[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Real-Time Small Business Intelligence with ksqlDB
If you’re like me, you may be accustomed to reading articles about event streaming that are framed by large organizations and mountains of data. We’ve read about how the event streaming juggernaut Netflix uses Apache Kafka® to make sense of the viewing habits of 167 million subscribers, and understand how best to allocate a production budget measured in billions of dollars. We’ve learned how Deutsche Bahn manages passenger data for over 5 million passengers every day, across 24,000 unique services. Kafka’s ability to reliably scale and handle workloads of these magnitudes is the reason why these big companies use it.
But what if your business operates on a more typical scale? What if you’re a small-sized or medium-sized enterprise with data, and have a desire to do more with it—can you make use of Kafka? Will the costs and infrastructure requirements overwhelm your budget and small team, taking them away from the important work they’re already doing? Can the sophistication of a tool designed to handle millions of events every day be harnessed by an organization that only generates a few hundred, or should you stick to spreadsheet formulae and point-in-time data extracts?
Confluent’s new kid on the block, ksqlDB, is designed to allow organizations of any size to build event streaming pipelines with minimal infrastructure and code, using a language that is intuitive and familiar to almost anyone with experience in relational databases. We’ll look at one such use case with an online pharmacy, and see how it took its transactional data and turned it into something of greater value.
The situation: An online store, with a twist
The company that undertook this project has a business model similar to that of many modern internet-based companies. It runs an online store, selling several thousand unique products sourced from multiple brands, and it ships these products to customers around the world. The store keeps track of stock on hand and manages product prices (including taxes) and various shipping methods that are available at different costs. Orders can be made up of many products and are recorded in the customer’s ordering history. So far, so good, right?
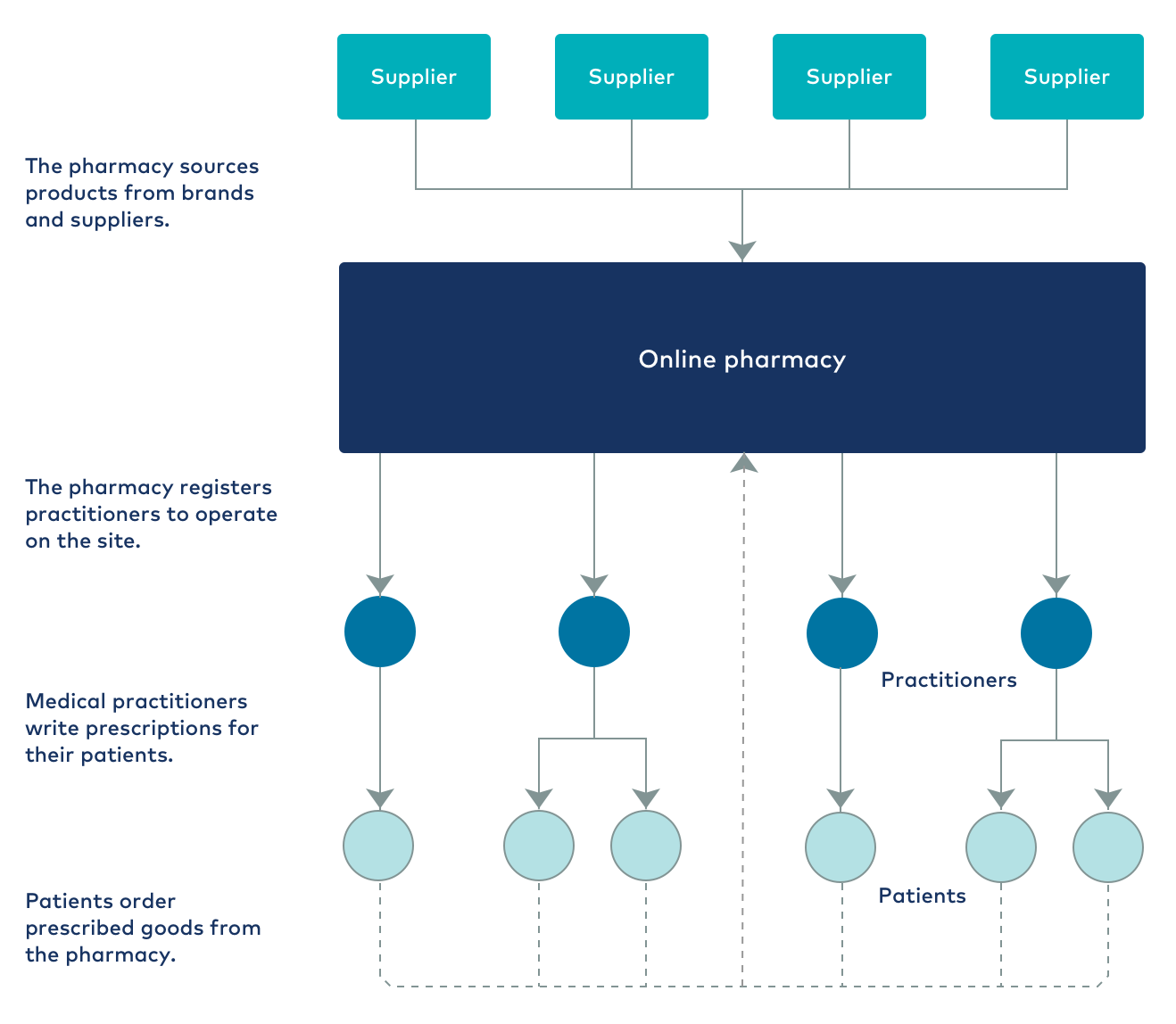
But the nature of the products differ within this online store. While some products are generally available, others are only sold under prescription from a registered practitioner. These practitioners exist as largely autonomous entities in the online store and are responsible for managing their patients, including generating prescriptions for them. A prescription is usually for a fixed quantity of a product and comes with an expiration date, after which another prescription is required. A practitioner can also offer patients a discount on purchased products, in effect acting as their own “mini business” within the greater online store. The layers of complexity are starting to add up.
