Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
🚂 On Track with Apache Kafka – Building a Streaming ETL Solution with Rail Data
Trains are an excellent source of streaming data—their movements around the network are an unbounded series of events. Using this data, Apache Kafka® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. With tools like KSQL and Kafka Connect, the concept of streaming ETL is made accessible to a much wider audience of developers and data engineers. The platform shown in this article is built using just SQL and JSON configuration files—not a scrap of Java code in sight.
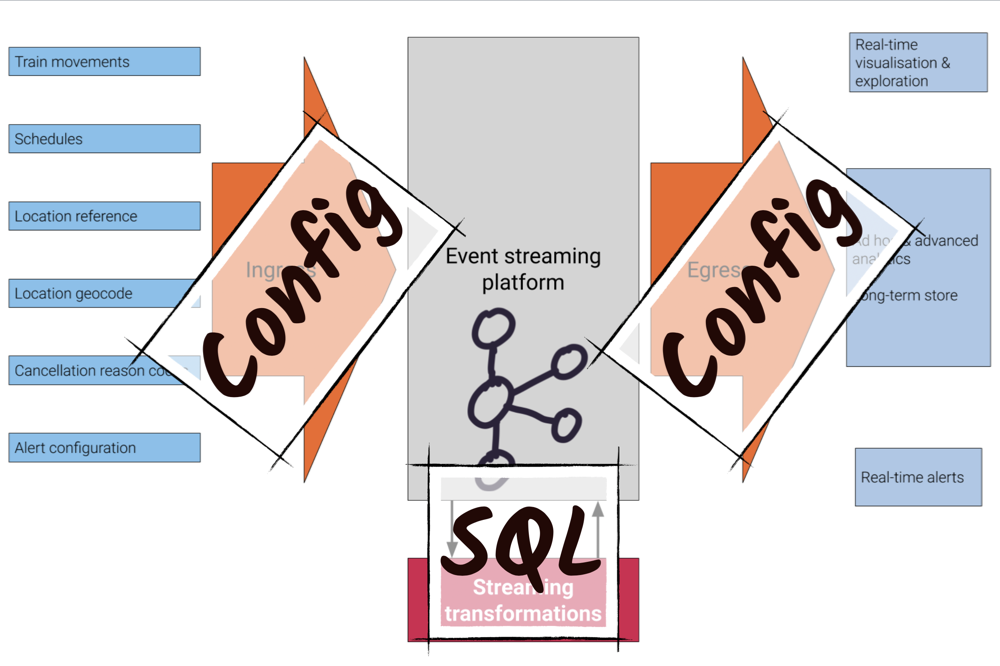
My source of data is a public feed provided by the UK’s Network Rail company through an ActiveMQ interface. Additional data is available over REST as well as static reference data published on web pages. As with any system out there, the data often needs processing before it can be used. In traditional data warehousing, we’d call this ETL, and whilst more “modern” systems might not recognise this term, it’s what most of us end up doing whether we call it pipelines or wrangling or engineering. It’s taking data from one place, getting the right bit of it in the right shape, and then using it or putting it somewhere else.
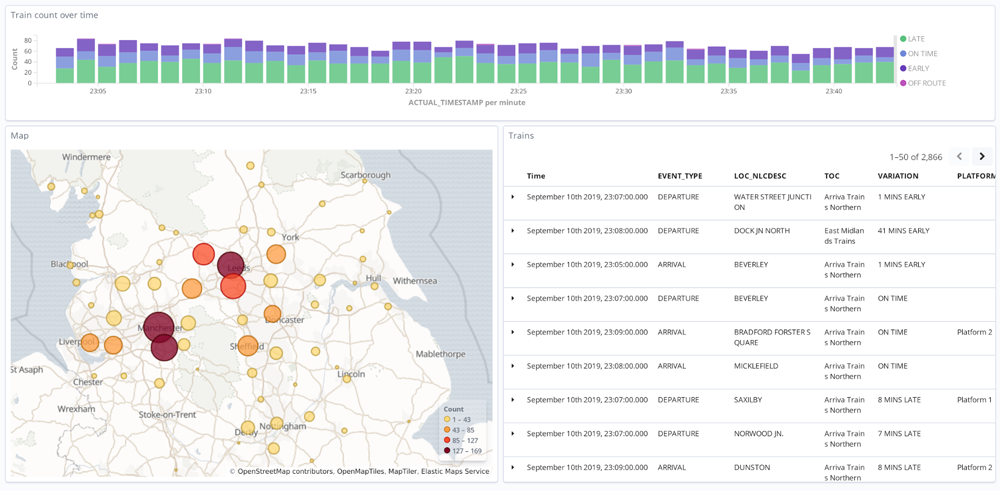
Once the data is prepared and available through Kafka, it’s used in multiple ways. Rapid analysis and visualisation of the real-time feed—in addition to historical data—is provided through Elasticsearch and Kibana.
For more advanced analytics work, the data is written to two places: a traditional RDBMS (PostgreSQL) and a cloud object store (Amazon S3).
I also used the data in an event-driven “operational” service that sends push notifications whenever a train is delayed at a given station beyond a configured threshold. This implementation of simple SLA monitoring is generally applicable to most applications out there and is a perfect fit for Kafka and its stream processing capabilities.
The data
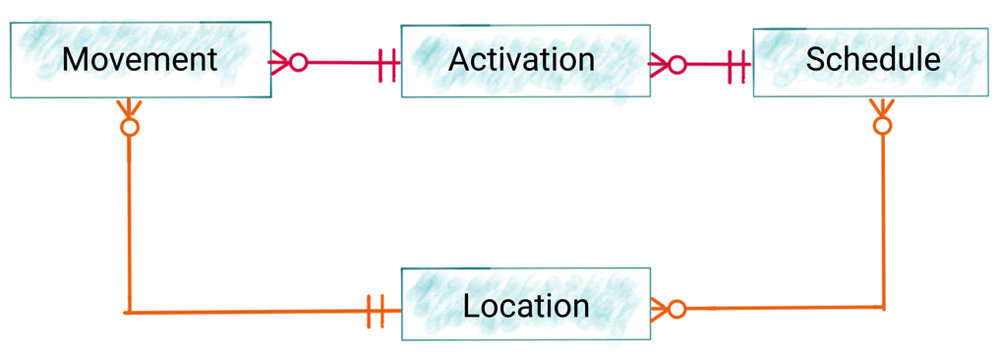
As with any real system, the data has “character.” That is to say, it’s not perfect, it’s not entirely straightforward, and you have to get to know it properly before you can really understand it. Conceptually, there are a handful of entities:
- Movement: a train departs or arrives from a station
- Location: a train station, a signal point, sidings, and so on
- Schedule: the characteristics of a given route, including the time and location of each scheduled stop, the type of train that will run on it, whether reservations are possible, and so on.
