[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Announcing ksqlDB 0.17.0
We’re excited to announce ksqlDB 0.17, a big release for 2021. This version adds support for managing the lifecycle of your queries from CI servers, a first-class timestamp data type, inline functions, extended expressivity for pull queries, materialization support for more kinds of data, and much more. We’ll walk through the most substantial changes in detail, but you can refer to the changelog for a thorough list of features and fixes. If you’re ready to get started, check out Confluent Cloud, which will quickly get you set up with the latest release of ksqlDB.
Version control ksqlDB with CI/CD
A common method of maintaining database schemas over time is to use migrations. Each time you want to make a change to your database, you write a SQL script for it (a migration). If you ever want to see what an old version of the database looks like, you can find the exact commands used to create that version of the database by finding all of the migrations that are older than that version.
ksqlDB 0.17 ships with a new tool for managing migrations, which can be used to version-control a ksqlDB schema, recreate schemas from scratch, and be part of a CI/CD system.
Let’s take a look at what working with this tool would look like.
First, let’s create a table of users. We can make a file called V000001__create_users_table.sql with the following command in it:
CREATE TABLE users ( name STRING, registration_date TIMESTAMP ) WITH ( kafka_topic=’users’, value_format=’json’ );
We run this file by running ksql-migrations apply -a --config-file <path-to-migrations-config>.
Now suppose we want to add a column called userid to the table. We would make a second file called V000002__add_userid_column.sql with the following content:
ALTER TABLE users ADD COLUMN userid STRING;
Running ksql-migrations apply -a --config-file <path-to-migrations-config> would find that V000002__add_userid_column.sql is pending and apply it.
If we run ksql-migrations info --config-file <path-to-migrations-config>, we can see information such as when each file was applied and if any errors occurred.
-------------------------------------------------------------------------------------------------------------------------------------- Version | Name | State | Previous Version | Started On | Completed On | Error Reason -------------------------------------------------------------------------------------------------------------------------------------- 1 | create users table | MIGRATED | <none> | 2021-04-07 12:18:39.080 PDT | 2021-04-07 12:18:39.446 PDT | N/A 2 | add userid column | MIGRATED | 1 | 2021-04-08 13:27:02.210 PDT | 2021-04-08 13:27:02.404 PDT | N/A -------------------------------------------------------------------------------------------------------------------------------------
A similar workflow can be used in a CI/CD pipeline. If we include our migrations folder to a Git project, then the command ksql-migrations apply -a --config-file <path-to-migrations-config> can be included as a step in a Github Actions or Jenkins workflow, and whenever changes are pushed to Git, any new migration files are applied. This way, any changes made to ksqlDB would line up perfectly with changes to other application source code.
For more information, read the documentation or keep an eye out for an upcoming blog post that will take a deeper dive into this tool.
Represent time data using the TIMESTAMP data type
Up until now, you’ve had to represent time data either as BIGINT or as STRING. ksqlDB 0.17 includes a new timestamp data type, as well as several functions to manipulate time data such as FORMAT_TIMESTAMP, PARSE_TIMESTAMP, and CONVERT_TZ.
Check out the new tutorial, Timezone Conversion and Kafka Connect JDBC Sink, which demonstrates how to use the TIMESTAMP data type, convert timestamp data into different time zones, and sync that data into a Postgres database.
CREATE STREAM TEMPERATURE_READINGS_TIMESTAMP_MT AS SELECT TEMPERATURE, CONVERT_TZ(FROM_UNIXTIME(EVENTTIME), 'UTC', 'America/Denver') AS EVENTTIME_MT FROM TEMPERATURE_READINGS_RAW;
Apply simple inline functions through lambda functions
In the past, if you wanted to transform data in a way that built-in functions did not support, you had to write a user-defined function (UDF), which may have combined other built-in functions. With the 0.17 release, ksqlDB can do this for you, allowing you to create simple inline functions that can be applied to structured data using only SQL. These composite functions are called lambda functions.
