[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
The Connect API in Kafka Cassandra Sink: The Perfect Match
The Connect API in Kafka is a scalable and robust framework for streaming data into and out of Apache Kafka, the engine powering modern streaming platforms.
At DataMountaineer, we have worked on many big data and fast data projects across many industries from financial such as High Frequency Traders and Banks, both retail and investment, to utilities and media. In each case, significant time is spent loading data, making these pipelines solid, reliable and robust. While this sounds straight forward, it is often overlooked. Data scientists can’t work their magic if they have no data.
Often these pipelines ended up using multiple components like Flume, Sqoop, Spark JDBC import/export or standalone Java or Scala applications to handle the multitude of data sources, both push and pull based. They grew even more complex to handle Lambda architectures and functional requirements (although we believe in Kappa to co-ordinate with workflow engines). They evolved beyond the simple loading of data and started dealing with business logic.
The Connect API in Kafka
The Connect API in Kafka simplifies all this and allows us to separate out these concerns. The Connect API Sources and Sinks act as sensors on the edge of our analytics platform, loading and unloading events as they happen real time. Under the hood they are Kafka consumers and producers with a simple and elegant API that allows developers to focus on moving data to and from Kafka.
Using the Connect API in Kafka, we can keep the ingest/egress layers clean and unpolluted by functional requirements. We leave the business logic, the `T` from `ETL`, to the processing layer leaving the Connect API decoupled from the applications that consume or produce the data it loads. The `T` is handled by stream processing engines, most notably Streams API in Kafka, Apache Flink or Spark Streaming.
Apache Cassandra
NoSQL stores are now an indispensable part of any architecture, the SMACK stack (Spark, Mesos, Akka, Cassandra and Kafka) is becoming increasing popular. Its demonstrated scalability and its high write throughput makes it the perfect partner to handle the flood of time series, IoT and industrial scale streams or financial data. This made Apache Cassandra an obvious choice as a Connect API in Kafka sink.
Joshua Ratha, product owner of the Data Hub and trader at Eneco Energy Trade, says:
“As a utility and trading company we deal with lots of time series. Think of gas and power prices,
steering of assets, forecasting the energy supply and demand of our assets and client portfolio at any given moment of the day. We want to interact with this information stream, to be responsive to what happens in the energy markets and analyze it historically to see patterns, learn and improve. This is why an architecture with both Confluent and Cassandra serves us well. At Eneco we are proud of our contribution to the Cassandra connector in collaboration with Datamountaineer.”
Connect API in Kafka Cassandra Sink
The DataStax Certified Connector, developed by DataMountaineer, simplifies writing data from Kafka into Cassandra. The connector converts the value from the Kafka Connect SinkRecords to Json. A fail fast thread pool is then used to insert the records asynchronously into Cassandra.
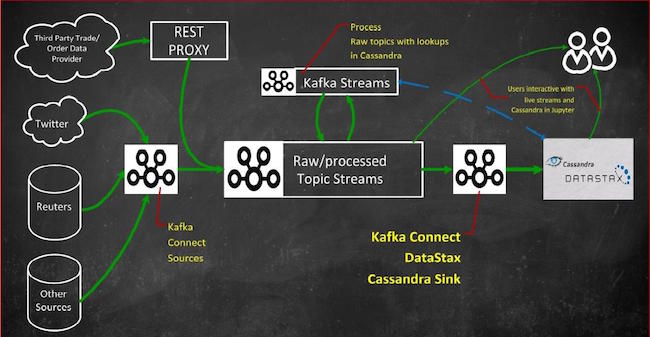
Below is a use case with Confluent Platform, Cassandra Sink and Cassandra all playing a pivotal role in a client’s streaming analytics platform.
DataMountaineer connectors can be downloaded from here.
The sink supports the following features:
Field selection – Kafka topic payload field selection is supported, allowing you to have choose selection of fields or all fields written to Cassandra.
