[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
The Link To Cloud: How to Build a Seamless and Secure Hybrid Data Bridge with Cluster Linking
Chances are your business is migrating to the cloud. But if you operate business applications in an on-premises datacenter, you know firsthand that the journey to the cloud is fraught with perils in security risks, networking challenges, and coordination interdependencies. Heavily guarded firewalls sit between private datacenters and public cloud providers, making connectivity a challenge.
Many organizations already find it challenging to manage and track the point-to-point connections and dependencies between existing services in their on-premises datacenters. Moving systems to the cloud will only exacerbate these issues. Security concerns, such as ensuring consistent authorization and authentication between deployments, remain a key consideration. Other factors include intermittent connectivity issues, system failures, and the quantity of systems that need support for point-to-point intercloud communication.
Apache Kafka® provides your organization with the means to decouple your point-to-point connections by using event streams. Producers write important business facts to your topics, and consumers self-select those that they want to consume for their own use cases. This model works extremely well within a single datacenter, but could do with more assistance when expanding into the cloud.
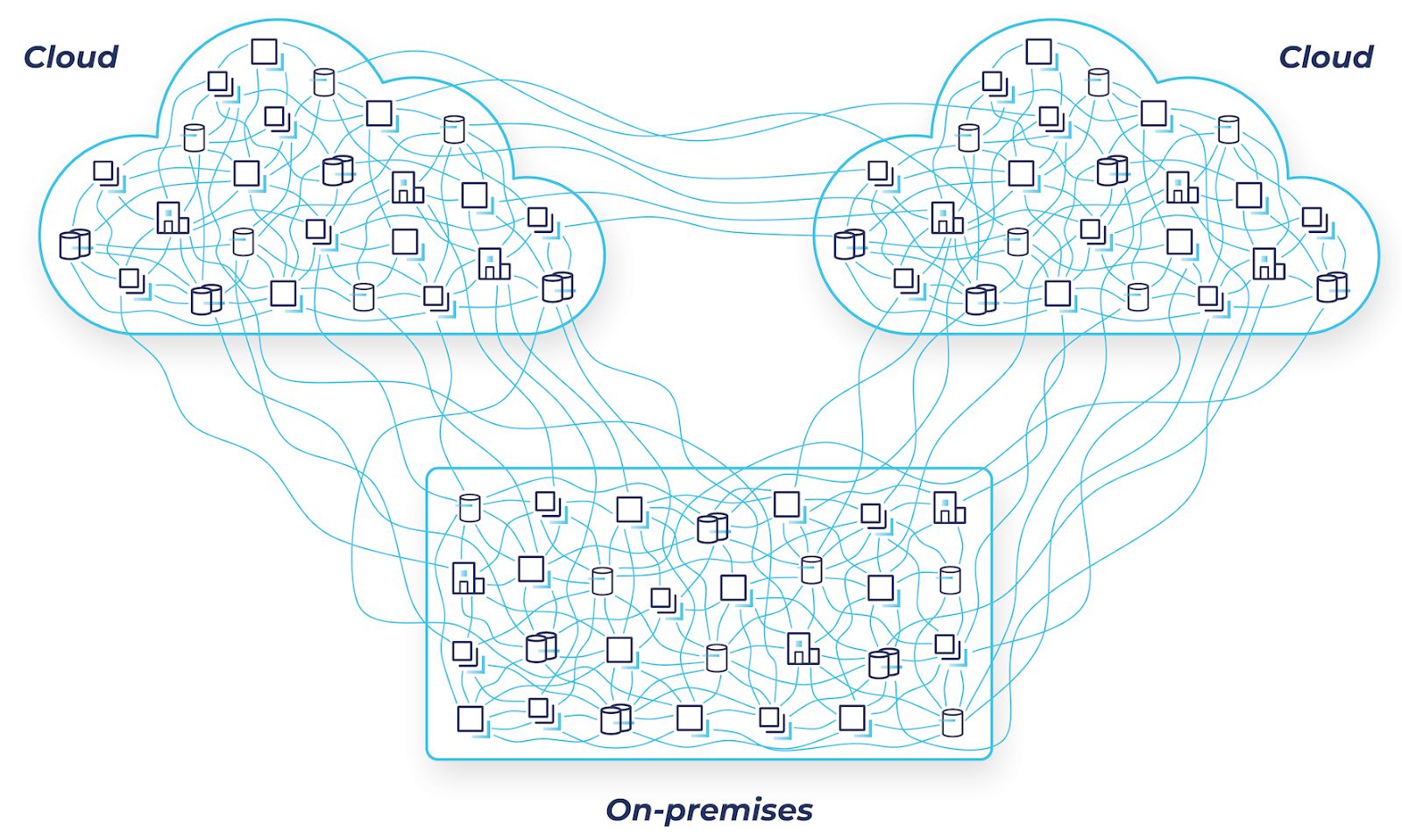
Hybrid cloud is challenging due to the mess of point-to-point connections
That’s why we are excited to show you how Cluster Linking can be the easy-to-use and repeatable solution to your hybrid architecture’s security and networking roadblocks. Cluster Linking—now generally available in Confluent Platform 7.1 and Confluent Cloud—is a built-in capability that mirrors data, topic configuration and structure, and consumer offsets from one Confluent cluster to another in real-time. A cluster link between a Confluent Platform cluster in your datacenter and a Confluent Cloud cluster in a public cloud is a single secure, scalable hybrid data bridge that can be used by hundreds of topics, applications, and data systems.
