[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Was ist Apache Flink?
Apache Flink ist ein Open-Source-Framework zur Datenverarbeitung mit einzigartigen Funktionen sowohl bei der Stream-Verarbeitung als auch bei der Batch-Verarbeitung. Flink ist ein beliebtes Tool zur Entwicklung leistungsstarker, skalierbarer und Event-getriebener Anwendungen und Architekturen.
Hochwertige, wiederverwendbare Datenströme können mit der branchenweit einzigen vollständig verwalteten, Cloud-nativen Apache Flink® + Kafka-as-a-Service-Lösung mühelos erstellt werden, um umfassendes Daten-Streaming und Analysen bereitzustellen.
Wie funktioniert Apache Flink?
Apache Flink ist ein Framework und eine verteilte Processing-Engine für die zustandsbehaftete Verarbeitung von unbegrenzten und begrenzten Datenströmen. Flink wurde so konzipiert, dass es in allen gängigen Cluster-Umgebungen ausgeführt werden kann und Berechnungen in jedem Umfang mit In-Memory-Geschwindigkeit ermöglicht. Entwickler können Anwendungen für Flink mit APIs wie Java oder SQL erstellen, die vom Framework auf einem Flink-Cluster ausgeführt werden.
Während andere beliebte Datenverarbeitungssysteme wie Apache Spark und Kafka Streams auf entweder Daten-Streaming oder Batch-Verarbeitung beschränkt sind, unterstützt Flink beides. Dies macht es zu einem vielseitigen Tool für Unternehmen in Branchen wie dem Finanzwesen, E-Commerce und der Telekommunikation, die dadurch sowohl Batch- als auch Stream-Verarbeitung auf einer einzigen Plattform durchführen können. Apache Flink kann für moderne Anwendungsfälle wie Betrugserkennung, personalisierte Empfehlungen, Börsenanalysen und maschinelles Lernen genutzt werden.
Architektur und Schlüsselkomponenten von Apache Flink
Bei Kafka Streams handelt es sich um eine Bibliothek, die als Teil der Anwendung ausgeführt wird. Flink hingegen ist eine eigenständige Engine zur Stream-Verarbeitung, die unabhängig eingesetzt wird. Anwendungen werden von Apache Flink in einem Flink-Cluster ausgeführt, der auf beliebige Weise bereitgestellt wird. Flink hilft dabei, die größten Herausforderungen verteilter Stream-Verarbeitungssysteme zu bewältigen, wie etwa Fehlertoleranz, Exactly-once-Delivery, hoher Durchsatz und Latenzzeiten. Diese Lösungen beinhalten Checkpoints, Savepoints, Zustandsverwaltung und Zeitsemantik.
