[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Transactional Machine Learning at Scale with MAADS-VIPER and Apache Kafka
This blog post shows how transactional machine learning (TML) integrates data streams with automated machine learning (AutoML), using Apache Kafka® as the data backbone, to create a frictionless machine learning process. This blog post also highlights the business value of combining data streams with AutoML, the types of use cases that can benefit from a TML platform, and how TML differs from conventional machine learning processes. Finally, a general TML architecture is presented using MAADS-VIPER, MAADS-HPDE, MAADS Python Library, and Apache Kafka.
Using these technologies, we will:
- Create transactional training datasets from data streams
- Apply machine learning algorithms to the training datasets
- Store and govern datasets and algorithms in Kafka
- Use the algorithm for predictive analytics and optimization
If you’d like some background on the relationship between Kafka and machine learning before diving in, check out How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka.
Use cases
The following list illustrates the breadth of use cases that can benefit from the application of machine learning to data streams in a scalable and robust platform:
- Algorithms and insights management
- Intelligent patient care
- Oil production optimization
- Hyper-predictions for edge devices
- Fleet prediction and optimization
- Bank fraud detection
- IoT asset monitoring and predictive asset maintenance
- Video analytics (i.e., detect facial expressions to predict customer satisfaction)
- Prediction of health and safety incidents
- Deep brain stimulation optimization to help patients with Parkinson’s disease
Transactional machine learning
Transactional machine learning (TML) applies auto generated machine learning algorithms to data streams with minimal manual intervention. TML creates a frictionless machine learning process, allowing organizations to build advanced and elastic TML solutions using data streams. TML was pioneered by OTICS Advanced Analytics, a company that specializes in streaming AI/ML solutions integrated with Kafka. Underpinning TML is the belief that fast data requires fast machine learning.
There are five principles of TML:
- Data is fluid: Just like streams of water, data flows in from any direction (source) and flows out to any location (sink)
- Data streams must be joinable: Just like SQL joins, joining data streams is critical to building a training dataset in real time
- Data stream format is standardized: Data streams are standardized to JSON format, which makes it easier to build portable solutions between systems and technologies and perform analysis
- Data streams are integrated with auto machine learning (AutoML): AutoML applies machine learning, which does not require any manual intervention, to training datasets in order to find an algorithm that best fits the data
- Low code: TML solutions provide coding languages that make it easy to develop TML solutions without the need to write extensive lines of code
The above principles are used to identify use cases that can benefit from TML. Kafka is an ideal platform for TML solutions because it aligns with principles 1 and 2: data fluidity and stream joining. For highly non-linear data, building machine learning models, or micro-models, from the latest set of data, can improve the quality of learnings, and therefore, improve real-time decision-making.
Kafka and Confluent connectors are built for data collection from multiple source applications into Kafka or OTICS. OTICS connectors are designed to be deployed remotely or close to the source and are deployed in standalone mode, whereas Confluent connectors can be deployed close to the source or run close to Kafka in a cluster mode.
To start building TML solutions, you need the following:
- Confluent Cloud, Confluent Platform, or Apache Kafka: This could be an event streaming on premises or in the cloud running on any vendor platform (Azure, AWS, or Google Cloud).
- MAADS-VIPER: MAADS-VIPER is a source/sink Kafka connector found on Confluent Hub; this is a binary that is cross-platform for Windows or Linux. Further connection details are stored in a Viper environment file:
- If connecting to Confluent Cloud, VIPER supports SASL/PLAIN authentication that requires a secret key and password to connect.
- VIPER also supports SSL/TLS encryption. You need to create three PEM files that are stored locally, such as client key, client certificate, and server certificate.
- MAADS-HPDE: HPDE is an AutoML technology, and it is a binary that is cross-platform for Windows or Linux.
- MAADS-Python Library: This is a client Python library for developing TML solutions, connecting to MAADS-VIPER. Optionally, you can use a REST API such as GET and POST to connect to VIPER from other programming interfaces. VIPER provides a “Help” screen that indicates all of the GET and POST commands.
| ℹ️ | Note: Get started with Confluent Cloud, a fully managed event streaming service based on Apache Kafka, using the promo code CL60BLOG to get an additional $60 of free usage.* You can access a free trial for MAADS-VIPER, MAADS-HPDE, and the MAADS-Python Library by sending a request to info@otics.ca. OTICS will provide a one-hour free overview and setup session if needed. |
Conventional machine learning vs. transactional machine learning
The following discusses the differences between conventional and transactional machine learning.
Conventional machine learning (CML) processes are not designed for data streams due to these reasons:
- The CML process uses historical training datasets that are static and disk resident for machine learning
- The CML process relies on many human touch points for data preparation, model formulation, model estimation, hyperparameter tuning, and model deployment
- CML processes are not easily repeatable
TML differs from CML in the following ways:
- TML uses MAADS-VIPER to automatically create training datasets by joining Kafka topics and data streams. It uses Kafka’s offset parameter to create a transactional training dataset.