Hybrid Cloud-Native Geo-Replication
Cluster Linking is geo-replication reinvented for the cloud. It’s built-in, seamless, reliable, secure, scalable, and easy to use.
- Built-in: Cluster Linking is built directly into the brokers, so you don’t need any extra infrastructure or software, like MirrorMaker 2. This simplifies the number of moving parts you’re managing in your hybrid cloud.
- Seamless: Cluster Linking creates identical “mirror topics” from one cluster to another. Mirror topics are byte-for-byte replicas of their source topic, right down to the offsets. This global consistency means that when you move a consumer application from a datacenter to the cloud, it won’t have to translate its offsets. Rather, it can pick up exactly where it left off, for a seamless transition without duplicates, out-of-order messages, or complex custom client-side code.
- Secure: Your security team likely has a DMZ to protect their internal networks, and does not allow incoming connections from the public cloud. Therefore, Cluster Linking separates the direction of the connection from the direction of the data flow. Your datacenter can initiate the connection to Confluent Cloud, so your firewall won’t need to open any holes to allow a public cloud to send connections into your datacenter. Cluster Linking supports all Confluent Platform authentication and authorization mechanisms—Kerberos, OAuth, etc.—and the Confluent Platform credentials never leave on-premises. These tenets will make it easier to pass your security team’s audit.
- Reliable: Cluster Linking can tolerate the high network latencies and instability that can be common when connecting on-premises environments to the cloud, especially if the “datacenter” is actually a factory floor or transport ship. If the two clusters lose connectivity, that’s okay; when they’re reconnected, Cluster Linking will resume automatically and sync any data it missed.
- Scalable: Cluster Linking scales well as your data volumes increase. It’s built into the broker, so it scales with the existing capacity of your cluster. Unlike other Kafka replication tools such as MirrorMaker 2, Cluster Linking doesn’t decompress and recompress messages, so the movement of data is much more efficient.
- Easy to use: A cluster link can be created with just one CLI or REST API command. Then, you can create mirror topics, sync consumer offsets, and promote mirror topics to writable topics with just a few commands. And since hundreds of different applications and data systems can all use one cluster link, these simple commands can accelerate your teams’ application development timelines or cloud migrations. But don’t take our word for it—let’s see what a hybrid cluster link looks like in practice.