Die Architektur von Flink ist sowohl für Stream- als auch für Batch-Verarbeitung konzipiert. Sie kann unbegrenzte Datenströme und begrenzte Datensätze verarbeiten, was die Datenverarbeitung und -analyse in Echtzeit ermöglicht. Außerdem stellt Flink die Datenintegrität und konsistente Snapshots sicher, selbst in komplexen Event-Verarbeitungs-Szenarien.
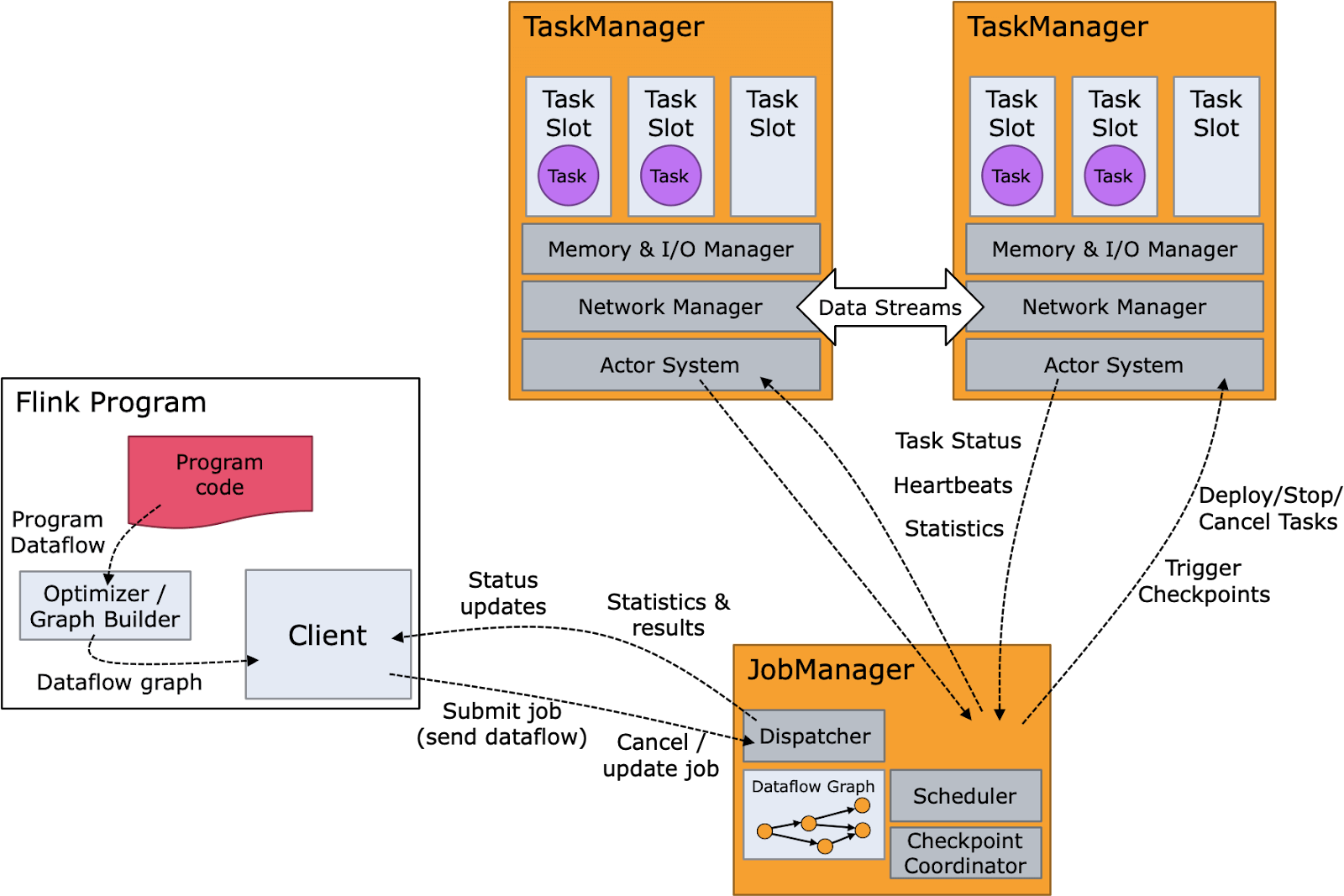
Das folgende Diagramm zeigt die Flink-Komponenten ebenso wie den Runtime-Flow von Flink. Der Programmcode oder die SQL-Abfrage wird in einen Operator-Graph geschrieben, der anschließend vom Client an einen Job-Manager gesendet wird. Der Job-Manager unterteilt den Auftrag in Operatoren, die als Tasks auf Knoten ausgeführt werden, auf denen Task-Manager laufen. Diese Tasks verarbeiten Streaming-Daten und interagieren mit verschiedenen Datenquellen, wie dem Hadoop Distributed File System (HDFS) und Apache Kafka.
Vorteile von Apache Flink
Apache Flink ist aufgrund seiner zuverlässigen Architektur und seines umfangreichen Feature-Sets eine beliebte Lösung. Zu den Features gehören ein hochentwickeltes Zustandsmanagement, Savepoints, Checkpoints, Semantik für Event-Time-Verarbeitung und die Gewährleistung der Exactly-Once-Consistency für die zustandsbezogene Verarbeitung.
Die zustandsbezogene Stream-Verarbeitung von Flink ermöglicht es Nutzern, verteilte Berechnungen von kontinuierlichen Datenströmen zu definieren. Dies ermöglicht komplexe Event-Processing-Analysen für Event-Steams wie etwa "Windowed Joins", Aggregationen und Pattern-Matching.
Flink kann sowohl begrenzte als auch unbegrenzte Streams verarbeiten und so die Batch- und Stream-Verarbeitung in einer Lösung vereinen. Dies ist besonders nützlich, wenn unterschiedliche Datenverarbeitungsanforderungen bestehen, wie bei Echtzeit-Streaming-Anwendungen, die eine Verarbeitung beider Datentypen erfordern.
Außerdem wurde Flink zur Ausführung zustandsbezogener Anwendungen in praktisch jedem Umfang entwickelt. Daten können parallelisiert in Tausenden von Tasks verarbeitet werden, die auf mehrere Maschinen verteilt sind, und große Datensätze effizient bewältigen. Dies macht es zur idealen Lösung für Anwendungen, die auf Tausende von Knoten skaliert werden müssen, bei minimaler Latenz und minimalem Durchsatz-Verlust.