As a business dealing in medical products, the company also has a legal imperative to properly handle the personally identifiable information (PII) data from the online store. It must strictly maintain customer confidentiality.
So our use case has a few features that set it apart from the traditional online store. But in reality, this isn’t uncommon—most companies have features that are specific to their industry or area of business, and these must be accounted for in any project. Luckily, ksqlDB is well suited to handle this kind of bespoke complexity without losing sight of the core objective: improved business intelligence.
The reality: Lots of data, not much insight
Online stores tend to generate a lot of data, especially when they take on roles and manage business processes other than handling orders. In this case, the starting point is a dataset containing:
- Patient data: contact and shipping details, assigned practitioner, assigned discount, favorite products
- Practitioner data: type of practice, modalities, professional certifications, registrations
- Prescriptions: date of issue, period of validity, products prescribed, repeats, dosage instructions
- Orders: date of order, products ordered (including sizes and quantities), prices, taxes, shipping method, costs
- Products: available stock, wholesale and recommended retail price (RRP) prices, sizes, availability (general or practitioner only)
- Brands: products available, restrictions on supply
- Shipping methods: cost, weight and value limits, vouchers
In the past, the company has tried to properly make sense of this data using the tried and tested Swiss Army knife of businesses: Excel. Though this can quickly get a business up and running with some useful metrics, it doesn’t scale well for a number of reasons:
- You must manually export data from its source into something Excel can work with (usually CSV). If you need data that lives in multiple places within your transactional system, you’ll need to write queries that join across multiple tables (in the case of a relational database), or even write an export process if the source is more complex. As your requirements or data source structure change over time, you’ll need to maintain this process as well.
- Your data manipulations are restricted by the capabilities of Excel and its formulas. Excel can be sufficient for simple aggregating and statistical manipulations, but it doesn’t offer the kind of adaptable toolset that many businesses require to truly get value from their data.
