[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Kafka Streams’ Take on Watermarks and Triggers
Back in May 2017, we laid out why we believe that Kafka Streams is better off without a concept of watermarks or triggers, and instead opts for a continuous refinement model. This article explains how we are fundamentally sticking with this model, while also opening the door for use cases that are incompatible with continuous refinement.
By continuous refinement, I mean that Kafka Streams emits new results whenever records are updated. You don’t have to worry about telling each operator when it should emit results. You get to focus on the logic of your data processing pipeline.
Whether Streams emits every single update or groups updates is irrelevant to the semantics of a data processing application. It is important for the operational characteristics, though. High-volume applications may not be able to process and transmit every update within the constraints of CPU, memory, network and disk. Because this is an operational problem, not a semantic one, Streams gives you operational parameters to tune a record cache rather than API operators.
The plot thickens
The continuous-refinement-with-operational-parameters model is a very simple and powerful design for a data processing system. It eliminates irrelevant details from applications while providing complete semantics.
However, many data processing applications will eventually produce results into a system outside of Apache Kafka®. Some of these external systems are designed in a way that don’t support continuous refinement, and it would be nice to support developers who have to work with these systems.
Also, there are plenty of use cases that are not pure data processing but need to produce side effects. Sending emails, firing off alerts or even committing resources, like telling a driver to start a delivery run, are all examples of side effects. They are all non-retractable. Anyone who has accidentally hit “send” too early or been woken up in the middle of the night by a flaky alert knows that sending a follow-up message is not exactly the same as a continuous update.
Kafka Streams now supports these use cases by adding Suppress. Suppress is an optional DSL operator that offers strong guarantees about when exactly it forwards KTable updates downstream. Since it’s an operator, you can use it to control the flow of updates in just the parts of your application that need it, leaving the majority of your application to be governed by the unified record cache configuration.
You can use Suppress to effectively rate-limit just one KTable output or callback. Or, especially valuable for non-retractable outputs like alerts, you can use it to get only the final results of a windowed aggregation. The clearest use case for Suppress at the moment is getting final results, so we’ll start by looking at the feature from that perspective.
Use case: Alerting
Consider building a metrics and alerting pipeline in which events are bucketed into two-minute windows. By default, Kafka Streams will update a window’s output whenever the window gets a new event (or soon afterward, depending on your record cache configuration). Let’s say you built some dashboard graphs by querying the result tables using Interactive Query. Each time the graph refreshes, it will get the most recent metric values in each window.
But how can you build alerts?
If you want to send an email when a key has less than four events in a window, it seems pretty straightforward…
But this program is broken! The filter is initially true for every key in every window, since the counts would progress through one, two and three before reaching four. So we’d wind up sending emails for every key before later realizing that we shouldn’t have sent them. We can send a follow-up email telling people to ignore the first message, but they’ll still receive both when they would have preferred no message at all.
You can try to suppress those intermediate states by using Streams’ cache.max.bytes.buffering and commit.interval.ms configs, but it’s going to be difficult (or impossible) to get them to line up perfectly with your windows, especially if you have two different streams with different window configs in the same application.
It would be a whole lot simpler if you could execute the callback only on the final result of the computation.
Well, now you can!
Final results with the Suppress operation
Our design challenge was to preserve the fundamental simplicity of Kafka Streams. You shouldn’t have to worry about event triggering patterns unless it’s important for your business logic. And when it is important, it should work in an intuitive way.
We’ve done this by adding a new operator for suppressing intermediate updates to the KTable API: Suppress.
This is how you can use the operator to trigger your callback only when the final count for a window is less than four:
Adding suppress(untilWindowClose...) to the program tells Streams to suppress all output results from the count operation, until the “window closes.” When the window closes, its result can never change again, so any results coming out of suppress(untilWindowClose...) are the final results for their windows.
It’s a little subtle, but “window close” in the previous paragraph is actually a new concept that we have added to help support the suppression feature and provide cleaner semantics around the window lifecycle in Streams. To understand Suppress, it’s helpful to take a quick detour and clarify when exactly a window closes.