You can use lambda functions through three supported functions: transform, filter, and reduce. Consider the following stream:
CREATE STREAM test (ID STRING KEY, numbers ARRAY)<INTEGER> WITH (kafka_topic='test_topic', value_format='JSON');
We can use lambda functions to transform, filter, and reduce the numbers array field in our stream:
CREATE STREAM transformed AS SELECT ID, transform(numbers, x => x * 5) FROM test; CREATE STREAM filtered AS SELECT ID, filter(numbers, x => x > 5) FROM test; CREATE STREAM reduced AS SELECT ID, reduce(numbers, 2, (s, x) => s + x) FROM test;
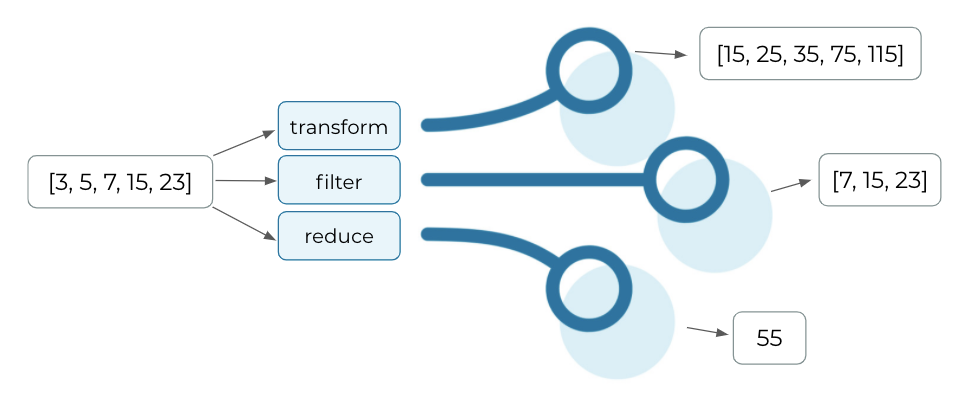
Table scans in pull queries
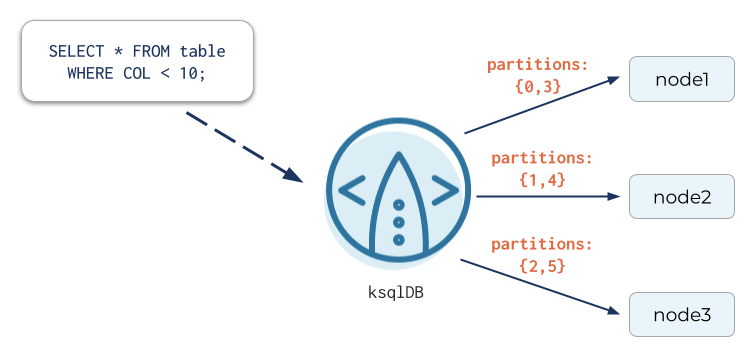
ksqlDB’s pull queries allow you to fetch the current state of a materialized view. Until now, pull queries have been limited to lookups using key equality comparisons in the WHERE clause that leverage the form KEY = 10 or KEY IN (10, 11, 12). Although these can be done very efficiently, they don’t allow for the flexibility that’s often needed. We’ve now expanded support for table scans to allow most types of operations in the WHERE clause, including:
- Key range queries (e.g., KEY < 10)
- Non-key comparisons (e.g., COL = 'item_type' or COL > 10.5)
- Complex comparison expressions (e.g., BUCKET % 100 < 15 or SQRT(KEY) * 3 > 5)
- Complex logical expressions (e.g., KEY IN (1, 2, 3) AND (AVG_STARS < 3 OR AVG_RATING < 2100))
A table scan is a heavier-weight operation. With larger tables, table scans can take resources from running persistent queries, so we encourage you to understand your workload before using the feature.
Table scans are not enabled by default. They can be turned on for pull queries run in the current CLI session with the command SET 'ksql.query.pull.table.scan.enabled'='true'; or for individual pull queries run in the Confluent Cloud UI by setting the equivalent query property. They can also be enabled by default by setting a server configuration property with ksql.query.pull.table.scan.enabled=true.
Scan-based queries are just the next incremental step for ksqlDB pull queries. In future releases, we will continue pushing the envelope of new query capabilities and greater performance and efficiency.
Pull queries on more tables
Previously, you could only execute pull queries over tables aggregated using an aggregation function like LATEST_BY_OFFSET(). You can now execute pull queries on any derived table created using the CREATE TABLE AS SELECT statement. Suppose you have the derived table:
CREATE TABLE TOP_RANKS AS SELECT ID, GRADE, RANK FROM STUDENTS WHERE RANK < 10;
You can now issue various types of pull queries against TOP_RANKS. You can then scan the entire table by issuing SELECT * FROM TOP_RANKS; or look up a single entry with SELECT * FROM TOP_RANKS WHERE ID = 14;.
Note: We currently don’t support pull queries on tables derived from table-table joins. This support will be introduced in a future release.
Get started with ksqlDB
ksqlDB 0.17.0 includes long-anticipated features, such as a migration tool, a timestamp data type, inline lambda functions, and pull queries on tables. Refer to the changelog for a full list of changes.
If you are already running ksqlDB on Confluent, your application will be automatically upgraded to version 0.17.0 in the near future. To check your ksqlDB server version, navigate to your ksqlDB app in the Confluent UI. Then, click the “Settings” tab to display app metadata, including the running version.
Just getting started? Try ksqlDB today through the standalone distribution or with Confluent, and make sure to join the Confluent Community Forum to get involved.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.