[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Streaming Machine Learning and Exploration with Confluent and SymetryML
Imagine you’ve been working with Confluent and just got your new streaming pipeline set up to power your new predictive maintenance solution. Next, you look to implement machine learning (ML) to help with fault detection across your in-service equipment sensors–but you quickly realize conventional (batch) machine learning isn’t agile enough to get the job done. You look for a solution that will allow you to close the machine learning loop very quickly, to ensure your models are always fresh and up to date so that you’re alerted before the equipment breaks, not after. The solution is online machine learning, otherwise known as streaming machine learning.
This blog post explores how to leverage a simple API to help you migrate from batch machine learning to streaming machine learning and real-time exploration, coupled with Apache Kafka®, to create unique solutions that will give your company an edge.
This blog post doesn’t address general machine learning basics—that was already covered nicely by Confluent’s Kai Waehner in Using Apache Kafka to Drive Cutting-Edge Machine Learning. Instead, this blog post focuses on showing cutting-edge, Kafka-native, streaming machine learning which provides several unique benefits that conventional machine learning can’t support, like supporting real-time machine learning pipelines, keeping all/most historical information in memory when building models, and expanding the map reduce paradigm to streaming data.
Data in motion is the future (and machine learning needs to keep up)
If you’re reading this blog, it’s safe to assume you understand the importance of streaming data and what Confluent is doing in the market. Plus, we can all agree that massive amounts of data continues to be generated in real time and at an ever-increasing velocity, which means companies need new tools and solutions that can keep up. Our hyper-connected world means companies have to learn to quickly and efficiently harness all of this data in motion, which is why Confluent and their work with Kafka continues to rise so rapidly in popularity.
The world needs machine learning to match the velocity and real-time nature of the budding environment of event stream processing. Stanford’s Chip Huyen agrees, as she concludes in Machine Learning Is Going Real Time: “Machine learning is going real-time, whether you’re ready or not. While the majority of companies are still debating whether there’s value in online inference and online learning, some of those who do it correctly have already seen returns on investment, and their real-time algorithms might be a major contributing factor that helps them stay ahead of their competitors.”
SymetryML capabilities and technical overview
The following outlines the technology that powers all the unique capabilities SymetryML brings to market, including our streaming anomaly detection solution, which helps to solve problems such as: monitor or predict maintenance and failure of IoT assets, identify and predict bank fraud in real time, enhance patient care, connected cars, hyper demand forecasting, and more.
SymetryML and Confluent
At its core, SymetryML is a streaming machine learning software (leveraging all proprietary online algorithms/models). When streaming data is pushed into the software, the proprietary technology extracts statistical information from each new tuple and builds predictive models or anomaly detection models, for instance:
- Separation between predictive model building and data ingestion, which allows you to perform continuous ML—as the stream of data is coming from a Kafka topic—to build various predictive models using any of your features as the target variables as well as using any other features as inputs variables
- Improvised ML models with incoming streams of data
- SymetryML can scale with many Kafka topics with multiple partitions; a feature that will be covered in a subsequent blog post
- SymetryML can automatically adapt to Kafka topic schema changes; if your data schema changes a lot, this is a great feature to have
- Extensive exploration API that allows you to get various real-time metrics from your streaming data
- Rest API for developers and Web UI for business and analytics users
For more information about the technology behind SymetryML, watch this quick introductory video.