- Activation: an activation ties a schedule to an actual train running on a given day and its movements.
Ingesting the data
All of the data comes from Network Rail. It’s ingested using a combination of Kafka Connect and CLI producer tools.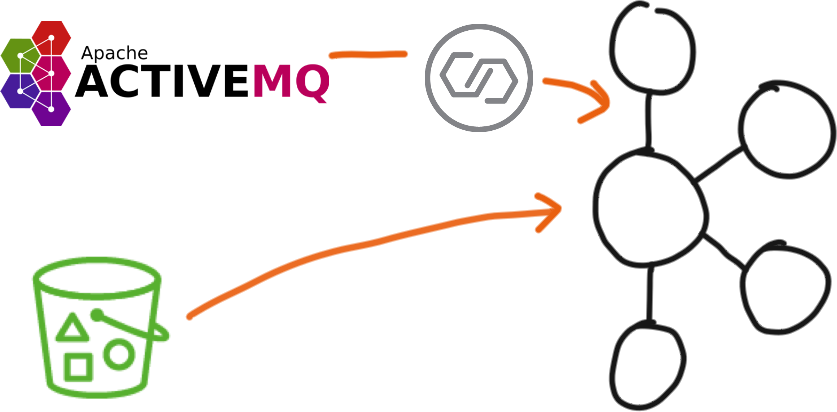
The live stream of train data comes in from an ActiveMQ endpoint. Using Kafka Connect and the ActiveMQ connector, we stream the messages into Kafka for a selection of train companies.
The remaining data comes from an S3 bucket which has a REST endpoint, so we pull that in using curl and kafkacat.
There’s also some static reference data that is published on web pages. After we scrape these manually, they are produced directly into a Kafka topic.
Wrangling the data
With the raw data in Kafka, we can now start to process it. Since we’re using Kafka, we are working on streams of data. As events arrive, they get processed and written back onto a Kafka topic, either for further processing or use downstream.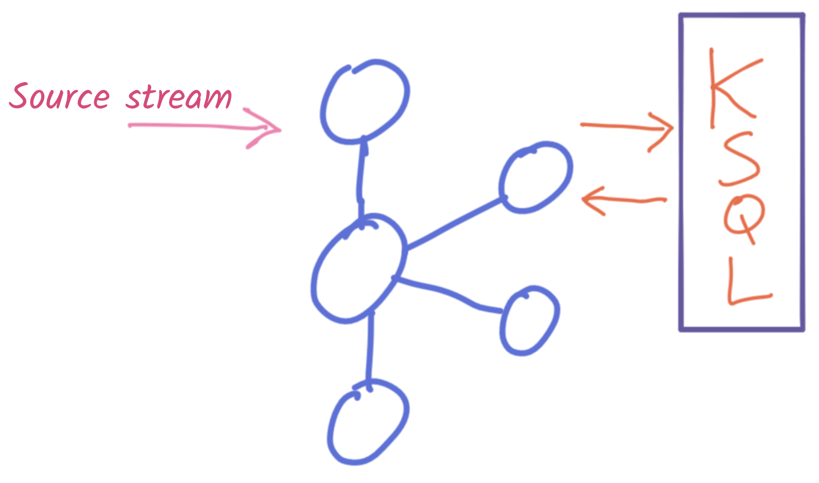 The kind of processing that we need to do includes:
The kind of processing that we need to do includes:
- Splitting one stream into many. Several of the sources include multiple types of data on a single stream, such as the data from ActiveMQ which includes Movement, Activation, and Cancellation message types all on the same topic.
- Applying a schema to the data
- Serialising the data into Avro for easier use downstream
- Deriving and setting the message key to ensure correct ordering of the data as it is partitioned across the Kafka cluster
- Enriching columns with conditional concatenation to make the values easier to read
- Joining data together, such as a movement event to reference information about its location, including full name and coordinates so as to be able to plot it on a map at a later point in the pipeline
- Resolving codes in events to their full values. An example of this is the train operating company name (EM is the code used in events, which users of the data will expect to see in its full form, East Midlands Trains).
