[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
No More Silos: How to Integrate Your Databases with Apache Kafka and CDC
One of the most frequent questions and topics that I see come up on community resources such as StackOverflow, the Confluent Platform mailing list, and the Confluent Community Slack group, is getting data from a database into Apache Kafka®, and vice versa. Often it’s Oracle, SQL Server, DB2, etc—but regardless of the actual technology, the options for doing it are broadly the same. In this post we’ll look at each of those options and discuss the considerations around each. It may be obvious to readers, but it’s worth restating anyway: since this is Kafka—a streaming platform—we are talking about streaming integration of data, not just bulk static copies of the data.
Databases? How Twentieth Century…
Before we dive too deeply into this, bear in mind that you don’t always need a database. If you’re wanting to ingest data from a database into Kafka, how did that data get into the database in the first place? Would it be better to instead ingest the data from the original source directly into Kafka itself? If you’re streaming data from Kafka into a database, why are you landing it to a database? Is it to integrate with another system that’s consuming the data? Would that other system be better ingesting the data from Kafka instead? It’s important to challenge assumptions about how systems are built, as Kafka introduces what we refer to in the trade as a paradigm shift that we need to leverage. Why introduce a database into an architecture if we could use a streaming platform such as Kafka instead? Kafka persists data, Kafka can process and transform data with the Kafka Streams API and KSQL too. Sometimes you need a database; but not always. For more insight on this, check out these articles:
- Martin Kleppman – Turning the database inside-out
- Jay Kreps – The Log: What every software engineer should know about real-time data’s unifying abstraction
- Ben Stopford – Leveraging the Power of a Database ‘Unbundled’
So anyway…assuming we’ve decided that we do indeed need a database, let’s look first at how we can get data from a database into Apache Kafka.
The two options to consider are using the JDBC connector for Kafka Connect, or using a log-based Change Data Capture (CDC) tool which integrates with Kafka Connect. If you’re considering doing something different, make sure you understand the reason for doing it, as the above are the two standard patterns generally followed – and for good reasons.
Kafka Connect
The Kafka Connect API is a core component of Apache Kafka, introduced in version 0.9. It provides scalable and resilient integration between Kafka and other systems.
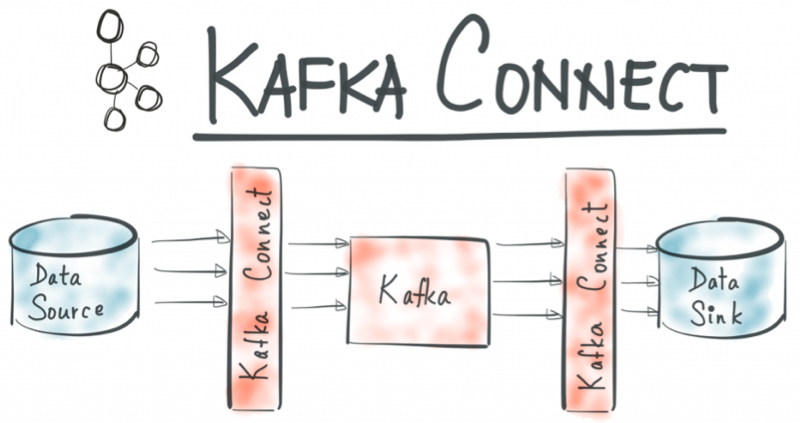
It is driven purely by configuration files, providing an easy integration point for developers.
{
"name": "jdbc_source_mysql_foobar_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/demo?user=rmoff&password=rmoff",
"table.whitelist": "foobar",
"mode": "incrementing",
"incrementing.column.name": "foobar_pk"
}
}
Kafka Connect can be run as a clustered process across multiple nodes, and handles all the tricky business of integration, including:
- Scaleout of ingest and egress across nodes for greater throughput
- Automatic restart and failover of tasks in the event of node failure
- Automatic offset management
- Automatic preservation of source data schema
- Utilisation of data’s schema to create target objects (e.g. Hive tables when streaming to HDFS, RDBMS tables when streaming to a database)
- Schema evolution and compatibility support (in conjunction with the Confluent Schema Registry)
- Automatic serialisation and deserialisation of data
- Single Message Transformations
- Exactly once processing semantics (on supported connectors)
To use Kafka Connect you simply need a plugin that integrates with the technology that you’re interested in. The Confluent Platform ships with several of these plugins, including JDBC, HDFS, Elasticsearch, and S3. You can find dozens more plugins for Kafka Connect here.
JDBC plugin for Kafka Connect
The Confluent JDBC Connector for Kafka Connect enables you to stream data to and from Kafka and any RDBMS that supports JDBC (which is to say pretty much any). It can stream entire schemas or just individual tables. It can pull the entire contents (bulk), or do an incremental fetch of data that’s changed since the last poll using a numeric key column, an update timestamp, or both.
It’s a super-easy way to get started with streaming data into Kafka from databases. You can see an example of it in action in this article, streaming data from MySQL into Kafka. Also check out the quickstart and the full documentation. The JDBC Connector also gives you a way to stream data from Kafka into a database—see details and examples in the quickstart here.
Because the JDBC Connector uses the Kafka Connect API, it has several great features when it comes to streaming data from databases into Kafka:
- Configuration-only interface for developers—no coding!
- Schemas
- The source database schema is preserved for use downstream in consuming Kafka applications
- When streaming data from Kafka to a database, the connector will use the schema to execute the necessary DDL on the target to create the destination objects before streaming data to them
- Kafka Connect can scale out the number of tasks to increase the throughput. For example, it can ingest data from multiple tables in parallel. Just make sure you don’t flatten your database with too many concurrent requests!