Here’s what you’ll need to use SymetryML on your own
- SymetryML Confluent Connector
- SymetryML license: simply email kafka@symetryml.net to get set up. If you’re a Confluent client, you get a free three-month trial
Why is having machine learning capabilities so important when using streaming data? Read these previous blog posts:
SymetryML and Confluent demo
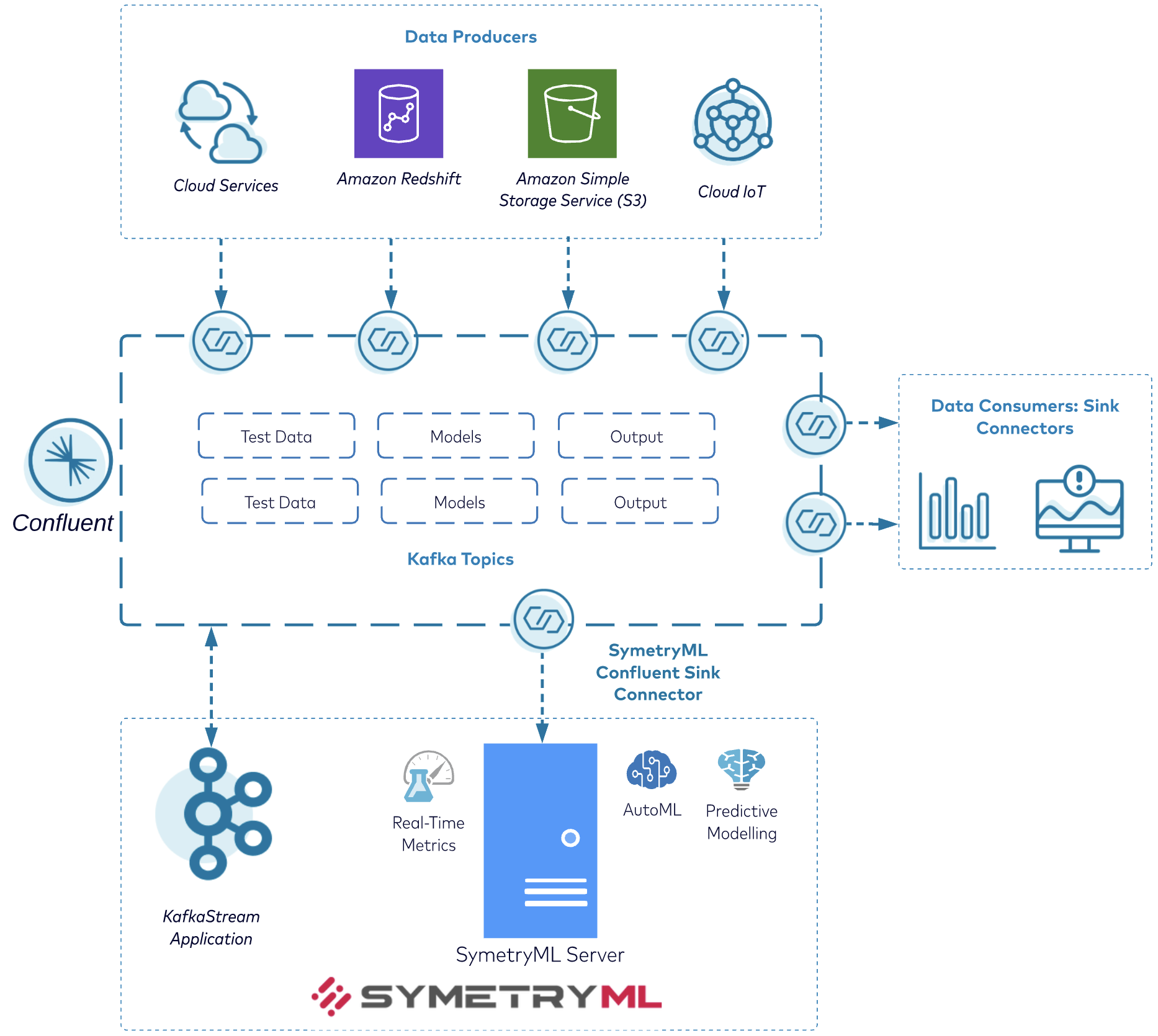
Architecture overview of how SymetryML sets ML in motion
About the data used for the demo
Below is a step-by-step outline of how to perform a few of the machine learning capabilities using Confluent, Apache Spark, and SymetryML.
Specifically, this demo shows the streaming anomaly detection solution using a publicly available dataset. While this dataset is somewhat generic, the goal is to show SymetryML’s unique ability to apply ML leveraging streaming data. (Note: This solution can be applied to any data schema supported by the SymetryML Confluent Connector. Supported data types include: boolean, integer, string, or integer.)
The dataset is a modification of the UCI Statlog (Shuttle) dataset and is described as:
“The original Statlog (Shuttle) dataset from UCI machine learning repository is a multi-class classification dataset with dimensionality 9. Here, the training and test data are combined. The smallest five classes, i.e., 2, 3, 5, 6, 7 are combined to form the outliers class, while class 1 forms the inlier class. Data for class 4 is discarded.”
Set up your Kafka Connect connector and SymetryML for streaming machine learning
With the SymetryML Confluent Connector, you can easily stream into a SymetryML project—where all the aforementioned ML techniques can be applied.
Below is a high-level diagram of how data flows from a Kafka topic to a SymetryML project.
