[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Project Metamorphosis Month 7: Reliable Event Streaming with Confluent Cloud and Proactive Support
The rise of the cloud introduced a focus on rapid iteration and agility that is founded on specialization. If you are an application developer, you know your applications better than anyone else in the world and are able to double down on your unique expertise to accelerate feature development and quickly respond to user feedback. Managed services allow you to focus on the application and assume that every other part of the stack just works.
As applications capture and process customer and business events that directly impact the experience of customers, Apache Kafka® is an increasingly important backbone to application architectures. Guaranteed low-latency and high-availability service delivery are essential to any event-based, context-sensitive application and, that’s why, in this month’s Project Metamorphosis theme, Reliable, we’re highlighting how Confluent Cloud and Proactive Support for Confluent Platform makes your deployments, well for lack of a better word, reliable.
Why fully managed Kafka is more reliable
When purchasing any fully-managed service, the first question often is, “What is the SLA?” which is a completely valid concern. You need to know the service will be up and working as it’s supposed to. However, for Confluent, reliability means more than uptime—it means knowing the services are performant, have the latest features, and meet the expectations of your business at any given moment.
Of course, we promise uptime for our fully managed service—Confluent Cloud has an uptime SLA of 99.95% with Standard and Dedicated clusters. But, more importantly, you don’t need to understand internal complexities of the service such as request queues and replica fetchers. Instead, you can know with certainty that if your application stays within the limits set out for your deployment, then your Confluent Cloud deployment will both be up and performant.
Beyond the operational performance of a service, reliability also means being there for those of you who want to try the latest and greatest features of that service. You don’t buy a fully-managed streaming service so that you can run a version of Kafka from last year that some vendor has deemed to be stable because it has been out long enough that other users have hit the bugs. Confluent Cloud picks up the latest bug fixes with constant upgrades and also deploys the leading edge versions of all services with established delivery guarantees that you can count on being reliable. With fully managed Kafka from Confluent Cloud, clear limits help keep performance smooth; you can focus on applications instead of operational complexity, and you are always getting the latest features and bug fixes.
Bringing a cloud-native support experience to self-managed Kafka
We’re excited to announce the launch of Proactive Support for Confluent Platform. Proactive Support runs continuous, real-time analysis of cluster metadata that alerts you to issues or potential problems with clusters before they happen and provides Confluent support engineers with critical context about your Kafka environment. In Confluent Platform 6.0, we started this journey to bring the level of reliability that we established in Confluent Cloud to those of you who choose to self-manage Confluent software. We released the Confluent Telemetry Reporter to enable Confluent Platform services to send metadata back to Confluent and be processed in the same data infrastructure that we use to keep Confluent Cloud running smoothly, which powers Proactive Support.
You keep the payload data in your topics in your environment and continue managing your deployment, as you see fit, with complete control. Your deployment sends its metadata back to Confluent over HTTPS, and we analyze that data to identify problems or make suggestions. Then, we categorize what we find in that analysis and notify you via Slack, email, or a webhook integration—whatever fits into your day-to-day operations seamlessly. Each notification you get is aimed at avoiding larger downtime or data loss by helping identify small issues before they become bigger problems.
This connection goes deeper than analysis rules and notifications when it’s time to chat with the Confluent Support team. By enabling this telemetry, we have a real-time view of performance for your Confluent Platform deployment. You no longer need to tell us about what versions are running or which topics are suddenly busy. We already have that context from the metadata that your deployment is sending, allowing us to focus on the issue at hand instead of spending time building up a picture of your environment.
This cloud-native support experience helps you speed up issue identification and resolution in your self-managed Confluent environments, allowing you to focus on streaming events instead of figuring out the best ways to work with support.
Context and Kafka experience matter
In order to meet the SLA and ensure reliability, the two most important aspects are context and experience. Context provides information about the environment and behavior that allows a support team to address issues immediately versus coming in cold to fix a problem. This results in faster problem mitigation and root cause analysis.
Let’s start with why context is important. You may need to know things like why does my Kafka cluster have under-replicated partitions that won’t go away? Why is the latency for my Kafka producer so high? Why is my consumer lag growing? These are some of the issues that we deal with every single day. Without proper context, it could feel like trying to find a needle in a haystack. By looking at a subset of hundreds of Kafka metrics, server logs, and command outputs, we can make decisions, and more importantly fast decisions that mitigate and ultimately resolve the problem using root cause analysis.
Of course, without experience in the technology, the context may not be very useful. When it comes to Apache Kafka, Confluent is in a unique position to provide world class support. Our founders were the original co-creators of Kafka and our team consists of twenty-two Kafka committers. Plus, with Confluent Cloud, our global team operates some of the largest use cases in Kafka and solves problems across thousands of clusters every week. In short, we’ve seen pretty much everything.