- Database-specific dialects (in progress)
So the JDBC Connector is a great start, and is good for prototyping, for streaming smaller tables into Kafka, and streaming Kafka topics into a relational database. But (and there’s always a but!) here are some considerations to bear in mind:
- The connector works by executing a query, over JDBC, against the source database. It does this to pull in all rows (bulk) or those that changed since previously (incremental). This query is executed at the interval defined in poll.interval.ms. Depending on the volumes of data involved, the physical database design (indexing, etc.), and other workload on the database, this may not prove to be the most scalable option.
- If you want to use the connector for incremental streaming of data, you need to be able to identify changed rows. This means either an incrementing ID column, and/or a column with a timestamp indicating the last change. If these don’t exist then it can be difficult to get them added unless you own the schema for the source data. Sometimes data comes from “blackbox” applications in which you literally cannot change the tables. Other times the data belongs to another team who won’t entertain making a change to their application.
- The JDBC Connector cannot fetch deleted rows. Because, how do you query for data that doesn’t exist? Depending on why you’re integrating the database with Kafka, deleted records may be required (for example, event-driven services which need to know when an entity no longer exists).
- There are of course workarounds, some more elegant than others. One example is that espoused by Bjöprn Rost and Stewart Bryson (video / slides), using Oracle’s Flashback feature to actually detect deletes.
- Other options I can imagine people proposing involve some kind of TRIGGER and a table, replicating in effect log-driven Change Data Capture, which we are going to discuss below.
- My caution would be that any home brew solution has got to be both scalable and supported. A PoC is one thing, but a deployment to production quite another.
So the JDBC connector is definitely the best place to get started with integrating databases and Kafka. But, particularly for streaming data from a database into Kafka, we sometimes need a better option.
Log-based Change-Data-Capture (CDC) tools and Kafka
If you want to go “the whole hog” with integrating your database with Kafka, then log-based Change-Data-Capture (CDC) is the route to go. Done properly, CDC basically enables you to stream every single event from a database into Kafka. Broadly put, relational databases use a transaction log (also called a binlog or redo log depending on DB flavour), to which every event in the database is written. Update a row, insert a row, delete a row – it all goes to the database’s transaction log. CDC tools generally work by utilising this transaction log to extract at very low latency and low impact the events that are occurring on the database (or a schema/table within it).
Many CDC tools exist, serving a broad range of sources. Some specialise in broad coverage of source systems, others in just specific ones. The common factor uniting most of them is close integration with Apache Kafka and Confluent Platform. Being able to stream your data from a database not only into Kafka, but with support for things such as the preservation of schemas through the Schema Registry, is a defining factor of these CDC tools. Some are built using the Kafka Connect framework itself (and tend to offer a richer degree of integration), whilst others use the Kafka Producer API in conjunction with support for the Schema Registry, etc.
CDC tools with support from the vendor and integration with Confluent Platform are (as of March 2018):
You can read more about CDC & Kafka in action at these articles:
- Streaming data from Oracle using Oracle GoldenGate and the Connect API in Kafka
- KSQL in Action: Real-Time Streaming ETL from Oracle Transactional Data
- Streaming databases in realtime with MySQL, Debezium, and Kafka
So what’s the catch with CDC? There isn’t one, per se. CDC is low impact, low latency, and gives you full data fidelity. There are a few reasons why you may not use a CDC tool when integrating a database with Kafka, at least to start with:
- CDC tools are more complex than the straightforward JDBC connector.
- This complexity may well be worth it given your requirements, but be aware that you are adding more moving parts to your overall solution.
- For rapid prototyping CDC can be overkill (and the JDBC connector fits well here)
- More complex to set up at first, because of the nature of the integration with the relatively low level log files
- Often requires administration access to the database for initial setup—can be a speedbump to rapid prototyping
- Cost considerations: many CDC tools are commercial offerings (typically those that work with proprietary sources).
Conclusion
My general steer on CDC vs JDBC is that JDBC is great for prototyping, and fine low-volume workloads. Things to consider if using the JDBC connector:
- Doesn’t give true CDC (capture delete records, want before/after record versions)
- Latency in detecting new events
- Impact of polling the source database continually (and balancing this with the desired latency)
- Unless you’re doing a bulk pull from a table, you need to have an ID and/or timestamp that you can use to spot new records. If you don’t own the schema, this becomes a problem.
Also bear in mind what your requirements are for the data. Are you wanting to simply stream data from the database so that you can use it in a traditional analytics/ETL sense? Or are you building event-driven applications? The former gives you more leeway on how you implement. The latter almost certainly necessitates a log-based CDC approach, because you need not only every event (rather than just the state at an arbitrary point in time), and you also need delete events.
For analytics and ETL, streaming data in from a database is a powerful way to integrate existing systems with Kafka. The great thing is that because Apache Kafka decouples sources and targets, you can easily switch one out for another. For example, an iterative development could look like :
- Stream data from database into Kafka using JDBC Connector – prove the value of the data being in Kafka in realtime to drive applications and requirements. Typically done as a prototype/sandbox/skunk-works project.
- Once proven out, more formally adopt the source of data into Kafka, and consider the use of CDC. Existing consuming applications and targets stay untouched, because the data is still the same (just being streamed into Kafka using a different method)
Interested in Learning More?
If you’d like to learn more about the Confluent Platform, here are some resources for you:
- Check out the support for Kafka Connect in the Confluent Platform
- To process and analyze data in Kafka after you’ve ingested it with Connect, check out KSQL
- Learn about ksqlDB, the successor to KSQL
Join us for a 3-part online talk series for the ins and outs behind how KSQL works, and learn how to use it effectively to perform monitoring, security and anomaly detection, online data integration, application development, streaming ETL, and more.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


