It’s Here! Confluent’s 2026 Data + AI Predictions Report | Download Now
Event Driven 2.0
In the future, data will be as automated and self-service as infrastructure is today. You’ll open a console that lists the data available in your company; define the pieces you need, the format you want and how you would like it joined together; spin up a new endpoint: a database, cache, microservice or serverless function and off you’ll go.
These are the event-driven architectures of the modern age—but ones where messaging is far more than a simple pipe that connects systems together. Part messaging system, part distributed database, streaming systems let you store, join, aggregate and reform data from across a company, before pushing it wherever it is needed, be it a hulking data warehouse or a tiny serverless function.
When combined with public and private clouds, where infrastructure can be provisioned dynamically, the result makes data entirely self-service. Many companies have implemented some version of this future.
The different approaches they take can be split into four broad patterns, and the companies and projects we see typically adopt them one at a time:
1. Global event streaming platform
2. Central event store
3. Event-first and event streaming applications
4. Automated data provisioning
No one company that we know of has mastered them all, but all these categories exist in production in one form or another.
1. Global event streaming platform
This is the easiest to grok, as it is similar to the enterprise messaging patterns of old. The organization moves to an event-driven approach with core datasets (those shared between applications, such as orders, customers, payments, accounts, trades, etc.) flowing through an event streaming platform like Apache Kafka®.
These replace legacy point-to-point communications with a single piece of infrastructure that lets applications operate across different geographies or cloud providers, at scale and in real time.
So, a company might run a legacy mainframe in San Francisco, have regional offices in Cape Town and London, as well as have highly available microservices running across AWS and GCP—all connected with the same event backbone. More extreme use cases include connecting ships via satellite or automobiles via mobile.
Companies implement this pattern in almost every industry. Examples are Netflix, Audi, Salesforce, HomeAway, ING and RBC, to name a few. 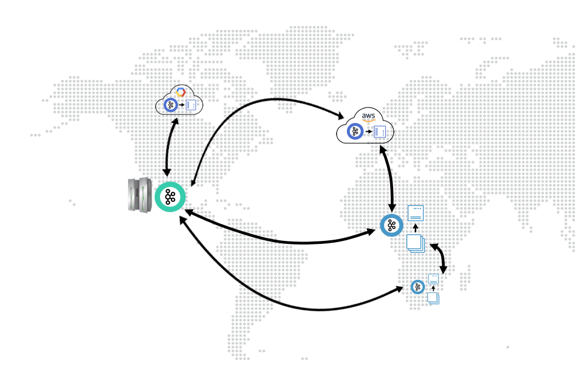
2. Central event store
Streaming platforms can cache events for some defined period of time or store them indefinitely, creating a kind or organizational ledger or event store.
Some companies use this pattern to drive retrospective analysis, for example training the machine learning models used in fraud detection or rewinding time in Formula 1 post-race analysis. Others apply the pattern across many teams.
This lets new applications be built without requiring source systems to republish prior events, a property that is particularly useful for datasets that are hard to replay from their original source, such as mainframe, external or legacy systems.
Some organizations hold all their data in Kafka. The pattern is termed a forward event cache, event streaming a source of truth, the Kappa Architecture or simply event sourcing.
Finally, event storage is required for stateful stream processing, which is often applied to create enriched, self-sufficient events from many different data sources. This could be enriching orders with customer or account information, for instance.
Enriched events are easier to consume from microservices or FaaS implementations because they provide all the data the service needs. They can also be used to provide a denormalized input for databases. The stream processors that perform these enrichments need event storage to hold the data that backs tabular operations (join to customers, accounts, etc.). 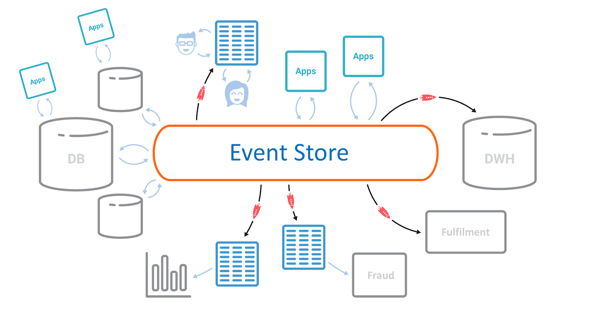
3. Event-first and event streaming applications
Most traditional applications work by importing datasets from different places into their database (e.g., ETL), where it can be cleansed, joined, filtered and aggregated.
For applications that create reports, dashboards, online services, etc., this remains the best choice, but for business processing, it is often more efficient to skip the database step by pushing real-time events directly into microservices or serverless functions.
In such approaches, stream processors like Kafka Streams or ksqlDB perform the data manipulation that the database did in the traditional approach by cleansing, joining, filtering and aggregating event streams before they are pushed into the microservice or FaaS.
