[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Kafka Connect Elasticsearch Connector in Action
The Elasticsearch sink connector helps you integrate Apache Kafka® and Elasticsearch with minimum effort. You can take data you’ve stored in Kafka and stream it into Elasticsearch to then be used for log analysis or full-text search. Alternatively, you can perform real-time analytics on this data or use it with other applications like Kibana.
About the Elasticsearch Sink Connector
The purpose of the Elasticsearch connector is to push events from Kafka into an Elasticsearch index.
When building solutions that utilize Kafka Connect, I always use Confluent Docker images and Docker Compose as they’re quick and easy to get up and running. Confluent offers two Kafka Connect Docker images: one with some connectors preinstalled—including the Elasticsearch sink connector—and the other without any connectors bundled within it.
If you want to use the latter Docker image, you can install the connector via the Confluent Hub:
$ confluent-hub install confluentinc/kafka-connect-elasticsearch:5.4.0
The Elasticsearch sink connector supports Elasticsearch 2.x, 5.x, 6.x, and 7.x.
How to Transfer JSON Data Into Elasticsearch From Apache Kafka®
Let’s start with something simple: sending a JSON document from Kafka into Elasticsearch. We’ll be using ksqlDB to carry out some of the Kafka operations, such as printing the contents of a topic.
Here, we have a basic connector configuration:
{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"name": "simple-elasticsearch-connector",
"connection.url": "http://elasticsearch:9200",
"type.name": "_doc"
}
First, specify the connector class, the maximum number of tasks, the Kafka topics to consume from, a name for our connector, the connection URL, and lastly the type.
Before creating the connector, we have to create the topic to store the records:
$ docker exec -it kafka kafka-topics --zookeeper zookeeper:2181 --create --topic simple.elasticsearch.data --partitions 1 --replication-factor 1
To verify that our topic has been created, use the ksqlDB CLI:
ksql> show topics;
Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups
-------------------------------------------------------------------------------------------------------
simple.elasticsearch.data | false | 1 | 1 | 0 | 0
-------------------------------------------------------------------------------------------------------
With the topic in place, create the connector:
$ curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "simple-elasticsearch-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"type.name": "_doc"
}
}'
We can use kafkacat, a handy CLI for interacting with Kafka, to send some JSON into Elasticsearch.
$ kafkacat -P -b localhost:9092 -t simple.elasticsearch.data
hello
hi
To be certain our JSON data is reaching Kafka, use the ksqlDB CLI to print the data inside the topic:
ksql> print 'simple.elasticsearch.data';
Format:JSON
{"ROWTIME":1571841133050,"ROWKEY":"null","message":"hello"}
{"ROWTIME":1571841161487,"ROWKEY":"null","message":"hi"}
But we end up getting an error in the logs of the Kafka Connect worker…
Caused by: org.apache.kafka.connect.errors.DataException: Failed to deserialize data for topic simple.elasticsearch.data.1 to Avro: … … Caused by: org.apache.kafka.common.errors.SerializationException: Error deserializing Avro message for id -1 Caused by: org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
So, what’s causing this?
When creating our Kafka Connect workers, we set a default converter for our keys and values in the Docker Compose file. In this case, it’s the Apache Avro™ converters…
CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081' CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
If we don’t specify a converter in our connector configuration, the connector will try to deserialize the data in the topic from Avro. This time, it failed. We now have to update our connector configuration to include the JSON converter.
Use the REST interface to update the configuration:
$ curl -X PUT localhost:8083/connectors/simple-elasticsearch-connector/config -H "Content-Type: application/json" -d ‘{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"name": "simple-elasticsearch-connector",
"type.name": "_doc",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
"value.converter.schemas.enable": "false"
}’
Kafka Connect supports JSON documents with embedded schemas. A document contains the message contents and a schema that describes the data. We don’t have a schema in this example, so we need to specify that in the connector configuration using the "schema.ignore": true attribute.
Last but not least, our message doesn’t have a key so we need to include the "key.ignore":"true" attribute. When we set this attribute to "true", only the value of the message will be inserted into Elasticsearch. We’ll explore the schema.ignore and key.ignore attributes more in the next section.
