CREATE DATABASE demo;
USE demo;
DROP TABLE customers;
CREATE TABLE customers (
id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
gender VARCHAR(50),
comments VARCHAR(90)
);
[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
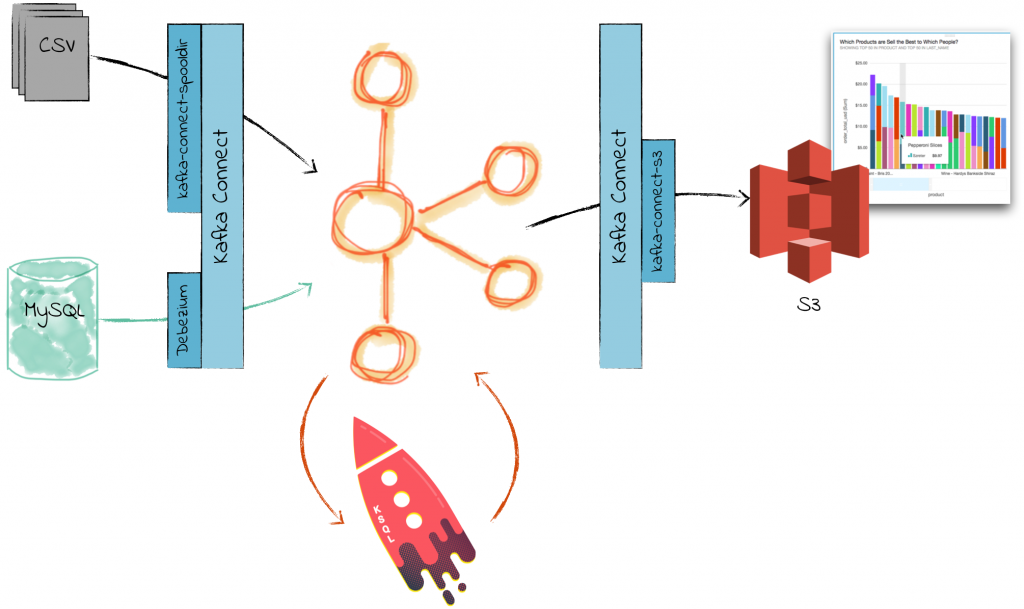
KSQL in Action: Enriching CSV Events with Data from RDBMS into AWS
Life would be simple if data lived in one place: one single solitary database to rule them all. Anything that needed to be joined to anything could be with a simple SQL JOIN command. But…back in the real world, we have myriad systems scattered across a landscape of log files, NoSQL, RDBMS, CSV, VSAM, IMS and more. What fun, what joy! Long live data silos? Well, no. Not anymore. With Apache Kafka® and KSQL we can integrate data from anywhere, in realtime, and transform it with filters, joins, and aggregations in-flight.
In this article we’ll see how we can take an event and enrich it in realtime. We’ll look up attributes relating to the events from data originating in a database. If you’re from a database or analytics background, we’re basically talking good ole’ denormalization—resolving foreign key relationships.
Our source data is CSV files with order data, and relational data about the customers who have placed these orders. We’ll join these together, and then stream the results to a datastore from where we can run some analyses against them.
Set up Customer Data in MySQL
For our customer data, we’re going to use the excellent Mockaroo to generate some data records with a simple schema.
Whilst Mockaroo can also generate the necessary CREATE TABLE DDL, I’m including it separately here. This is because you need to amend it to declare a Primary Key (PK). If you don’t, the compacted topic will cause Kafka Connect to throw an error Got error produce response with correlation id 2538 on topic-partition asgard.demo.customers-0, retrying (2147483156 attempts left). Error: CORRUPT_MESSAGE.