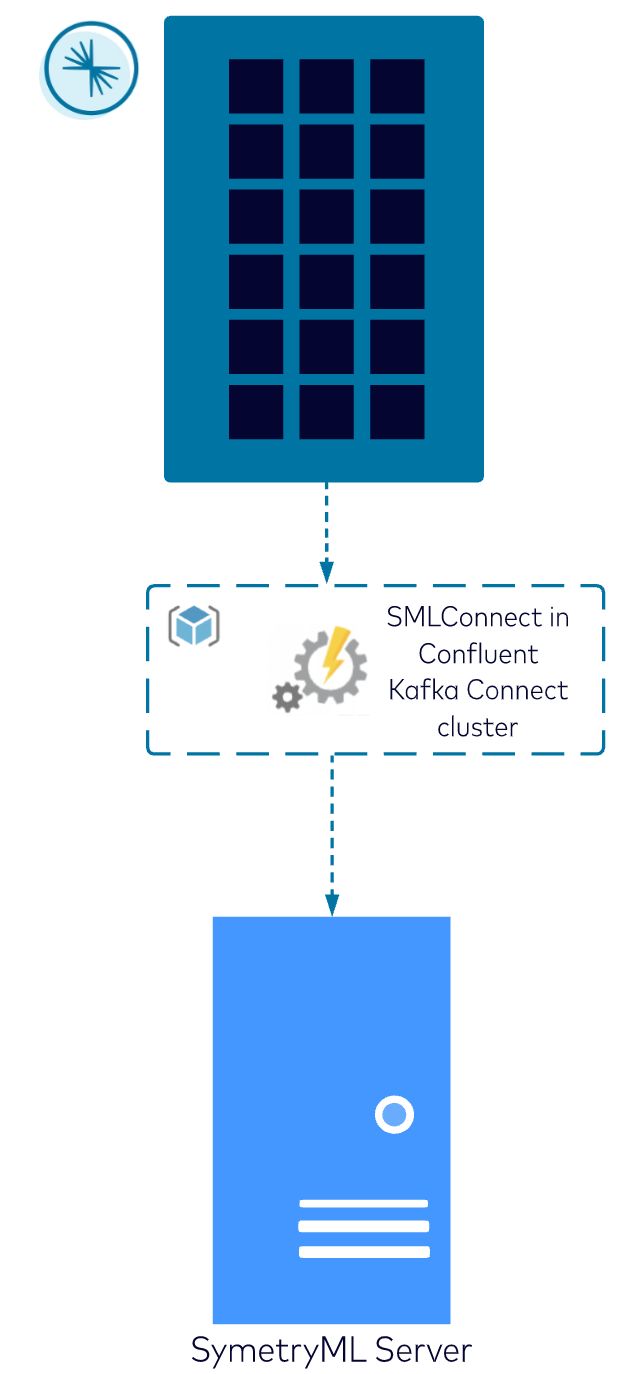
The connector uses the SymetryML Rest API to stream data continuously. More details about the SymetryML Confluent Connector can be found on Github.
The following illustrates how to take a stream of inbound sensor information continuously pushed into a Kafka topic and detect anomalies using a Kafka Stream application:
- Push data into a Kafka topic (shuttle-sensors)
- Create a SymetryML project
- Use the SymetryML Connector to push data to the SymetryML project
- Create an anomaly detection model to compute an anomaly score
- Use a Kafka Stream application to continuously perform anomaly detection
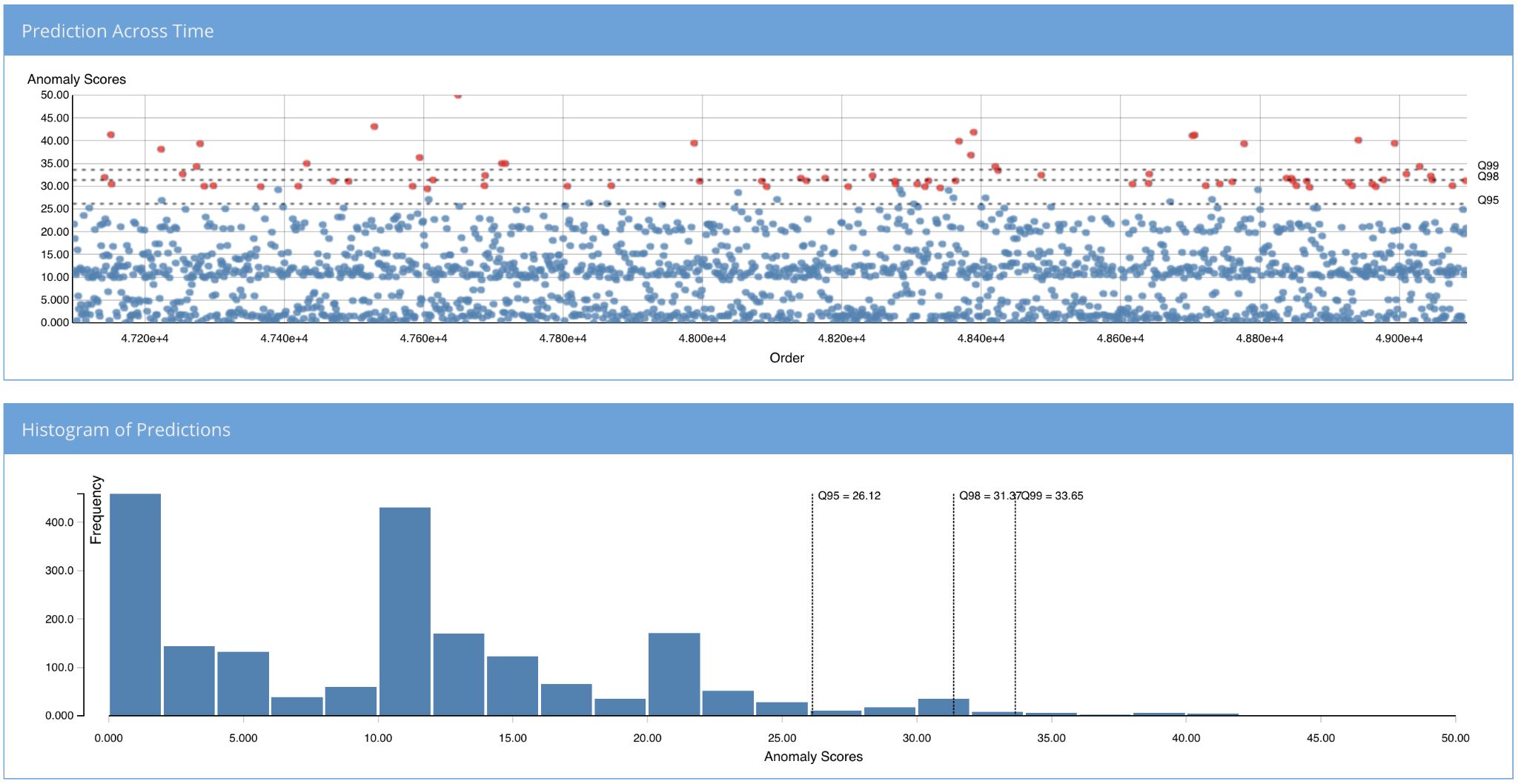
- Visualize anomaly score as well as some quantile of the anomaly scores
See below for step-by-step visuals of the SymetryML UI (SymetryML also has a REST API).