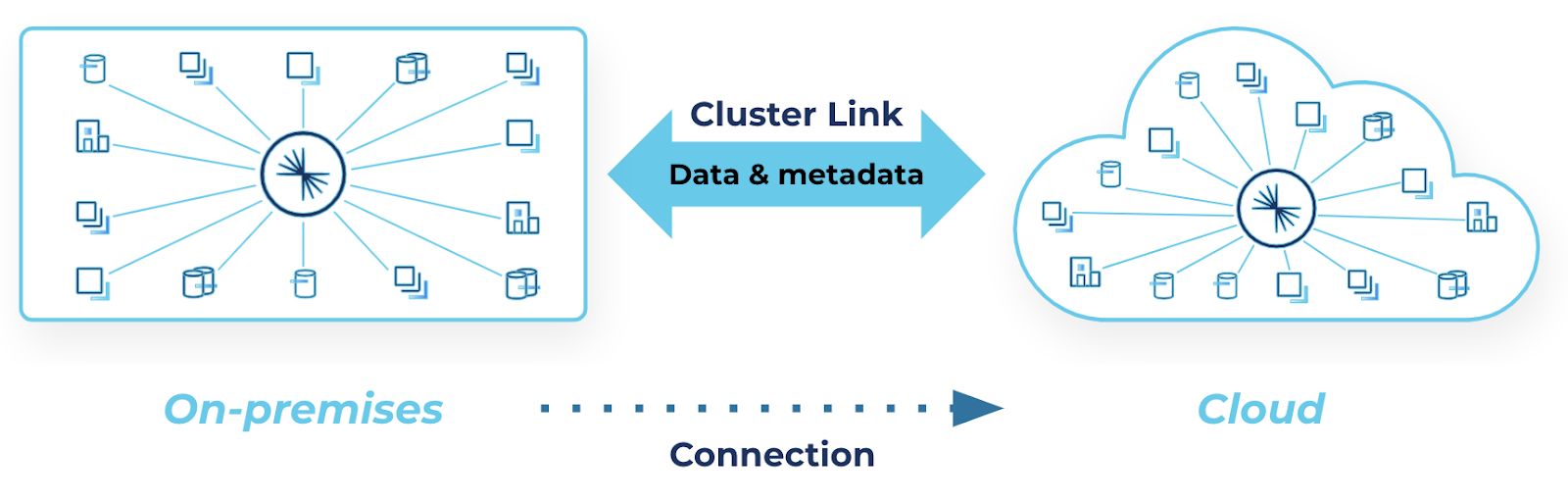
A cluster link can be your hybrid data bridge between on-premises and the cloud
Linking in Action
To create a hybrid cluster link that sends data from on-premises to the cloud, you’ll need a Confluent Platform 7.1 (or later) cluster. You’ll also need a Confluent Cloud cluster—see the documentation for supported Confluent Cloud cluster types. If you don’t have a Confluent Cloud cluster already, you can spin one up in a few clicks. The Confluent Platform cluster needs network connectivity to the Confluent Cloud cluster—but not necessarily the other way around.
In order to create a cluster link to Confluent Cloud with the connection coming from on-premises, you’ll need a “source initiated” cluster link. Making a source-initiated link requires you to create two halves of the single cluster link—one on each cluster.
You first create the Confluent Cloud half of the cluster link. You’ll need a file called cloud-dst-link.config with these two simple configurations, which tell the cluster link that it’s the destination side of a “source initiated” cluster link:
link.mode=DESTINATION connection.mode=INBOUND
The CLI command for that looks like this:
confluent kafka link create onprem-to-cloud \
--config-file cloud-dst-link.config \
--source-cluster-id <CP-cluster-id> \
Because the connection is coming from on-premises, the cloud cluster only needs to know the name of the cluster link and the ID of the Confluent Platform cluster.
Put the security credentials for both the Confluent Platform and Confluent Cloud clusters into a single file on the Confluent Platform cluster. The Confluent Platform credentials never leave the platform and will be used for creating half of the cluster link. The Confluent Cloud credentials are encrypted and securely sent to Confluent Cloud for authentication, creating the other half of the cluster link. That file, which here we’ve called CP-src-link.config looks like this:
link.mode=SOURCE connection.mode=OUTBOUND
bootstrap.servers=<cloud-bootstrap-server> security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule \ required username='<cloud-api-key>' \ password='<cloud-api-secret>';
local.listener.name=SASL_PLAINTEXT local.security.protocol=SASL_PLAINTEXT local.sasl.mechanism=SCRAM-SHA-512 local.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule \ required username="cp-to-cloud-link" password="1LINK2RUL3TH3MALL";
The first two lines tell the cluster link that it is the source side of a source-initiated cluster link. The middle section tells the cluster link where to find the cloud cluster and how to authenticate. The bottom section is the security credentials that the cluster link will use to read topics from the Confluent Platform cluster. In this case, we’ve created a user called cp-to-cloud-link for the cluster link, and given it ACLs for READ and DESCRIBE_CONFIGS on all topics on the cluster.
Finally, you can create the Confluent Platform half of the cluster link with this CLI command:
kafka-cluster-links --create --link onprem-to-cloud \
--config-file CP-src-link.config \
--cluster-id <cloud-cluster-id> \
--bootstrap-server localhost:9092 \
--command-config CP-command.config
That’s it—you now have a hybrid cluster link! You can geo-replicate data from on-premises to the cloud using this cluster link to create mirror topics on the destination cluster. Mirror topics are identical, read-only copies of topics from the source cluster. When you create a mirror topic, the cluster link will start syncing any historical data from its source topic.