Our last connector configuration update should include the following:
$ curl -X PUT localhost:8083/connectors/simple-elasticsearch-connector/config -H "Content-Type: application/json" -d ‘{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"name": "simple-elasticsearch-connector",
"type.name": "_doc",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"schema.ignore": "true",
"key.ignore": "true"
}’
After the configuration update, we shouldn’t see any more errors in the Kafka Connect worker logs. We can utilize the Elasticsearch search API to verify the message has been indexed.
$ curl localhost:9200/simple.elasticsearch.data/_search | jq
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "simple.elasticsearch.data",
"_type": "_doc",
"_id": "simple.elasticsearch.data.1+0+0",
"_score": 1,
"_source": {
"text": "hello"
}
}
]
}
}
Two things to point out:
- Our document now has an _id made up of the topic name, partition, and offset
- The index name is the same as the Kafka topic
If we want to use a different index name, we can utilize the RegexRouter single message transformation (SMT) to modify it. We could also go one step further and use the TimestampRouter SMT to include a timestamp in the index name. If we didn’t set "key.ignore": "true", the key associated with the message would be the _id instead.
Keys and Schemas
In the previous examples, we ignored the key and schema as our message didn’t include them. In the real world, however, this isn’t always going to be the case. The connector could potentially be consuming messages from topics that have keys and schemas and from some topics that don’t. In the world of integration and external data providers, we can try to influence or enforce data decisions, but sometimes it’s out of our control.
Let’s say we run a company that sells electrical products. An external supplier provides product listings in a topic named external.supplier.product.listings. The records are in JSON format and include a key, schema, and the message payload.
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "productName"
},
{
"type": "string",
"optional": false,
"field": "description"
},
{
"type": "string",
"optional": false,
"field": "price"
}
],
},
"payload": {
"productName": "Bagotte BG600 Robot Vacuum Cleaner",
"description": "Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of the kitchen.",
"price": 199.9
}
}
In this scenario, configure the connector similarly to how we did it in the previous section but without overriding the key.ignore and schema.ignore attributes. Also set the key.converter attribute to utilize the String Converter.
From there, send some messages into the external product listings topic:
$ kafkacat -P -b localhost:9092 -t external.supplier.schema.product.listings -K: <<EOF
13240212:{"schema":{"type":"struct","fields":[{"type":"string","optional":false,"field":"productName"},{"type":"string","optional":false,"field":"description"},{"type":"string","optional":false,"field":"price"}]},"payload":{"productName":"Bagotte BG600 Robot Vacuum Cleaner","description":"Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of the kitchen.","price":"199.99"}} 13300212:{"schema":{"type":"struct","fields":[{"type":"string","optional":false,"field":"productName"},{"type":"string","optional":false,"field":"description"},{"type":"string","optional":false,"field":"price"}]},"payload":{"productName":"Shark NV601UKT Upright Vacuum Cleaner","description":"Pet vacuum - pet power brush attachment easily removes pet hair from carpets, stairs and sofas: Hose stretches up to 2.15 m.","price":"9.99"}}
EOF
With a couple of messages sent into Kafka, check Elasticsearch to see if the external product listings have made it:
$ curl localhost:9200/external.supplier.schema.product.listings/_search | jq '.hits'
{
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "external.supplier.schema.product.listings",
"_type": "listing",
"_id": "13240212",
"_score": 1,
"_source": {
"productName": "Bagotte BG600 Robot Vacuum Cleaner",
"description": "Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of the kitchen.",
"price": "199.99"
}
},
{
"_index": "external.supplier.schema.product.listings",
"_type": "listing",
"_id": "13300212",
"_score": 1,
"_source": {
"productName": "Shark NV601UKT Upright Vacuum Cleaner",
"description": "Pet vacuum - pet power brush attachment easily removes pet hair from carpets, stairs and sofas: Hose stretches up to 2.15 m.",
"price": "9.99"
}
}
]
}
Success! When the record is inserted into Elasticsearch, the embedded schema creates a mapping for the index instead of Elasticsearch working out the mapping from the data. Since we aren’t ignoring the key in this example, the provided key is used for the ID of the document.
The external suppliers have noticed an issue with one of the listings that requires attention: the price is incorrect. As messages are sent into Kafka with a key, the external supplier is able to send another record through to Kafka with amendments to the price, updating the record in Elasticsearch rather than creating a new record.