- Push data into a Kafka topic; this demo uses a simulator to push the shuttle data into a Kafka topic.
- Create a SymetryML project and enable histogram so that you can use the histogram-based anomaly detection:
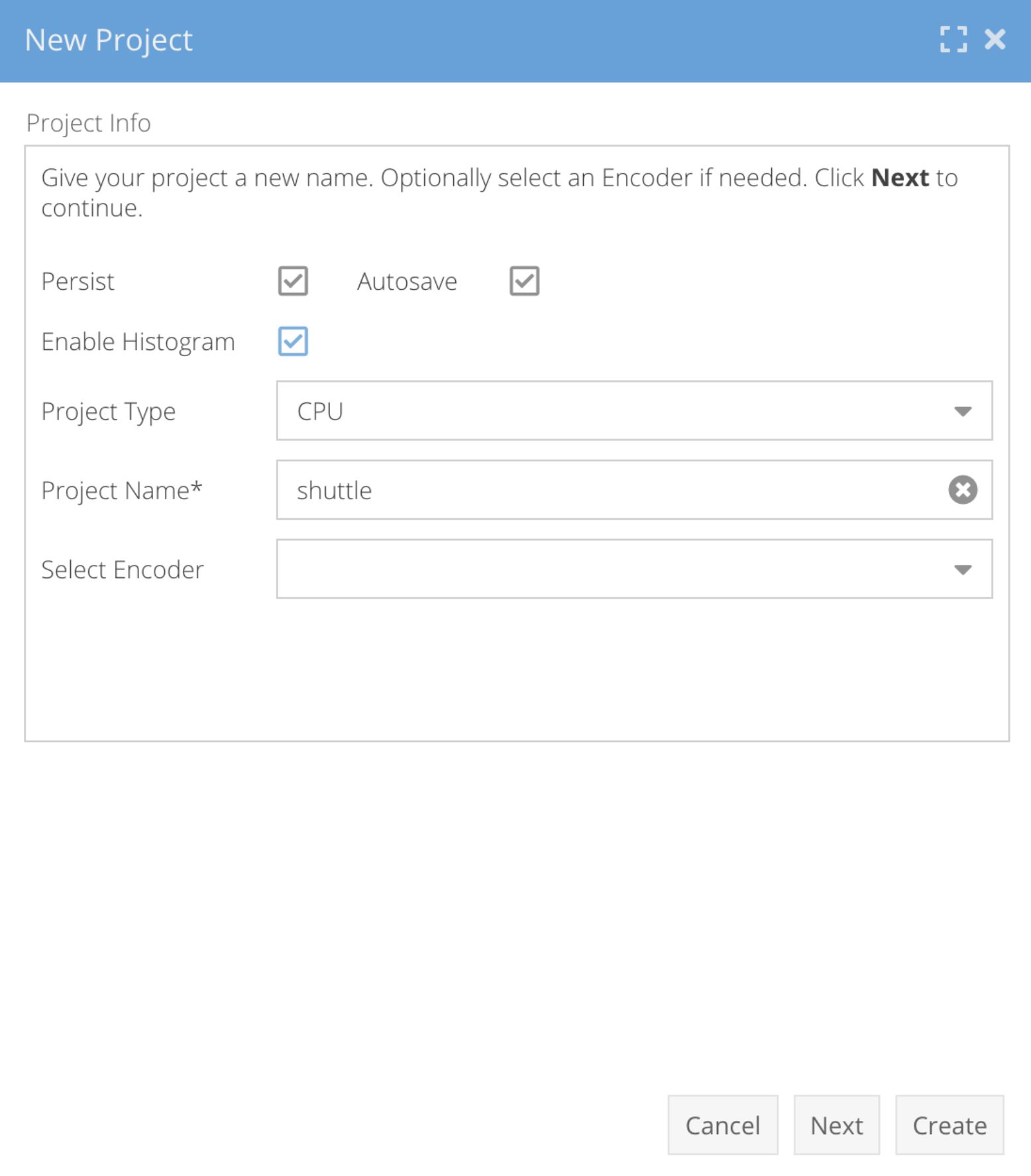
SymetryML UI – New SymetryML project setup - Configure the SymetryML Kafka Sink Connector.
Here is an example of configuring the SymetryML Sink connector to push data–coming from the shuttle-sensor topic into the “shuttle” SymetryML project:{ "name": "symetry-sink-1", "config": { "connector.class": "com.sml.kafka.connector.SymetryKafkaSinkConnector", "group.id": "connect-group-1", "tasks.max": "2", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "io.confluent.connect.avro.AvroConverter", "topics": "shuttle-sensor", "consumer.max.poll.records": 500, "sml.attribute.types": "C,C,C,C,C,C,C,C,C,X", "sml.dataframe.max.chunk.size": "100", "sml.url.1": "http://charm:8080/symetry/rest", "sml.project.1": "shuttle", "sml.customer.id.1": "c1", "sml.customer.secret.key.1": "XXXX_OMMITTED_XXXX", "http.client.idle.timeout.ms": "55000", "http.client.response.buffer.size": "2048000", "logging.is.verbose": "false", "logging.is.signature.included": "false", "logging.is.url.body.truncated": "true", "sml.request.retry.delay.ms": 10000, "sml.request.max.retries": 3, "sml.project.must.preexist": "false", "drop.invalid.message": "false", "key.ignore": "true", "schema.ignore": "true", "behavior.on.malformed.documents": "warn", "value.converter.schema.registry.url": "http://host.docker.internal:8081" } }Once the project is created, the data starts to stream into the application. You can look at the various univariate statistics changing in real time as data is pushed into the Kafka topic.