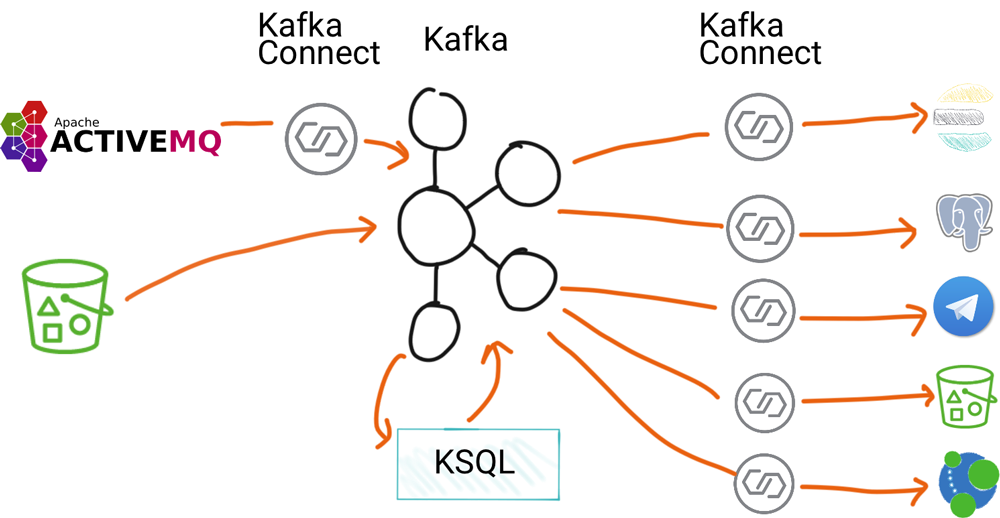
All of this is done using KSQL, in several stages where necessary. This diagram shows a summary of one of the pipelines:
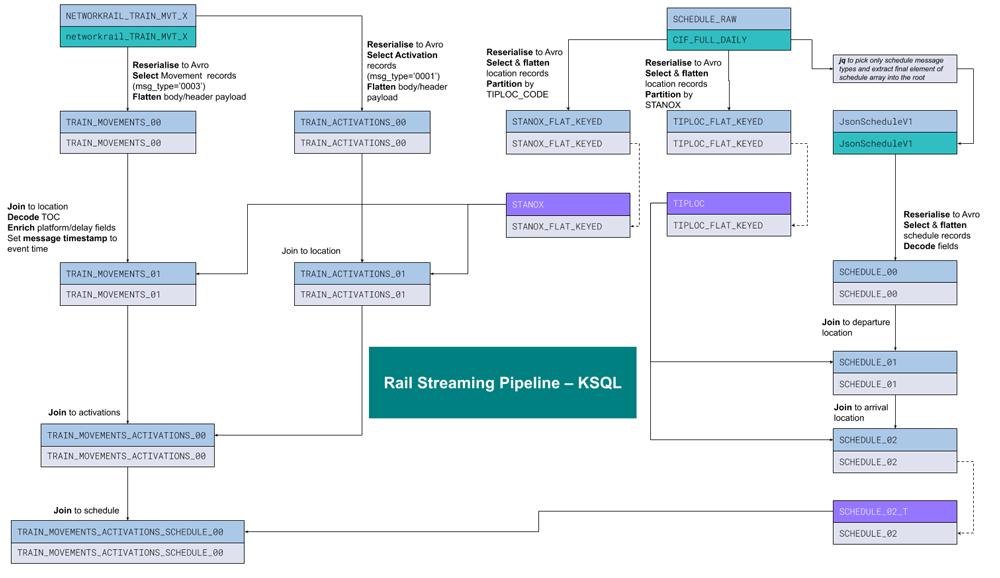
Using the data
With the ingest and transform pipelines running, we get a steady stream of train movement information.
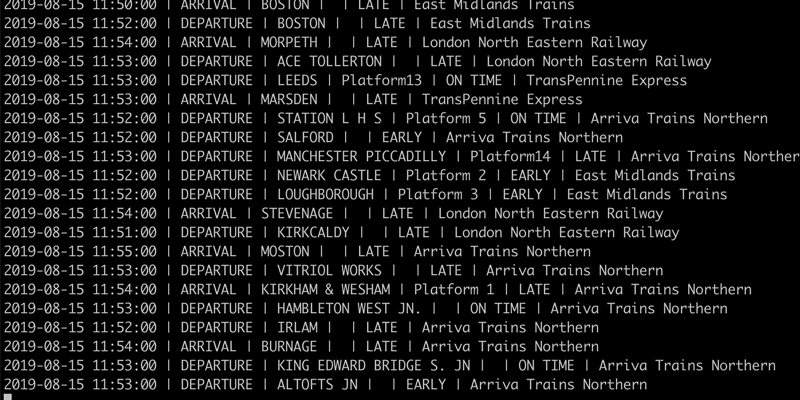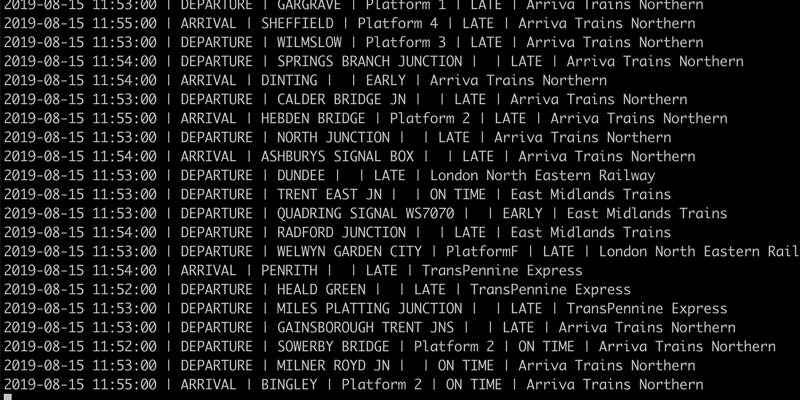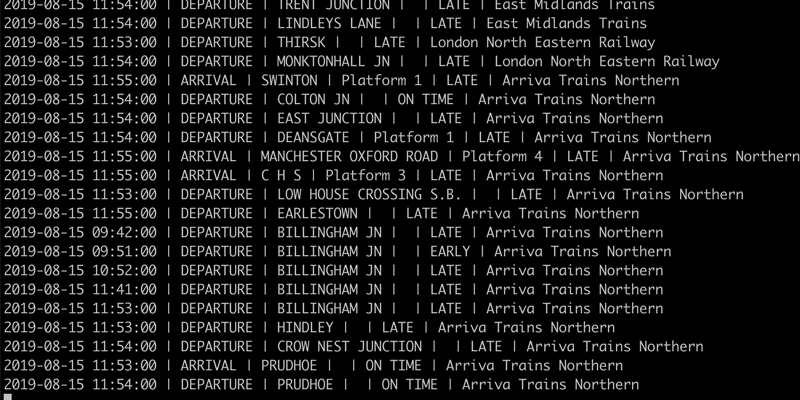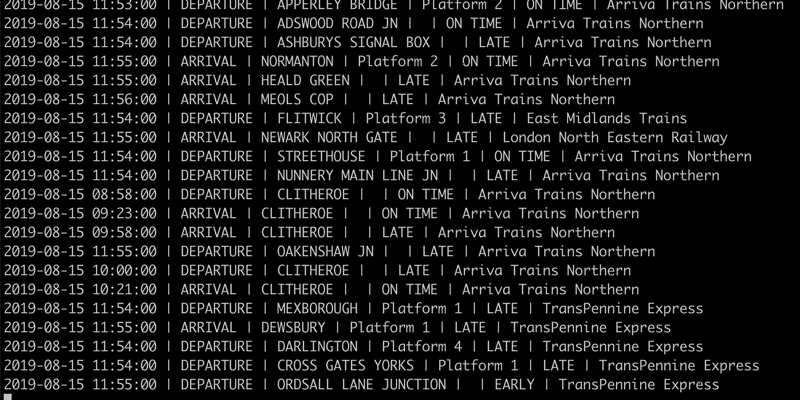
This live data can be used for driving alerts as we will see in more detail shortly. It can also be used for streaming to target datastores with Kafka Connect for further use. This might apply to a team who wants the data in their standard platform, such as Postgres, for analytics.