$ kafkacat -P -b localhost:9092 -t external.supplier.schema.product.listings -K: << EOF13300212:{"schema":{"type":"struct","fields":[{"type":"string","optional":false,"field":"productName"},{"type":"string","optional":false,"field":"description"},{"type":"string","optional":false,"field":"price"}]},"payload":{"productName":"Shark NV601UKT Upright Vacuum Cleaner","description":"Pet vacuum - pet power brush attachment easily removes pet hair from carpets, stairs and sofas: Hose stretches up to 2.15 m.","price":"249.99"}} EOF
We can then check Elasticsearch to make sure the update has taken place:
$ curl localhost:9200/external.supplier.schema.product.listings/_doc/13300212 | jq '._source'{ "productName": "Shark NV601UKT Upright Vacuum Cleaner", "description": "Pet vacuum - pet power brush attachment easily removes pet hair from carpets, stairs and sofas: Hose stretches up to 2.15 m.", "price": "249.99" }
A Real-World Scenario
Let’s look at a scenario we might come across in the real world. Some product listing data is being inserted into a MySQL database that we want to send into Elasticsearch to drive a search function on our web application. We’ll use Schema Registry to store a schema for the product listing.
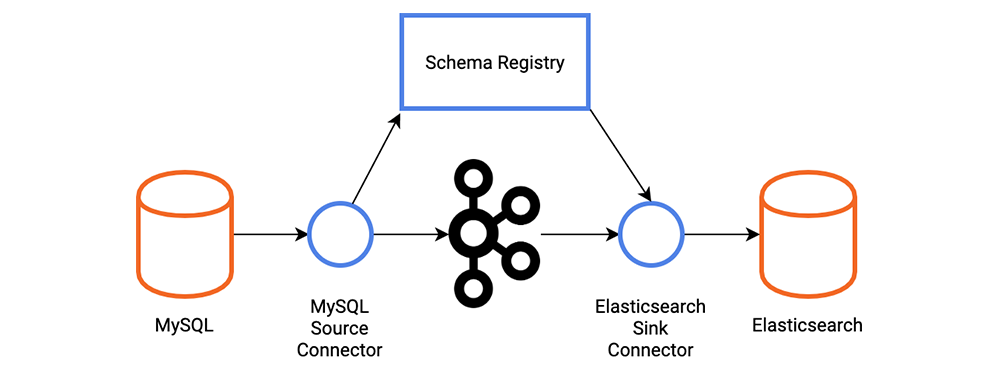
The MySQL table is a pretty basic table with four columns. The ID field is auto incremented so that the connector is aware of new records being added to the table.
$ create table products ( id INT auto_increment PRIMARY KEY, product_name VARCHAR(50), description VARCHAR(250), price DECIMAL(10, 2) );
With our table created, we can make the connector. Since we’re focusing on the Elasticsearch sink connector, you should check out this blog post on the JDBC source connector if you want to know more about the attributes used.
$ curl -X POST http://localhost:8083/connectors -H “Content-Type: application/json” -d '{
"name": "mysql_product_listings",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/dev",
"connection.user": "root",
"connection.password": "Admin123",
"topic.prefix": "mysql-",
"mode": "incrementing",
"incrementing.column.name": "id",
"poll.interval.ms": 5000,
"tasks.max": 3,
"table.whitelist": "products"
}
}'
Once we have created the connector, we should see log lines similar to this:
[2019–08–07 07:38:52,587] INFO Started JDBC source task (io.confluent.connect.jdbc.source.JdbcSourceTask)
[2019–08–07 07:38:52,587] INFO WorkerSourceTask{id=mysql_product_listings-0} Source task finished initialization and start (org.apache.kafka.connect.runtime.WorkerSourceTask)
[2019–08–07 07:38:52,588] INFO Begin using SQL query: SELECT * FROM `dev`.`products` WHERE `dev`.`products`.`id` > ? ORDER BY `dev`.`products`.`id` ASC (io.confluent.connect.jdbc.source.TimestampIncrementingTableQuerier)
To test that the connector is working, create a row in the products table:
$ insert into products(product_name, description, price) values ("Bagotte BG600 Robot Vacuum Cleaner", "Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of the kitchen.", 199.9);
You should see it in a topic created by the connector:
ksql> print ‘mysql-01-products’;
Format:AVRO
8/7/19 7:44:22 AM UTC, null, {"id": 2, "product_name": "Bagotte BG600 Robot Vacuum Cleaner", "description": "Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of the kitchen.", "price": {"bytes": "N\u0016"}}
Notice Format:AVRO on the second line? More on that later.