- The data is static. Once you’ve exported the data, you’ve actually made a copy that can only reflect the state of things at that point in time. Many businesses today need to understand and respond to events in real time, but unless you spend time continuously updating your exported data (or risk introducing the dreaded “ETL (extract, transform, load) is running” slowdown by implementing an automated, scheduled export), spreadsheets aren’t a viable path to real-time insights.
The ideal: What would improved business intelligence look like?
To begin with, the business wanted answers to some common questions, such as:
- Which brands and products are performing best?
- Are customers satisfied with their experience and making repeat orders?
- Are sales and revenue trending in the right direction?
But this company’s online store is also different in that patients are really buying from their registered practitioner; it is the practitioner that decides which products to prescribe to a patient, under what conditions, and how much of a discount should be given on their orders. The store actually operates on two levels, and that means digging deeper to understand the state of the business:
- Do practitioners of a certain type perform better on the site?
- Do specific practitioners and brands perform well together, while others don’t?
- For practitioners, what is the discounting sweet spot that maximizes orders, where further discounting brings reduced returns?
Finally, the company wanted to answer some complex questions about the state of the business, which its existing spreadsheet-based analysis couldn’t handle:
- If a patient receives a prescription for several products, does the patient order all of them, or only some?
- Does a prescription tend to be filled all at once, or over a period of time?
- What is the real sales impact of the changes the company makes to the site?
This kind of information is ideal for supporting a test-and-measure mindset, but it only works when supported by real-time feedback and a set of tools with the power to properly transform the data.
The solution: ksqlDB
In our use case, ksqlDB is compelling as the backbone of our business intelligence platform based on three main factors:
- The system is event-driven, and the results are delivered in real time. Modern, data-driven businesses simply cannot afford to make their decisions based on old data, nor do they want to be saddled with the additional workload of ETL.
- No additional burden is added to existing systems. ksqlDB now has its own built-in connectors, but it still integrates fully with the broader Kafka ecosystem, which means it’s right at home processing data collected by other components. In this case, we use Kafka Connect and the Debezium MySQL CDC Connector to stream data changes from the source database into Kafka as they occur, which requires nothing more than enabling binary logs on the MySQL database powering the online store (a good practice even if you aren’t using Kafka).
- The platform is extendable. The company in question decided to outsource the building of this project to a consultancy in order to gain access to the right level of Kafka-related expertise. The infrastructure and event streaming pipeline they were delivered is one that can be easily accessed, understood, and adapted by another team or consultancy in the future. At its core, the entire business logic of a ksqlDB pipeline is encapsulated in a single .ksql queries file, rather than a complex framework-based project that could require thousands of support files.
- Bonus feature: the creation of new data! It might sound strange, but because it operates in an event-driven manner and can reason about the state of data as each event happens, ksqlDB is actually capable of creating new data that the source database does not have. For this company, the source system did not record a history of discounts given to a patient—they may have a discount of 10% today, but that could have been 8% last week and 5% the week before. When trying to assess the impact of discounting, this kind of historical data can be of significant value. ksqlDB allows you to capture the latest discount at the point in time that each order occurs, which it can record and deliver onto another system (or back into Kafka) for closer analysis.
The implementation: Streams and tables
A full outline of all streams and tables created for this project is beyond the scope of this article, so we’ll instead focus on the code used to answer one of the company’s more pressing questions, and see how easy it is to handle the complexity of that using ksqlDB’s featureset.
What is the impact of discounting when looking at average order value?