With the Kafka Connect JDBC connector, it’s easy to hook up a Kafka topic to stream to a target database, and from there use the data. This includes simple queries, as well as more complex ones. Here’s an analytical aggregate function to show by train company the number of train movements that were on time, late, or even early:
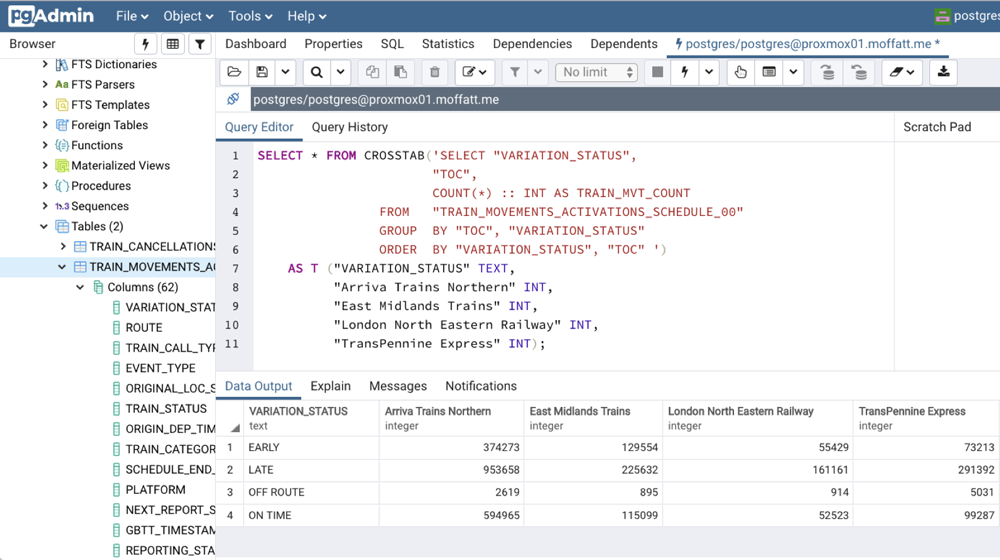
This is a classic analytical query that any analyst would run, and an RDBMS seems like an obvious place in which to run it. But what if we could actually do that as part of the pipeline, calculating the aggregates as the data arrives and making the values available for anyone to consume from a Kafka topic? This is possible within KSQL itself:
ksql> SELECT TIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd') AS Date, VARIATION_STATUS as Variation, SUM(CASE WHEN TOC = 'Arriva Trains Northern' THEN 1 ELSE 0 END) AS Arriva, SUM(CASE WHEN TOC = 'East Midlands Trains' THEN 1 ELSE 0 END) AS EastMid, SUM(CASE WHEN TOC = 'London North Eastern Railway' THEN 1 ELSE 0 END) AS LNER, SUM(CASE WHEN TOC = 'TransPennine Express' THEN 1 ELSE 0 END) AS TPE FROM TRAIN_MOVEMENTS WINDOW TUMBLING (SIZE 1 DAY) GROUP BY VARIATION_STATUS; +------------+-------------+--------+----------+------+-------+ | Date | Variation | Arriva | East Mid | LNER | TPE | +------------+-------------+--------+----------+------+-------+ | 2019-07-02 | OFF ROUTE | 46 | 78 | 20 | 167 | | 2019-07-02 | ON TIME | 19083 | 3568 | 1509 | 2916 | | 2019-07-02 | LATE | 30850 | 7953 | 5420 | 9042 | | 2019-07-02 | EARLY | 11478 | 3518 | 1349 | 2096 | | 2019-07-03 | OFF ROUTE | 79 | 25 | 41 | 213 | | 2019-07-03 | ON TIME | 19512 | 4247 | 1915 | 2936 | | 2019-07-03 | LATE | 37357 | 8258 | 5342 | 11016 | | 2019-07-03 | EARLY | 11825 | 4574 | 1888 | 2094 |
The result of this query can be stored in a Kafka topic, and from there made available to any application or datastore that needs it—all without persisting the data anywhere other than in Kafka, where it is already persisted.
Along with using Postgres (or KSQL as shown above) for analytics, the data can be streamed using Kafka Connect into S3, from where it can serve multiple roles. In S3, it can be seen as the “cold storage”, or the data lake, against which as-yet-unknown applications and processes may be run. It can also be used for answering analytical queries through a layer such as Amazon Athena.
Alerting
One of the great things about an event streaming platform is that it can serve multiple purposes. Reacting to events as they happen is one of the keys to responsive applications and happy users. Such event-driven applications differ from the standard way of doing things, because they are—as the name says—driven by events, rather than intermittently polling for them with the associated latency.
Let’s relate this directly to the data at hand. If we want to know about something happening on the train network, we generally want to know sooner than later. Taking the old approach, we would decide to poll a datastore periodically to see if there was data matching the given condition. This is relatively high in latency and has negative performance implications for the datastore. Consider now an event-driven model. We know the condition that we’re looking for, and we simply subscribe to events that match it.
The wonderful thing about events is that they are two things: notification that something happened and state describing what happened. So we’re not getting a notification to go and fetch information from somewhere else; we’re getting a notification along with the state itself that we need.