One thing to point out is that the JDBC connector doesn’t create a key for our records. If your records need a key, take a look at the ValueToKey SMT, which allows you to create a key for the record from attributes inside the record.
Now that the JDBC connector is working, we can create the Elasticsearch connector:
$ curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "elasticsearch_product_listings_sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "mysql-products",
"name": "elasticsearch_product_listings_sink",
"type.name": "listing",
"key.ignore": "true"
}
}'
Fingers crossed, there should be no errors. As in the first example, let’s check Elasticsearch to make sure the product listing is in there:
$ curl localhost:9200/mysql-01-products/_search | jq ‘.hits’
{
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "mysql-products",
"_type": "listing",
"_id": "mysql-products+0+1",
"_score": 1,
"_source": {
"id": 2,
"product_name": "Bagotte BG600 Robot Vacuum Cleaner",
"description": "Bagotte 1500 Pa powerful vacuum cleaner robot, easy to access every corner of kitchen."
]
}
Success!
When we created the MySQL connector, we didn’t specify a converter in the configuration. This means the connector is using the default converter specified on the Kafka Connect worker, which in this case is Avro. The connector is taking data from MySQL and serializing it into the Avro format, creating a schema for that data and storing it in the Schema Registry. If we want to check that the schema was created, head to the URL of the Schema Registry, which in my case as I’m running the Kafka stack locally is http://localhost:8081/subjects.
It’s pretty much the same scenario when creating the Elasticsearch connector. We don’t need to specify a converter as the Connect worker is using the default converter for our keys and values.
Rotating Indexes
A common use case for Elasticsearch is storing log data. Typically, log data is streamed into an array of time-bucketed indexes. Perhaps we want to use the Elasticsearch connector to stream data into a new index every day. The Elasticsearch connector can be configured to do this using the TimestampRouter SMT.
The TimestampRouter SMT updates the record’s topic field as a function of the original topic value and the record timestamp. Because the Elasticsearch connector uses the topic name as the index name in Elasticsearch, configure the connector to suffix the current day to the topic name. Below is an example configuration for a connector that writes to a daily rotating index:
{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"topics": "simple.elasticsearch.data",
"name": "simple-elasticsearch-connector",
"type.name": "_doc",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
"value.converter.schemas.enable": "false",
"transforms":"routeTS",
"transforms.routeTS.type":"org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.routeTS.topic.format":"${topic}-${timestamp}",
"transforms.routeTS.timestamp.format":"YYYYMMDD"
}
This connector creates a new index in Elasticsearch every day and streams events into the index that corresponds to the record’s timestamp. Expiring and deleting old indexes can be done using the Elasticsearch Curator or manually using a daily job.
Malformed Documents
There might come a time when we don’t have control over the data our connector consumes.
Say we start working with a third party who provides us with product listings. We can’t guarantee the quality of that data. What if the contents of the JSON document aren’t correct for our index? What happens if there is an illegal character in one of the field names? What happens if there’s a mapping conflict?
The behavior.on.malformed.documents attribute can help here. We get three options for this attribute: ignore, warn, or fail. We can ignore the problematic record, give a warning about it that will be visible in the logs, or fail it, which will cause the connector to catch fire and require fixing.
Tombstone Messages
A tombstone message is a record that has a key but doesn’t have a value. Its purpose is to remove all messages in a compacted topic with the associated key. By default, a tombstone record is deleted after a day or based on whatever the value of delete.retention.ms has been assigned. This way, consumers that might have been relying on this value for state are aware that the value for the key has been deleted.
What happens when the Elasticsearch connector comes across a tombstone message? This is where the behavior.on.null.values attribute comes into play. By default, the connector ignores tombstone messages, but this behavior can be modified so that a delete operation is performed instead.
