[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
How to Keep Bad Data Out of Apache Kafka with Stream Quality
Dealing with garbage in, garbage out (GIGO) has tormented data teams for generations. Analytics and decision making have suffered from this “garbage”. The new era of machine learning and being increasingly data-driven brings more concerns and consequences. Data quality controls ensure data is fit for consumption and meets the needs of downstream data consumers and users across the business.
While data quality is a concern in the data-at-rest world, the problem is exacerbated in the new world of data in motion and streaming as bad data can spread faster and to more places. In particular, in event-driven systems that react immediately to real-time data, bad data can cause an entire ecosystem of applications and services to crash or run sub-optimally on invalid schemas and information.
In asynchronous messaging patterns, decoupled services and applications that are developed, maintained, and deployed by different teams must have a way to understand each other. These entities need to be able to communicate over agreed-upon data contracts that they all can trust and share—a kind of lingua franca for data streaming.
So why do we feel the pain of poor data quality now more than ever?
- The volume, variety, and velocity of data are rapidly increasing, particularly with the rise of streaming and data in motion
- A global re-architecture of data systems is taking place, with a massive shift to the cloud
- Increasingly complex data architectures with a proliferation of applications, databases, and other data systems needing to talk to each other across environments
- Tangled and dynamic data flows make it difficult to pinpoint exactly where issues are occurring
- Data ownership is less clear as teams shift towards distributed data ownership models
Ensure streaming data quality with Confluent’s Stream Quality
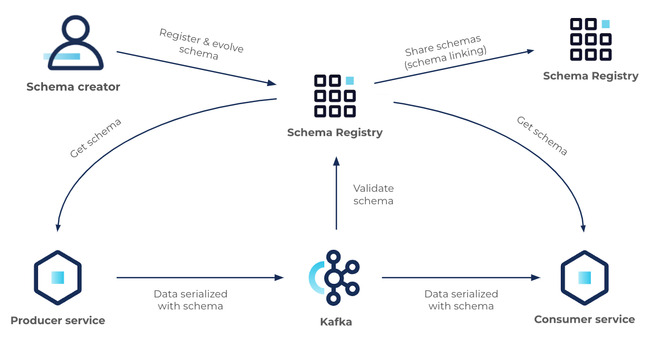
Confluent’s Stream Quality enables teams to deliver trusted real-time data streams throughout the business. These components set and control the data rules, constraints, and conditions by which an entire event-driven system operates. Stream Quality comprises two components today: Schema Registry and Schema Validation.
In this blog post, we’ll dive into each of these components to discuss their importance, cover the most common use cases, and show you how to quickly get up and running.
Schema Registry: The easiest way to define and share data contracts without operational complexity
Confluent’s Schema Registry is a central repository for schemas that:
- Allows producers and consumers to communicate over a well-defined “data contract” in the form of a schema
- Controls the schema evolution via clear compatibility rules everyone understands
- Optimizes the payload over the wire by passing a schema ID instead of an entire schema definition
At its core, Schema Registry has two main parts:
- A REST service for validating, storing, and retrieving Avro, JSON Schema, and Protobuf schemas
- Serializers and deserializers that plug into Apache Kafka® clients to handle schema storage and retrieval for Kafka messages across the three formats
Additionally, Schema Registry seamlessly integrates with the rest of the Confluent ecosystem:
- Kafka is integrated with Schema Registry via Schema Validation (more on that later)
- Connect is integrated with Schema Registry via converters
- ksqlDB, REST Proxy, and the Confluent CLI are integrated with Schema Registry via serialization formats
- Confluent GUI is integrated with Schema Registry via the Message Browser
So, let’s see how we can leverage Schema Registry to reliably produce and consume data in Kafka.
1. Choose a data serialization format
The decision of which data serialization format to use with Kafka is an important one. In our context, data serialization is the process of translating an object into a stream of bytes to be sent over the wire and stored in Kafka. The reverse process of reconstructing the object from a stream of bytes stored in Kafka is called deserialization. We recommend that you use a serialization format with schema support. Schemas are extremely important in data streaming for clean and safe communications between parties. Schemas act as a kind of API in data streaming; as the interface on which decoupled services and applications operate.
As mentioned above, at Confluent we added special support for Avro, Protocol Buffers, and JSON. These are our recommended serialization formats to use with Kafka. Deciding which of the three to use really depends on your needs, preferences, and constraints.