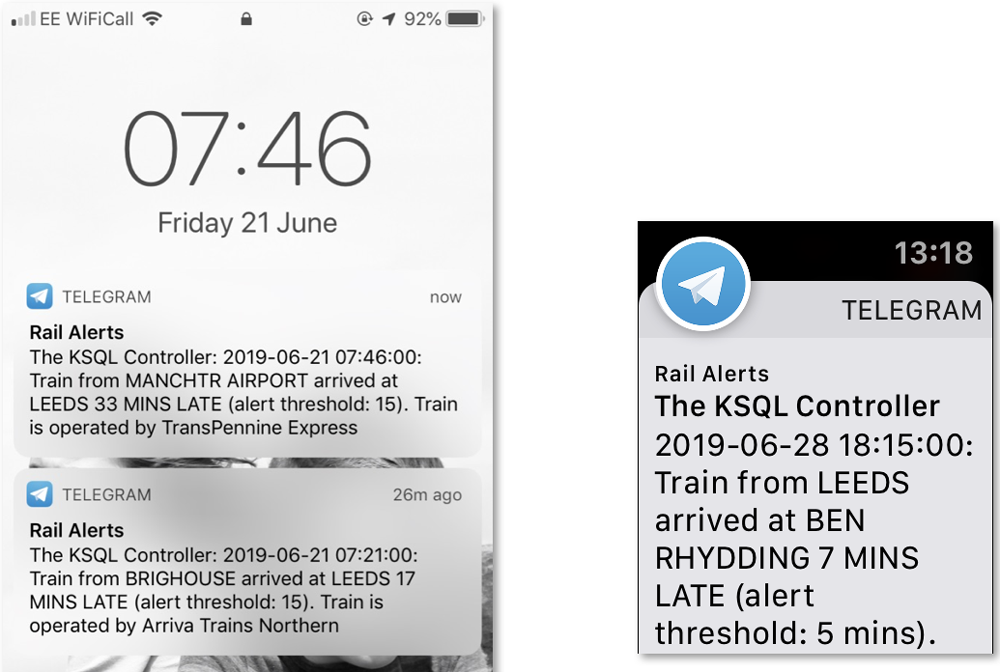
In this example, one of the things we’d like to alert on is when a train arrives at a given station over a certain number of minutes late. Perhaps we’re monitoring service levels at a particular station. The notifications are pushed out directly to the user. To implement this is actually very straightforward using Confluent Platform.
The conditions are stored in a compacted Kafka topic using the station name as a key and the threshold as a value. That way, different thresholds can be set for different stations. This Kafka topic is then modelled as a table in KSQL and joined to the live stream of movement data. Any train arriving at one of the stations in the configuration topic will satisfy the join, causing a new row to be written to the target topic. This is therefore a topic of all alert events and can be used as any other Kafka topic would be used.

We subscribe to the alert topic using Kafka Connect, which takes messages as they arrive on the topic and pushes them to the user, in this case using the REST API and Telegram.
The platform in detail
Let’s now take a look at each stage of implementation in detail.
Ingest
All of the data comes from Network Rail. It’s ingested using a combination of Kafka Connect and CLI producer tools.
The live stream of train data comes in from an ActiveMQ endpoint. Using Kafka Connect, the ActiveMQ connector, and externally stored credentials, stream the messages into Kafka for a selection of train companies:
curl -X PUT -H "Accept:application/json" \ -H "Content-Type:application/json" \ http://localhost:8083/connectors/source-activemq-networkrail-TRAIN_MVT_EA_TOC-01/config \ -d '{ "connector.class": "io.confluent.connect.activemq.ActiveMQSourceConnector", "activemq.url": "tcp://datafeeds.networkrail.co.uk:61619", "activemq.username": "${file:/data/credentials.properties:NROD_USERNAME}", "activemq.password": "${file:/data/credentials.properties:NROD_PASSWORD}", "jms.destination.type": "topic", "jms.destination.name": "TRAIN_MVT_EA_TOC", "kafka.topic": "networkrail_TRAIN_MVT", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "key.converter.schemas.enable": "false", "confluent.license": "", "confluent.topic.bootstrap.servers": "kafka:29092", "confluent.topic.replication.factor": 1 }'
The data is written to the .text field of the payload as a batch of up to 30 messages in escaped JSON form, which looks like this:
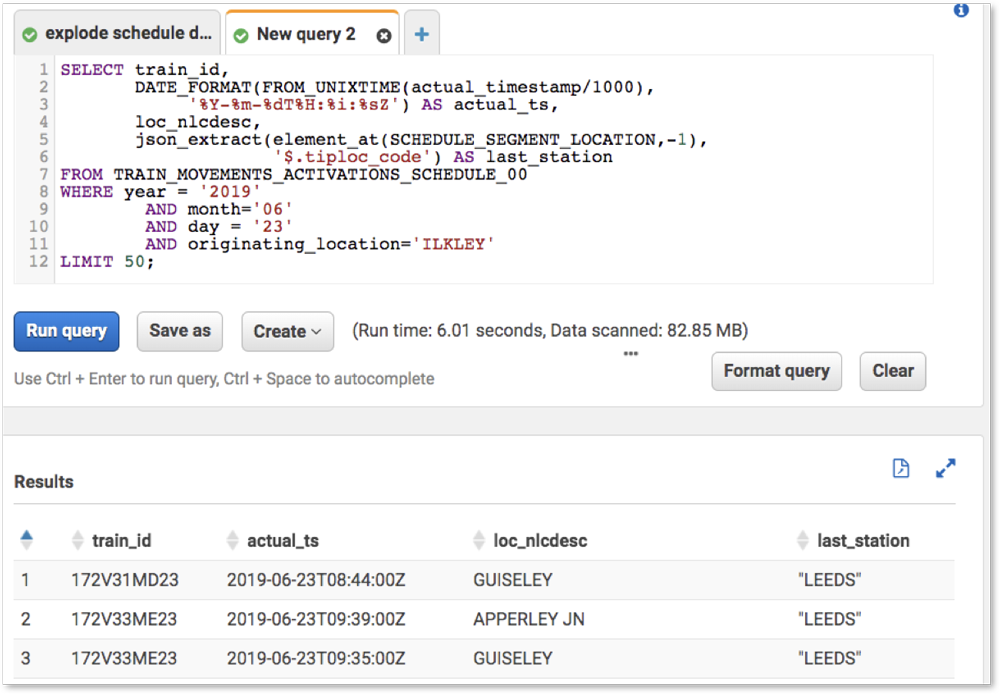
To make these into an actual stream of individual events, I use kafkacat and jq to parse the JSON payload and stream it into a new topic after exploding each batch of messages into individual ones:
kafkacat -b localhost:9092 -G tm_explode networkrail_TRAIN_MVT | \ jq -c '.text|fromjson[]' | \ kafkacat -b localhost:9092 -t networkrail_TRAIN_MVT_X -T -P
The resulting messages look like this:
The remaining data comes from an S3 bucket which has a REST endpoint, so we pull that in using curl and again kafkacat:
curl -s -L -u "$NROD_USERNAME:$NROD_PASSWORD" "https://datafeeds.networkrail.co.uk/ntrod/CifFileAuthenticate?type=CIF_EA_TOC_FULL_DAILY&day=toc-full" | \ gunzip | \ kafkacat -b localhost -P -t CIF_FULL_DAILY
There’s also some static reference data that is published on web pages. After scraping these manually, they’re produced directly into a Kafka topic:
kafkacat -b localhost:9092 -t canx_reason_code -P -K: <
Data wrangling with stream processing
With the reference data loaded and the live stream of events ingesting continually through Kafka Connect, we can now look at the central part of the data pipeline in which the data is passed through a series of transformations and written back into Kafka. These transformations make the data usable for both applications and analytics which subscribe to the Kafka topics populated.
