[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
What Is a Data Streaming Platform (DSP)?
A data streaming platform (DSP) enables organizations to capture, store, and process data as a continuous flow of real time events. By leveraging event-driven architectures powered by foundational technologies like Apache Kafka® and Apache Flink®, a data streaming platform allows businesses to unlock real-time insights, build responsive applications, and connect diverse systems with unprecedented agility. With integrated tools for governance, schema management, and self-service access, a data streaming platform simplifies complex data architectures and enables teams to deliver real-time value from data streams.
Overview
Businesses face an explosion of data as they scale rapidly to meet the real-time needs of customers. Traditional batch-processing systems and complex, point-to-point integrations can no longer keep up. This is where a data streaming platform comes in—providing the means to manage, process, and act on data as it’s generated in real time.
Data streaming platforms are built on robust technologies like Apache Kafka® and Apache Flink®, enabling organizations to build event-driven architectures. Apache Kafka acts as the backbone for reliable, scalable data streaming, allowing businesses to capture and transmit events in real time while ensuring data durability and accessibility. Apache Flink completes this framework by offering advanced stream processing capabilities to transform, enrich, and analyze data streams in motion.
Additionally, modern data streaming platforms include advanced governance tools, providing self-service data catalogs for end users, stream lineage, and schema validation for consistent and reliable data management across teams and stakeholders.
Why Adopt a Data Streaming Platform?
Challenges of Early Data Streaming
In the early days of data streaming, platforms struggled to meet the evolving needs of enterprises. Data streams were often ephemeral with no ability to store or reuse historical data, as early streaming systems were not designed to handle enterprise-scale demands. Lacking proper schema enforcement and governance, early streaming solutions resulted in inefficiencies and tightly coupled architectures, making it difficult to scale and adapt. These shortcomings, combined with operational complexity, made early data streaming costly and impractical for widespread enterprise use.
Apache Kafka was a big leap forward, providing durability, replayability, and enterprise scalability. But it remains labor-intensive to operate and maintain, requiring dedicated teams to handle scaling, fault-tolerance, upgrading, security, and monitoring.
Advantages of a Modern Data Streaming Platform
Today’s data streaming platforms address these shortcomings with an ecosystem of enterprise-ready features and tools. They enable teams to:
- Simplify and unify architectures by connecting data across diverse systems, applications, and sources.
- Improve operational efficiency by eliminating custom messaging systems and disparate integrations.
- Leverage real-time data processing with tools like Flink to enrich, aggregate, and analyze data on the fly.
- Accelerate data integration with seamless integration between operational and analytical systems.
Modern data streaming platforms also help enterprises eliminate decades of tech debt by offering centralized schema management, robust data quality enforcement, and comprehensive governance—all while scaling effortlessly to meet evolving business demands and power critical use cases.
Technical Benefits of a Data Streaming Platform
Enterprise-Grade Data Streaming
Modern data streaming platforms reimagine and elevate Kafka by offering a fully managed, scalable infrastructure with built-in monitoring, fault tolerance, and multicloud support. This ensures businesses can focus on building and deploying data-driven applications rather than managing Kafka operations.
Seamless Data Connections
A data streaming platform helps break down data silos by facilitating connections to a vast ecosystem of data sources and sinks, including databases, cloud services, and applications. Managed Kafka connectors streamline data ingestion and delivery, ensuring fast and reliable data movement across systems.
In-Stream Processing
With tools like Apache Flink, a data streaming platform enables real-time data enrichment, aggregations, and transformations. This allows organizations to extract actionable insights from their data in near real time, powering advanced analytics as data flows through the platform.
Enhanced Governance
Built-in features like schema registries, stream lineage, and access controls provide complete visibility and control over data. Teams and stakeholders can enforce data quality standards, maintain compatibility across evolving schemas, and ensure data streams are secure and discoverable.
How Confluent's Data Streaming Platform Works
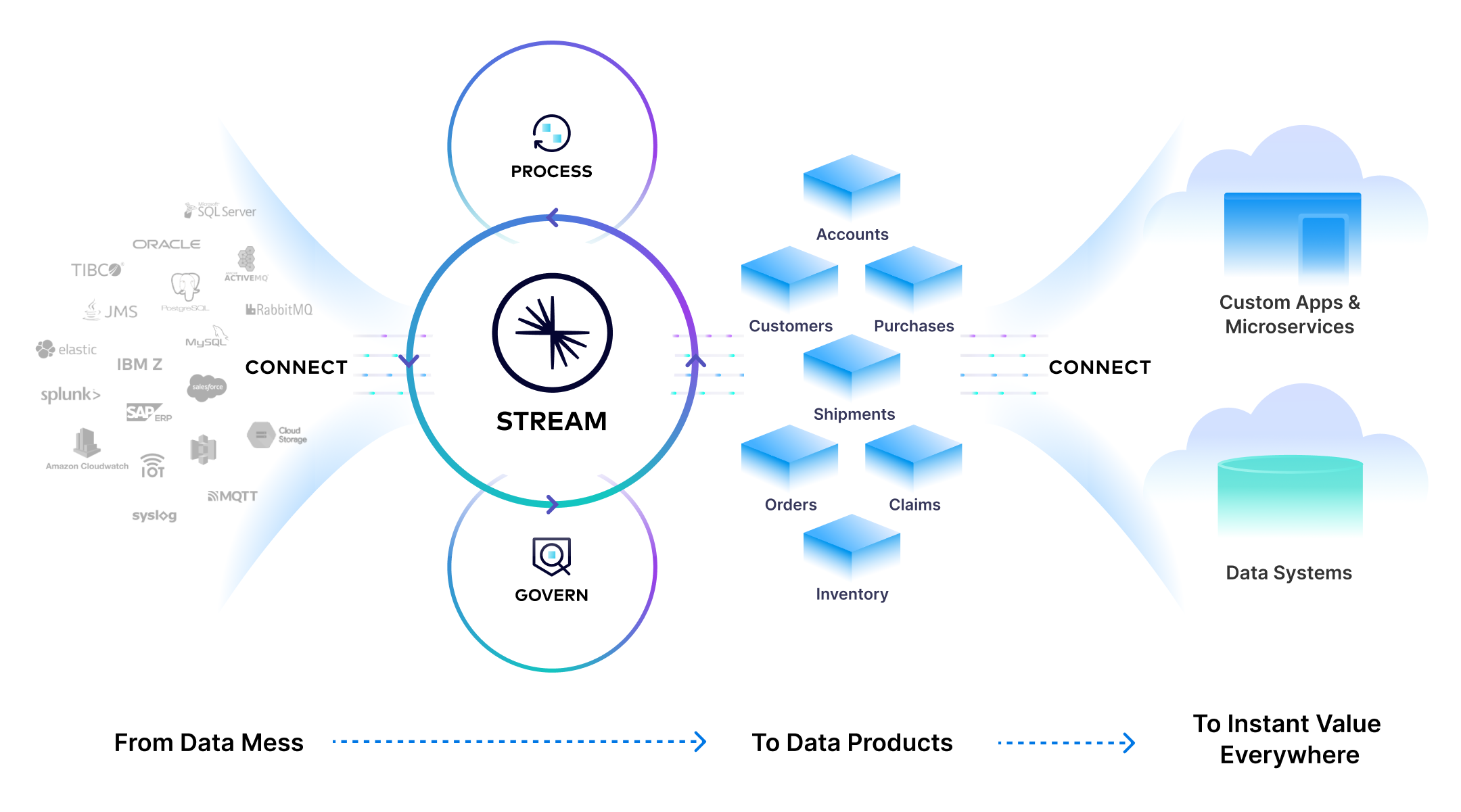