Topic to table routing.
Error policies for handling failures – On Error the Sink will throw a RetriableException telling Connect to redeliver the messages on the next poll.
Secure connections via SSL.
Field selection and topic routing is handled by Kafka Connect Query Language which can be found here.
It allows for routing and mapping using an SQL like syntax, consolidating those configuration details into a single option.
The Cassandra Sink supports the following model for saving data from the Kafka topic:
Why KCQL?
While working on our Sink/Sources, we ended up producing quite complex configuration in order to support the functionality required. Imagine a Sink where you source from different topics and from each topic you want to cherry pick the payload fields or even rename them. Furthermore, you might want the storage structure to be automatically created and/or even evolve or you might add new support for the likes of bucketing. Imagine a Sink with a table which needs to be linked to two different topics and the fields in there need to be aligned with the table column names and the complex configuration involved …or you can just write this:
Using the Cassandra Sink
Ok, enough preaching, let’s use the Cassandra Sink to write some fictional trade data.
Preparation
Connect API in Kafka Sources and Sinks require configuration. For the Cassandra Sink a typical configuration looks like this:
Create a file with these contents, we’ll need it to tell the Connect API to run the Sink later.
The configuration options are hopefully obvious. We define the standard configurations required by the Connect API in Kafka such as the connector class, tasks and topics. Next we provide the KCQL statement, `connect.cassandra.export.route.query`. This tells the Sink to select all fields from the payload of the `orders-topic` and insert it into the table `orders` in the keyspace `demo`. We could have remapped or dropped fields from the payload here.
First we need to download Confluent Platform, so download and follow the Quickstart Guide here to get Apache Kafka, Zookeeper and the Schema Registry up and running.
Additionally, we need to start the Connect API in Kafka. We will do this in distributed mode which is straight forward but we need the Cassandra Sink on the CLASSPATH. Download the `Stream Reactor,` unpack the archive and add the Sink to the CLASSPATH. Be sure to add the full path.
To start Connect run the following from the location you installed Confluent.
We can use Kafka Connect’s Rest API to confirm that our Sink class is available.
We also need Cassandra so download and install from here or follow these instructions:
Start the CQL shell and set up the keyspace and table, the `csqlsh` can be found in `bin` folder of the Cassandra install.
Writing Data
Now we are ready to post in our Cassandra Sink configuration. To submit tasks to the Connect API in distributed mode you post in your config as Json to the rest endpoint. The Connect API exposes this by default at port 8083. To make this easier we developed a small command line tool to help interaction with the Connect API. It can be found here. We also have a CLI for the Schema Registry. To post in the config download the Connect cli and run the following passing in the configuration file we created earlier.
The Sink should start, then you can check the logs in the terminal you started the Connect API in Kafka in:
The CLI also lets you check for active connectors and their status. The full set of supported commands are `ps|get|rm|create|run|status`.
And you should see some nice ASCII art. Another feature 🙂
Next we need to push in some data! We can use the `kafka-avro-console-producer` tool from the Confluent Platform for this purpose. When writing data, we are good citizens and use Avro so we pass in the Avro schema with the `–property value.schema`.
Now paste the following into the terminal:
Check the logs of the Connect API in Kafka:
Now if we check Cassandra we should see our rows:
Conclusion
The combination of Apache Kafka, Streams API in Kafka, Connect API in Kafka and Apache Cassandra provides a powerful real time streaming and analytics platform. Initially, the Cassandra Sink was developed for a trade data source at a Eneco, but has now been successfully deployed to sink Twitter, Reuters and more to Cassandra to feed multiple APIs and Data Scientists.
This is a guest blog post written by Andrew Stevenson, CTO at DataMountaineer.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Keeping Multiple Databases in Sync Using Kafka Connect and CDC
Microservices architectures have now been widely adopted among developers, and with a great degree of success. However, drawbacks do exist. Data silos can arise where information processed by one microservice […]



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…