The table below provides a quick run through of characteristics and differences across the three formats to help you with the decision process.
| Avro | Protocol Buffer | JSON | |
| Type | Binary-based | Binary-based | Text-based |
| Schema support | Yes | Yes | Yes |
| Schema on read | Yes | No | No |
| Schema language | JSON | Protobuf IDL | JSON |
| Size/compression | Great compression | Great compression | No compression |
| Speed | Very good | Very good | Moderate |
| Ease of use | Very good | Good | Very good |
| Programming languages support | Good | Very good | Good |
| Tooling | Very good | Very good | Moderate |
| Community activity | Moderate | Great | Moderate |
2. Register a schema in Schema Registry
Once you have your Schema Registry up and running, you can start registering schemas via the UI, API, CLI or the maven plugin. Schema Registry will assign a monotonically increasing (but not always consecutive) unique ID (within that registry) to each registered schema. Additionally, and for non-production scenarios, you can have your producer application directly register a schema with the property auto.register.schemas=true.
3. Produce records to Kafka
Now it’s time to start sending data to Kafka. The first thing the producer will do is fetch the schema ID from the Schema Registry given an Avro, Protobuf, or JSON object (with reference to the schema that describes it). The schema ID will then be prepended to the record payload (schema ID+record) and sent to Kafka. Note that all this orchestration is done automatically by the Avro, Protobuf, and JSON serializers on the Kafka clients.
4. Consume records from Kafka
On the consumer side, after receiving the payload, the first thing the consumer will do is extract the schema ID (bytes 1 through 5 of the payload, byte 0 is a magic byte) and use it to look up/fetch the writer schema in the Schema Registry if not available in cache (clients cache the schema ID to schema mapping the first time they talk with Schema Registry and use it for subsequent lookups). With the writer schema in hand and the current reader schema, the consumer can now deserialize the payload. Note that all this orchestration is done automatically by the Avro, Protobuf, and JSON deserializers on the Kafka clients.
5. Evolve a schema
Producers and consumers are decoupled in regards to schema evolution, and can upgrade their schemas independently following an agreed-upon compatibility type. After the initial schema is defined, applications may need to evolve it over time. When this happens, it’s critical for the downstream consumers to be able to seamlessly handle data encoded with both the old and the new schema. This is an area that tends to be overlooked in practice until you run into your first production issues. Without thinking through data management and schema evolution carefully, people often pay a much higher cost later on.
In general, backward compatibility is the easiest to work with since it does not require that you plan for future changes in advance so you only need to consider past versions of a schema. You can make schema changes as you encounter new requirements. First, you would update new consumers to accommodate the schema change, and then you would update producers.
Quoting Martin Kleppmann from his great blog post on schema evolution:
“In real life, data is always in flux. The moment you think you have finalised a schema, someone will come up with a use case that wasn’t anticipated, and wants to ‘just quickly add a field.’”
6. Share schemas
As Kafka usage grows to support more mission-critical workloads within an organization and more teams start working with the technology, the need to establish and enforce global controls for data quality only increases. Schema linking provides an easy means of sharing schemas and establishing consistent quality controls everywhere they are needed: across clouds, on-premises, throughout a hybrid environment, etc. Paired with cluster linking, this allows you to:
- Build a globally connected and highly compatible Kafka deployment with shared schemas and perfectly mirrored data
- Ensure data compatibility everywhere with operational simplicity by leveraging shared schemas that sync in real time
- Share schemas to support every cluster linking use case including cost-effective data sharing, multi-region data mirroring for disaster recovery, cluster migrations, and more
Putting this into action – StreamWearables
Let’s walk through the importance of schema consistency and compatibility using an example of how an e-commerce business, StreamWearables, processes its online orders. In the figure below, we can see the online “Order service” producing new order events to a topic named “order” and two consumers, “Shipping service” and “Customer rewards service”, consuming those events for further processing.