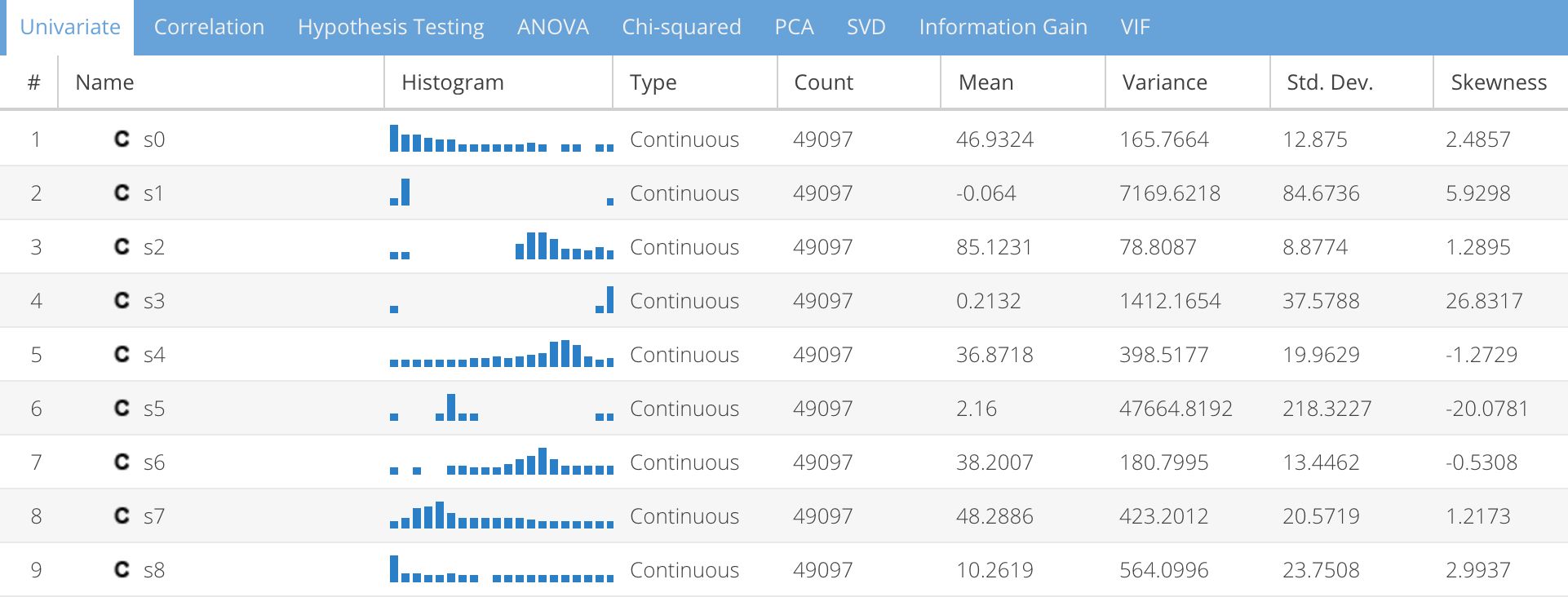
SymetryML UI – Real-time data exploration dashboard - Create a histogram-based anomaly detection model:
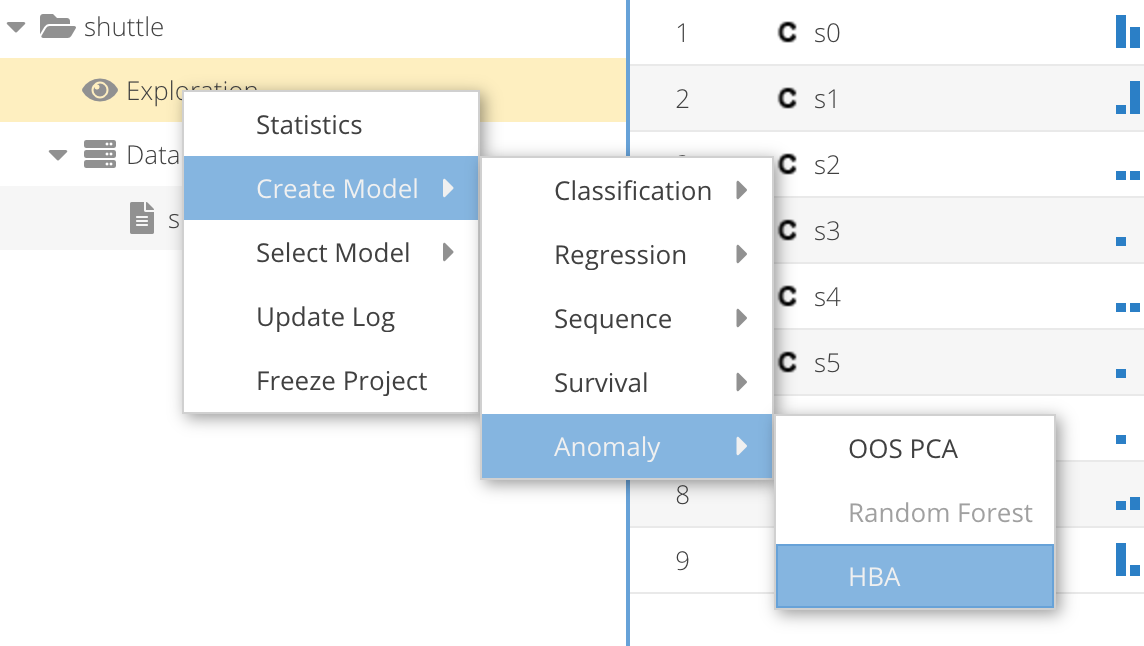
- Start the Kafka Stream application.