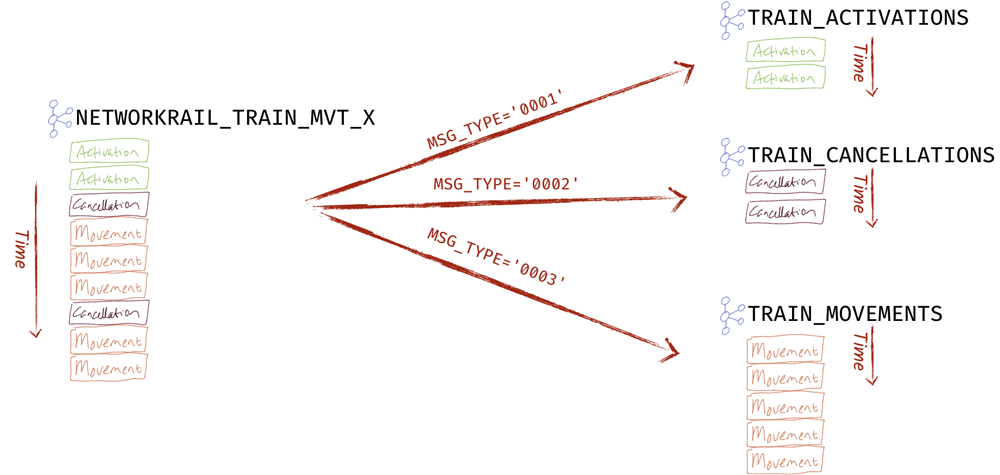
Splitting one stream into many
Several of the sources include multiple types of data on a single stream, such as the data from ActiveMQ, which includes Movement and Cancellation message types all on the same topic. Each is identifiable through the value of MSG_TYPE.
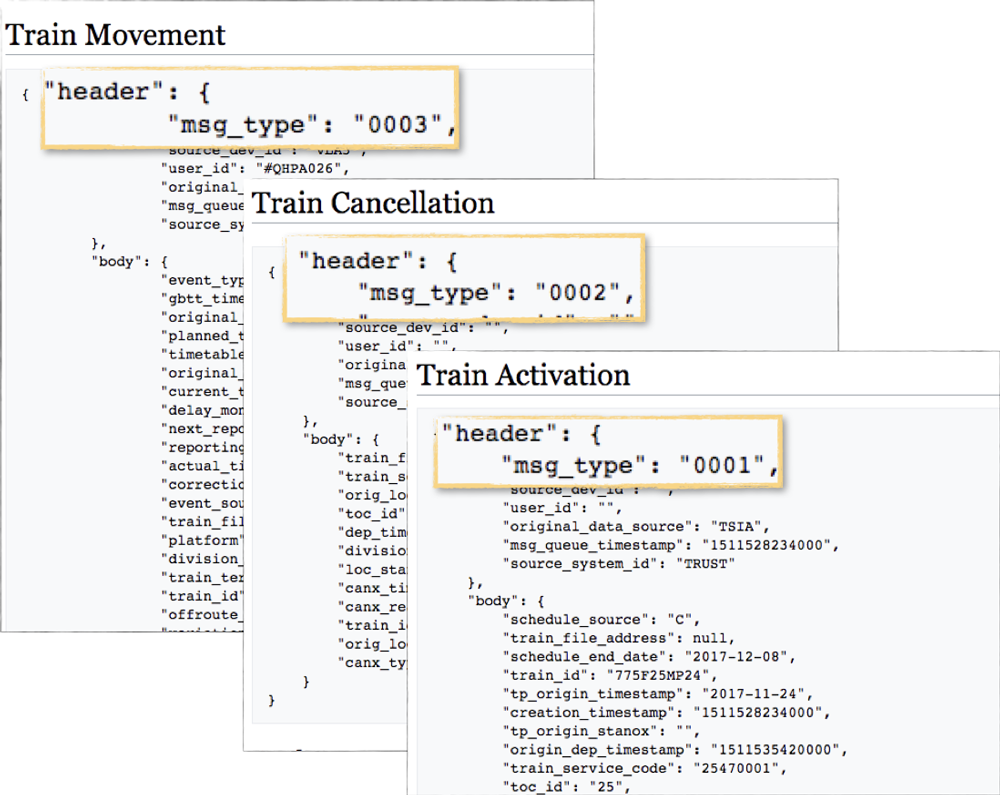
Using KSQL, we can simply read every message as it arrives and route it to the appropriate topic:
CREATE STREAM ACTIVATIONS AS SELECT * FROM SOURCE WHERE MSG_TYPE='0001';
CREATE STREAM MOVEMENTS AS SELECT * FROM SOURCE WHERE MSG_TYPE='0003';
CREATE STREAM CANCELLATIONS AS SELECT * FROM SOURCE WHERE MSG_TYPE='0002';
Schema derivation and Avro reserialisation
All of the data we’re working with here has a schema, and one of the first steps in the pipeline is to reserialise the data from JSON (no declared schema) to Avro (declared schema). Aside from Avro’s smaller message sizes, the key benefit is that we don’t have to declare the schema in subsequent queries and derivations against Kafka topics.