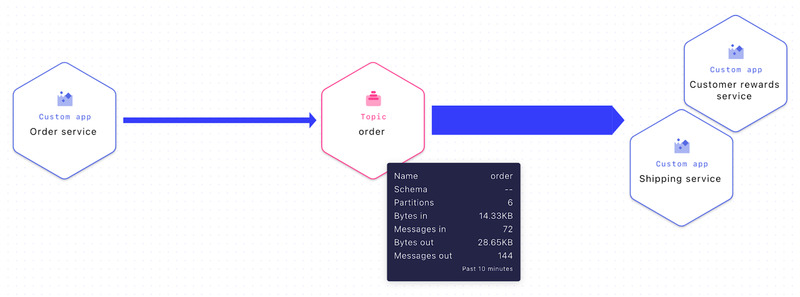
Stream Lineage (real time view of data flows) “Order service” producing to topic “order” and “Customer rewards service” and “Shipping service” consuming from topic “order”.
Now, because the teams at StreamWearables thought they were great at communicating with each other and keeping in-sync, schemas and Schema Registry became an afterthought. “Let’s move ahead without schemas”, said Francisco, the lead streaming architect, “no need to worry because we have everything under control, life is good.” That’s true, until it’s not good! One day, the “Order service” decides to change the orderId type from a number to a string, and 💣💣💣, both “Shipping service” and “Customer rewards service” crashes.
The next thing you know, disaster strikes and orders are unable to be fulfilled—now, someone needs to call the CEO at 2 a.m. on a Saturday, during his only vacation of the year.

“Shipping service” logs before and after the “Order service” changed the data format
Stream Lineage with “Order service” producing to the “order” topic, but no services consuming from it (result of services crash due to unexpected data format changes)
How did the StreamWearables team fix this problem? They created an explicit data contract for order events in the form of a Protobuf schema, and registered it in Schema Registry:
syntax = "proto3";
package io.confluent.demo.streamwear.pojo;
import "google/protobuf/timestamp.proto";
message OnlineOrder { string order_id = 1; google.protobuf.Timestamp order_date = 2; double order_amount = 3; repeated int32 product_id = 4; int32 customer_id = 5; }
OnlineOrder Protobuf schema
Next, all of the various teams changed their code to use the Confluent Protobuf serializer and deserializer with the new Protobuf schema.
// Set key serializer to StringSerializer and value serializer to KafkaProtobufSerializer
props.put("key.serializer", StringSerializer.class);
props.put("value.serializer", "io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializer
");
// New online order - create the OnlineOrder POJO generated from protoc-jar-maven-plugin
Order.OnlineOrder order = new OnlineOrder().newProtobufOrder();
// Create a producer
Producer<String, Order.OnlineOrder> producer = new KafkaProducer<>(props);
// Create a producer record
