[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Event-Driven Microservices with Python and Apache Kafka
Our journey with microservices, so far…
Back in the days before microservices, we used to build applications that were often hosted in application servers such as WebLogic or WebSphere (apologies for stirring up any painful memories). Clients connected to these server applications using a web browser over HTTP. It worked well, for some definition of “well”. It gave us the flexibility of not having to control the client hardware or software and allowed us to focus on our business logic.
This approach opened the door to doing more and more business transactions online instead of by mail or in person. As the amount of work that these applications handled grew, so did the complexity of the applications themselves. Soon multiple teams were working on the same application, focusing on different feature sets. But these teams had to coordinate changes and deployments because they were all working on a single application, which soon became known as a monolith.
Microservices: the key to modern, distributed systems
Along came microservices. Individual, smaller applications that could be changed, deployed, and scaled independently. After some initial skepticism, this architectural style took off. It truly did solve several significant problems. However, as is often the case, it brought new levels of complexity for us to deal with. We now had distributed systems that needed to communicate and depend on each other to accomplish the tasks at hand.
The most common approach to getting our applications talking to each other was to use what we were already using between our clients and servers: HTTP-based request/response communications, perhaps using REST or gRPC. This works, but it increases the coupling between our independent applications by requiring them to know about APIs, endpoints, request parameters, etc., making them less independent.
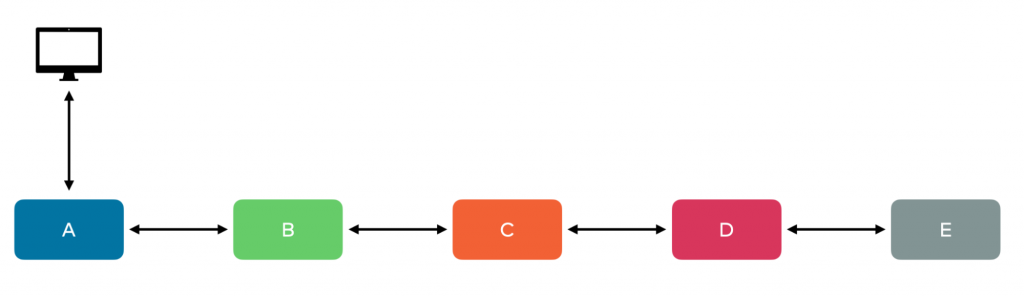
A common, though vastly simplified, design can be seen above. Here a client application, perhaps a web browser or a mobile application, connects to our web server over HTTP. That makes sense, as that’s what HTTP was intended for. Then our web server, service A, makes a call to service B, which makes a call to service C, and so on down the line. Another variation is to let one service act as an orchestrator making calls to other applications, as shown below.
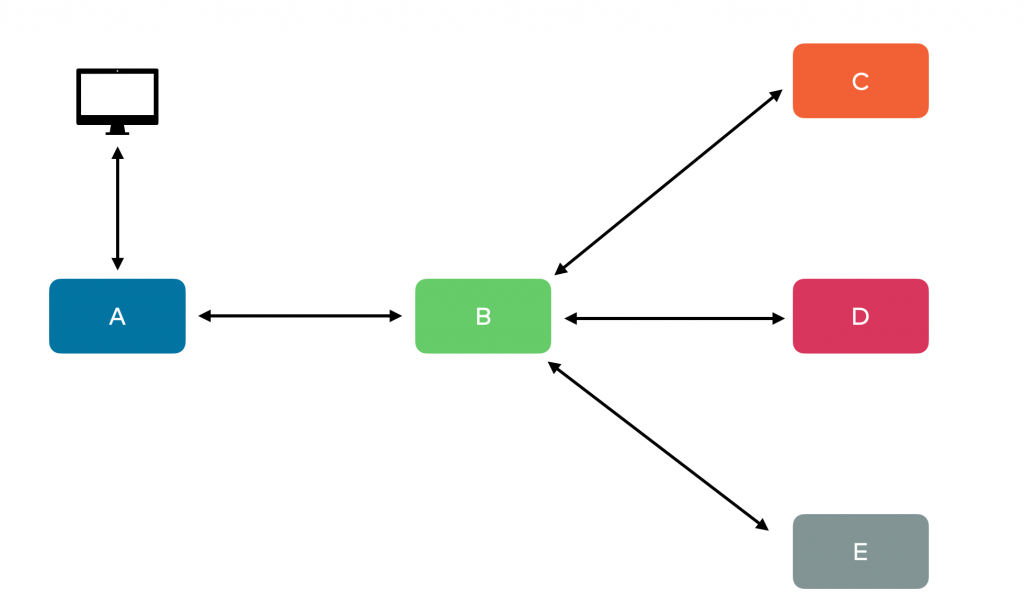