Run this DDL to create the table in MySQL:
Now populate it with the Mockeroo output:
curl -s "https://api.mockaroo.com/api/94201080?count=1000&key=ff7856d0" | mysql demo -uroot
(this assumes that you’ve signed up for a Mockaroo account to get access to the API; if not just download the .sql file from Mockaroo’s web UI and pipe it into MySQL instead)
Check the data has been created in MySQL:
mysql> select * from demo.customers limit 1;
+----+------------+-----------+----------------------------+--------+-----------------------------+
| id | first_name | last_name | email | gender | comments |
+----+------------+-----------+----------------------------+--------+-----------------------------+
| 1 | Kania | Eggleson | keggleson0@tripadvisor.com | Female | Multi-channelled web-enable |
+----+------------+-----------+----------------------------+--------+-----------------------------+
1 row in set (0.00 sec)mysql> select count() from demo.customers; +----------+ | count() | +----------+ | 1000 | +----------+ 1 row in set (0.00 sec)
mysql>
Stream customer data from MySQL to Kafka
We’re going to use Debezium to stream the contents of the customers table, plus any changes as they occur, from MySQL into Kafka. Instead of a normal Kafka topic with standard retention policies, we’re going to use a compacted topic. We want to work with customer information not a stream of events per se, but instead as the value (name, email, etc) per key(in this case, customer id).
Create the topic, and set it as compacted:
$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic asgard.demo.customers
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "asgard.demo.customers".
$
$ kafka-configs --zookeeper localhost:2181 --entity-type topics --entity-name asgard.demo.customers --alter --add-config cleanup.policy=compact
Completed Updating config for entity: topic 'asgard.demo.customers'.
(The topic naming is set by Debezium, and is based on <server>.<database>.<table>)
Now set up the Kafka Connect Debezium connector. This will stream the current contents of the table into Kafka, and then use MySQL’s binlog to track any subsequent changes to the table’s data (including deletes) and stream those to Kafka too.
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/ \
-d '{
"name": "mysql-demo-customers",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "42",
"database.server.name": "asgard",
"table.whitelist": "demo.customers",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "dbhistory.demo" ,
"include.schema.changes": "true",
"transforms": "unwrap,InsertTopic,InsertSourceDetails",
"transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
"transforms.InsertTopic.type":"org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.InsertTopic.topic.field":"messagetopic",
"transforms.InsertSourceDetails.type":"org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.InsertSourceDetails.static.field":"messagesource",
"transforms.InsertSourceDetails.static.value":"Debezium CDC from MySQL on asgard"
}
}'
Check the status of the connector:
$ curl -s "http://localhost:8083/connectors"| jq '.[]'| xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
mysql-connector | RUNNING | RUNNING
If it’s not RUNNING then check the Connect stdout for errors.
Now let’s check that the topic has been populated:
$ kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic asgard.demo.customers \
--from-beginning --max-messages 1| jq '.'
{
"id": 1,
"first_name": {
"string": "Kania"
},
"last_name": {
"string": "Eggleson"
},
"email": {
"string": "keggleson0@tripadvisor.com"
},
"gender": {
"string": "Female"
},
"comments": {
"string": "Multi-channelled web-enabled ability"
},
"messagetopic": {
"string": "asgard.demo.customers"
},
"messagesource": {
"string": "Debezium CDC from MySQL on asgard"
}
}
We can also see the Change-Data-Capture (CDC) in action. Run the kafka-avro-console-consumer command from above, but without the --max-messages 1—you’ll get the contents of the topic, and then it will sit there, waiting for new messages. In a separate terminal, connect to MySQL and make a change to the data:
mysql> update demo.customers set first_name='Bob2' where id = 1;
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql>
You should see almost instantaneously the changed record appear in the Kafka topic.
Streaming CSV data into Kafka
Data comes in all sorts of shapes and sizes, from a few bytes of Avro to hundreds of megabytes of XML files, and more. And for better or worse, CSV files are still used as a common interchange format of data, despite a lack of declared schema and difficult to parse field separators. But the great news about Apache Kafka is that with Kafka Connect you can integrate data from lots of sources—even CSV!
To stream CSV data into Kafka we can use the kafka-connect-spooldir plugin. This monitors a folder for a given pattern of file, and processes them, streaming the rows into Kafka and applying the supplied schema. It supports CSV, TSV, and JSON data. Note that it is only suitable for files that are complete; if the file is still being written to by another process then it wouldn’t be appropriate to use this.
To get the plugin simply clone the GitHub repository and build the code. This is done using Maven—download it first if you don’t have it.
git clone https://github.com/jcustenborder/kafka-connect-spooldir.git
cd kafka-connect-spooldir
mvn clean package
Having built the plugin, add it to the Kafka Connect worker’s configuration. Locate the plugin.path configuration entry and add /full/path/to/kafka-connect-spooldir/target/kafka-connect-target/usr/share/kafka-connect/ to the list of paths.