As an example, consider a limit checking service that joins orders and payments together using a stream processor like ksqlDB, extracting the relevant records/fields and passing them into a microservice or function as a service that checks the limit—a workflow in which no database is used at all.
Due to their event-driven nature, such systems are more responsive. They are also typically simpler and faster to build, as there is less infrastructure and data to maintain, and the toolset naturally handles asynchronously connected environments.
Richer examples incorporate stream analysis directly, such as detecting anomalous behavior in credit card payments or optimizing energy delivery in a smart power grid. Such systems often exist as chains, where the stages separate stateful and stateless operations, can scale independently and leverage transactional guarantees for correctness.
We see applications of this type crop up across many industries: finance, gaming, retail, IoT, etc., spanning both offline and online use cases. 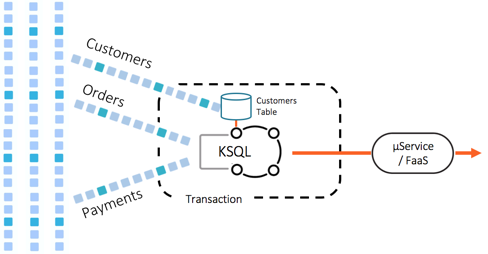
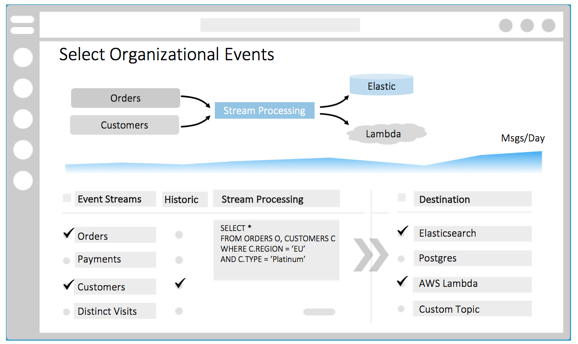
4. Automated data provisioning
This final pattern is the culmination of the others, blended with PaaS/serverless implementations to make data provisioning entirely self-service.
A user defines the data they require (real time or historical), what form it should take and where it should be landed, whether in a database, distributed cache, microservice, FaaS or wherever. (Typically, this is used in association with a central repository of schemas which is made discoverable.)
The system provisions the infrastructure, pre-populates it where necessary and manages the event flow. A stream processor filters, manipulates and buffers the various shared data streams, moulding them to the user’s specification.
So, a finance user doing risk analysis might spin up a new Elasticsearch instance pre-populated with three months’ trades, risk results and books. Or, a retail company might join real-time orders, payments and customer data, and push them into a microservice or FaaS that sends the customer a payment confirmation.
As organizations move to public and private clouds, the dynamic nature of cloud-based infrastructure makes this pattern increasingly practical, leading to systemic benefits. New projects, environments or experimentation can be quickly initiated.
Because datasets are cached or stored in the messaging system, users are encouraged to take only the data they need at a point in time (unlike traditional messaging where there is a tendency to consume and hoard whole datasets in case they are needed again later). This minimizes friction between teams and keeps applications close to a single, shared source of truth.
Few organizations that we know of have fully achieved this level of automation, but core elements of this pattern are used in production at several of our customers in the finance, retail and internet domains, both on premises and in the cloud.
Event driven 2.0: An evolution and a new beginning
Event-driven architectures have evolved naturally over the years. Originally, they only did message passing: notification and state transfer applied with traditional messaging systems.
Later, enterprise service buses embellished these with richer out-of-the-box connectivity and better centralized control. Centralized control turned out to be a mixed blessing, as the standardization it provided often made it harder for teams to progress.
More recently, storage patterns like event sourcing and CQRS have become popular, as discussed by Martin Fowler in his article What do you mean by “Event Driven”?
The four patterns that I’ve described all build on this foundation, but today’s modern event streaming systems allow us to go even further by unifying events, storage and processing into a single platform. This unification is important, because these systems aren’t databases which lock data up in a single place; they aren’t messaging systems, where data is fleeting and transitory. They sit somewhere in between.
By striking a balance between these two traditional categories, companies have been able to become globally connected across regions and across clouds, with data—their most precious commodity—provisioned as a service, whether that means pushing it into a database, cache, machine learning model, microservice or serverless function.
So, in summary:
- Broadcast events
- Cache shared datasets in the log and make them discoverable.
- Let users manipulate event streams directly (e.g., with an event streaming database like KSQL)
- Drive simple microservices or FaaS, or create use-case-specific views in a database of your choice
Find out more
To find out more about event-driven systems and how to implement them:
- Download the free O’Reilly book Designing Event-Driven Systems
- Watch Confluent CEO Jay Kreps explain event-driven architectures
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.



Developer Experience in the Age of AI: Developing a Copilot Chat Extension for Data Streaming Engineers
AI is bringing changes in developer experience… we shared what we learned in this article about creating our new GitHub Copilot chat extension for data streaming engineers.