Modern data streaming platforms, like Confluent’s cloud-native, fully managed data streaming platform, are powered by six interconnected components that simplify the creation, management, and consumption of real-time data streams. Together, they enable businesses to capture and use event-driven data with ease and efficiency. The six core components of a data streaming platform include:
1. Real-Time Data Streaming
The ability to stream data from multiple sources in real time is the core function of a data streaming platform. Apache Kafka, the most widely adopted event streaming technology, forms the foundation for Confluent’s DSP. Kafka powers real-time data capture, storage, and transmission with high throughput and fault tolerance. Kafka’s distributed architecture allows for scalable performance, ensuring businesses can handle massive volumes of data reliably. Confluent’s fully managed data streaming platform enhances Kafka with features like tiered storage for infinite retention, multi-cloud replication, and enterprise-grade monitoring, making it a robust solution for large-scale streaming needs.
2. Schema Registry and Data Quality
The Schema Registry ensures data consistency and compatibility by validating schemas for all streams. It supports schema evolution, enabling updates without disrupting producers or consumers, and ensures that data remains trustworthy across the organization. By centralizing schema management, it eliminates errors caused by mismatched data formats and accelerates development.
3. Data Portal
The Data Portal provides a self-service interface for discovering and managing data streams. It offers stream discovery, lineage tracking, and access controls, making it easy for teams to find, understand, and use the right data. By empowering teams with easy access to data streams, the data portal, combined with Schema Registry, accelerates the development of data products—the reusable data assets that power operational systems and analytical computations across the business.
4. Kafka Connectors
Kafka Connectors simplify the integration of external systems with Kafka. Confluent offers over 120 pre-built connectors, enabling seamless data movement between sources like databases or SaaS applications and destinations such as analytics tools or cloud storage. These connectors eliminate the need for custom coded integrations, saving development teams time, effort, and cost while ensuring high reliability and performance.
5. Apache Flink
Apache Flink powers advanced stream processing capabilities, powering both applications and data pipelines. It enables businesses to transform events in real-time, materialize them to tables, join them together, and build aggregations (or choose from a wide range of processing options). Flink can also read and process data directly from Apache Iceberg™ tables in both batch and streaming modes.
6. Tableflow
Tableflow is a fully managed Kafka-topic-to-Iceberg-table converter tool that bridges the gap between real-time and batch systems. By converting Kafka topics into Iceberg-compatible, append-only tables, teams are able to combine real-time and historical data for analysis, query streams using familiar SQL-based tools, and automate schema updates for reduced operational complexity.
Bringing It All Together
These six components work in harmony to transform raw event data into actionable insights. Confluent’s data streaming platform simplifies architectures, integrates seamlessly with existing systems, and enables businesses to build scalable, real-time data pipelines that unlock the full potential of event-driven data.
Data Streaming Platform Use Cases
Modern data streaming platforms enable a variety of high-impact business use cases across various industries. Here are a few examples:
In financial services, a data streaming platform can unify disparate data sources to create real-time data products that power personalized customer insights, fraud detection, and risk management. By connecting data from multiple systems in real time, businesses can ensure they have accurate, consistent, and actionable data available instantly across their organization, enhancing decision-making and operational efficiency.
In healthcare, a data streaming platform can shift data processing left by enabling real-time updates to patient records and appointment systems. By transforming and curating data as it’s created, healthcare providers can ensure that clinicians have access to the freshest and most accurate patient data, improving patient outcomes and operational workflows while reducing the need for downstream data wrangling.
In media and entertainment, data streaming platforms support GenAI use cases by enabling real-time personalization for content recommendations. By leveraging a data streaming platform to continuously process and analyze user interactions, businesses can dynamically adjust content recommendations, instantly serving relevant media based on user preferences and behavior patterns. This enhances engagement and customer satisfaction.