Grace period and window lifecycle
Our example is a windowed count, meaning we split up the stream into time-based windows. TimeWindows.of(Duration.ofMinutes(2)) means that the windows are two minutes long and don’t overlap. So, there’s one window covering 09:00:00 to 09:02:00 (exclusive), and another one from 09:02:00 to 09:04:00 (exclusive), etc. The first window’s start is at 09:00:00, and its end is two minutes later at 09:02:00 (exclusive).
On top of this, we want to be able to tolerate some amount of late-arriving records that arrive after the window end time, so we keep the window open for a grace period of two more minutes using .withGrace(Duration.ofMinutes(2)). Once the grace period expires, the window is closed, and we can never add more events to it.
If we’re processing at 09:02:30, and some record comes in that’s tagged 09:01:45, we can still add it to the 09:00:00 window. But if we’re processing at 09:51:00, and some record comes in 50 minutes late tagged at 09:01:00, we’d discard it since the window is already closed.
Note that the grace period is enforced by the Kafka Streams DSL (Domain-Specific Language) windowed aggregation and join processors. If you use your own processors using the Processor API, you have the option of whether or not to enforce it.
Achieving final results with Suppress
The suppression operator can make use of the fact that once the window is closed, Streams will never add more results to it. In our example, as soon as 09:04:00 rolls around, we can emit all the counts from the 09:00:00 window, knowing that these are the final results.
This is why we can safely use the declarative filter _ < 4. Anything after the Suppress will never see those intermediate states as the count is increasing. They will only see the final count for each key in each window.
| Important: If you’re using Suppress.untilWindowClose, you should definitely also set the grace period on the window definition, since the default is 24 hours (for legacy reasons). You have to decide for yourself what a good choice is, trading off between leaving the window open for late-arriving updates (but increasing latency) and closing the window more promptly to get more timely results from Suppress (but potentially discarding some late-arriving records). |
Here’s a picture of what’s going on with each of the operators in the code block shown above (Metrics App with Alerts) during processing:
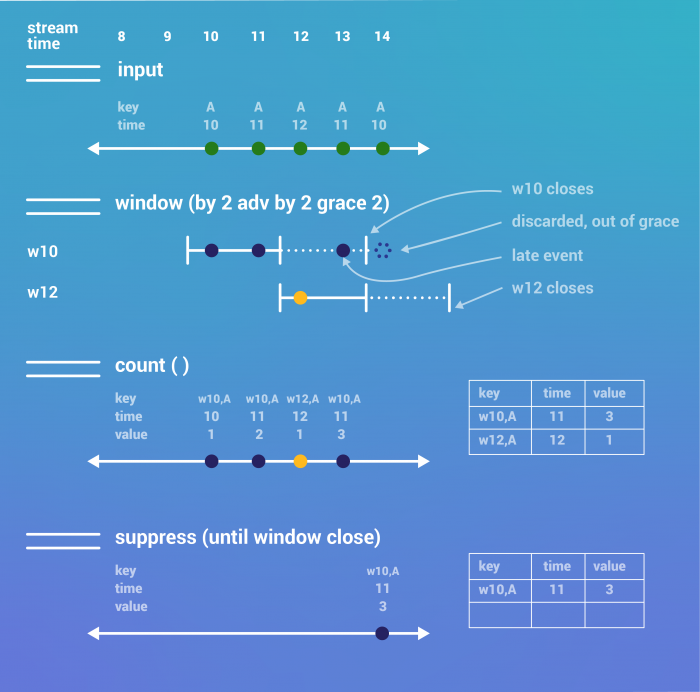
At the top, we see the input stream of events. This essentially corresponds to line 1 of Metrics App with Alerts. For simplicity, all the events have the same key, A, but they vary by timestamp. At the very top, you can see the current stream time.
You can see that the first event is on time, since it has the timestamp 10 and actually arrives at time 10, whereas the fourth event is two minutes late, since it arrives at time 13 but has the timestamp 11.
We window the incoming events in line 3 of Metrics App with Alerts. Below is the assignment of the events to the two relevant windows:
- Window w10 starts at time 10, ends at time 12 (exclusive) and closes at time 14 (exclusive)
- Window w12 starts at time 12, ends at time 14 (exclusive) and closes at time 16 (exclusive)
Note that the late event arriving at time 13 but timestamped 11 gets added to w10, whereas the late event arriving at time 14 but timestamped 10 is discarded, since w10 is closed as of time 14.
