[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
The Curious Incident of the State Store in Recovery in ksqlDB
When operating cloud infrastructure, “time is money” is more than a cliché—it is interpreted literally as every processing second stacks up on the monthly bill. ksqlDB strives to reduce these costs for users with various optimizations, but sometimes those same measures end up costing more.
For example, on June 16, 2020, the Confluent Cloud orchestrator relocated a ksqlDB node that was running out of memory. While this is a somewhat routine occurrence, and something that ksqlDB was built to tolerate, this specific cluster was unable to restart; a perfect storm of events caused the previously successful queries to fail! To understand the root cause and how the issue was identified, this blog post takes a step back to examine parts of the ecosystem that power ksqlDB.
State stores and changelog topics
A topic in ksqlDB can be interpreted as either a STREAM or TABLE. A TABLE needs to be materialized locally on the computing node in order to efficiently look up the most recent entry for a key without scanning the Apache Kafka® topic. To help illustrate, consider the following motivating stream-table join, which requires looking up the corresponding row in the table for each event in the stream:
CREATE TABLE users (userID INT PRIMARY KEY, username VARCHAR); CREATE STREAM logins (userID INT, logInTime BIGINT, ip VARCHAR); CREATE STREAM enriched_logins AS SELECT logins.*, users.username FROM logins JOIN users ON users.userID = logins.userID;
In ksqlDB, tables are materialized into RocksDB stores on the computing node to provide fast and memory-efficient key lookups. Each time a query processes an event from the source table, it will serialize the event into the format required and upserts it into RocksDB. Next, when it receives an event from the source stream, it looks for the value in the materialized store instead of scanning the topic.
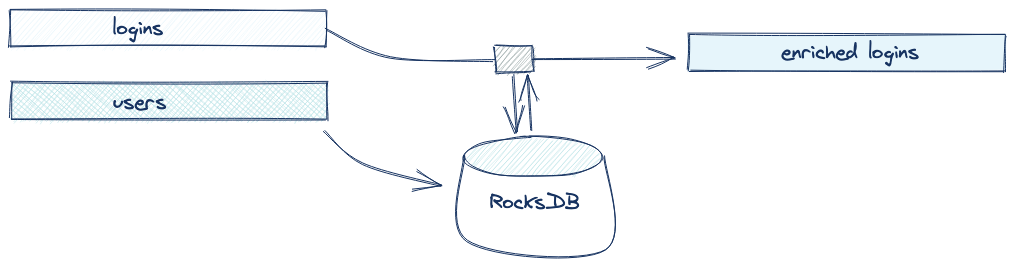
The RocksDB store is replicated by ksqlDB using a mechanism called changelog topics. These topics are used to restore the local state in the event that a new node comes online (or an old one is physically relocated). A changelog topic is a log compacted, internal topic to ksqlDB that contains every change to the local state store; the key and value for events in the changelog topic are byte for byte the same as the most recent matching key and value in the RocksDB store. Leveraging this topic makes recovery simple: You can scan the changelog topic and put each Kafka message directly into the state store without any additional processing.
Connecting theory to action
Much of the data that flows through the Kafka ecosystem is encoded using the Avro data format. Unlike JSON and other schemaless formats, Avro requires a schema to deserialize and serialize raw bytes. Managing schemas requires more than just mapping topics to schemas—consumers and producers need to coordinate on schema evolution and maintain versioned schemas. To make life easier, ksqlDB delegates this tough task to Schema Registry.
Schema Registry supplies a custom Avro SerDe suite, which prepends the schema ID to each record that it serializes. This way, any deserializer can fetch the corresponding schema from the registry at runtime and producers can dynamically register new schemas as their topic evolves.
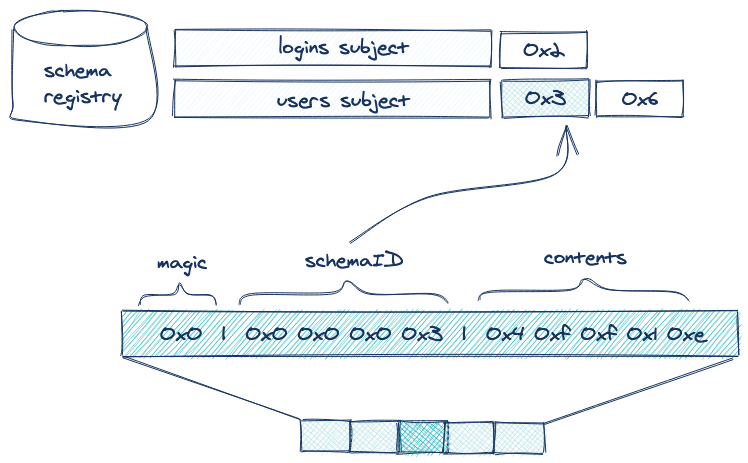
These schema IDs are organized under subjects and versions. While an ID is a unique identifier across a deployment of Schema Registry, subjects allow you to group IDs together. Each time a schema is registered to a subject, that schema is given an ID (reused if the schema has ever been registered under a different subject) and a version (an incrementing number relative to the subject it is being registered under). Generally, schemas under the same subject are often compatible to some degree, so fetching a schema by subject and ID is often safer than just by ID.
