[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Let Flink Cook: Mastering Real-Time Retrieval-Augmented Generation (RAG) with Flink
Commercial and open source large language models (LLMs) are evolving rapidly, enabling developers to create innovative generative AI-powered business applications. However, transitioning from prototype to production requires integrating accurate, real-time, domain-specific data tailored to your business needs and deploying at scale with robust security measures.
The reliance on static pre-trained data, which can quickly become outdated, can lead to inaccuracies and “hallucinations.” Additionally, LLMs often struggle with understanding and integrating domain-specific knowledge, which is critical for generating contextually relevant and precise responses.
As a result, there is a growing need for methods that can provide real-time, context-specific data to enhance the performance and reliability of generative AI systems. This is where retrieval-augmented generation (RAG) comes into play, offering a promising solution by integrating live data streams with AI models to ensure accuracy and relevance in generated outputs.
This blog discusses how you can use Apache Kafka® and Apache Flink® in Confluent Cloud to build a RAG-enabled Q&A chatbot that uses real-time airline data.
RAG as a grounding technique
Before digging into the use case, it is important to note that RAG is not the only solution for grounding language models with business relevant data. You can also take the more traditional approach of fine-tuning, although that comes with the following disadvantages:
Fine-tuning requires a curated training dataset which may not be easily available.
Fine-tuning can result in inaccurate results if the dataset quickly becomes out of date.
Fine-tuning can be more compute resource-intensive compared to RAG.
Fine-tuning requires very specific skill sets or domain knowledge which further increases the cost of building and maintaining such a system.
Models have a tendency to forget old information upon learning new information with fine-tuning—a phenomenon called “catastrophic forgetting” that is extremely hard to determine or control.
Fine-tuning can still be useful in areas like branding and creative writing where the output requires adhering to a specific tone or style.
Okay, back to the RAG-enabled chatbot.
RAG explained
Think of building a RAG-based AI system as preparing a meal using your unique ingredients and specialized tools. Your data, both structured and unstructured, are like the fresh ingredients that you feed into a food processor—your LLM—based on a carefully crafted recipe, or in this case, the system prompts. The power and capacity of the food processor depend on the scale and complexity of the dish you're preparing. But the real magic happens with the chef who oversees it all—this is where data orchestration comes into play. In real-time AI systems, Flink takes on the role of the chef, orchestrating every step, with Kafka serving as the chef’s table, ensuring everything is prepared and delivered seamlessly.
In order to build a RAG-based AI system like a chatbot, there are two important patterns that should be followed:
Data preparation: Similar to how the ingredients need to be cleaned, chopped, and arranged before cooking, data needs to be prepared before feeding into a knowledge base.
Inference: Just as a chef combines the ingredients using various tools, an orchestrator connects relevant context with each prompt and sends it to an LLM to generate a response.
Let’s see how Confluent Cloud for Apache Flink’s AI features help you with these patterns and more.
Using Flink for RAG
Confluent offers a complete data streaming platform built on the most efficient storage engine, 120+ source and sink connectors, and a powerful stream processing engine in Flink. With the latest features in Flink SQL that introduce models as first-class citizens, on par with tables and functions, you can simplify AI development by using familiar SQL syntax to work directly with LLMs and other AI models.
New predefined functions like ml_predict() and federated_search() in Flink SQL allow you to orchestrate a data processing pipeline in Flink while seamlessly integrating inference and search capabilities.
Let’s look at each of the steps involved in detail.
Step 1: Data preparation
A chatbot that answers customer questions like “Can you help me find my lost baggage?” and “How much is a business class ticket on the next available flight?” needs intelligence on a wide variety of data such as:
Customer identity and current bookings
Pricing information and airline change policies
Airline luggage policy documents
Customer service logs and tickets
The effectiveness of such an AI assistant depends on how well it can understand the context of a natural language query and yield relevant, trustworthy results in real time.