I’ve worked on systems like these several times over the years, and they work well at first. We can use careful API design and tools like Swagger or OpenAPI to help manage the coupling. But as new requirements emerge or existing requirements change, things tend to get more complicated quickly. And even with the best of intentions, we often end up with something more like this:
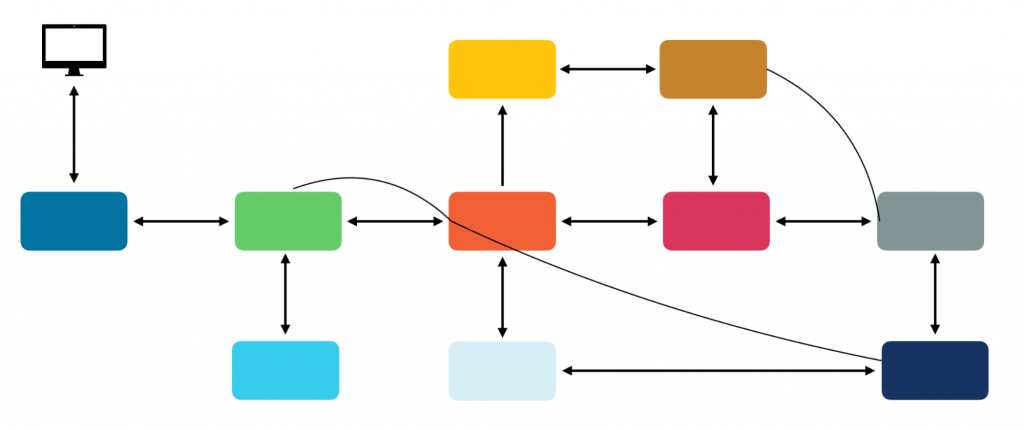
A system of many, highly coupled components becomes almost impossible to maintain or deploy piece by piece, and we lose many of the benefits we gained by moving to microservices.
But there is another approach to microservices—the event-driven architecture. Using events with a platform like Apache Kafka® can dramatically reduce the coupling between our applications and make it easier to keep our microservices from becoming a distributed monolith. Let’s look at how we can use events to build a similar system.
Connecting applications with events
An event is a logical construct that contains both notification and state. In other words, it tells us something happened and it gives us information about what happened. In Kafka, events are posted to topics (logs) by a producer and received by a consumer. These producers and consumers don’t need to know anything about each other. Let’s see how we can take advantage of this when connecting our microservices.
Instead of one application calling another via HTTP, it can produce an event to a Kafka topic. Another application, or more than one other application, can consume that event and take some action. Those applications can then, in turn, produce new events to other topics, either to be acted upon downstream or as final results.
This type of architecture has many benefits, including reduced design-time coupling. None of the applications involved know anything about or have any dependency on the others. Each application listens to the topic(s) that are of interest and produces to topic(s) based on the action they perform. It also makes it easier to extend our systems by adding new applications that can consume the same events without affecting the existing flow.
Because events in Kafka are durable, we can also replay them at a later time or use them to produce data products that can be of value to other parts of the organization.
Let’s try it out
Probably the best way to illustrate event-driven microservices is to build some out together.
Our project
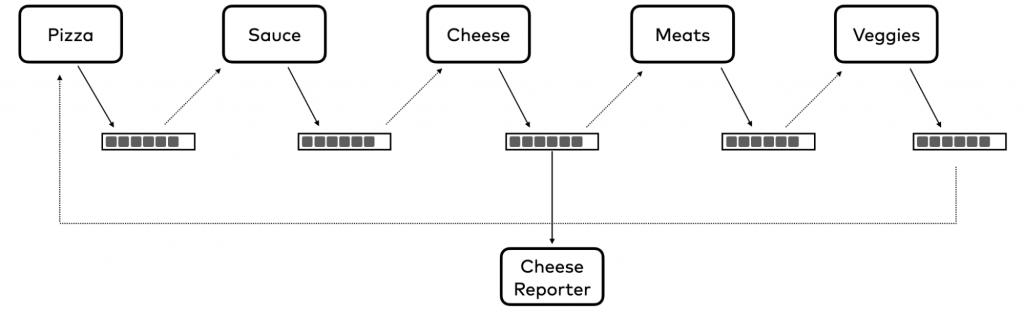
If you’ve ever ordered several pizzas for a team gathering,a birthday party, or something similar, you know how difficult it can be to decide what types of pizza to order. We are going to solve this problem with event-driven microservices by building a random pizza generator using Python, Flask, and Kafka. Here’s our design diagram.