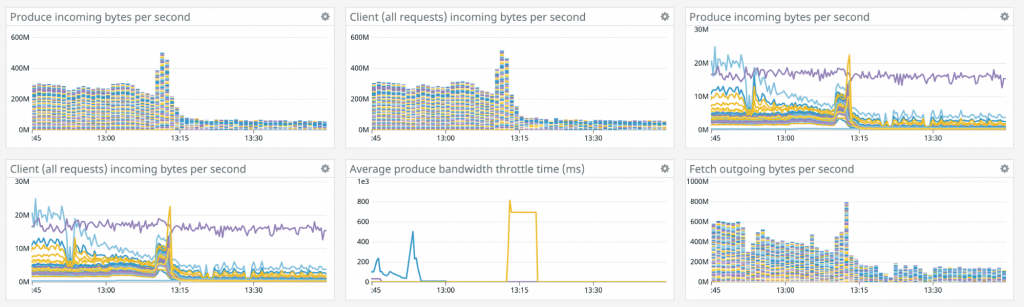
Here’s an example of what happens when you marry context and Kafka experience together. Back in late 2017, transactions were introduced in Kafka. The Confluent Cloud team currently monitors a Kafka metric in order to detect hung transactions. This is the Kafka server metric:
kafka.server:type=ReplicaManager,name=MaxLastStableOffsetLag
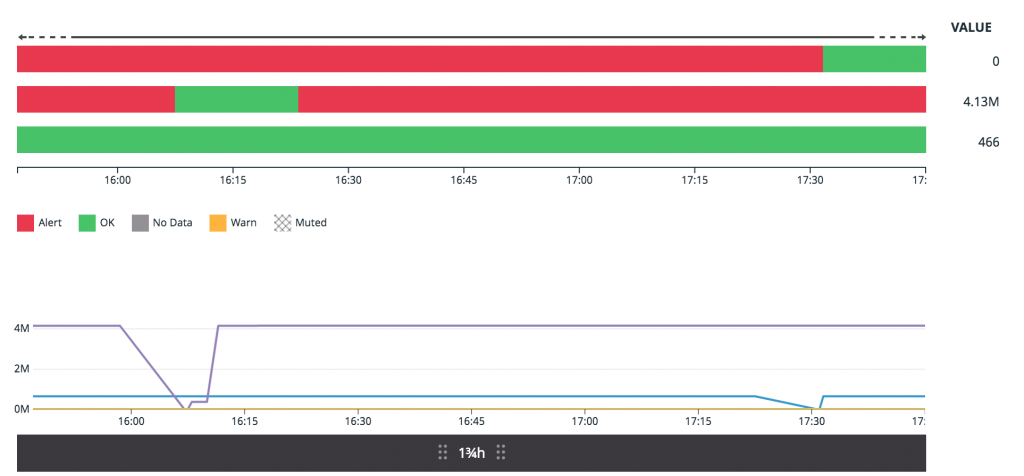
Why is this important? On the occasion that a transaction hangs for any reason, the Confluent Support team can proactively reach out and inform you that we have hit an issue with this cluster. A hung transaction can lead to high consumer lag, as the consumer can no longer make progress. It can also lead to failure of compaction of data for compacted topics, which can lead to disk space growing without bounds. We all know what happens if you fill up disk space on your broker. Monitoring this metric enables us to start an investigation in case it is triggered.
Next, we have mitigation with in-house tools and root cause analysis to ensure that hung transactions are prevented in the future. In fact, earlier this year, this came to the rescue with one of our Confluent Cloud customers as we were able to address and mitigate the issue within a couple of hours. The iteration of solving such problems gives the platform reliability, which is essential for running Kafka as a service.
In addition, we continue to improve the reliability as we proceed to innovate. Every high-impact problem we uncover results in review and improvement of the product. For example, the next steps on the hung transaction problem are already being discussed in KIP-664.
In summary, we believe two things are critical to world-class operational management of large-scale and mission-critical workloads. The first is rich environmental context for each cluster, and the second is deep Kafka experience.
Reliable event streaming for all
With Confluent Cloud and Proactive Support, we’re making Kafka reliable for organizations of all sizes and all deployment types. We know the journey is never complete. As new features and use cases arise, we will be there to tweak, patch, and advise in real time on the best way to keep your event streams flowing.
To learn more:
- Watch this demo featuring cloud-native reliability in Confluent Platform with Proactive Support
- Download Confluent Platform 6.0 to get started with Proactive Support
- See the Reliable page dedicated to this announcement
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...