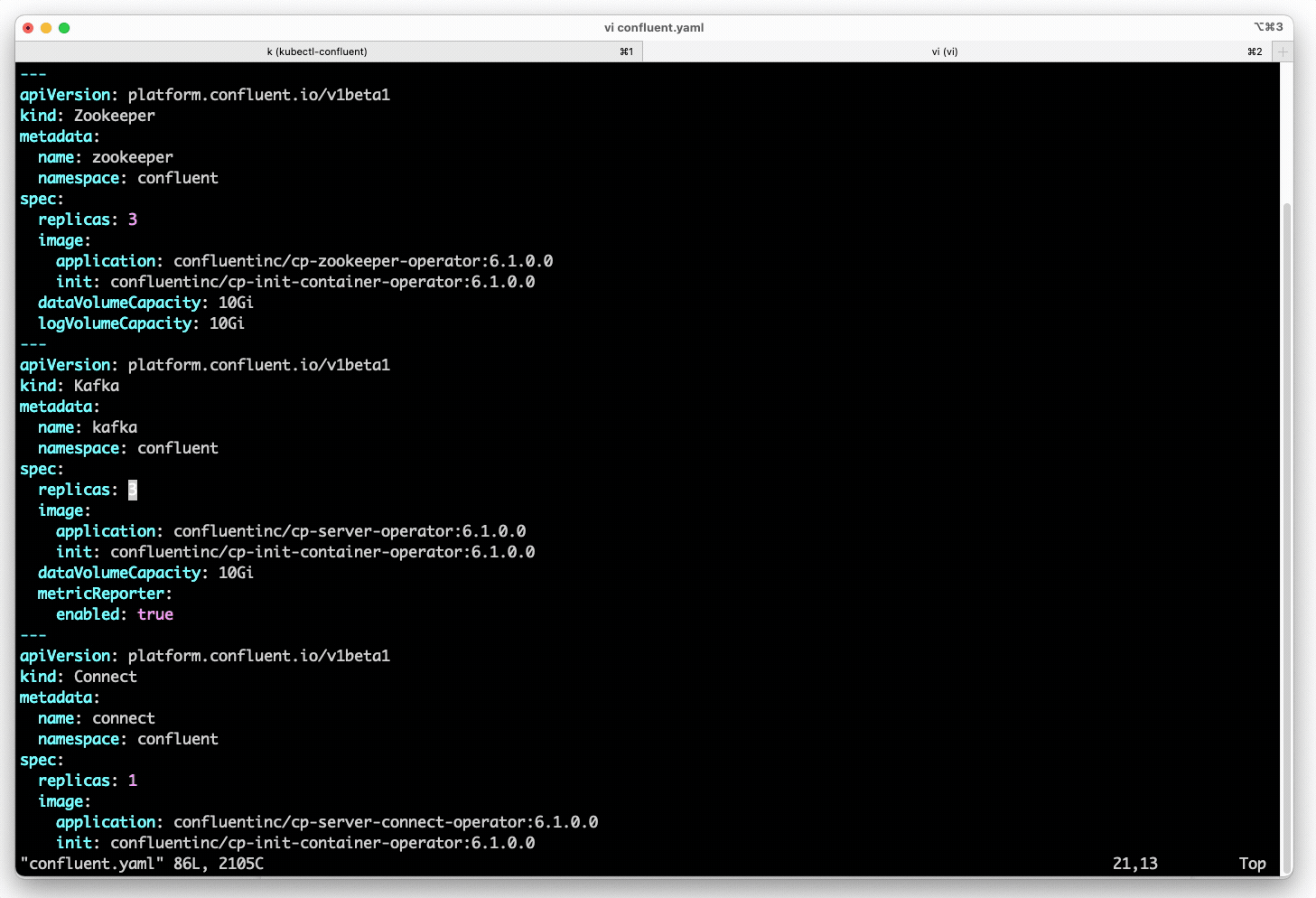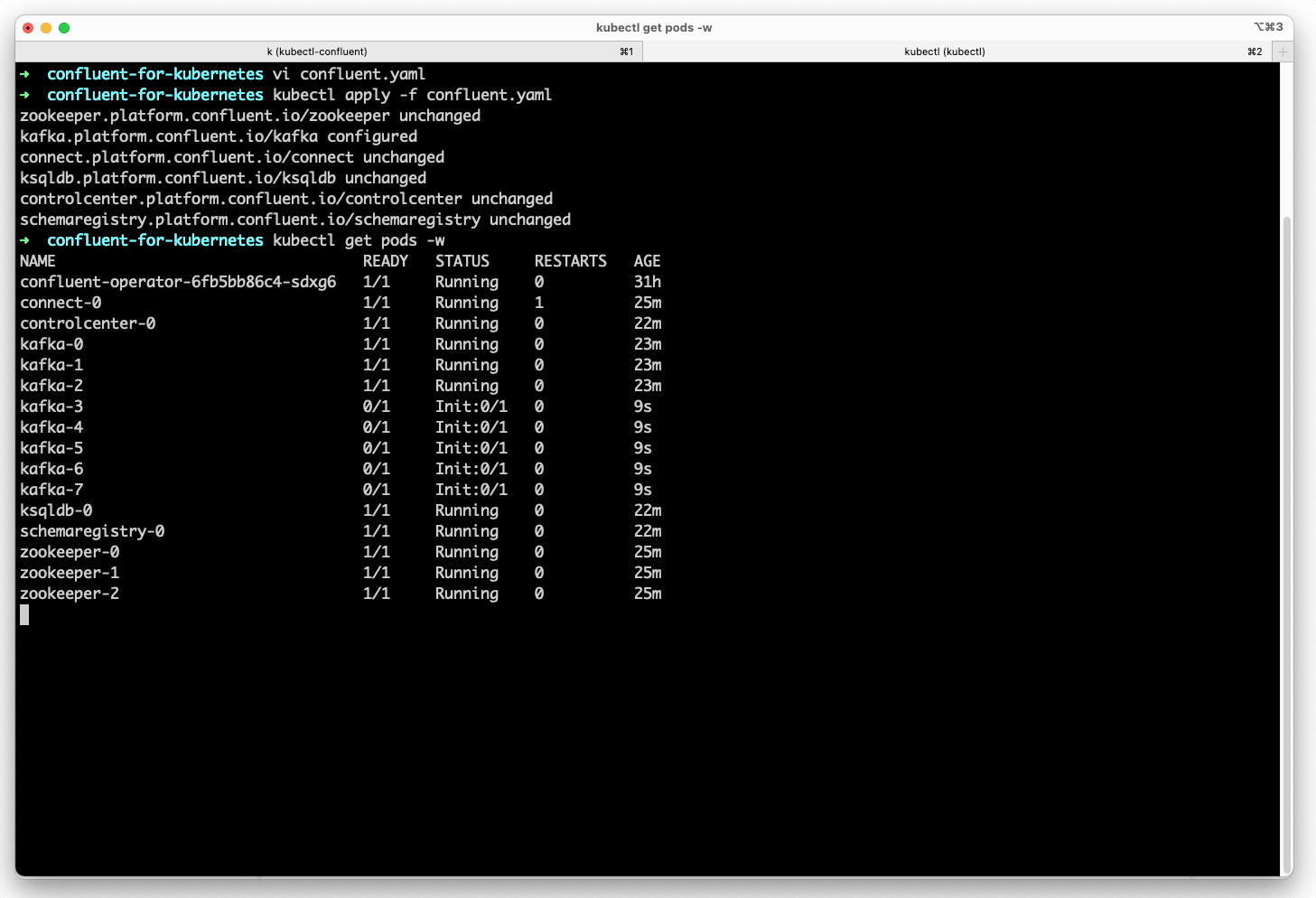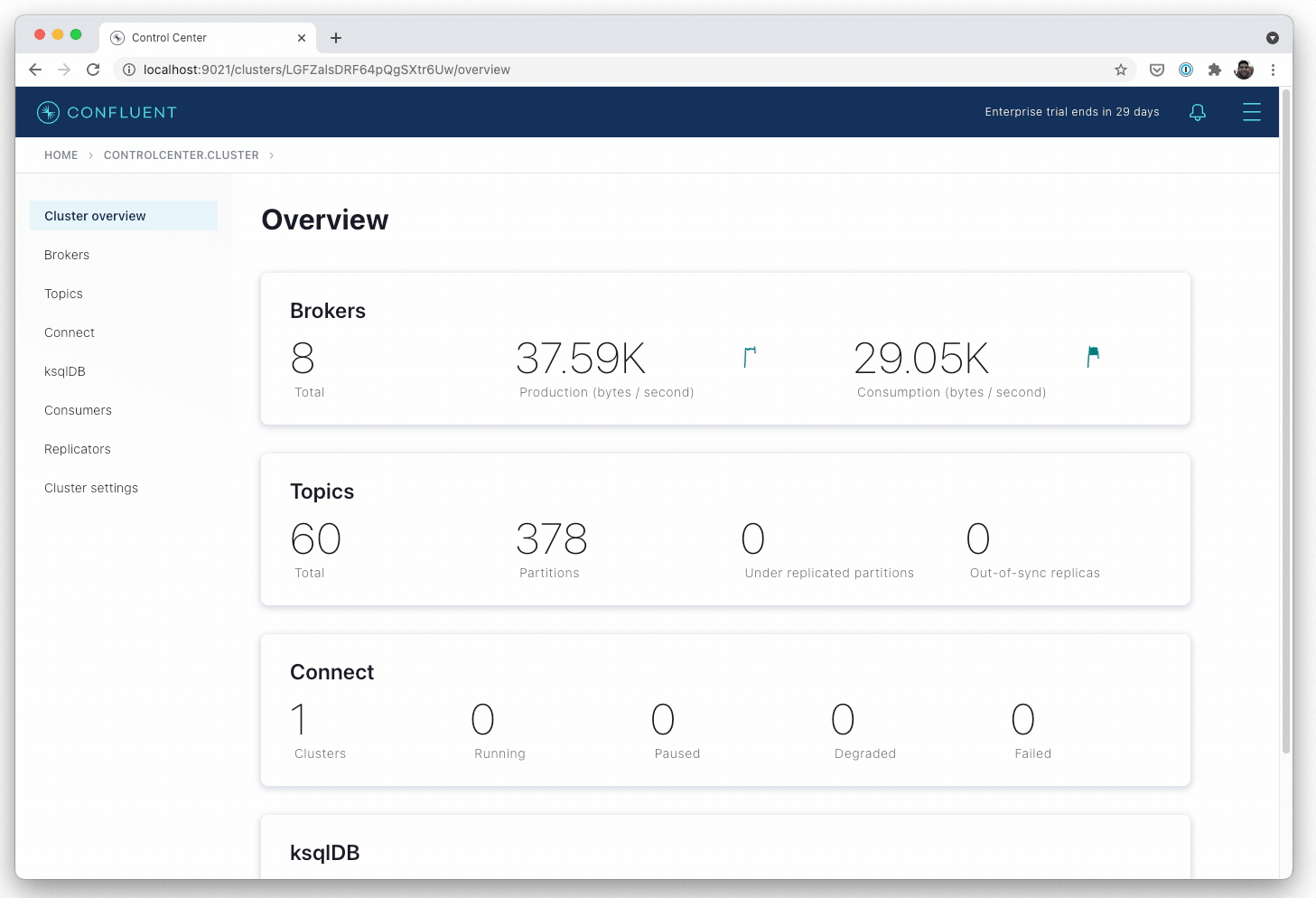
- Deploy a fully secure Confluent Platform with a single declarative spec. Confluent