At the beginning of the pipeline, declare the schema once against the JSON data:
CREATE STREAM SCHEDULE_RAW (
TiplocV1 STRUCT)
WITH (KAFKA_TOPIC='CIF_FULL_DAILY',
VALUE_FORMAT='JSON');
We then reserialise it to Avro using the WITH (VALUE_FORMAT='AVRO') syntax whilst selecting just the data types appropriate for the entity:
CREATE STREAM TIPLOC
WITH (VALUE_FORMAT='AVRO') AS
SELECT *
FROM SCHEDULE_RAW
WHERE TiplocV1 IS NOT NULL;
We can also manipulate the schema, flattening it by selecting nested elements directly:
CREATE STREAM TIPLOC_FLAT_KEYED AS
SELECT TiplocV1->TRANSACTION_TYPE AS TRANSACTION_TYPE ,
TiplocV1->TIPLOC_CODE AS TIPLOC_CODE ,
TiplocV1->NALCO AS NALCO ,
TiplocV1->STANOX AS STANOX ,
TiplocV1->CRS_CODE AS CRS_CODE ,
TiplocV1->DESCRIPTION AS DESCRIPTION ,
TiplocV1->TPS_DESCRIPTION AS TPS_DESCRIPTION
FROM TIPLOC;
The two strategies (reserialise to Avro and flatten schema) can be applied in the same query, but they’re just shown separately here for clarity. While it can flatten a declared STRUCT column, KSQL can also take a VARCHAR with JSON content and extract just particular columns from it. This is very useful if you don’t want to declare every column upfront or have more complex JSON structures to work with, from which you only want a few columns:
CREATE STREAM SCHEDULE_00 AS SELECT extractjsonfield(schedule_segment->schedule_location[0],'$.tiploc_code') as ORIGIN_TIPLOC_CODE, […] FROM JsonScheduleV1;
Deriving and setting the message key and partitioning strategy
The key on a Kafka message is important for two reasons:
- Partitioning is a crucial part of the design because partitions are the unit of parallelism. The greater the number of partitions, the more you can parallelise your processing. The message key is used to define the partition in which the data is stored, so all data that should be logically processed together, in order, needs to be located in the same partition and thus have the same message key.
- Joins between streams and tables rely on message keys. The key is used to route the partitions inside different streams and tables to the right machine so that distributed join operations can be performed.
The data at point of ingest has no key, so we can easily use KSQL to set one. In some cases, we can just use an existing column:
CREATE STREAM LOCATION_KEYED AS SELECT * FROM LOCATION PARTITION BY LOCATION_ID;
In other cases, we need to derive the key first as a composite of more than one existing column. An example of this is in the schedule data, which needs to be joined to activation data (and through that to movement) on three columns, which we generate as a key as shown below. In the same statement, we’re declaring four partitions for the target topic:
CREATE STREAM SCHEDULE_00 WITH (PARTITIONS=4) AS
SELECT CIF_train_uid,
schedule_start_date,
CIF_stp_indicator,
CIF_train_uid + '/' + schedule_start_date + '/' + CIF_stp_indicator AS SCHEDULE_KEY,
atoc_code,
[…]
FROM JsonScheduleV1
PARTITION BY SCHEDULE_KEY;
Enriching data with joins and lookups
Much of the data in the primary event stream of train movements and cancellations is in the form of foreign keys that need to be resolved out to other sources in order to be understood. Take location, for example: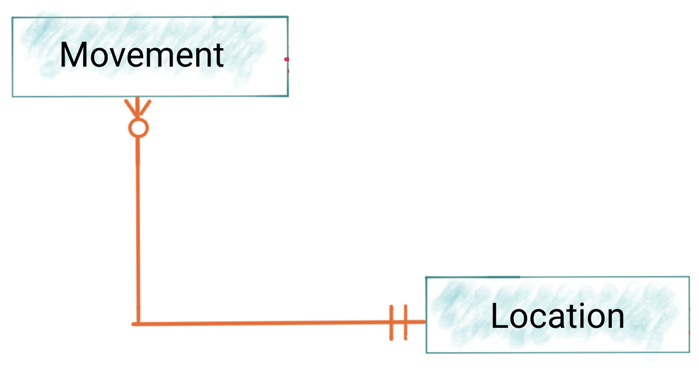
A record may look like this:
{
"event_type": "ARRIVAL",
"actual_timestamp": "1567772640000"
"train_id": "161Y82MG06"
"variation_status": "LATE"
"loc_stanox": "54311"
}
We want to resolve the location code (loc_stanox), and we can do so using the location reference data from the CIF data ingested into a separate Kafka topic and modelled as a KSQL table:
SELECT EVENT_TYPE,
ACTUAL_TIMESTAMP,
LOC_STANOX,
S.TPS_DESCRIPTION AS LOCATION_DESCRIPTION
FROM TRAIN_MOVEMENTS_00 TM
LEFT OUTER JOIN STANOX S
ON TM.LOC_STANOX = S.STANOX;
+------------+-----------------+------------+---------------------+
|EVENT_TYPE |ACTUAL_TIMESTAMP |LOC_STANOX |LOCATION_DESCRIPTION |
+------------+-----------------+------------+---------------------+
|ARRIVAL |1567772640000 |54311 |LONDON KINGS CROSS |
More complex joins can also be resolved by daisy-chaining queries and streams together. This is useful for resolving the relationship between a train’s movement and the originating schedule, which gives us lots of information about the train (power type, seating data, etc.) and route (planned stops, final destination, etc.).