Create three folders: one for the source data, one where the files will be placed once processed, and one for any files in error. Here I’m using /tmp—for real-world use you would amend this to your own path.
mkdir /tmp/source
mkdir /tmp/finished
mkdir /tmp/error
We’re using dummy data, again courtesy of Mockeroo. Download some sample CSV files, call them orders<x>.csv (where <x> is a varying suffix) and place them in the source folder. The folders and contents should look like this:
$ ls -l /tmp/source/ /tmp/finished/ /tmp/error/
/tmp/error/:
/tmp/finished/:
/tmp/source/:
total 5224
-rw-r--r--@ 1 Robin staff 440644 9 Feb 22:55 orders.csv
-rw-r--r--@ 1 Robin staff 440644 9 Feb 23:37 orders1.csv
-rw-r--r--@ 1 Robin staff 440644 9 Feb 23:39 orders2.csv
The great thing about the SpoolDir connector is that is applies a schema to the data, ensuring life is happy for those downstream in Kafka wanting to make use of the data. You can enter the schema by hand (and you do know the schema, right?), or you can use a utility that ships with the plugin to automagically determine it. To do this, create a temporary config file (e.g. /tmp/spool_conf.tmp) as follows:
input.path=/tmp/source finished.path=/tmp/finished csv.first.row.as.header=true
Run the utility, specifying the sample input file, and also the field name(s) that is to be the key:
# Run this from the folder in which you built kafka-connect-spooldir
$ export CLASSPATH="$(find target/kafka-connect-target/usr/share/kafka-connect/kafka-connect-spooldir/ -type f -name '*.jar' | tr '\n' ':')"
$ kafka-run-class com.github.jcustenborder.kafka.connect.spooldir.SchemaGenerator -t csv -f /tmp/source/orders.csv -c /tmp/spool_conf.tmp -i order_id
#Configuration was dynamically generated. Please verify before submitting.
#Wed Mar 14 16:01:08 GMT 2018
csv.first.row.as.header=true
value.schema={"name"\:"com.github.jcustenborder.kafka.connect.model.Value","type"\:"STRUCT","isOptional"\:false,"fieldSchemas"\:{"order_id"\:{"type"\:"STRING","isOptional"\:true},"customer_id"\:{"type"\:"STRING","isOptional"\:true},"order_ts"\:{"type"\:"STRING","isOptional"\:true},"product"\:{"type"\:"STRING","isOptional"\:true},"order_total_usd"\:{"type"\:"STRING","isOptional"\:true}}}
input.path=/tmp/source
key.schema={"name"\:"com.github.jcustenborder.kafka.connect.model.Key","type"\:"STRUCT","isOptional"\:false,"fieldSchemas"\:{"order_id"\:{"type"\:"STRING","isOptional"\:true}}}
finished.path=/tmp/finished
Now define the connector. The configuration items are fairly obvious, requiring only a couple of notes:
- The input.file.pattern is a regex based on the filenames within the specified `input.path` (not the entire pathname as you may assume).
- The key.schema and value.schema come from the output of the utility above.
Make sure to escape the quotation marks in the schema correctly in the JSON you send with curl (replace \: with :and replace " with \") (which you can do by piping the above kafka-run-class statement through sed: sed 's/\\:/:/g'|sed 's/\"/\\\"/g').