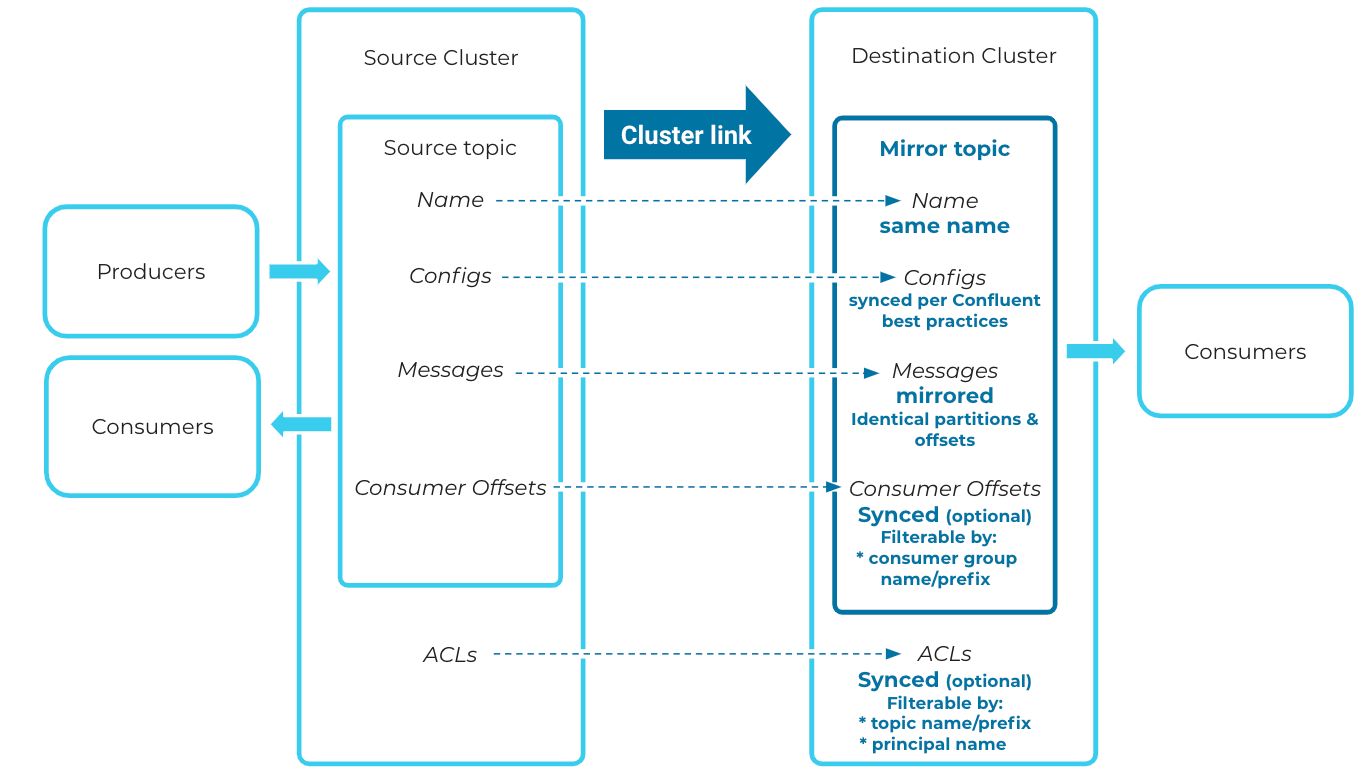
Historical data is synced from source to mirrored topic
Then, as new messages come in on the source cluster, the cluster link will sync them to the destination cluster’s mirror topic in real time. Create a mirror topic on the destination with this command:
ccloud kafka mirror create <topic-name> --link onprem-to-cloud
All of these commands are also available via REST API calls on both Confluent Platform and Confluent Cloud, which can be easy for scripting and integrating with your tooling.
Summary
You can create a secure, seamless hybrid data bridge between your on-premises Confluent Platform cluster and your Confluent Cloud cluster using Cluster Linking, now generally available in Confluent Platform 7.1 and Confluent Cloud. This will help your business execute a hybrid cloud strategy or migrate from a datacenter to the cloud. Cluster Linking is built-in, globally consistent, and designed for the networking and security requirements of hybrid architectures.
If you want to dive deeper, you can read the Hybrid Cloud & Bridge-To-Cloud documentation. To get started using Cluster Linking, download Confluent Platform or sign up for a free trial of Confluent Cloud. You can use the promo code CL60BLOG for an additional $60 of free cloud usage.* Happy linking!
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...