for Kubernetes automates platform configuration for strong authentication, authorization, and network encryption, as well as creates the set of access controls and TLS certificates required by Confluent services to operate.
kind: Kafka spec: replicas: 3 image: application: confluentinc/cp-server-operator:6.1.0.0 init: confluentinc/cp-init-container-operator:6.1.0.0 dataVolumeCapacity: 250Gi tls: autoGeneratedCerts: true authorization: type: rbac listeners: external: authentication: type: plain jaasConfig: secretRef: credential externalAccess: type: loadBalancerA single declarative spec for secure Kafka
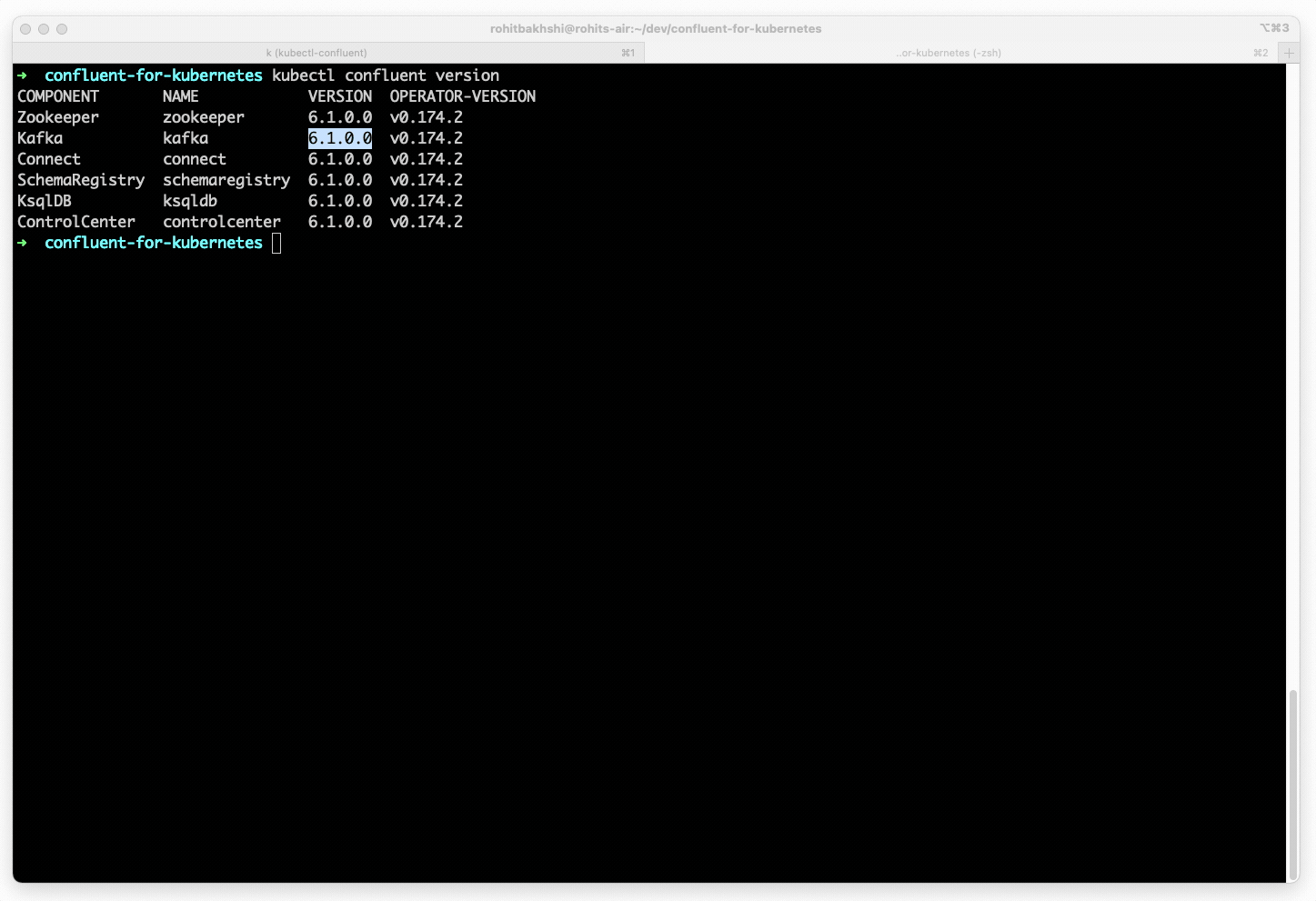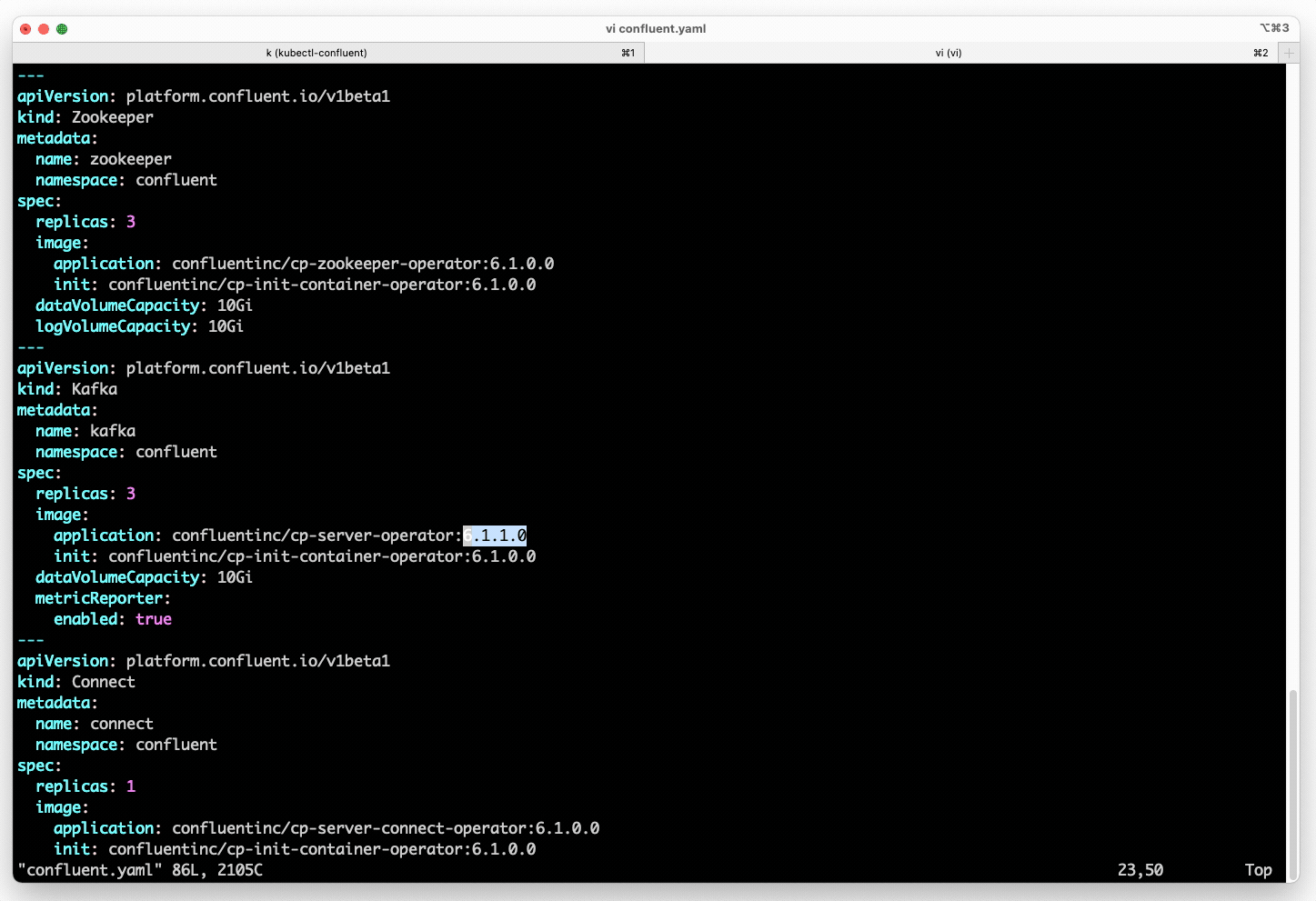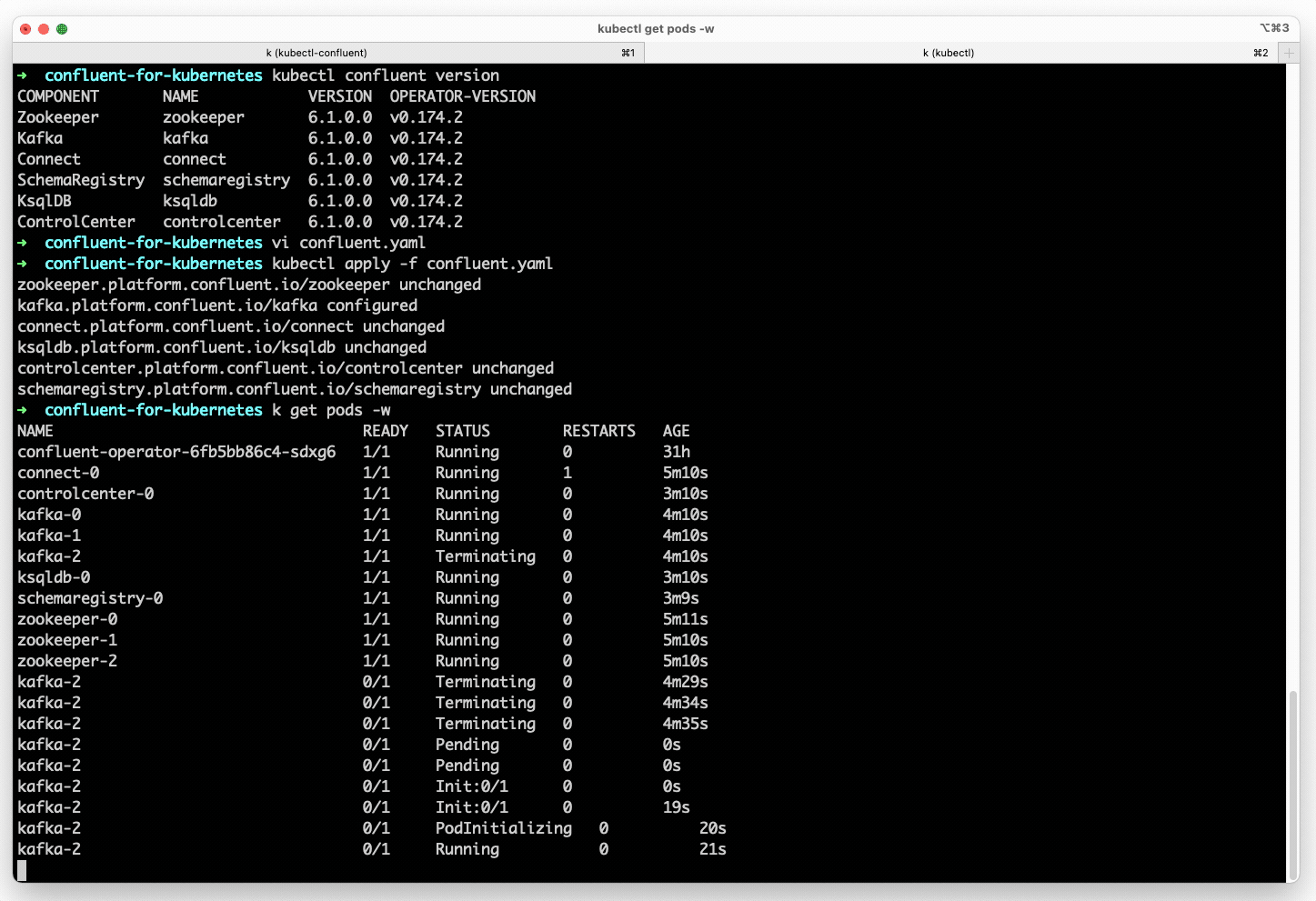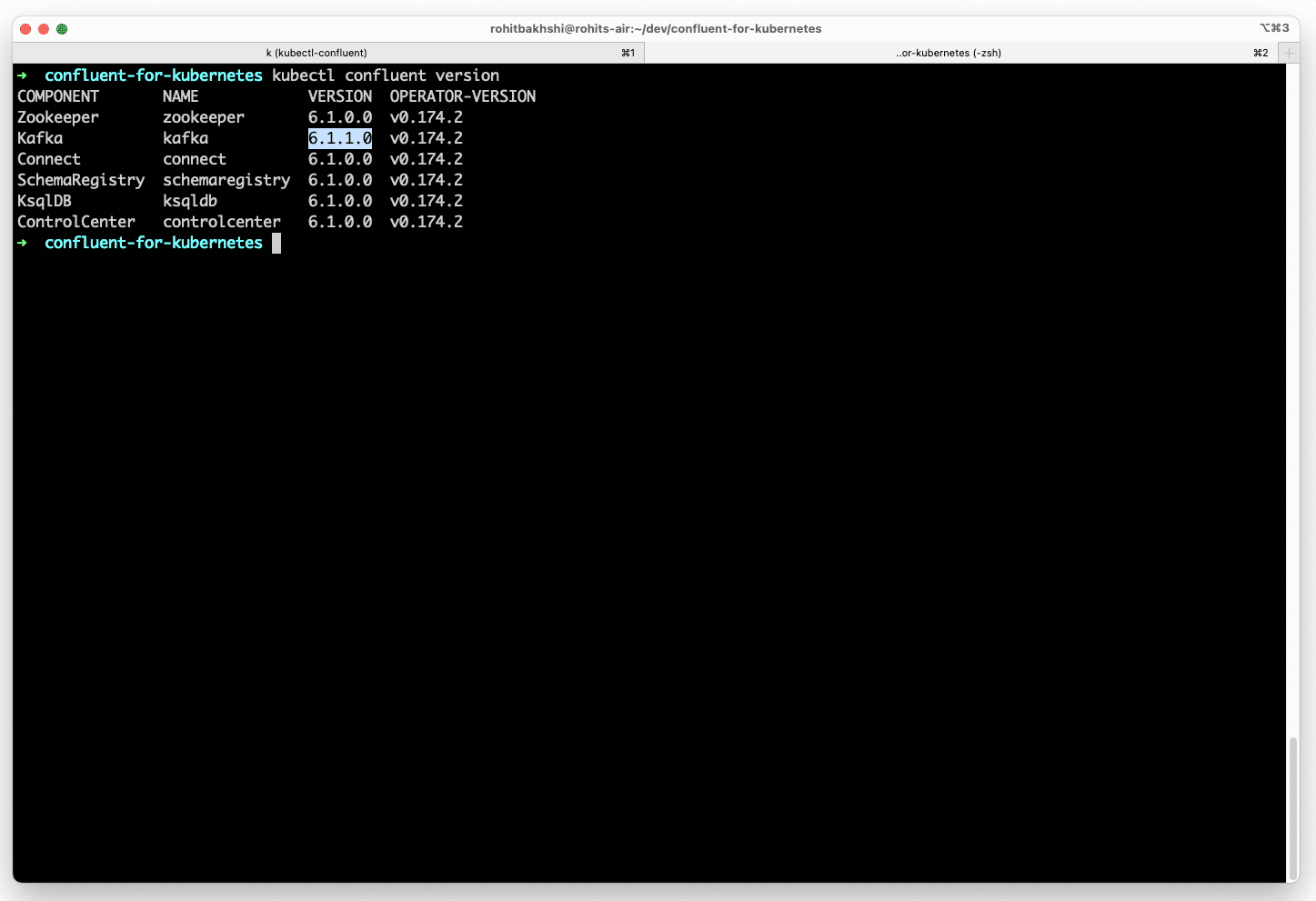
- Upgrade to the latest Confluent Platform release by specifying the new version in the declarative spec. Confluent for Kubernetes then orchestrates a rolling upgrade, deploying the new version without disruption to ongoing workloads.