Flink verfügt außerdem über mehrschichtige APIs zur Stream-Verarbeitung auf verschiedenen Abstraktionsebenen. Das gibt Entwicklern die nötige Flexibilität, um sowohl gängige als auch hochgradig spezialisierte Stream-Processing-Anwendungsfälle zu bewältigen.
Flink hat Connectors für Messaging- und Streaming-Systeme, Datenspeicher, Suchmaschinen und Dateisysteme wie Apache Kafka, OpenSearch, Elasticsearch, DynamoDB, HBase und jede Datenbank, die einen JDBC-Client bereitstellt.
Flink bietet außerdem verschiedene Programmierschnittstellen, darunter die High-Level Streaming SQL und Table-API, die Lower-Level DataStream-API und die ProcessFunction-API zur Feinsteuerung. Diese Flexibilität ermöglicht es Entwicklern, für jedes Problem das richtige Tool zu verwenden und unterstützt sowohl unbegrenzte Datenströme als auch begrenzte Datensätze.
Es werden außerdem mehrere Programmiersprachen unterstützt, darunter Java, Scala, Python und andere JVM-Sprachen wie Kotlin, was es zu einer beliebten Lösung bei Entwicklern macht.
Anwendungsfälle von Apache Flink
Obwohl Flink als generischer Datenprozessor entwickelt wurde, trug die native Unterstützung von unbeschränkten Streams zu seiner Beliebtheit als Stream-Prozessor bei. Die gängigen Anwendungsfälle von Flink sind den Kafka-Anwendungsfällen sehr ähnlich, obwohl Flink und Kafka etwas unterschiedliche Zwecke erfüllen. Kafka übernimmt in der Regel das Event-Streaming, während Flink zum Verarbeiten der Daten aus den Streams genutzt wird. Flink und Kafka werden häufig gemeinsam genutzt für:
-
Batch-Verarbeitung: Eine Stärke von Flink ist die Verarbeitung von begrenzten Datensätzen, wodurch es sich gut eignet für herkömmliche Batch-Verarbeitungsaufgaben mit endlichen Daten, die in Blöcken verarbeitet werden.
-
Stream-Verarbeitung: Flink ist für die Verarbeitung unbegrenzter Datenströme konzipiert. Dies ermöglicht eine kontinuierliche Datenverarbeitung in Echtzeit und ist daher ideal für Anwendungen, die Analysen und Monitoring in Echtzeit erfordern.
-
Event-getriebene Anwendungen: Die Fähigkeiten von Flink bei der Verarbeitung von Event-Streams machen es zu einem wertvollen Tool für die Erstellung von Event-getriebenen Anwendungen, wie Systeme zur Betrugs- und Anomalieerkennung, Kreditkartentransaktionen, Monitoring von Geschäftsprozessen usw.
-
Aktualisierung zustandsbezogener Anwendungen (Savepoints): Die Zustandsbezogene Verarbeitung und die Savepoints von Flink ermöglichen die Aktualisierung und Wartung von zustandsbezogenen Anwendungen. Dies gewährleistet Konsistenz und Kontinuität, sogar bei Ausfällen.
-
Streaming-Anwendungen: Flink unterstützt eine Vielzahl von Streaming-Anwendungen, von der einfachen Datenverarbeitung in Echtzeit bis hin zur komplexen Event-Verarbeitung und Mustererkennung.
-
Datenanalyse (Batch, Streaming): Durch die Fähigkeit, sowohl Batch- als auch Streaming-Daten zu verarbeiten, eignet sich Flink gut für Datenanalysen. Sowohl für die Datenanalyse in Echtzeit als auch die Verarbeitung historischer Daten.
- Daten-Pipelines/ETL: Flink wird beim Aufbau von Daten-Pipeines für ETL-Prozesse verwendet, bei denen Daten aus verschiedenen Quellen extrahiert, transformiert und zur weiteren Analyse in Data-Warehouses oder andere Speichersysteme geladen werden.
Herausforderungen mit Apache Flink
Apache Flink hat eine komplexe Architektur und ist nicht einfach zu erlernen. Selbst für erfahrene Praktiker kann ein umfassendes Verständnis, die Bedienung und das Debuggen zur Herausforderung werden. Flink-Entwickler und Operatoren haben häufig mit den Komplexitäten von Custom-Wasserzeichen, Serialisierung, Typenentwicklung usw. zu kämpfen.