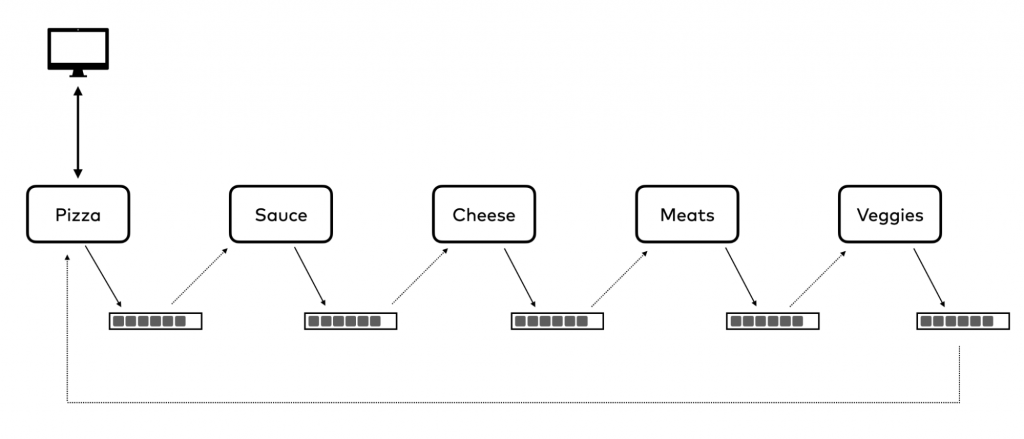
Clients will connect with our initial application, the PizzaService, using HTTP since that’s what it’s best at. They will request a certain number of random pizzas, and our PizzaService will produce an event to the pizza topic for each one. Our SauceService will add a random sauce selection and produce events to the pizza-with-sauce topic. The CheeseService will consume from that topic, add a random cheese selection and produce an event to the pizza-with-cheese topic. The MeatService and VeggiesService will operate in a similar fashion and finally, the PizzaService will consume from the pizza-with-veggies topic, which will contain a completed pizza. Finally, in a separate call, clients will be able to retrieve their completed random pizza order. Let’s get to work.
The pizza service
The PizzaService will be accessible to external clients. We’ll use Flask, a lightweight and easy-to-use Python framework for building web applications.
Our application will have one endpoint /order, with the POST method used to place an order and the GET method used to get it.
Here’s the POST method handler from app.py:
@app.route('/order/<count>', methods=['POST'])
def order_pizzas(count):
order_id = pizza_service.order_pizzas(int(count))
return json.dumps({"order_id": order_id})
When a user posts an order for a certain number of pizzas, this handler will call the pizza_service.order_pizzas() method and pass in the number desired. The function will return the order id and we’ll return that to the client. This id can later be used to retrieve the order with a GET call.
Next, let’s take a look at the pizza_service module. In this module, as in all the others where we are using Kafka, we will import the producer and consumer from confluent_kafka. This package is available at https://pypi.org/project/confluent-kafka and is based on librdkafka, the gold standard for non-Java Kafka clients.