ProducerRecord<String, Order.OnlineOrder> record =
new ProducerRecord<>(topic, "" + order.getOrderId(), order);
// Send the record
producer.send(record);
// Close producer
producer.close();
Order service code snippet using the KafkaProtobufSerializer
With all services running and communicating with the new order schema, let’s now take another look at the data stream within Stream Lineage:
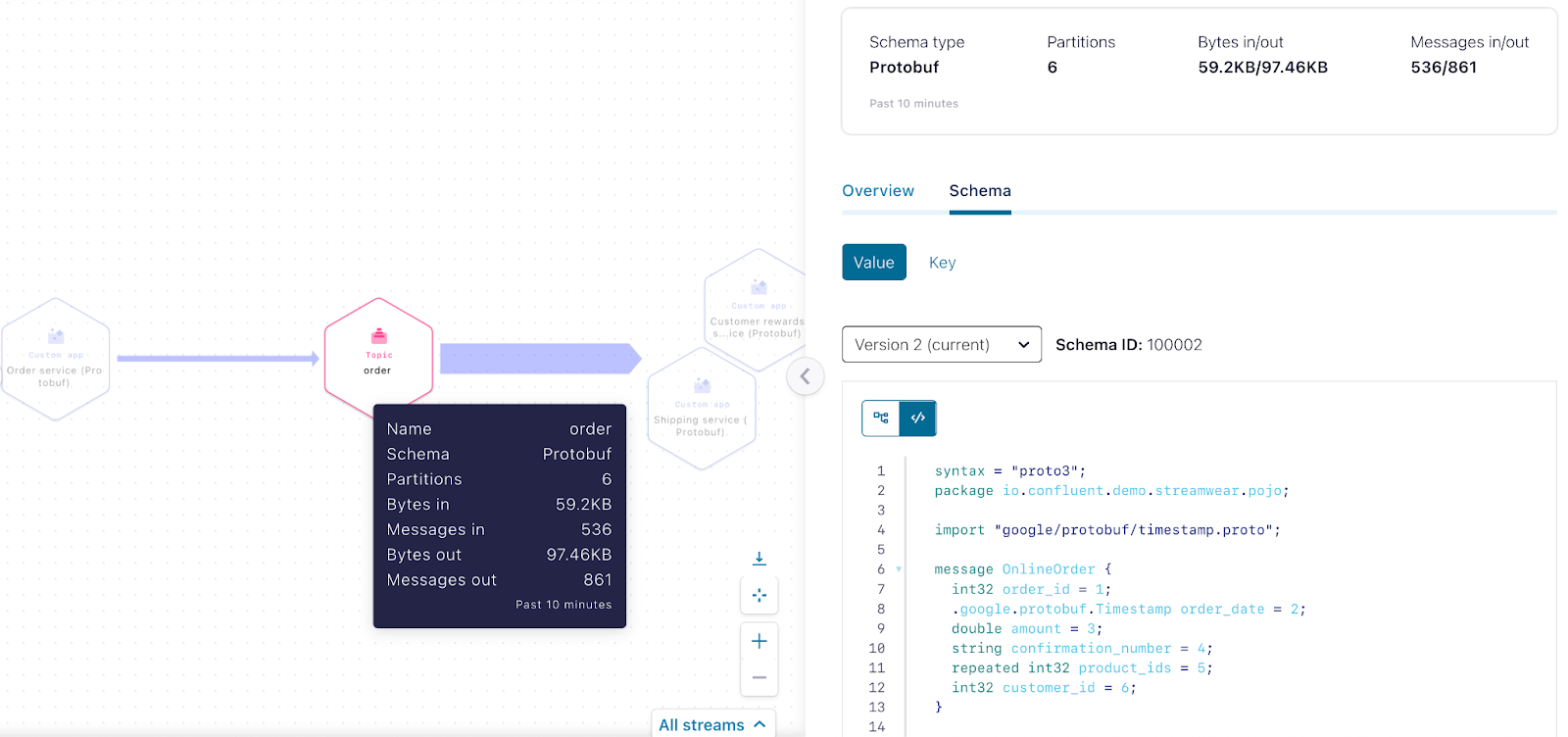
The StreamWearables teams learned their lesson from this incident; “SCHEMA-DRIVEN DEVELOPMENT ROCKS” is now scrawled on the walls of the office.
Last but not least, the CEO kept his promise: everyone went on a week-long vacation on the Stream Boat to celebrate!

Source: Original image is from “The Love Boat: Happily Ever After” (1986), modified for this blog post
Schema Validation: Enforce data contracts with the click of a button
Using schemas and Schema Registry is quite simple, as explained above, but relies on the clients to make sure rules are followed, i.e, that data is serialized and deserialized with a schema registered in Schema Registry. It’s basically a handshake agreement between the producers and consumers of the data.

Source: “Design for Living” (1933)
But what if one side drops out of the agreement, whether voluntarily or involuntarily? Typically in such scenarios, you end up with bad data in Kafka. And note that this is not necessarily bad actors—in fact, many times and probably most commonly it’s simply misconfigured or unaware clients.
Schema Validation ensures that data produced to a Kafka topic is using a valid schema ID in Schema Registry, and discards it if it’s not with a validation error. Essentially, Schema Validation makes sure both parties honor their agreements. Today, Schema Validation is available for Dedicated clusters on Confluent Cloud, as well as in Confluent Platform.

Error message on the Confluent CLI producer when trying to send a “garbage” message to the topic “order” configured with broker-side schema validation.
Enabling Schema Validation on a topic is straightforward, and can be configured using the Confluent CLI or the Confluent UI.
confluent kafka topic update order --config confluent.<key|value>.schema.validation=true
Enable broker-side schema validation on the topic order using the Confluent CLI.