With de-identified patient data arriving via the Debezium CDC connector into the source topic USERS_SRC:
Name: USERS_SRC Field | Type ------------------------------------------------------------------- ROWTIME | BIGINT (system) ROWKEY | VARCHAR(STRING) (system) ID | BIGINT PRACTITIONER_ID | BIGINT CLINIC_ID | BIGINT PRACTITIONER_DISCOUNT | DOUBLE REGISTER_DATE | BIGINT -------------------------------------------------------------------
We can reduce this to just the fields that are relevant to our question in the derived stream USERS:
CREATE STREAM USERS WITH (VALUE_FORMAT='AVRO', PARTITIONS=3, REPLICAS=3) AS SELECT CAST(ID AS VARCHAR) AS ID, CAST(PRACTITIONER_ID AS VARCHAR) AS PRACTITIONER_ID, TIMESTAMPTOSTRING(REGISTER_DATE, 'yyyy-MM-dd HH:mm:ss') AS REGISTER_DATE, PRACTITIONER_DISCOUNT FROM USERS_SRC PARTITION BY ID;
Then we can turn this into a table to give us the latest state of any user when joining to the table:
CREATE TABLE USERS WITH (KAFKA_TOPIC='USERS_SRC', VALUE_FORMAT='AVRO', KEY='ID');
Order data is delivered in a similar way from Debezium into ORDERS_SRC:
Name: ORDERS_SRC Field | Type ----------------------------------------------------- ROWTIME | BIGINT (system) ROWKEY | VARCHAR(STRING) (system) ID | BIGINT USER_ID | BIGINT PRACTITIONER_ID | BIGINT CLINIC_ID | BIGINT TRANSACTION_ID | VARCHAR(STRING) AMOUNT_TOTAL | DOUBLE AMOUNT_SUBTOTAL | DOUBLE
So let’s reduce that to only what we need and partition it for joining to the users table:
CREATE STREAM ORDERS WITH (VALUE_FORMAT='AVRO', PARTITIONS=3, REPLICAS=3) AS SELECT CAST(ID AS VARCHAR) AS ORDER_ID, DATE AS EVENT_TS, CAST(USER_ID AS VARCHAR) AS PATIENT_ID, CAST(PRACTITIONER_ID AS VARCHAR) AS PRACTITIONER_ID, CAST(CLINIC_ID AS VARCHAR) AS CLINIC_ID, TIMESTAMPTOSTRING(DATE, 'yyyy-MM-dd HH:mm:ss') AS ORDER_DATE, AMOUNT_TOTAL FROM ORDERS_SRC PARTITION BY PATIENT_ID;
Now, let’s enrich the orders with the patient data that we’re most interested in, their assigned discount:
CREATE STREAM ORDERS_ENRICHED WITH (VALUE_FORMAT='AVRO', PARTITIONS=3, REPLICAS=3) AS SELECT O.ORDER_ID AS ORDER_ID, O.PATIENT_ID AS PATIENT_ID, O.PRACTITIONER_ID AS PRACTITIONER_ID, O.CLINIC_ID AS CLINIC_ID, O.ORDER_DATE AS ORDER_DATE, O.AMOUNT_TOTAL AS AMOUNT_TOTAL, P.DISCOUNT AS DISCOUNT FROM ORDERS O JOIN USERS P ON O.PATIENT_ID = P.ID
Repartition that stream by order ID, which helps reason about the orders in subsequent streams and tables:
CREATE STREAM ORDERS_BY_ID WITH (VALUE_FORMAT='AVRO', PARTITIONS=3, REPLICAS=3) AS SELECT * FROM ORDERS PARTITION BY ORDER_ID;
Let’s turn that stream into a table to support aggregation:
CREATE TABLE ORDERS_WITH_DISCOUNT WITH (KAFKA_TOPIC='ORDERS_BY_ID', VALUE_FORMAT='AVRO', KEY='ORDER_ID');
Calculate the average order value per unique discount value:
CREATE TABLE AVG_ORDER_VALUE_BY_DISCOUNT AS SELECT DISCOUNT, ROUND(AVG(AMOUNT_TOTAL), 2) AS AVG_ORDER_VALUE FROM ORDERS_WITH_DISCOUNT GROUP BY DISCOUNT;
This gives us a high-level, real-time view of the average value of orders at different degrees of discounting:
+-----------------------------------------------+--------------------------------------+ |ROWTIME |DISCOUNT |AVG_ORDER_VALUE | +-----------------------------------------------+--------------------------------------+ |1580921043000 |-4.0 |91.64 | |1581615972000 |-5.0 |126.24 | |1581619970000 |-6.0 |151.54 | |1580987564000 |-7.0 |121.94 | |1581263574000 |-8.0 |148.89 | |1581011841000 |-9.0 |148.99 | |1581627574000 |-10.0 |129.44 | |1580381414000 |-11.0 |169.77 | |1581605818000 |-12.0 |148.73 | |1579627567000 |-13.0 |168.62 | |1581490185000 |-14.0 |146.12 | |1581620261000 |-15.0 |134.31 |
