[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Stream Processing Made Easy With Confluent Cloud and KSQL
Confluent Cloud™ is a fully-managed streaming data service based on open-source Apache Kafka. With Confluent Cloud, developers can accelerate building mission-critical streaming applications based on a single source of truth. Liberated from the operational burden of managing their own Kafka clusters, they can easily deploy a single cloud cluster or a solution that spans multiple cloud providers and on-premises deployments.
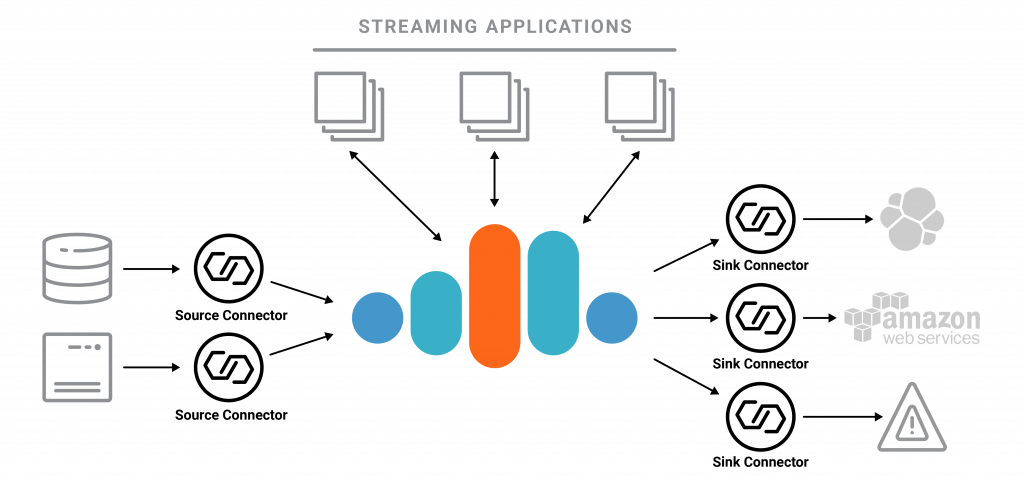
In our white paper, Stream Processing Made Easy with Confluent Cloud and KSQL, we discuss how to design, configure, and manage your streaming applications with Confluent Cloud. The paper covers the following:
- Apache Kafka in the Cloud
- Launching a Confluent Cloud Cluster
- Management and Monitoring with Confluent Control Center
- Stream Processing with KSQL
- KSQL User Interface
- Monitoring KSQL Performance
- Data Governance with Confluent Schema Registry
- Getting Data Into and Out of Confluent Cloud
- Connecting External Data Systems
- Transferring Kafka data from other Clusters
To see a hybrid deployment in action, run the Confluent Cloud demo, which uses KSQL for stream processing, Confluent Replicator for moving data from on-prem to Confluent Cloud, and Confluent Control Center for monitoring. The demo includes a script that auto-generates the additional component configuration parameters, derived from your Confluent Cloud cluster configuration. You must already have access to a Confluent Cloud cluster to run the demo.
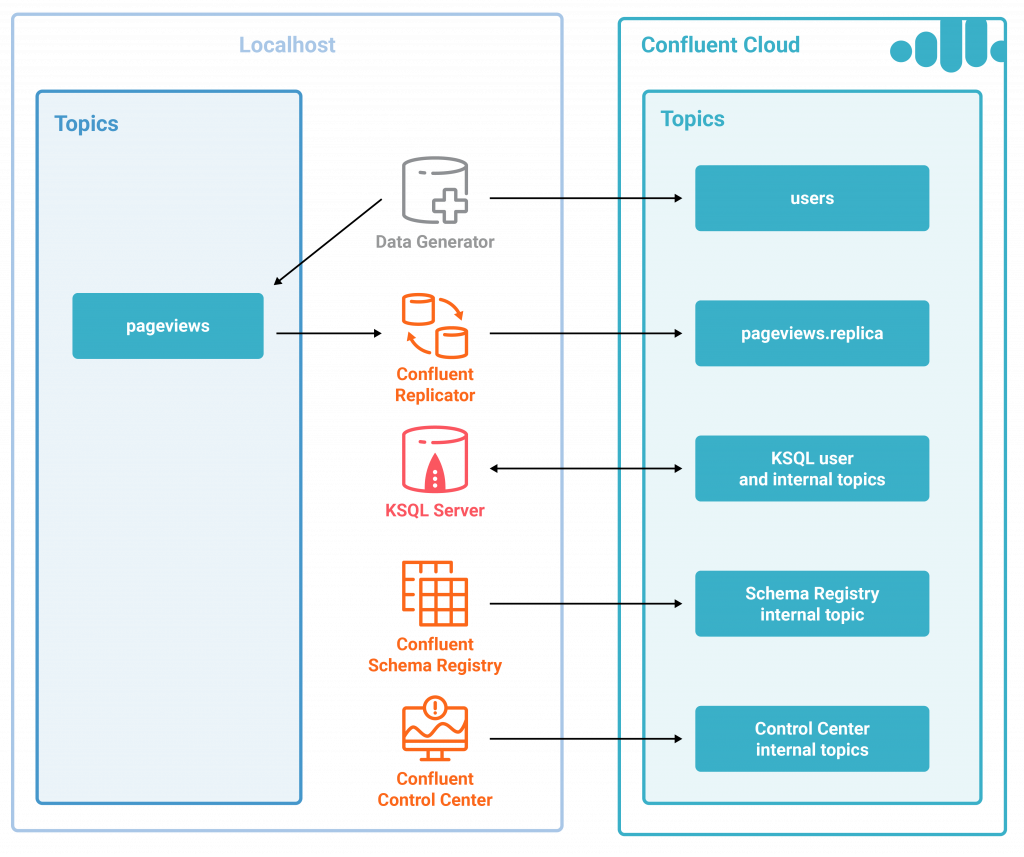
Download the white paper today for a practical guide to deploying an enterprise-ready streaming platform in the cloud.
If you want to know more about Confluent Cloud, check out:
- Visit the Confluent Cloud site
- Watch the Confluent Cloud demo
- Questions? Ask them in the #confluent-cloud channel on our community Slack group
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.