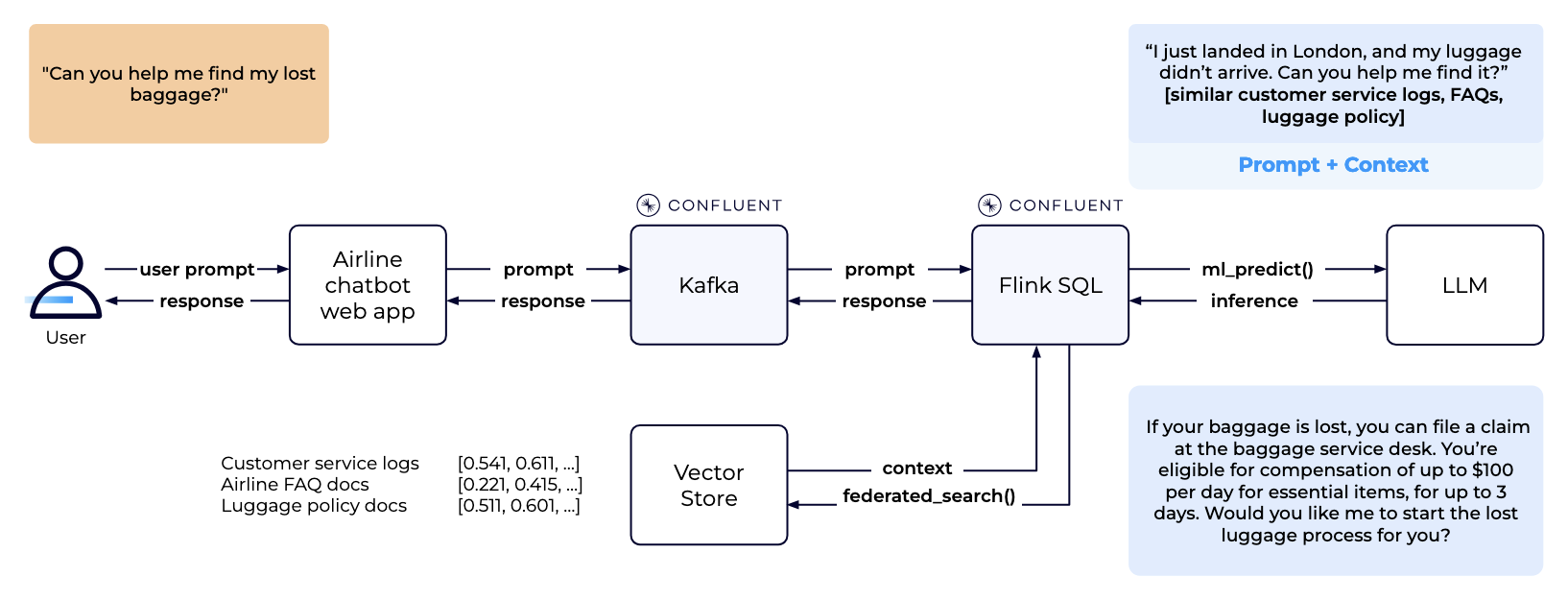
To achieve this, you need to ingest unstructured data from the above sources, break it down into smaller pieces (chunking), convert it into vector embeddings, and store the embeddings into a vector store. Vector embeddings are numeric representations of data and related context. The “related context” is at the heart of any RAG-based application. The following diagram shows how you can build a real-time pipeline in Confluent Cloud to achieve this:
If you’re thinking, “Does this really need to be a real-time, event-based pipeline?” The answer, of course, depends on the use case, but fresh data is almost always better than stale data.
You can set up a pipeline for embedding creation in Flink by simply writing a few lines of SQL:
Step 2: Inference
Now that your vector store is continuously hydrated with private business data, you can use it to retrieve the relevant context and augment your prompt on the fly before sending it to an LLM for inference. The generated response from the LLM can then simply be streamed back to the web application. The following diagram shows RAG in action in Confluent Cloud:
You might be wondering, “Why Flink+Kafka?” It’s a valid question because there are dozens of tools out there that can help you orchestrate RAG workflows. Real-time systems based on event-driven architecture and technologies like Kafka and Flink have been built and scaled successfully across industries. Real-time AI systems can take advantage of the same pattern.
Moreover, a data streaming platform like Confluent allows you to completely decouple the architecture, standardize your schemas for downstream compatibility, and enable in-flight stream processing, combining any stream from anywhere for an enriched view of your data in real time. This is critical as you move from proofs of concept to enterprise applications. As a bonus, you get out-of-the-box data lineage and governance integration.
If you want to build a simple RAG-enabled Q&A chatbot, congratulations! You just learned how you can use Flink SQL to prepare your data and retrieve it for GenAI applications. However, if your goal is to build an AI assistant capable of more, read on.
Advanced RAG: reasoning & workflows
It is a well-documented fact that LLMs struggle with complex logical reasoning and multistep problem-solving. Therefore, you need to enable your AI application to break a single natural language query into composable multipart logical queries or generate domain-specific data in a way that is more likely to yield a complete answer using a different pattern like HyDE or a knowledge graph. Then, you need to ensure the information is available to the end user in real time.
Using Flink Table API, you can write Python applications with predefined functions (UDFs) that can help you with reasoning and calling external APIs, thereby streamlining application workflows.
Moreover, Flink, with its powerful state management capabilities, allows you to manage memory (session history in the case of an AI assistant) that can augment LLMs which are typically stateless.
Ensuring AI reliability: post-processing in RAG systems
Most enterprise AI assistants need a final step called post-processing in a RAG system that performs sanity checks and other safeguards on the LLM response. This is another great opportunity for an event-driven pattern. A separate Flink job decoupled from the inference workflow can be used to do a price validation or a lost luggage compensation policy check, for example.
Let’s see how this all comes together in Confluent Cloud:
Conclusion
With AI model inference in Flink SQL, Confluent allows you to simplify the development and deployment of RAG-enabled GenAI applications by providing a unified platform for both data processing and AI tasks. By tapping into real-time, high-quality, and trustworthy data streams, you can augment the LLM with proprietary and domain-specific data using the RAG pattern and enable your LLM to deliver the most reliable, accurate responses.
To see this in action, watch the RAG tutorial for a step-by-step walkthrough of using Flink for vector encoding and how to keep a vector database like MongoDB Atlas continuously updated with real-time information. For additional resources, visit the GenAI hub.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Why Is My Apache Flink® Job Not Producing Results?
An Apache Flink® job not producing results often indicates an issue with watermarks, which are necessary for handling out-of-order message processing in time-based aggregations from Kafka. Watermarks balance data loss and latency by defining how long to wait for late messages. Incorrectly setting...


{kind=link}

The AI Silo Problem: How Data Streaming Can Unify Enterprise AI Agents
Salesforce has Agentforce, Google launched Agentspace, and Snowflake recently announced Cortex Agents. But there’s a problem: They don’t talk to each other…