The curious incident
What does Schema Registry have to do with changelog topics and state stores? Before the ksqlDB instance was relocated, queries could successfully process new events, but during the incident, the team noted the following deserialization exception (modified for readability):
Failed to deserialize data for topic CSAS_J_0-Reduce-changelog to Avro: Error retrieving Avro value schema version for id 3
There are a few things to dissect from this error message:
- The stack trace showed MeteredKeyValueStore.get(MeteredKeyValueStore.java:133), which corresponds to a state store lookup
- The data in the state store must have had bytes that were serialized with schema ID 3
- The deserializer was using the CSAS_J_0-Reduce-changelog topic to determine the subject in Schema Registry
Now, these three points don’t add up. ID 3 was registered under the subject for the source topic, not the changelog subject that the deserializer indicated. Additionally, the queries were able to access the state store before the node was relocated, so the contents must have changed after recovering the data in changelog topic…
Aha!
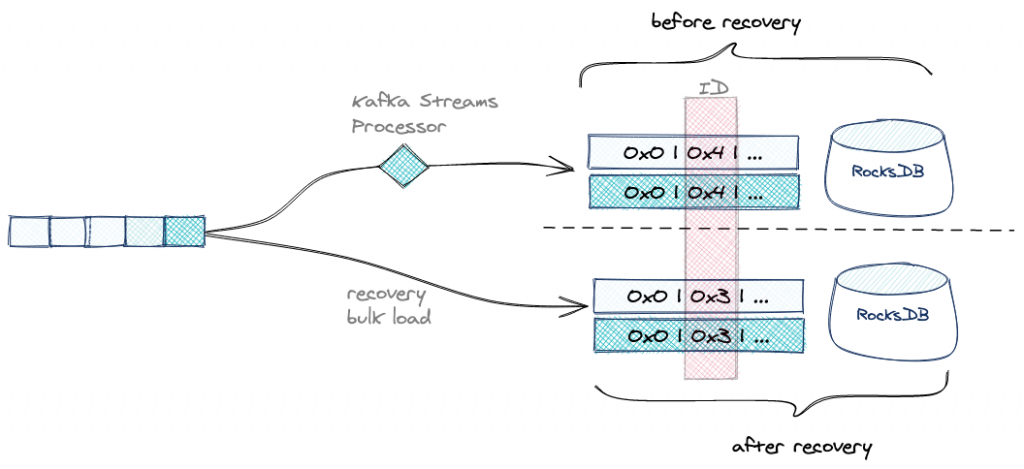
But there shouldn’t be any changelog topic in Kafka for this query—this detail brings the other pieces together.
There is a time-saving optimization implemented in Kafka Streams that avoids the changelog topic if the data in the source topic is exactly the same as the data that is being serialized into the state store.
And therein lies the bug: When the optimization is enabled, the topic name that is passed to the serializer should be the source topic, but instead the changelog topic name was passed as if there was a dedicated changelog topic (for more information, see KAFKA-10179).
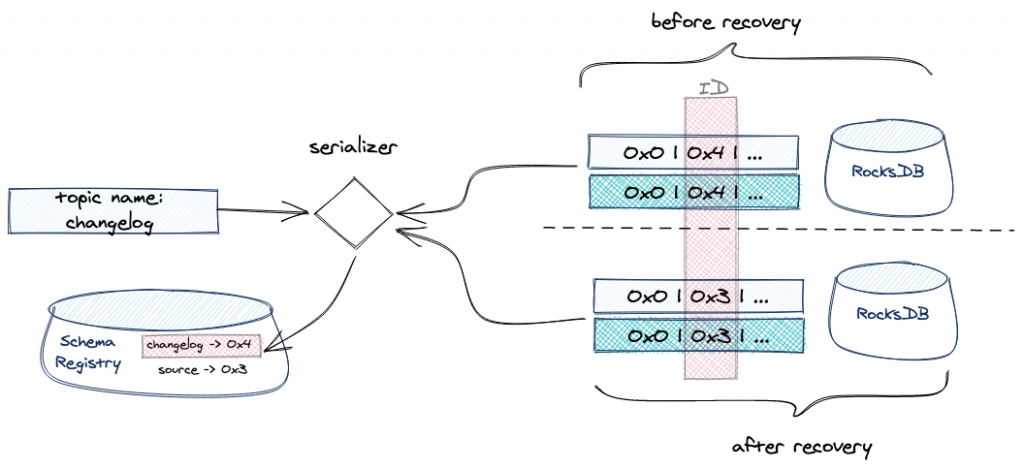
During standard operation, events are deserialized to be piped through the topology before being reserialized and put into the state store. Since the SerDe that ksqlDB uses is case insensitive and allows queries to declare only a subset of the fields, it requires a different schema from the original data. When the data was deserialized and subsequently reserialized, the output was not the same as the input; it had a different schema and therefore a different schema ID—and it was that ID (not ID 3 from above), which was being written into the state store. During serialization, this schema was registered under the phantom CSAS_J_0-Reduce-changelog-value subject that was generated from the (incorrect) topic name that was passed to it.