I’ve also manually changed the STRING to INT64 for the ID columns, and marked all the fields as isOptional=false:
$ curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/ \
-d '{
"name": "csv-source-orders",
"config": {
"tasks.max": "1",
"connector.class": "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector",
"input.file.pattern": "^orders.*.csv$",
"input.path": "/tmp/source",
"finished.path": "/tmp/finished",
"error.path": "/tmp/error",
"halt.on.error": "false",
"topic": "orders",
"value.schema":"{\"name\":\"com.github.jcustenborder.kafka.connect.model.Value\",\"type\":\"STRUCT\",\"isOptional\":false,\"fieldSchemas\":{\"order_id\":{\"type\":\"INT64\",\"isOptional\":false},\"customer_id\":{\"type\":\"INT64\",\"isOptional\":false},\"order_ts\":{\"type\":\"STRING\",\"isOptional\":false},\"product\":{\"type\":\"STRING\",\"isOptional\":false},\"order_total_usd\":{\"type\":\"STRING\",\"isOptional\":false}}}",
"key.schema":"{\"name\":\"com.github.jcustenborder.kafka.connect.model.Key\",\"type\":\"STRUCT\",\"isOptional\":false,\"fieldSchemas\":{\"order_id\":{\"type\":\"INT64\",\"isOptional\":false}}}",
"csv.first.row.as.header": "true"
}
}'
(N.B. this doesn’t handle the timestamp column parsing, instead bringing it in as a VARCHAR)
Check that the connector’s running:
$ curl -s "http://localhost:8083/connectors"| jq '.[]'| xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
csv-source-orders | RUNNING | RUNNING
mysql-demo-customers | RUNNING | RUNNING
Assuming all of that has worked, you should see that all the source files are now in finished:
ls -l /tmp/source/ /tmp/finished/ /tmp/error/
/tmp/error/:
/tmp/finished/:
total 168
-rw-r--r-- 1 Robin wheel 27834 14 Mar 16:00 orders.csv
-rw-r--r-- 1 Robin wheel 27758 14 Mar 16:01 orders1.csv
-rw-r--r-- 1 Robin wheel 27894 14 Mar 16:01 orders2.csv
/tmp/source/:
And then the proof is in the pudding: do we have messages on our Kafka topic?
$ kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--property print.key=true \
--topic orders \
--from-beginning \
--max-messages 1|jq '.'{
"order_id": 1
}
{
"order_id": 1,
"customer_id": 827,
"order_ts": "2018-02-28T04:40:50Z",
"product": "Macaroons - Homestyle Two Bit",
"order_total_usd": "3.30"
}
Yes, we do! \o/
Using KSQL to Enrich CSV data in Kafka
From the KSQL command prompt, we’ll first declare the stream of events (orders), using the Kafka topic populated from the CSV files:
ksql> CREATE STREAM orders WITH (KAFKA_TOPIC='orders',VALUE_FORMAT='avro');
It’s easy to check that we’ve got data—note the use of SET 'auto.offset.reset' = 'earliest'; to tell KSQL to process all data in the topic, rather than the default which to only new data:
ksql> SET 'auto.offset.reset' = 'earliest';
Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
ksql> SELECT * FROM orders LIMIT 1;
1521209173235 | - | 1 | 288 | 2018-03-05T07:30:55Z | Wine - Sherry Dry Sack, William | 1.53
LIMIT reached for the partition.
Query terminated
Now let’s look at the customers. We are going to declare this as a table in KSQL, because it is a set of values for a given key (as opposed to a stream of events, which is what the orders are). But, we need to be careful with the key. Before declaring the object (CREATE TABLE) we can use the PRINT command to inspect the topic:
ksql> PRINT 'asgard.demo.customers' FROM BEGINNING;
Format:AVRO
16/03/18 14:01:27 GMT, +�, {"id": 245, "first_name": "Sergent", "last_name": "Greenmon", "email": "sgreenmon6s@wordpress.com", "gender": "Male", "comments": "Synergized optimizing pricing structure", "messagetopic": "asgard.demo.customers", "messagesource": "Debezium CDC from MySQL on asgard"}
Note the special characters in the record key (the , +�, after the timestamp, before the message payload). This is because the key is actually an Avro key — and KSQL can’t handle Avro keys yet, so blanks it out. We can verify that this is the case by looking at the raw message and its key:
$ kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic asgard.demo.customers --property print.key=true --max-messages=1 --from-beginning
{"id":1} {"id":1,"first_name":{"string":"Kania"},"last_name":{"string":"Eggleson"},"email":{"string":"keggleson0@tripadvisor.com"},"gender":{"string":"Female"},"comments":{"string":"Multi-channelled web-enabled ability"},"messagetopic":{"string":"asgard.demo.customers"},"messagesource":{"string":"Debezium CDC from MySQL on asgard"}}
Processed a total of 1 messages
We could workaround this upstream in the Kafka Connect config (by using "key.converter":"org.apache.kafka.connect.storage.StringConverter" in the configuration), or we could just use KSQL!