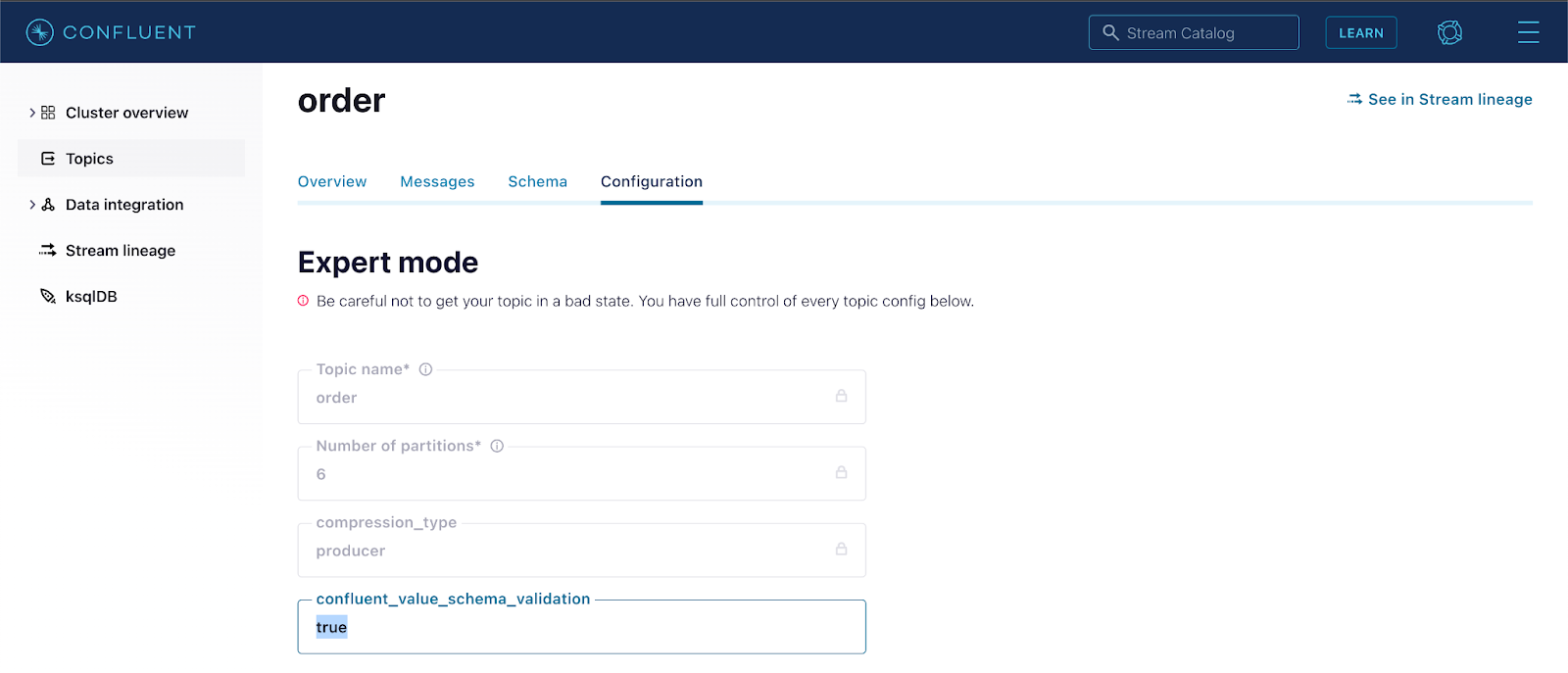
Enable broker-side schema validation on the topic order using the Confluent UI (Topic → Configuration → Switch to expert mode → confluent_value_schema_validation → true).
Moreover, we’ve made extensive refinements and performed benchmark testing across different scenarios to make sure this validation does not negatively impact cluster performance. Our test results show a minor ~3-4% performance overhead on the cluster, a small price to pay for the assurance and trust that the data coming in is high quality, and not “garbage” that can end up taking down a system.
Conclusion
We’ve covered two features for Confluent’s Stream Quality: Schema Registry and Schema Validation. Together, both provide a powerful set of tools for ensuring a high standard of streaming data quality within your Kafka architecture. Having a single source for defining your data structures for your streaming data allows your organization to seamlessly exchange & validate data between services. Importantly, as your data evolves, you don’t have to worry about your services and applications breaking down due to schema disparities.
If you are not already using our Stream Quality features, you can get started by signing up for a free trial of Confluent Cloud. For new customers, use the promo code CL60BLOG for an additional $60 of free Confluent Cloud usage.*
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...