- MAADS-VIPER uses MAADS-HPDE to perform machine learning on the training dataset and finds the optimal algorithm that best fits the data.
- MAADS-VIPER produces the optimal algorithm in another Kafka topic.
- MAADS-VIPER consumes the optimal algorithm for predictive analytics or optimization.
Here are some key considerations in the TML process to highlight:
- Kafka’s offsets are critical in rolling back data in the stream to construct training datasets in real time. There are further benefits with Confluent Tiered Storage that enables a cost-efficient way to roll back data in time—short term or long term. Machine learning pairs well with Confluent Tiered Storage.
- To construct a training dataset using streams, you must join the streams.
- The topics in Kafka can be identified as dependent and independent variables to formulate a machine learning model.
- MAADS-HPDE uses proprietary applications of several different algorithms in real time to the training dataset, such as neural networks, linear and non-linear regression, gradient descent, and logistic regressions.
- MAADS-HPDE automatically fine-tunes the hyperparameters in the algorithms.
- MAADS-VIPER consumes the algorithm and produces it to a topic in Kafka for predictive analytics and optimization, which can be consumed by other applications or devices.
- If you are using other machine learning technologies like TensorFlow or have developed your own custom algorithms, the output of these models/algorithms can be used as “external predictions” in VIPER and can be added to a Kafka topic. This could be useful in order to:
- Compare the results of different models
- Combine the results from one model with another model
- Construct more robust training datasets from different model outputs
- If you are using other machine learning technologies like TensorFlow or have developed your own custom algorithms, the output of these models/algorithms can be used as “external predictions” in VIPER and can be added to a Kafka topic. This could be useful in order to:
MAADS-VIPER and MAADS-HPDE can be instantiated to an unlimited number of instances in Windows or Linux-based systems; it is only limited by hardware. Organizations can scale TML solutions easily and quickly with Confluent Cloud, which provides unlimited storage, security, and scalability in a distributed network using the REST API and the MAADS Python library.
Large TML solutions can be architected as microservices to allow solutions to load shed across distributed Kafka brokers.
MAADS Python library
The MAADS Python library is a convenient way to create low-code TML solutions by simply using the functions in the library shown in Table 1 below:
| MAADS Functions | Description |
| vipercreatetopic | Create topics in Kafka brokers. |
| vipersubscribeconsumer | Subscribe consumers to topics. Consumers will immediately receive insights from topics. This also gives administrators of TML solutions more control over who is consuming the insights and allows them to ensure that any issues are resolved quickly in case something happens to the algorithms. |
| viperhpdetraining | Users can perform TML on the data in Kafka topics. This is very powerful and useful for “transactional learnings” on the fly using HPDE. HPDE will find the optimal algorithm for the data in a few minutes. |
| viperhpdepredict | Using the optimal algorithm, users can do real-time predictions from streaming data into Kafka topics. |
| viperhpdeoptimize | Users can even do optimization to minimize or maximize the optimal algorithm to find the best values for the independent variables that will minimize or maximize the objective function. |
| viperproducetotopic | Users can produce to any topics by ingesting from any data sources. |
| viperconsumefromtopic | Users can consume from any topic and use it for visualization. |
| viperconsumefromstreamtopic | Users can consume from a multiple stream of topics at once. |
| vipercreateconsumergroup | TML administrators can create a consumer group made up of any number of consumers. You can add as many partitions for the group in the Kafka broker as well as specify the replication factor to ensure high availability and no disruption to users who consume insights from the topics. |
| viperconsumergroupconsumefromtopic | Users who are part of the consumer group can consume from the group topic. |
| viperproducetotopicstream | Consolidate the data from the streams and produce to the topic |
| Vipercreatejointopicstreams | Users can join multiple topic streams and produce the combined results to another topic. |
| vipercreatetrainingdata | Users can create a training dataset from the topic streams for TML. |
Table 1. MAADS Python library functions
The above functions allow anyone with minimal Python knowledge to connect to MAADS-VIPER and Kafka and perform all the necessary functions to build powerful TML solutions that can push the limits of Kafka for machine learning.