ksql> SET 'auto.offset.reset' = 'earliest';
ksql> CREATE STREAM CUSTOMERS_SRC WITH (KAFKA_TOPIC='asgard.demo.customers',VALUE_FORMAT='AVRO');
ksql> CREATE STREAM CUSTOMERS_REKEYED AS SELECT * FROM CUSTOMERS_SRC PARTITION BY ID;
The above statement takes the source topic which is flowing through from MySQL via Debezium, and explicitly partitions it on the supplied key—the ID column. KSQL does this and the resulting topic is keyed as we want, and using a simple String for the key this time:
ksql> PRINT 'CUSTOMERS_REKEYED' FROM BEGINNING;
Format:AVRO
02/03/18 23:48:05 GMT, 5, {"ID": 5, "FIRST_NAME": "Marion", "LAST_NAME": "Micklem", "EMAIL": "mmicklem4@mail.ru", "GENDER": "Male", "COMMENTS": "Reactive clear-thinking functionalities", "MESSAGETOPIC": "asgard.demo.customers", "MESSAGESOURCE": "Debezium CDC from MySQL on asgard"}
Inspect the message—we can’t use kafka-avro-console-consumer because it assumes that the key is also Avro-encoded, which it isn’t this time. Instead, we’ll use the excellent kafkacat tool:
$ kafkacat -C -K: -b localhost:9092 -f 'Key: %k\nValue: %s\n\n' -t CUSTOMERS_REKEYED -c1
Key: 5
Value:
MarionMicklem"mmicklem4@mail.rMaleNReactive clear-thinking functionalities*asgard.demo.customersBDebezium CDC from MySQL on asgard
We can now use the correctly-keyed topic for our KSQL table:
ksql> CREATE TABLE CUSTOMERS WITH (KAFKA_TOPIC='CUSTOMERS_REKEYED', VALUE_FORMAT='AVRO', KEY='ID');
Check that the table’s declared key (ID) matches that of the Kafka message key:
ksql> SELECT ROWKEY,ID FROM CUSTOMERS LIMIT 5;
5 | 5
6 | 6
10 | 10
12 | 12
15 | 15
LIMIT reached for the partition.
Query terminated
Now the bit we’ve all been waiting for…enrich the stream of inbound orders data with customer data from MySQL!
ksql> SELECT O.ORDER_TS, O.PRODUCT, O.ORDER_TOTAL_USD, \
C.ID, C.FIRST_NAME, C.LAST_NAME, C.EMAIL \
FROM ORDERS O \
LEFT OUTER JOIN CUSTOMERS C \
ON O.CUSTOMER_ID = C.ID \
LIMIT 5;
2018-03-13T01:50:53Z | Onions - Spanish | 9.44 | 115 | Alexandr | Willcot | awillcot36@facebook.com
2018-03-04T07:58:10Z | Halibut - Whole, Fresh | 5.11 | 929 | Ulick | Dumberell | udumberellps@ucla.edu
2018-02-09T19:11:15Z | Beef Wellington | 7.33 | 632 | Jennie | McMichell | jmcmichellhj@miitbeian.gov.cn
2018-03-11T15:39:49Z | Chocolate Eclairs | 1.45 | 270 | Margareta | Kerfod | mkerfod7h@nhs.uk
2018-03-04T23:27:04Z | Wine - George Duboeuf Rose | 6.68 | 117 | Duky | Raden | draden38@marketwatch.com
LIMIT reached for the partition.
Query terminated
(I’m using the \ line-continuation character to make it easier to read the KSQL statements, but you can put it all on one line if you want)
We can persist this streaming query with a CREATE STREAM statement:
ksql> CREATE STREAM ORDERS_ENRICHED AS \
SELECT O.ORDER_TS, O.PRODUCT, O.ORDER_TOTAL_USD, \
C.ID, C.FIRST_NAME, C.LAST_NAME, C.EMAIL \
FROM ORDERS O \
LEFT OUTER JOIN CUSTOMERS C \
ON O.CUSTOMER_ID = C.ID \
Message
----------------------------
Stream created and running
----------------------------
This is a continuous query that executes in the background until explicitly terminated by the user. In effect, these are stream processing applications, and all we need to create them is SQL! Here all we’ve done is an enrichment (joining two sets of data), but we could easily add predicates to the data (simply include a WHERE clause), or even aggregations.