Immediately, we can see that the average value of an order experiences its greatest jump when moving from a 5% to 6% discount, and again when moving from 10% to 11%. There is probably an element of human psychology at play here—5% and 10% are both fairly “conventional” in terms of a discount, but moving even 1% beyond that makes the discount feel more significant. In working with its practitioners, the company can now advise them that these two, slightly non-conventional figures represent the greatest return on the discounts they give, and that higher levels of discounting do not necessarily correlate with greater average order values.
While this is a somewhat simplified example (there might be other influencing factors to investigate), the great thing about ksqlDB is that digging deeper from here is straightforward and efficient. If we want to look at how the discount impacts order value over time (year on year for, example), we just adjust the ORDERS declaration to bring in the year:
CREATE STREAM ORDERS AS SELECT ..., TIMESTAMPTOSTRING(DATE, 'yyyy') AS ORDER_YEAR, AMOUNT_TOTAL FROM ORDERS_SRC PARTITION BY PATIENT_ID;
Include that as part of the SELECT statement in ORDERS_ENRICHED, and then group on the year and discount in the output table:
CREATE TABLE AVG_ORDER_VALUE_BY_DISCOUNT_PER_YEAR AS SELECT DISCOUNT, ORDER_YEAR, ROUND(AVG(AMOUNT_TOTAL), 2) AS AVG_ORDER_VALUE FROM ORDERS_WITH_DISCOUNT GROUP BY DISCOUNT, ORDER_YEAR;
This kind of extendable, reusable architecture is one of the great things about ksqlDB. We don’t need to go back to scratch to adjust the output; we can incrementally update as our areas of focus and available data evolve.
Of course, this new intelligence is still in its raw Kafka form and is not that compelling for a presentation or showcase. But that’s really just another advantage of the platform—it generates output without any specific visualization app or storage engine in mind. Set up the appropriate connector, and you can sink out the data to wherever you wish, all from within ksqlDB. The client is currently assessing a number of third-party products for this role, including Tableau and Google Data Studio.
The payoff: Better context and decision making
We can see that by using a transactional dataset the company already has, some ksqlDB/Kafka expertise, and a curious mind, it’s possible to:
- Answer difficult questions about different aspects of the business that manual shuffling of data in Excel can’t hope to match
- Establish new metrics for performance that can go beyond just total sales and orders
- Provide a means to test and evaluate the impact of new ideas on the business, by looking at the changes to key metrics over time
- Develop an extendable platform that can be easily reconfigured to answer new questions or work with new data sources without requiring new infrastructure
Improved business intelligence shouldn’t be limited to large-scale, international companies with in-house analytics teams. ksqlDB is an agile and easily adapted framework that can offer the same level of insight to small and medium-sized businesses alike, in any kind of industry. The knowledge required to make better decisions is already contained within your data. ksqlDB provides the means to deliver it.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



3 Strategies for Achieving Data Efficiency in Modern Organizations
The efficient management of exponentially growing data is achieved with a multipronged approach based around left-shifted (early-in-the-pipeline) governance and stream processing.



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.