In line 6 of Metrics App with Alerts, we use the count operator to tally up the number of events for each key in each window. The result of count is a KTable, which is depicted in tabular form (as of time 14) to the right. After discarding the event that arrived after w10 closed, the count for w10 is 3, and the count for w12 is 1. Note that as of time 14, w12 is still open (it won’t close until time 16).
Finally, we see a depiction of the suppress operator in line 7 of Metrics App with Alerts. Suppress doesn’t change the type of the stream, so the result type is still a KTable, which is again depicted as of time 14 to the right. As you can see in the event view, Suppress doesn’t emit anything until a window closes, so it emits the (final) result for w10 at time 14.
Since w12 is still open, nothing has been emitted, and it’s therefore missing from the tabular view. As you can see, the rows that Suppress produces is a subset of the rows that count produces at any point in time. That is, if a row is present in the suppress result, it is present with exactly the same value in the count result. This follows from the definition of a final result. As long as any value can still change in the count result, it will be missing from the suppress result.
Keeping raw updates alongside suppressed results
One neat thing about the implementation of Suppress as an operator, rather than an option on the count or window definition, is that both the raw and final streams are available in your topology. Even though you might need just the final results for your alerts, you can still use the raw updates for other operations that can handle continuous refinement.
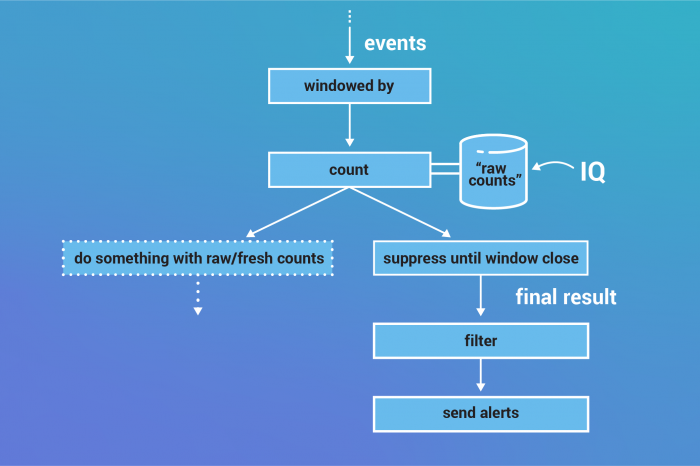
Additionally, because the grace period is a property of the window configuration, all the windowed aggregations that descend from it, and any suppressions that descend from the aggregations will ultimately agree on the final state of the window. This makes it safe to express your computation as multiple independent streams coming out of the windowing operation. The results will be consistent.
Memory and storage
Since the suppression operator needs to hold on to events for an arbitrary amount of time before emitting them, we need to allocate some memory to hold that data.
In the example above, we’re doing this with BufferConfig.unbounded().
The suppression BufferConfig has options for restricting the amount of memory to use or the number of records to store, or leaving both bounds unset.
Suppress also needs to know what to do when the buffer fills up. Right now, the three options are:
- emitEarlyWhenFull(): Just emit the oldest record in the buffer.
- shutDownWhenFull(): Gracefully flush and close all the internal state stores and producers, and then stop the application.
- withNoBound(): Keep allocating more memory as needed. Clearly, if the buffer requires more memory than the heap can supply, your process will crash. But this is no different than using other unbounded data structures like ArrayList. The buffer only needs to store data for the windows that are currently open, so this is a reasonable configuration if you don’t have a lot of keys or windows at one time.
When you use suppress with the untilWindowClose configuration, your choices are more restricted. Suppress cannot guarantee to suppress all the intermediate results and emit only the final results, while also honoring emitEarlyWhenFull. Therefore, untilWindowClose only allows so-called “strict buffer configs.”
Currently, this only includes buffers withNoBound or shutDownWhenFull. That is, your instance will either crash or shut down gracefully if it runs out of memory. From here, you could add more instances to spread the load more evenly, or adjust the buffer bounds or heap size and restart.