You can see which queries are running with the SHOW QUERIES; statement. All queries will pause if the KSQL server stops, and restart automagically when the KSQL server starts again.
The DESCRIBE EXTENDED command can be used to see information about the derived stream such as the one created above. As well as simply the columns involved, we can see information about the underlying topic, and run-time stats such as the number of messages processed and the timestamp of the most recent one.
ksql> DESCRIBE EXTENDED ORDERS_ENRICHED;
Type : STREAM
Key field : O.CUSTOMER_ID
Timestamp field : Not set - using <ROWTIME>
Key format : STRING
Value format : AVRO
Kafka output topic : ORDERS_ENRICHED (partitions: 4, replication: 1)
Field | Type
---------------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
ORDER_TS | VARCHAR(STRING)
PRODUCT | VARCHAR(STRING)
ORDER_TOTAL_USD | VARCHAR(STRING)
ID | INTEGER
FIRST_NAME | VARCHAR(STRING)
LAST_NAME | VARCHAR(STRING)
EMAIL | VARCHAR(STRING)
---------------------------------------------
Queries that write into this STREAM
-----------------------------------
id:CSAS_ORDERS_ENRICHED - CREATE STREAM ORDERS_ENRICHED AS SELECT O.ORDER_TS,O.PRODUCT,O.ORDER_TOTAL_USD,C.ID, C.FIRST_NAME, C.LAST_NAME, C.EMAIL FROM ORDERS O LEFT OUTER JOIN CUSTOMERS C ON O.CUSTOMER_ID = C.ID LIMIT 5;
For query topology and execution plan please run: EXPLAIN <QueryId>
Local runtime statistics
------------------------
messages-per-sec: 15.08 total-messages: 1500 last-message: 14/03/18 16:15:07 GMT
failed-messages: 0 failed-messages-per-sec: 0 last-failed: n/a
(Statistics of the local KSQL server interaction with the Kafka topic ORDERS_ENRICHED)
Underneath every persisted KSQL stream or table query (i.e. CSAS or CTAS) is a Kafka topic. This is just a Kafka topic as any other:
$ kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic ORDERS_ENRICHED --max-messages=1 --from-beginning|jq '.'
{
"ORDER_TS": {
"string": "2018-03-13T01:50:53Z"
},
"PRODUCT": {
"string": "Onions - Spanish"
},
"ORDER_TOTAL_USD": {
"string": "9.44"
},
"ID": {
"int": 115
},
"FIRST_NAME": {
"string": "Alexandr"
},
"LAST_NAME": {
"string": "Willcot"
},
"EMAIL": {
"string": "awillcot36@facebook.com"
}
}
Processed a total of 1 messages
Streaming the Enriched Data to S3 for Visual Analysis
We’ve seen how easy it is to ingest data from multiple sources—whether flat-file or RDBMS—and join it effortlessly. Now let’s see how we can stream it to a target datastore in order to built analytics on it.
S3 is Amazon’s ubiquitous object store, used extremely widely for both long-term storage of data for analytics, as well as operational data files. Confluent Platform ships with a Kafka Connect connector for S3, meaning that any data that is in Kafka can be easily streamed to S3. The connector supports exactly-once delivery semantics, as well as useful features such as customisable partitioning.
To set up the S3 connector you just need your bucket name, region, and your AWS access keys that have permission to write to the bucket. You can make the credentials available to the connector in several ways, the simplest being to set the required environment variables before launching the Connect worker.
export AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX
export AWS_SECRET_ACCESS_KEY=YYYYYYYYY/YYYYYYYYY
Restart the Connect worker to pick up the new environment variables:
confluent local stop connect
confluent local start connect
Now create the connector:
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/ \
-d '{
"name": "s3-sink-orders",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"tasks.max": "1",
"topics": "ORDERS_ENRICHED",
"s3.region": "us-east-2",
"s3.bucket.name": "rmoff-demo-orders-02",
"s3.part.size": "5242880",
"flush.size": "3",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"schema.compatibility": "NONE"
}
}'
One thing to note is that we’re using "key.converter":"org.apache.kafka.connect.storage.StringConverter", because the messages that KSQL is writing are not keyed with Avro, but String. Without this override Kafka Connect will use the default worker settings (which in my case are Avro), and the task will fail with a org.apache.kafka.connect.errors.DataException, and error detail Error deserializing Avro message for id -1 Unknown magic byte!.