TML and Kafka architecture
Below is a general TML architecture with Confluent Cloud:
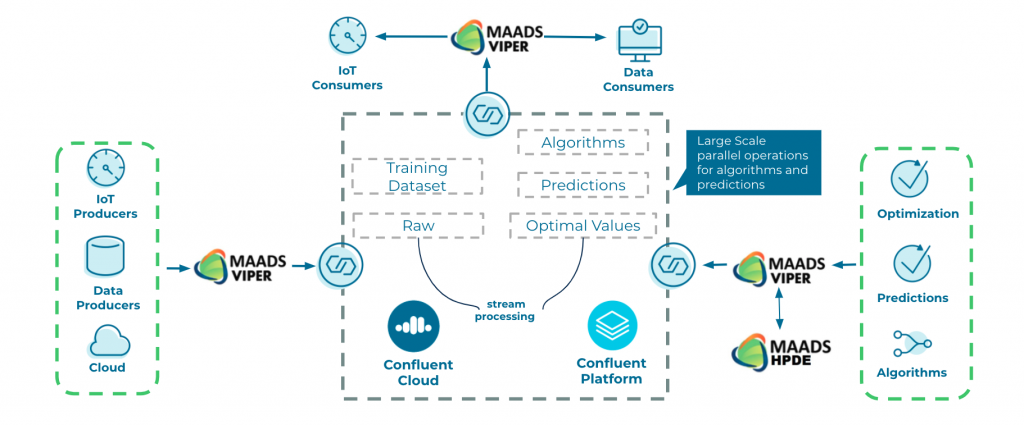 This diagram contextualizes the connector as both a source and sink to Confluent Platform and Confluent Cloud.
This diagram contextualizes the connector as both a source and sink to Confluent Platform and Confluent Cloud.
Some points to note about the architecture:
- It can handle any type of data: numeric (integer or float) or text
- It is horizontally scalable across multiple Kafka brokers and partitions
- It is cross-platform; VIPER and HPDE can run on Windows or Linux
- It is SSL/TLS enabled for Kafka on premises or in the cloud
- It is cloud agnostic
Business value of TML solutions
As businesses face a post-COVID world, the need for increased operational efficiencies and broader use of AI will rise. The growth in data and the increase in the creation of data will demand faster ways of learning from the data. Having the ability to learn faster will lead to faster decision-making.
Data streams integrated with AutoML that can address large-scale problems will continue to gain traction. The resulting business value will manifest as the following:
- Faster decision-making: By reducing the friction that exists in CML, TML increases speed to insight with little manual intervention using solutions that are frictionless and elastic.
- Faster scale: Together with Kafka, TML solutions can scale fast using an API and microservices architecture, opening up new opportunities for organizations in almost every industry.
- Faster (deep) insights: Joining data streams to create training datasets on the fly and applying machine learning to find optimal algorithms with fine-tuned hyperparameters creates a frictionless machine learning process that can provide deeper insights in minutes, as opposed to days or weeks.
- Never lose your ML data: Kafka is a distributed, highly scalable event streaming platform, making it very effective in preserving ML data. It can be further enhanced with Confluent Tiered Storage to enable the long-term storage and reprocessing of historical event data in a cost-efficient way. Storing ML data and models can improve model management, model and data governance, and meet model audit requirements in a distributed manner with high resiliency.
- The Kafka MAADS-VIPER connector for TML applications streams raw data, predictions, optimizations, and algorithms. It is written to a Kafka cluster for further processing and consumed by IoT devices or any other application for visualizations. Kafka offers easy rollback capabilities by way of the offset parameter that facilitate the auditing of data and the models’ results.
Managing algorithms
The increased speed of creating algorithms will lead to an increased number of algorithms in circulation in the enterprise. This creates challenges with:
- Model management
- Governance of algorithms
- Security
As optimal algorithms are found by HPDE for the training datasets, the information about the algorithm type, parameter values, and forecast accuracy are stored or produced by VIPER in a Kafka topic. In addition, MAADS-VIPER automatically keeps track of metadata associated with every model created and stores the information shown in Table 2 in a local embedded database.