The following is a high-level diagram of the Kafkfa Streams app and the configuration file for sym-kafkastream-app. For more detail or setup support, please email kafka@symetryml.net.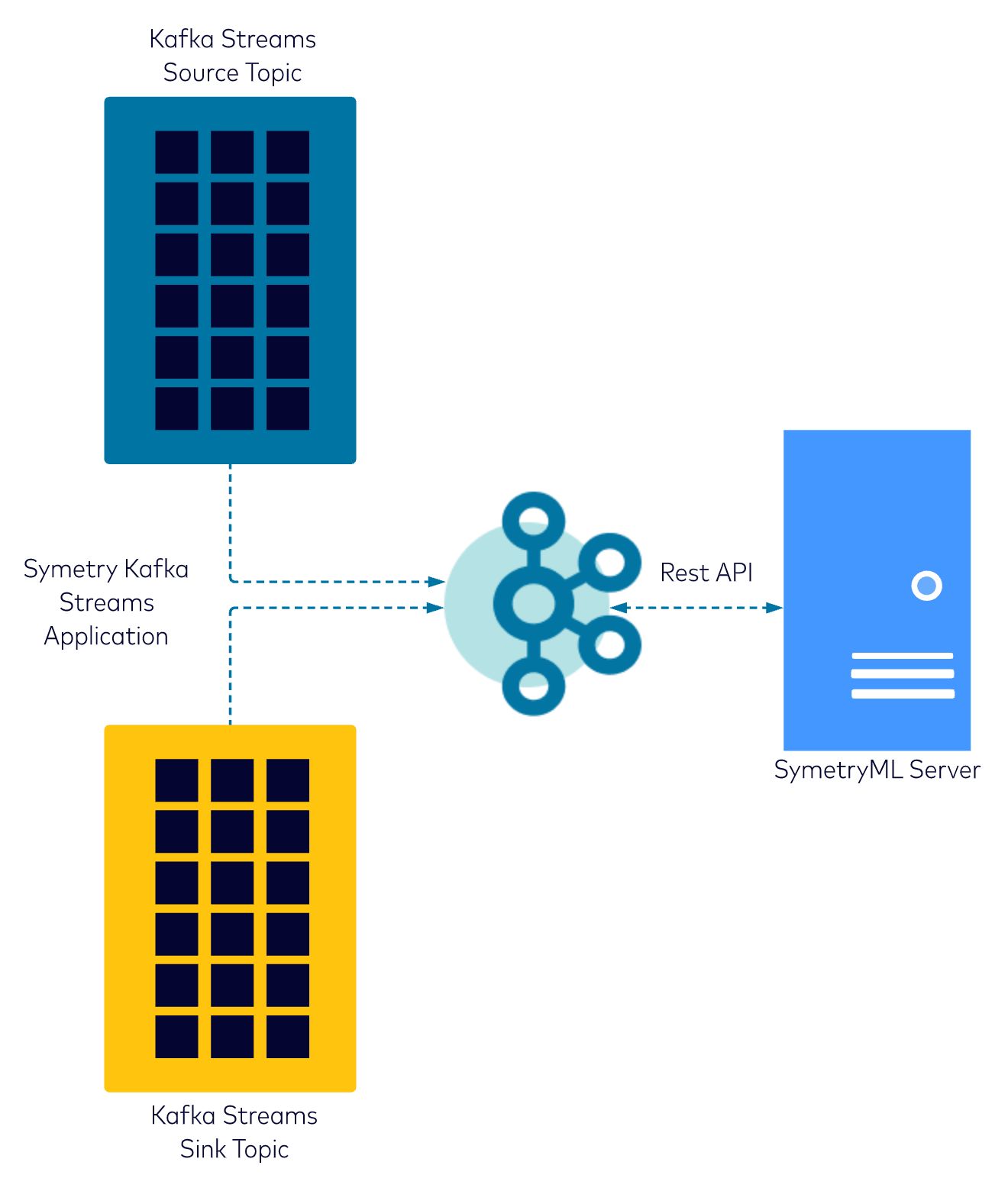
sml.kstream.source.topic=shuttle-sensor sml.kstream.sink.topic=shuttle-sensor-preds
sml.kstream.app.id=smlks-app-v1 sml.kstream.client.id=smlks-client-v1
sml.kstream.project.id=shuttle sml.kstream.model.id=hba1
sml.kstream.rest=true sml.kstream.rest.user=c1 sml.kstream.rest.secret= XXXXX-OMMITTED-XXXXXX sml.kstream.rest.host=http://charm:8080
sml.kstream.record.poll.max=500 sml.kstream.schedule.ms=4000
# KAFKA PROPS bootstrap.servers=charm:9092 schema.registry.url=http://charm:8081 enable.auto.commit=true commit.interval.ms=5000
Result
You can now visualize the anomalies directly (in real time) from the SINK topic as the predictions are pushed by the sym-kafkastream-app. SymetryML models have the ability to process and adjust to new data in real time, enhancing the effectiveness of your anomaly detection solution (or any solution).