- Deploy fault-tolerant infrastructure in any environment. Confluent for Kubernetes understands the infrastructure topology of nodes, racks, and zones, while automating the detection of and ensuring resilience to node, rack, and zone failures.
kind: Kafka spec: replicas: 6 rackAssignment: nodeLabels: - topology.kubernetes.io/zone podTemplate: serviceAccountName: kafka oneReplicaPerNode: true image: application: confluentinc/cp-server-operator:6.1.0.0 init: confluentinc/cp-init-container-operator:6.1.0.0A single declarative spec for fault-tolerant-zone-aware Kafka
Manage data plane resources
Confluent for Kubernetes provides a set of CustomResourceDefinitions to manage Confluent data plane resources, in particular, topics and Role-Based Access Control (RBAC) role bindings.
You now can specify an application, its dependent topics, and its required RBAC role bindings—all in one declarative specification. This declarative spec can be used to test in QA and operate in production.
apiVersion: platform.confluent.io/v1beta1
kind: KafkaTopic
metadata:
name:
namespace: confluent
spec:
replicas: 1
partitionCount: 1
configs:
cleanup.policy: "delete"
Manage Confluent data plane resources with a “custom resource” declarative spec
Deliver a consistent experience with packaged best practices
Confluent for Kubernetes provides a declarative spec that captures your desired state. This forms the source of truth for your infrastructure and application state. You can leverage this source of truth to drive consistency across your organization:
- Provide a consistent, secure-by-default production environment. Utilize a declarative spec with complete security controls. This includes fully automating Confluent’s granular Role-Based Access Control for authorization—taking a setup process with dozens of steps down to a one-step process.
- Deliver a simple-to-deploy development environment. Utilize a declarative spec that brings up all Confluent Platform services with optimal resource utilization.
- Standardize how Kafka is exposed to external client applications, avoiding the risk of misconfigurations and security incidents. Utilize a declarative spec that either leverages load balancers or an ingress controller.
These declarative specs enable you to express the state of your infrastructure and application state as code—as a collection of YAML files. You can check these YAML files into a Git repository so that your teams can collaborate on managing these environments. With CI/CD systems, the YAML files can be pulled from Git to deploy updates to the Confluent environments in development, QA, and then production. This entire paradigm is referred to as GitOps.
If you’d like to learn more, check out the Kafka Summit talk: GitOps for Kafka with Confluent for Kubernetes.
Confluent for Kubernetes packages the constructs for declaratively managing the complete platform. If you are a central platform team or a shared services team, you can build on top of these to provide your application teams a self-service, private cloud experience for Confluent Platform.
Leverage a cloud-native ecosystem to operate efficiently
It’s not just Confluent that you’ll be running in your shared compute environment! Using Confluent for Kubernetes, you can utilize Kubernetes-native interfaces, integrations, and scheduling controls to operate consistently and cost-effectively alongside other applications and data systems.
We started on this journey a few years ago with Confluent Operator. We started with using Helm to provide a simple configuration abstraction on top of Kubernetes and allowed you to define a declarative spec as a Helm values.yaml file.
As we thought about how to provide automation and packaged best practices, we realized that Helm templates were not the right architecture choice. Thus, we moved to an industry standard and aligned on providing a Kubernetes-native interface with CustomResourceDefinitions and Controllers. A Kubernetes-native experience allows you to rely on an API-driven approach through custom resources and take advantage of ecosystem tooling and features inherent to Kubernetes. This means not having to build specialized knowledge of how the applications are deployed, like how to configure storage and network for stateful services.