We’ll also use configparser to read our configuration files. For all the details, see the complete project in the GitHub repo.
config_parser.read_file(config_file)producer_config = dict(config_parser['kafka_client'])
pizza_producer = Producer(producer_config)
The pizza_producer will be used in the order_pizzas() function, along with Pizza and PizzaOrder, which are simple value objects.
def order_pizzas(count):order = PizzaOrder(count)
pizza_warmer[order.id] = order
for i in range(count):
new_pizza = Pizza()
new_pizza.order_id = order.id
pizza_producer.produce('pizza', key=order.id,
value=new_pizza.toJSON())
pizza_producer.flush()
return order.id
In this function we first create a PizzaOrder with the count that the user passed in. The constructor for this class assigns a unique id, which will be returned at the end of the function. We then stash the order in the pizza_warmer, a dictionary for holding PizzaOrders while they are in process. Next, based on the count, we enter a loop where we create a new Pizza instance, assign the order.id to its order_id property, and then call the Producer’s produce() function. The produce function takes the name of the topic, the key of the event, and the value. In our case, the topic will be pizzas, the key will be the order.id, and the value will be the Pizza instance as JSON. After completing the loop, we call Producer.flush() just to be sure all of the pizza events have been sent, and then return the order.id. I still can’t get over how easy it is to produce events to Kafka with Python!
The sauce service
We’ll use the sauce-service project as a model for the rest of the services in this system, cheese-service, meats-service, and veggies-service, since they all follow the same pattern.
The core of this application is a Kafka consumer loop, but before we look at that, let’s see how simple it is to set up the consumer.
pizza_consumer = Consumer(client_config)pizza_consumer.subscribe(['pizza'])
Similar to the producer, we construct the consumer instance by passing in the configuration properties that we loaded with configparser. In our example, these properties only consist of Kafka broker location, and credentials along with a consumer group id and auto.offset.reset value. Again, you can get all the details in the GitHub repo.
There is an extra step with a consumer that we didn’t have with the producer, and that is to subscribe to one or more topics. The subscribe method takes a list of topics, and in our case we’re giving it a list of one: ‘pizza’. Now, whenever we call poll() on our consumer instance, it will check the ‘pizza’ topic for any new events. Let’s look at that now.
def start_service():while True:
event = pizza_consumer.poll(1.0)
if event is None:
pass
elif event.error():
print(f'Bummer! {event.error()}')
else:
pizza = json.loads(event.value())
add_sauce(event.key(), pizza)
Within the loop we’re calling pizza_consumer.poll(1.0) which will retrieve events from the subscribed topic, one at a time. As stated in the docs, the consumer is fetching events in a more efficient way, behind the scenes, but is delivering them to us individually, which saves us from having to nest another loop to process collections of events. The number we are passing in, 1.0, is a timeout value in seconds. With this parameter, the consumer will wait up to 1 second before returning None, if there are no new events.
If there is no event, we will do nothing. If the event contains an error, we’ll just log it, otherwise, we have a good event, so we’ll get to work. First, we’ll extract the value of the event, which is our pizza. Next, we’ll pass that pizza, along with the event’s key, to the add_sauce() function. Recall that the event’s key is the order.id.
def add_sauce(order_id, pizza):pizza['sauce'] = calc_sauce()
sauce_producer.produce('pizza-with-sauce', key=order_id,
value=json.dumps(pizza))
The add_sauce() function sets the sauce property of our pizza to the result of the calc_sauce() function, which just generates a random sauce selection (light, extra, alfredo, bbq, none). After that is set, it will use the updated pizza as the value in a produce() call to the pizza-with-sauce topic.
Fast forward
The next service, the cheese-service, will consume from the pizza-with-sauce topic, do its work, and produce to the pizza-with-cheese topic. The meat-service will consume from that topic and produce to the pizza-with-meats topic. The veggie-service will consume from the pizza-with-meats topic and produce to the pizza-with-veggies topic. Hungry yet? Finally, the original pizza-service will consume from the pizza-with-veggies topic to collect the completed random pizza and add it to the pizza_order.
def load_orders():pizza_consumer = Consumer(consumer_config)
pizza_consumer.subscribe(['pizza-with-veggies'])
while True:
msg = pizza_consumer.poll(1.0)
if msg is None:
pass
elif msg.error():
print(f'Bummer - {msg.error()}')
else:
pizza = json.loads(msg.value())
add_pizza(pizza['order_id'], pizza)
This works much the same way the other consumer loops do, but instead of adding something to the pizza that is retrieved from the event, we are passing it to the add_pizza() function. This function will look up the pizza_order in the pizza_warmer dictionary and add the pizza to its internal list. Also, notice that we are using a variable for the topic subscription instead of the string ‘pizza-with-veggies’. That just gives us the flexibility to change the final topic in case we add more steps to our pizza building process down the road.