Flink wirft, womöglich etwas mehr als die meisten verteilten Systeme, Schwierigkeiten beim Deployment und Cluster-Betrieb auf, wie der Leistungsoptimierung, um der Hardwareauswahl und den Job-Charakteristiken Rechnung zu tragen. Zu den häufigsten Schwierigkeiten gehören die Ursachenforschung bei Leistungsproblemen wie Rückstau, langsamen Jobs und die Savepoint-Wiederherstellung aus unverhältnismäßig großen Zuständen. Andere häufig auftretende Probleme betreffen die Behebung von Checkpoint-Fehlern und das Debuggen von Job-Fehlern, etwa bei unzureichendem Arbeitsspeicher.
Unternehmen, die Flink verwenden, benötigen in der Regel Expertenteams, die sich um die Entwicklung von Stream-Processing-Jobs und die Aufrechterhaltung des Stream-Processing-Frameworks kümmern. Aus diesem Grund war Flink bisher nur für große Unternehmen mit komplexen und fortgeschrittenen Anforderungen an die Stream-Verarbeitung wirtschaftlich sinnvoll.
Flink vs. Kafka vs. Spark, und wann sich welche Lösung eignet
Kafka Streams ist eine beliebte Client-Bibliothek für die Stream-Verarbeitung, insbesondere wenn die Input- und Output-Daten in einem Kafka-Cluster gespeichert sind. Weil es Teil von Kafka ist, nutzt es die Vorteile von Kafka nativ.
ksqlDB überträgt die Einfachheit von SQL auf Kafka Streams und bietet so einen guten Ausgangspunkt für die Stream-Verarbeitung und erweitert den Nutzerkreis.
Kafka-Nutzer und Confluent-Kunden entscheiden sich aus verschiedenen Gründen für Apache Flink, wenn es um die Stream-Verarbeitung geht. Eine komplexe Stream-Verarbeitung etwa, geht oft mit einem großen Zwischenzustand einher, für den es nicht immer sinnvoll ist, Kafka zu verwenden. Wenn dieser Zustand groß genug ist, wird er zu einem eigenständigen Element, das sich auf die Ressourcen und die Planung auswirkt, die für den Betrieb des Kafka-Clusters erforderlich sind. Außerdem können Anforderungen entstehen, für die Streams aus mehreren Kafka-Clustern an verschiedenen Standorten, Streams in Kafka mit Streams außerhalb von Kafka usw. verarbeitet werden müssen.
Da Flink ein eigenständiges verteiltes System mit eigenen Komplexitäten und operativen Nuancen ist, war oft nicht klar, wann die Vorteile von Apache Flink die damit verbundenen Komplexitäten oder Kosten überwiegen. Vor allem, wenn andere Stream-Processing-Technologien wie Kafka Streams oder Apache Spark verfügbar sind.
Vorteile von vollständig verwaltetem Flink mit Confluent
Die Cloud ändert diese Betrachtungen und ermöglicht es, Apache Flink umfassend zu nutzen. Apache Flink als vollständig verwalteter Cloud-Service bietet die gleichen Vorteile, die Confluent Cloud für Kafka bietet. Die operativen Komplexitäten und Nuancen, die Apache Flink aufwendig und kostspielig machen, wie die Auswahl des Instanz-Typs oder Hardwareprofils, die Knotenkonfiguration, die Auswahl des Zustand-Backends, die Verwaltung von Snapshots, Savepoints usw., werden ausgelagert und ermöglichen es Entwicklern, sich ausschließlich auf die Anwendungslogik anstatt auf Flink-spezifische Nuancen zu konzentrieren.
Die Funktionen von Flink sind dadurch nicht nur in Confluent Cloud verfügbar, sondern ändern auch die wirtschaftlichen Überlegungen, wann es sinnvoll ist, Flink zur Stream-Verarbeitung zu verwenden. Unternehmen können Flink somit bei der Einführung von Daten-Streaming früher und für mehr Anwendungsfälle nutzen. Es bedeutet außerdem, dass die Entwickler die für sie am besten geeignete Stream-Verarbeitungsebene wählen können und auch bei sich ändernden Anforderungen oder zunehmender Komplexität, nur eine Plattform nutzen müssen.
Da Flink nun über eine ausgereifte und zuverlässige SQL-Schnittstelle verfügt, ist es sinnvoll, dort zu beginnen – nicht nur für Endnutzer, die Stream-Verarbeitung einführen, sondern auch für Confluent zur Einführung von Apache Flink.
Confluent Chronicles: The Force of Kafka + Flink Awakens
Introducing the second issue of the Confluent Chronicles comic book! Trust us, this isn’t your typical eBook. Inside you’ll find a fun and relatable approach to learn about the challenges of streaming processing, the basics of Apache Flink, and why Flink and Kafka are better together.