Suppression buffer memory is independent of Streams’ record cache, so be sure you have enough heap to host the record cache (cache.max.bytes.buffering) in addition to the sum of all the suppression buffer sizes.
| Warning: When one instance goes down (for any reason), its tasks will eventually be assigned to the remaining instances. If the problem was insufficient memory, then the remaining instances may also run out of memory once they rebuild the state for the first instance. This is a problem with any self-healing data system, but I’m calling it out because it’s easy to overlook until it happens. |
We are actively working on a proposal to add another option to store the suppression buffer in RocksDB (like the state stores). This would sacrifice some performance, but if you can give up some performance in order to run with a smaller memory footprint, it’s a nice option.
What time is it?
Time is always a deceptively tricky concept with software and computers—more so with distributed systems—and even more so with stream processing systems. It’s especially important for Suppress because a mistake could result in incorrect or bizarre behavior.
The important aspects of time for Suppress are:
- The timestamp of each record: This is also known as event time.
- What time is “now”? Stream processing systems have two main choices here:
- The intuitive “now” is wall-clock time, the time you would see if you look at a clock on the wall while your program is running.
- There is also stream time, which is essentially the maximum timestamp your program has observed in the stream so far. If you’ve been polling a topic, and you’ve seen records with timestamps 10, 11, 12, 11, then the current stream time is 12.
Note that if you run your program twice in a row, the wall-clock time will be different each run. But, after retrieving those same four records, the stream time will again be 12. In other words, if you run your program twice, the stream time will be the same between runs at every point in the execution.
Also, if you stop getting new records (e.g., your connection to the broker fails for a while or no new data is produced upstream), wall-clock time will continue to advance, but stream time will freeze. Wall-clock time advances because that little quartz watch in your computer keeps ticking away, but stream time only advances when you get new records. With no new records, stream time is frozen. It might seem obvious right now, but this can be an unpleasant surprise in the heat of the moment, especially when you’re writing tests.
As of Apache Kafka 2.1, Suppress only supports stream time. Suppression itself was a huge design effort, so we didn’t want to tackle too much at once. Stream time is required to be able to guarantee correctness for the “final results” use case, so that’s the one we had to start with. There is an effort underway to add an option for wall-clock time to the API.
Testing your suppressions
One consistent challenge has been how to test a Streams application that uses Suppress. If you have a suppression in your topology, and you write some test data, no amount of waiting will make the results come out. You have to advance stream time to flush your results out of the suppression buffer. I find it useful to explicitly set the timestamps in my test data and then, when I wish to verify the results, write a dummy record with a timestamp that is large enough to flush everything else out of the suppression operator.
Using the TopologyTestDriver to test with the data depicted in the diagram above would look something like:
For more involved testing examples, I recommend reading the SuppressScenarioTest in the Kafka codebase.
Rate control with Suppress
The primary motivation for Suppress right now is to get just the final results from a windowed aggregation, as this is otherwise impossible. Nevertheless, other applications may benefit from fine-grained rate control as well.
Although Suppress.untilWindowClose only works on windowed KTables, Suppressed.untilTimeLimit is available on any KTable. This mode lets you specify a stream-time delay. When the operator gets an update for a new key, it buffers the record and soaks up any updates. Once the time limit expires, the operator emits the last observed value for that key.
Unlike untilWindowClose, untilTimeLimit permits you to specify BufferConfig.emitEarlyWhenFull if you don’t need to enforce a strict time limit.
As of now, untilTimeLimit only supports stream time, which limits its usefulness. Work is underway to add a wall-clock time option, expanding this feature into a general rate control mechanism.
Operational notes
Since Suppress has some implications on memory usage and also affects the shape of the Streams application topology, there are a few operational concerns to bear in mind.
Setting the buffer size
One operational concern is managing memory usage. Especially if you select BufferConfig.unbounded, you will want to monitor the used buffer size. Then, if the application does run low on heap, you’ll be able to identify which (if any) suppression buffer is to blame.
The primary metrics for monitoring buffer size are suppression-buffer-size-{current|max|avg} and suppression-buffer-count-{current|max|avg}. These correspond to the primary configurations of the buffer, maxBytes and maxRecords.
The suppression buffer has to store the key and latest value, both serialized, as well as any headers and miscellaneous state metadata, like the record topic, partition, offset and timestamp. Suppress must store this data for each key that appears at least once within the time horizon of the buffer. Using your knowledge of the input data, you can estimate the memory requirements up front and then check your calculations against the actual metrics as the application runs.