Adding a consumer to a Flask application
Another important note here: because the pizza-service is a Flask application, we can’t just run our endless consumer loop on startup. That would prevent our application from receiving requests from clients. So, we put our loop into the load_orders() function which we run in a separate thread. To do this we’ll use Flask’s @app.before_first_request decorator in our app.py module.
@app.before_first_requestdef launch_consumer():
t = Thread(target=pizza_service.load_orders)
t.start()
This won’t start until the first request is made, but then if no pizzas have been requested, there won’t be anything to consume, so it all works out.
Retrieving the completed order
After a customer has requested some pizzas they can make a GET call to the same endpoint, passing in the order id, to retrieve their order. Here’s the GET request handler in app.py.
@app.route('/order/<order_id>', methods=['GET'])
def get_order(order_id):
return pizza_service.get_order(order_id)
The get_order() function will find the pizza_order in the pizza_warmer and render it as JSON to be returned to the client.
With all of our applications running, we can issue a simple curl command to order some pizzas.
curl -X POST http://localhost:5000/order/2
This will call our Flask application and cause it to send two pizza events to the pizza topic. The rest of the applications will do their work purely based on the events that are consumed and produced, and the user will get back an order id like this:
{"order_id":"199467350823967746698504683131014209792"}
Another curl command, this time piped to jq, will return our delicious ready-to-bake pizzas.
curl http://localhost:5000/order/1994673508239677466…792 | jq{
"id": "199467350823967746698504683131014209792",
"count": 2,
"pizzas": [
{
"order_id": "199467350823967746698504683131014209792",
"sauce": "bbq",
"cheese": "extra",
"meats": "pepperoni & ham",
"veggies": "tomato & pineapple & mushrooms"
},
{
"order_id": "199467350823967746698504683131014209792",
"sauce": "extra",
"cheese": "goat cheese",
"meats": "anchovies & bacon",
"veggies": "peppers & mushrooms"
}
]
}
Ok, I guess I can’t vouch for the deliciousness of these particular pizzas, but I can say that we just connected five microservices with very little design-time coupling using events stored in Kafka topics.
More thoughts on coupling
Let’s draw your attention to the previous paragraph in regards to coupling. First, we said that we had very little and not “none”. It’s not possible to remove all coupling between systems that are all involved in a single outcome, but we can and should try to reduce coupling when we can. In our example, we still have coupling at the event level. More specifically, the schemas of the events. For example, the sauce-service will produce events, with a certain schema, to the pizza-with-sauce topic. The cheese-service will consume those events and it will have to know about the schema of those events. We can manage the impact of schema coupling by using a tool like Confluent Schema Registry.
The second thing we should highlight is the phrase “design-time coupling”. Our example focused on reducing design-time coupling which makes it easier to work on and deploy applications individually. There is still some runtime coupling between our applications in that a failure in one of them will prevent the entire system from completing. We do avoid cascading failures, but we won’t get any completed pizzas if any of the services are down.
Event-driven architecture can also help reduce runtime coupling as we can see from a new service that we added, called the cheese-reporter. This application will consume from the pizza-with-cheese topic and whenever it receives an event it will update a report on the most popular cheese selections in our random pizzas. This service will always return a report when asked, regardless of the status of the cheese-service or any of the other services. If the cheese-service is down for any length of time the report might become stale (to say nothing of the cheese), but the cheese-reporter service will still fulfill its requests. We won’t go into the code for this service, but it is included in the GitHub repo mentioned earlier.
Conclusion
This is obviously a trivial example but it does show how simple it can be to use Apache Kafka to build event-driven systems in Python, and how that can help us build more loosely coupled, easier to maintain applications.
You can check out the entire project along with some instructions for getting it running with Confluent Cloud, from the demo-scene GitHub repository. Then you can try some variations on this design to get some hands-on experience. One suggestion is to have the four downstream services all consume from the initial pizza topic, do their work and produce to their own topics, and then have another service that consumes from those four topics and joins them to build the completed pizzas. Or for a simpler challenge: add a service that consumes from one of the topics and performs some sort of aggregation. This will show how easy it is to extend our architectures without affecting the existing applications. If you do try something like this out, drop me a note. I’d love to hear how it went.
Python and Kafka are both amazing tools to help us get more done in less time and have more fun doing it. There are tons of resources available for learning both, so dig in and enjoy the journey!
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