Check that the connector’s running:
$ curl -s "http://localhost:8083/connectors"| jq '.[]'| xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
csv-source-orders | RUNNING | RUNNING
mysql-demo-customers | RUNNING | RUNNING
s3-sink-orders | RUNNING | RUNNING
Go to S3 and you’ll see the files now exist! You can use the web GUI, or the aws cli:
$ aws s3 ls rmoff-demo-orders-02/topics/ORDERS_ENRICHED/partition=0/
2018-03-16 15:14:31 878 ORDERS_ENRICHED+0+0000000000.avro
2018-03-16 15:14:32 891 ORDERS_ENRICHED+0+0000000003.avro
2018-03-16 15:14:32 882 ORDERS_ENRICHED+0+0000000006.avro
2018-03-16 15:14:33 897 ORDERS_ENRICHED+0+0000000009.avro
2018-03-16 15:14:34 893 ORDERS_ENRICHED+0+0000000012.avro
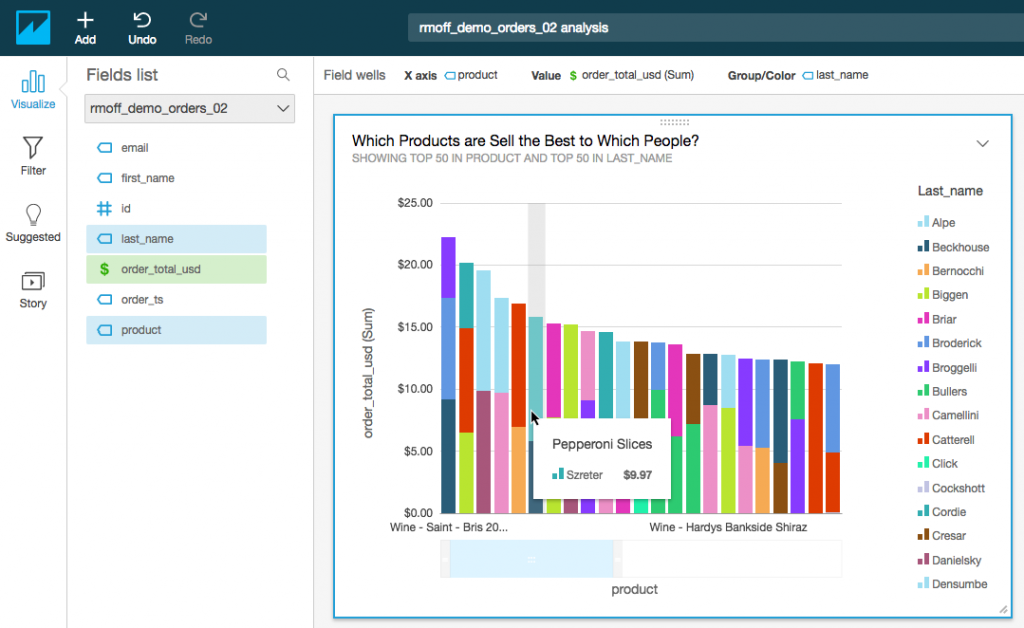
People use S3 for a variety of reasons, and being able to stream data into it from Kafka via the Kafka Connect S3 connector is really useful. In this example here we can take the data, and use AWS’s Quicksight to do some analytical visualisation on top of it, first exposing the data via Athena and auto-discovered using Glue.
Summary
Apache Kafka and KSQL make for a powerful toolset for integrating and enriching data from one or more sources. All that’s needed is configuration files and SQL—not a single line of code was written in creating this article! Kafka Connect makes it easy to ingest data from numerous sources, as well as stream data from Kafka topics to many different targets.
Itching to get started with KSQL and see what it can do?
- Get started with KSQL to process and analyze your company’s data in real-time
- Learn about ksqlDB, the successor to KSQL, and see the latest syntax
To read more about building streaming data pipelines with Apache Kafka and KSQL, check out the following articles:
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.