Reconfiguring buffer size at runtime
Unlike the record cache for state stores (cache.max.bytes.buffering), suppression buffer size limits are compiled into the source code. If you wish to maintain the flexibility to alter the buffer limits at run time, you can retrieve the buffer size dynamically from a runtime config.
Here is an example:
Establishing such a pattern would be useful in combination with good monitoring of the buffer sizes. If the application runs low on heap and you’re unable to increase just the heap size, you would be able to restrict the memory given to untilTimeLimit buffers.
Adding and removing suppression operations
In general, altering a Streams topology (adding or removing operations) requires an application reset.
This is because Streams has to manage persistent resources like state stores and internal topics by name. You can see these names by printing the topology description (topology.describe()).
By default, Streams generates unique names for each operator and uses these names to identify the relevant persistent resources. The generated names depend on the structure of the topology, so adding an operator can change the names of multiple other operators in the topology. Changing operator names can cause Streams to lose track of important state or, worse, to mistakenly load the state of some other operator if a name happens to get reused (causing a crash or data corruption).
Resetting the application avoids this issue simply by destroying all the internal state and starting over from scratch. Of course, the downside is that you lose all the state and have to rebuild it all from scratch.
As of 2.1, you can set up your application for safe alterations without resetting by naming stateful operators. The most stable practice would be to name every operator that supports naming. Then, you could alter the topology arbitrarily (including adding and removing suppressions), and Streams would still be able to keep track of all its resources.
If you have a running topology and have not named all the stateful operators, you can still safely add and remove suppressions by carefully following this practice:
When adding suppressions, always specify a name using Suppressed.withName
Removing suppression operators in particular has an extra hazard. Removing suppression operators may result in data loss because the operator is holding buffered data. If you just remove the operator, Streams will have no idea that it was previously there and won’t know that it needs to flush that data downstream. To circumvent this problem, you can disable instead of removing suppressions:
Instead of removing unwanted suppressions, disable them:
- Convert untilWindowCloses suppressions to untilTimeLimit
- Set the time limit to Duration.ZERO
Naming suppressions ensures that adding suppressions won’t disturb the names of other operators. Disabling instead of removing suppressions ensures that any state that was buffered when you shut the application down will be flushed downstream instead of being lost.
After running the topology with a disabled suppression, all the state gets flushed out, so you could shut it down again and finally remove it.
What’s next for suppression
As I mentioned above, we’re not finished with Suppress. The main things on the horizon are:
- Adding wall-clock time for doing rate-limiting with Suppress
- Using RocksDB for the suppression buffer when it doesn’t fit easily in memory
Beyond the horizon, there are a number of challenging future directions that Suppress could take.
Some folks have pointed out that Suppress could potentially replace the state store record cache in Streams, resulting in cleaner and more configurable caching behavior. But this will take careful design, as it has implications on state stores and the Kafka client libraries as well.
In theory, Suppress could eschew the buffer as well, and instead fetch the latest state from the upstream state store when it’s time to emit. There are a number of logistical challenges to be overcome, but the payoff would be a large savings in overhead on the suppression buffer.
The topology compatibility warnings from the previous section are not fundamental limitations, but just limitations of the current implementation. An interesting challenge would be to give Streams some memory of the prior topology. Then, it could automatically handle both addition and removal of Suppress operators without disrupting the topology.
The rate-limiting aspect of Suppress is also related to some extent to the long-running effort to design a good way to interact with remote services within Streams (see KIP-311 and KIP-408, for example). This is a really challenging design space, but there are a lot of valuable use cases it could unlock.
If you have thoughts, feedback or ideas, feel free to jump in on the discussion, propose a KIP or even send a PR! Confluent is also hiring, so if this stuff sounds like an interesting challenge, you can work on it full time!
Conclusion
I hope the details I’ve given are helpful for understanding and using this new feature. However, I don’t want to lose sight of the fact that Suppress is completely optional. If you don’t need to exercise fine-grained control over KTable updates, then you don’t have to worry about any of the above. You can still stick with the Kafka Streams DSL to describe your program logic.
If you are interested in learning more:
- See the Kafka Streams API documentation to get started with build your own real-time applications and microservices
- Walk through the Confluent tutorial for the Kafka Streams API with Docker and play with our demo applications
- Listen to the Streaming Audio podcast where I discuss KIP-328
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.