Sticking with the example of an external supplier who provides us with product listings, there could become a point in time when a product listing in the index is no longer available and the suppliers don’t require it to be listed. The supplier could send a tombstone record, which would delete the document from the index.
Because the default behavior is to ignore tombstone messages, we have to update the connector configuration to override the attribute in order to delete the document:
$ curl -X PUT http://localhost:8083/connectors/external_product_listings_es_sink/config -H "Content-Type: application/json" -d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"connection.url": "http://elasticsearch:9200",
"tasks.max": "1",
"name": "external_product_listings_es_sink",
"type.name": "_doc",
"topics": "external.supplier.schema.product.listings",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": "true",
"behavior.on.null.values": "delete"
}'
Then send in the tombstone record, which is composed of a null schema and null payload:
$ kafkacat -P -b localhost:9092 -t external.supplier.schema.product.listings -K: << EOF
13300212:{"schema":null,"payload":null}
EOF
Finally, check Elasticsearch to verify that the document has been deleted:
$ curl localhost:9200/external.supplier.schema.product.listings/_doc/13300212 | jq
{
"_id": "13300212",
"_index": "external.supplier.schema.product.listings",
"_type": "_doc",
"found": false
}
Success!
Tuning
It’s important to tune connectors with the correct parameters to get the best possible performance. For the Elasticsearch sink connector, these parameters will largely depend on the volume of your Kafka topic, the size of your Elasticsearch cluster, the indexing latency, the size of the documents being indexed, and the memory in your Kafka Connect nodes. In addition to the number of tasks in your connector, the three main parameters to tune are:
- batch.size: the number of records to process as a batch when writing to Elasticsearch
- max.buffered.records: the maximum number of records each task will buffer before blocking acceptance of more records
- flush.timeout.ms: the timeout in milliseconds to use for periodic flushing and while waiting for buffer space to be made available by completed requests as records are added
The default configurations are:
flush.timeout.ms=10000 max.buffered.events=20000 batch.size=2000
With these defaults, each task needs to flush 10 batches of up to 2,000 events at a time within 10 seconds. If the task cannot keep up with this rate of indexing, two common events may happen:
- org.apache.kafka.connect.errors.ConnectException: Flush timeout expired with unflushed records: 17754: this means the task could not flush all its buffered events to Elasticsearch within the timeout of 10 seconds. In this case, the connector rewinds to the last committed offset and attempts to reindex the whole buffer again. If it continues failing in this way, Elasticsearch may get stuck in a continuous index-fail-rewind loop. The connector is effectively stopped, but its state will be RUNNING. To fix this issue, either raise the flush.timeout.ms or lower the max.buffered.events (or scale up the Elasticsearch cluster).
- WARN Failed to execute batch 34716 of 2000 records, retrying after 100 ms (io.confluent.connect.elasticsearch.bulk.BulkProcessor) java.net.SocketTimeoutException: Read timed out: this means that a single batch could not be flushed to Elasticsearch within the socket timeout. The connector will retry and eventually crash, usually meaning your batch.size is too high and needs to be lowered.
Of course, every deployment is different so the numbers you settle on will depend on your infrastructure and requirements. Take some time to ensure your connectors are configured to optimize for throughput and will not crash or get stuck, especially when they are catching up on a backlog of data and are indexing at their maximum rate.
Learn Faster With More Pre-Built Connectors
Using Kafka Connect solves common integration challenges when trying to move data between multiple applications and systems. Confluent provides a wide variety of sink and source connectors for popular databases and filesystems that can be used to stream data in and out of Kafka. With the Elasticsearch sink connector, we can stream data from Kafka into Elasticsearch and utilize the many features Kibana has to offer.
To get started, you can download the Elasticsearch sink connector from Confluent Hub. And if you haven’t already, sign up for Confluent Cloud to get started with a fully managed Kafka service.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Guide to Consumer Offsets: Manual Control, Challenges, and the Innovations of KIP-1094
The guide covers Kafka consumer offsets, the challenges with manual control, and the improvements introduced by KIP-1094. Key enhancements include tracking the next offset and leader epoch accurately. This ensures consistent data processing, better reliability, and performance.



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…