| Field Names | Description |
| Activate/Deactivate | Administrators of VIPER can manually activate or deactivate a topic, or they can tell VIPER to automatically deactivate algorithms using alerts and notifications. |
| Topic/Algorithm | The topic name in Kafka can also be the name of the algorithm and is chosen by the user. |
| Last Read of Topic | This is the date and time when the topic was last read from. Whenever a consumer reads from a topic, VIPER records the date and time. |
| Bytes Read (KB) | The number of bytes, in kilobytes, read by the consumer are recorded. This is the egress amount. Egress is an important metric for pricing cloud consumption. |
| Active Read Days | This is the number of days that the topic has been read. |
| Consumer ID | Consumer ID uniquely identifies the consumer that is consuming from the topic. |
| Producer ID | Producer ID is the ID of the producer that is writing to the topic. |
| Group ID | Group ID is the ID of the group that the consumer may belong to. Administrators can create groups and assign consumers to the group. This could be useful for parallel delivery of information from a single topic to multiple consumers. |
| Company Name | This is the name of the company that the consumer belongs to. |
| Contact Name | This is the name of the consumer. |
| Contact Email | This is the email of the consumer. |
| Location | This is the location where the consumer resides. |
| Description | This is a description of the topic. |
| Last Offset | When a consumer reads from a topic, this field records the last offset or the location of the read in the topic. |
| isActive | This indicates if a topic is active (1) or not active (0). |
| CreatedOn | This is the date and time when the topic was created. |
| Updated | This is the last date and time that the topic was written to by the producer. |
| Last Write to Topic | This is the last date and time that the topic was written to by the producer. |
| Bytes Written (KB) | This is the number of bytes, in kilobytes, written by the producer. |
| Active Write Days | This is the number of days that the topic was written to. |
| Replication Factor | The replication factor is a feature of Kafka and signifies the number of physical computer servers to use for redundancy. |
| Partitions | This is the number of partitions in the topic. |
| Dependent Variable | If this topic is a joined topic that stores a training dataset, then this is the name of the dependent variable in the training dataset. |
| Independent Variables | If this topic is a joined topic that stores a training dataset, then this is the name of the independent variables in the training dataset. |
| MAADS-HPDE Algo Server | This is the physical IP address or network name of the AutoML server. |
| MAADS-HPDE Port | This is the network port that MAADS server is listening on. |
| MAADS-HPDE Microservice | If you are using a reverse proxy, this is the network name for the proxy. Using microservices can be very beneficial for large-scale TML solution deployments. |
| MAADS Algorithm Key | This is the key name that uniquely identifies the optimal algorithm. |
| MAADS Token | This is a secure token needed to access MAADS-HPDE. |
| Joined Topicaims | This lists the names of the topics that are joined together. |
| Group ID | This is a unique ID for the group that consumers belong to. |
| Group Name | This is the name of the group. |
| Number of Consumers | This is the number of consumers in the group. |
Table 2. Topic metadata
You are also provided with a dashboard called the Algorithm and Insights Management System (AiMS), as shown in the figure below: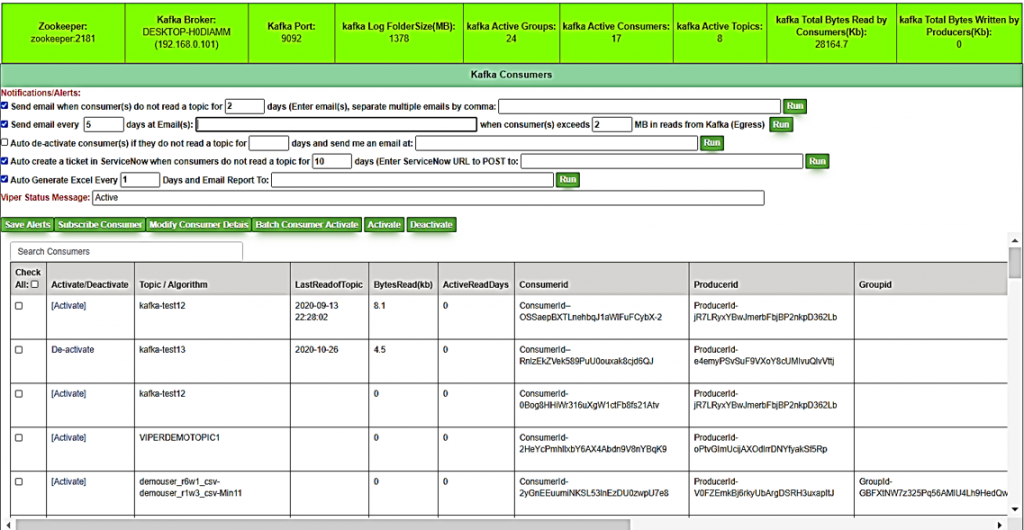
The above image shows an AiMS dashboard for Kafka consumers, and similar information is provided for producers and groups. AiMS allows administrators to set up notifications and alerts to activate or deactivate algorithms. By keeping track of egress and ingress, administrators can also keep track of how much money TML solutions are costing and who is producing to and consuming from solutions.
The data in topics can be validated through the CLI or a GUI tool like Confluent Control Center.


Bringing it all together
Conventional machine learning processes are not ideal for data streams. TML with Apache Kafka offers a way forward, allowing organizations to layer on deeper machine learning to data streams to create a frictionless machine learning process for greater business impact.
MAADS-VIPER, MAADS-HPDE, and MAADS Python Library, alongside Kafka, work together to provide TML solutions that can easily scale and provide faster decision-making with deeper insights—all in real time.
As data creation speed increases, machine learning speed will also need to increase. Kafka with MAADS-VIPER and MAADS-HPDE is breaking new ground in transactional machine learning and will continue to add considerable value to organizations that are looking for faster ways to apply machine learning to data streams at scale.
Next steps
Interested in learning more? Download the MAADS-VIPER Kafka Connector to get started!
You can also check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud.*
If you’re looking at scaling machine learning operations, reach out to OTICS for a demo on Kafka with MAADS-VIPER and HPDE by emailing them at info@otics.ca or visit GitHub to get started with TML today.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