To start with we need to join movements to activations:
CREATE STREAM TRAIN_MOVEMENTS_ACTIVATIONS_00 AS
SELECT *
FROM TRAIN_MOVEMENTS_01 TM
LEFT JOIN
TRAIN_ACTIVATIONS_01_T TA
ON TM.TRAIN_ID = TA.TRAIN_ID;
Having done that we can then join the resulting stream to the schedule:
CREATE STREAM TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00 AS
SELECT *
FROM TRAIN_MOVEMENTS_ACTIVATIONS_00 TMA
LEFT JOIN
SCHEDULE_02_T S
ON TMA.SCHEDULE_KEY = S.SCHEDULE_KEY;
Column value enrichment
As well as joining to other topics in Kafka, KSQL can use the powerful CASE statement in several ways to help with data enrichment. Perhaps you want to resolve a code used in the event stream but it’s a value that will never change (famous last words in any data model!), and so you want to hard code it:
SELECT CASE WHEN TOC_ID = '20' THEN 'TransPennine Express' WHEN TOC_ID = '23' THEN 'Arriva Trains Northern' WHEN TOC_ID = '28' THEN 'East Midlands Trains' WHEN TOC_ID = '61' THEN 'London North Eastern Railway' ELSE '<unknown TOC code: ` + TOC_ID + '>' END AS TOC, […] FROM TRAIN_MOVEMENTS_00
What if you want to prefix a column with some fixed text when it has a value, but leave it blank when it doesn’t?
SELECT CASE WHEN LEN( PLATFORM)> 0 THEN 'Platform' + PLATFORM ELSE '' END AS PLATFORM, […] FROM TRAIN_MOVEMENTS_00
Or maybe you want to concatenate the value of another column conditionally based on another:
SELECT CASE WHEN VARIATION_STATUS = 'ON TIME' THEN 'ON TIME'
WHEN VARIATION_STATUS = 'LATE' THEN TM.TIMETABLE_VARIATION + ' MINS LATE'
WHEN VARIATION_STATUS='EARLY' THEN TM.TIMETABLE_VARIATION + ' MINS EARLY'
END AS VARIATION ,
[…]
FROM TRAIN_MOVEMENTS_00 TM
Handling time
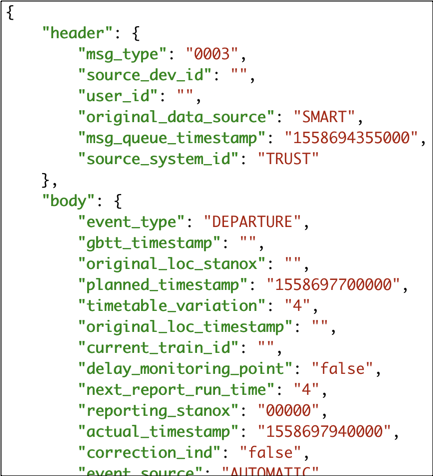
One of the most important elements to capture in any event streaming system is when different things actually happen. What time did a train arrive at the station? If it was cancelled, when was it cancelled? Other than simply ensuring accuracy in reporting the individual events, time becomes really important when we start aggregating and filtering on it. If we want to know how many trains a given operating company cancelled each hour, it’s no use simply counting the cancellation messages received in that hour. That would just be telling us how many cancellation messages we received in the hour, which might be interesting but doesn’t answer the question asked. Instead of using system time, we want to work with event time. Each message has several timestamps in it and can tell KSQL to use the appropriate one. Here’s an example cancellation message:
{
"header": {
"msg_type": "0002",
"source_dev_id": "V2PY",
"user_id": "#QRP4246",
"original_data_source": "SDR",
"msg_queue_timestamp": "1568048168000",
"source_system_id": "TRUST"
},
"body": {
"train_file_address": null,
"train_service_code": "12974820",
"orig_loc_stanox": "",
"toc_id": "23",
"dep_timestamp": "1568034360000",
"division_code": "23",
"loc_stanox": "43211",
"canx_timestamp": "1568051760000",
"canx_reason_code": "YI",
"train_id": "435Z851M09",
"orig_loc_timestamp": "",
"canx_type": "AT ORIGIN"
}
}
There are four timestamps, each with different meanings. Along with the timestamps in the message payload, there’s also the timestamp of the Kafka message. We want to tell KSQL to process the data based on the canx_timestamp field, which is when the cancellation was entered into the source system (and thus our closest field for event time):
CREATE STREAM TRAIN_CANCELLATIONS_01 WITH (TIMESTAMP='CANX_TIMESTAMP') AS SELECT * FROM TRAIN_CANCELLATIONS_00 ;
Data sinks
Kafka Connect is used to stream the data from the enriched topics through to the target systems:
- Elasticsearch
- Amazon S3 (Google Cloud Storage and Azure Blob Storage connectors are also available)
- Postgres (the JDBC sink supports any other RDBMS too)
- Neo4j
Because the enriched data is persisted in Kafka, it can be reloaded to any target as required as well as streamed to additional ones at a future date.
One of the benefits of using Elasticsearch is it can serve the kind of interactive dashboards through Kibana, as shown above. Another benefit is that it has data profiling tools. These are useful for understanding the data during iterations of pipeline development:
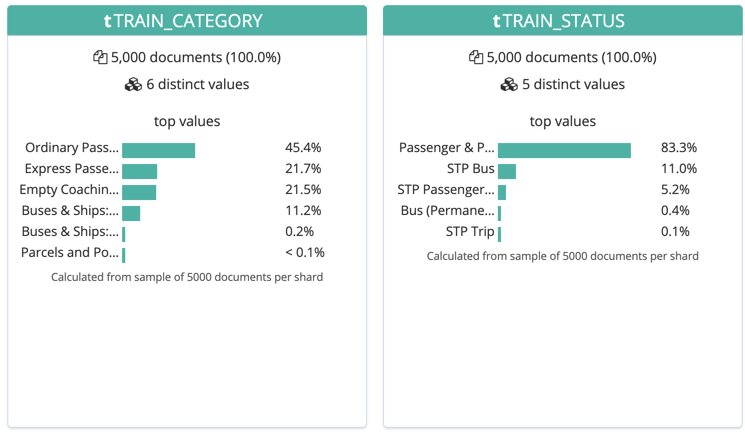
Fast track to streaming ETL
This article has shown how Apache Kafka as part of Confluent Platform can be used to build a powerful data system. Events are ingested from an external system, enriched with other data, transformed, and used to drive both analytics and real-time notification applications.
If you want to try out the code shown in this article, you can find it on GitHub and download the Confluent Platform to get started.
You can also watch a YouTube recording of my presentation on this topic.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents With Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