Each Confluent for Kubernetes resource configuration spec is defined as a Kubernetes-native CustomResourceDefinition, and each Confluent resource provides a configuration extensibility interface:
- Configure component server properties, JVM configurations, and Log4j properties for each Confluent Platform service.
- Manage the lifecycle of sensitive credentials and configurations separately, and only reference them in the Confluent resource configuration spec. Leverage industry standards like Kubernetes Secrets or Hashicorp Vault to manage the lifecycle of credentials.
- Specify workload scheduling rules through Kubernetes tolerations, as well as Node and Pod affinity.
- Integrate with Prometheus and Grafana out of the box. Each Confluent Platform service exposes JMX metrics through a Prometheus exporter, and Prometheus on Kubernetes automatically discovers the exporter interface and starts scraping metrics.
Looking forward to what’s next
Global control plane
Today, Confluent for Kubernetes gives you the ability to define a declarative spec for development and production configurations. You can then deploy and manage that in any environment of your choice.
In the future, you’ll receive a consistent experience across those environments and deployments:
- A single pane of glass to view operational status across multiple environments, with the ability to drill down into each environment
- A GUI and CLI interface to deploy and manage Confluent across environments
Cloud-native networking
Istio is a platform to connect, manage, and secure microservices. Kafka is a popular tool for microservices because it solves many of the issues of microservices communication and orchestration, while enabling attributes that microservices aim to achieve, such as scalability, efficiency, and speed.
Although Istio was originally architected to facilitate RESTful HTTP communications, there are a few scenarios where Istio could evolve to help Kafka operations:
- Istio could provide a network communication view across the Confluent services
- Istio could serve as a routing layer for clients to Kafka broker communication
- Istio could help manage TLS encryption certificates and configurations
We’ve documented the current state in this white paper. We are actively exploring how this evolves, and you’ll see more blog posts from us on this in the future.
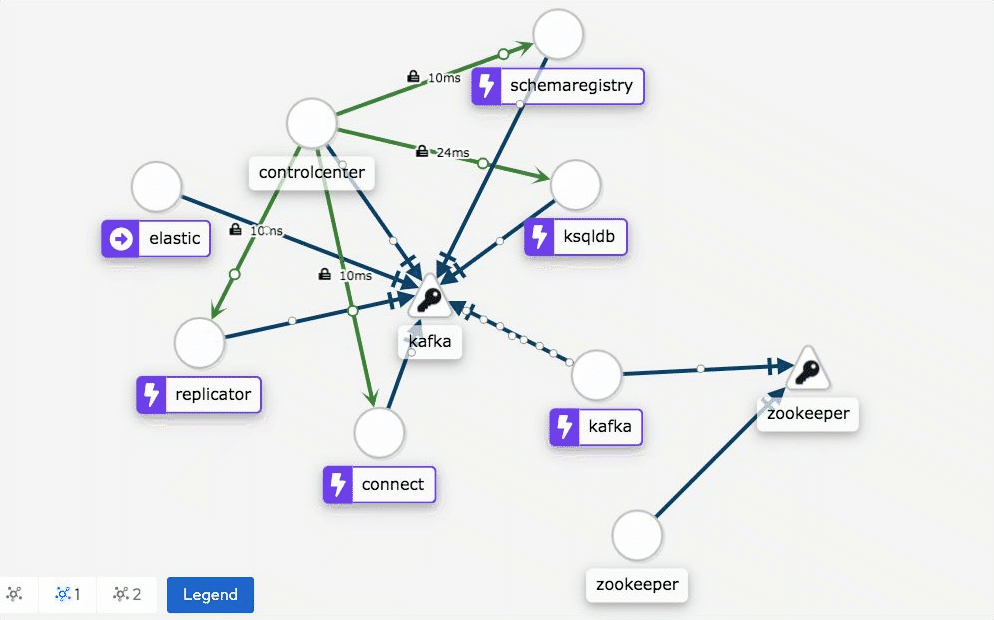
Sneak peek of Istio providing a network communication view for Confluent services
Summary
We believe that cloud-native data systems are the future and that Kafka and event streams are core to the architecture primitives for digital businesses to set their data in motion. Now is the time to build towards a cloud-native Confluent across all your environments.
Whether you want to go to production with your first use case and operate with agility, or are building streaming as a service for developers across your organization, check out Confluent for Kubernetes and get started today.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...