During recovery, the events don’t go through the round-trip SerDe described above. Instead, the data from the topic is directly plopped into the state store with schema ID 3 alongside the raw bytes. Later, when trying to read from the state store, ksqlDB cannot find the schema ID under the changelog subject because it was never registered there.
Fighting fire
A simple solution can remedy the query and the corrupted state store: Register the schema ID 3 under the changelog subject and the data will be readable using Schema Registry deserializers.
But what if this incident happens again? How can ksqlDB prevent a node relocation from causing this every time?
A myopic view of the problem would suggest an easy fix: Pass the right topic name into the SerDe and you’re good to go! Unfortunately, as is often the case with complex systems, this fix is not sufficient. Recall these two details:
- A schema ID is unique to a schema and is reused if the same schema is uploaded to multiple subjects
- Looking at the subject for the phantom changelog topic, the schema is nearly but not exactly identical to schema 3
If the schema that was used to produce the data to the source topic is identical to the schema that wrote data into the state store, it will register schema 3 into the changelog subject to begin with, masking the problem of a missing ID.
Why aren’t the schema identical? ksqlDB leverages a generated custom schema for each source that is registered to implement a case-insensitive wrapper on top of case-sensitive serialization formats such as Avro and JSON. Since Schema Registry serializers expect the ID to precede the serialized data, ksqlDB registers this schema and uses it when serializing events.
This detail introduces a new layer of complexity: ksqlDB needs to register its internal schema somewhere, and that somewhere shouldn’t be the user’s original topic’s subject.
Band-Aids and the future
The first-aid response is to disable the optimization for any new queries, but that won’t work for existing queries. If you disable it for existing queries, when you restart them, they will look for a non-existent changelog topic and bootstrap with an empty state store (even though they should have a state store with all the contents of the source topic).
Instead, we’ve implemented a patch that will help automatically resolve this in the future. Whenever ksqlDB identifies that a query is running into an issue reading from a state store and that the changelog topic doesn’t exist, it tries to deserialize the row under both subjects: the original and the phantom changelog subject.
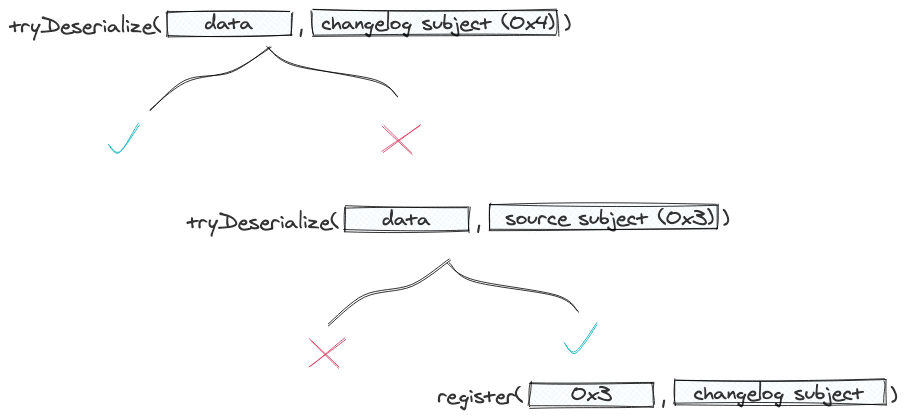
What’s next? Going forward, ksqlDB’s roadmap includes various changes that will improve the integration with Confluent Schema Registry and will grant the end-user more flexibility with the way it registers schemas.
Ready to check ksqlDB out? Head over to ksqldb.io to get started, where you can follow the quick start, read the docs, and learn more!
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.