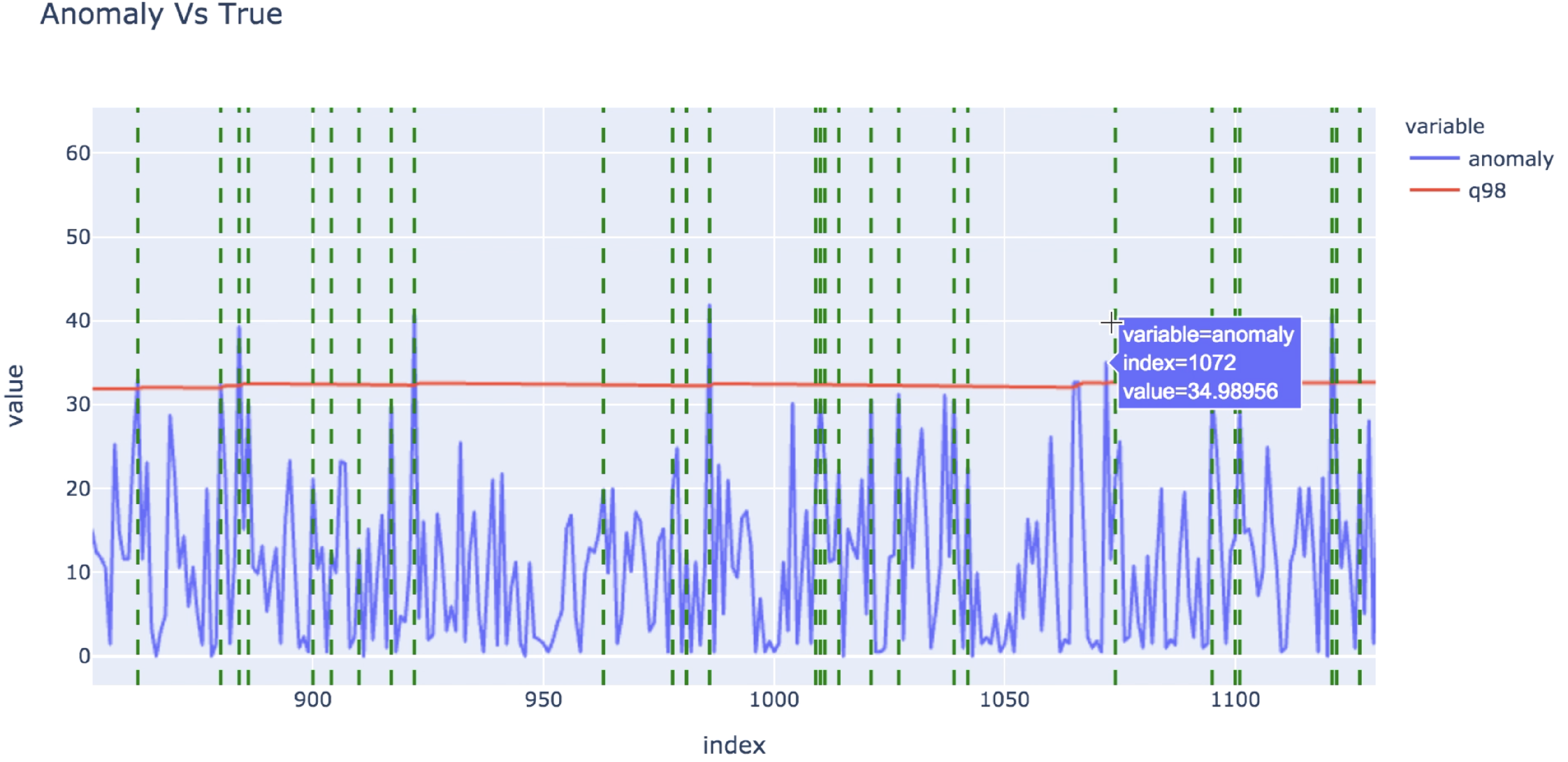
The following graphic shows a sample of the true value (the actual anomalies) versus the anomaly scores as predicted by the model.
Conclusion
With SymetryML, users can quickly and easily create predictive models to apply to their event streaming architecture. And because SymetryML models can continuously learn on the fly, your models can stay up to date, resulting in more efficient and effective solutions, and ultimately leading to better business outcomes.
With Confluent and Kafka, your business and your data are operating in real time. It’s time your machine learning solutions do too.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.



Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.