[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Saxo Bank’s Best Practices for a Distributed Domain-Driven Architecture Founded on the Data Mesh
 Al data til folket (all data to the people) is a compelling proposition in an enterprise context. Yet the ability to quickly address integration challenges and deliver data to those who can unlock insight and innovate is a distant dream for many organisations.
Al data til folket (all data to the people) is a compelling proposition in an enterprise context. Yet the ability to quickly address integration challenges and deliver data to those who can unlock insight and innovate is a distant dream for many organisations.
Whilst adhering to regulations such as GDPR and BCBS 239 can be challenging, they are no more than best practise guidelines for a modern data platform. Forward-thinking organisations require a data fabric that addresses common nonfunctional requirements together with an operating model that recognises the strategic value of data.
This blog post outlines how Saxo Bank approached this vision through the adoption of a data mesh architecture. Driven by the Data Platforms team, this change has required us to completely rethink our use of data across the organisation.
Image reproduced with the permission of Superflex
Distributed data management at scale
Whilst the tech industry has made great progress over the past two decades to scale data processing, it has largely failed to scale data management at an organisational level. This is as much about ways of working as it is technological change. In short, we need to start thinking about data as a product and consider the ease with which it can be published, discovered, understood, and consumed.
Data mesh is an architectural paradigm that has slowly gained traction since it was first proposed by Zhamak Delgahni in 2019. Saxo Bank was on a similar path as we embarked on implementing a new data architecture in late 2018 and soon realised that our thinking was closely aligned.
Given the growing base of literature around Delgahni’s original vision, this blog post does not attempt to duplicate efforts. Instead, we will outline how Saxo approached this architectural paradigm, beginning with the key tenets of data mesh; how Saxo has started to bring it to life; and the challenges that lie ahead.
- Distributed domain-driven architecture
- The antithesis to the data monolith is a decentralized, federated architecture that forces you to rethink the locality of processing and ownership.
- Instead of flowing the data from domains into a centrally owned data lake or platform, data mesh stipulates that data domains should host and serve their domain datasets in an easily consumable way.
- Self-serve platform design
- As outlined in the 2020 State of DevOps Report, a high DevOps evolution correlates strongly with self-service capabilities, as it allows application teams to be more efficient, controls to be improved, and platform teams to focus on continuous infrastructure improvement.
- In this context, Saxo’s self-service platform moves beyond pure infrastructure to one that is focused on enabling domain teams to publish their own data assets and use those published by other teams.
- Data and product thinking convergence
- At Saxo, we think about data as a product and believe that the product’s usability can be directly attributed to the ease with which it can be discovered, understood, and used. Domain data teams are encouraged to apply product thinking to the datasets that they provide with the same rigour as they would with any other capabilities.
Distributed domain-driven architecture
The data domains relevant to Saxo are no different to any other investment bank or brokerage. Producer-aligned domains such as trading represent the transactions (facts) of the business, master datasets such as the party provide the context for such domains, and consumer-aligned domains such as risk tend to consume a lot of data but produce very little (e.g., metrics).
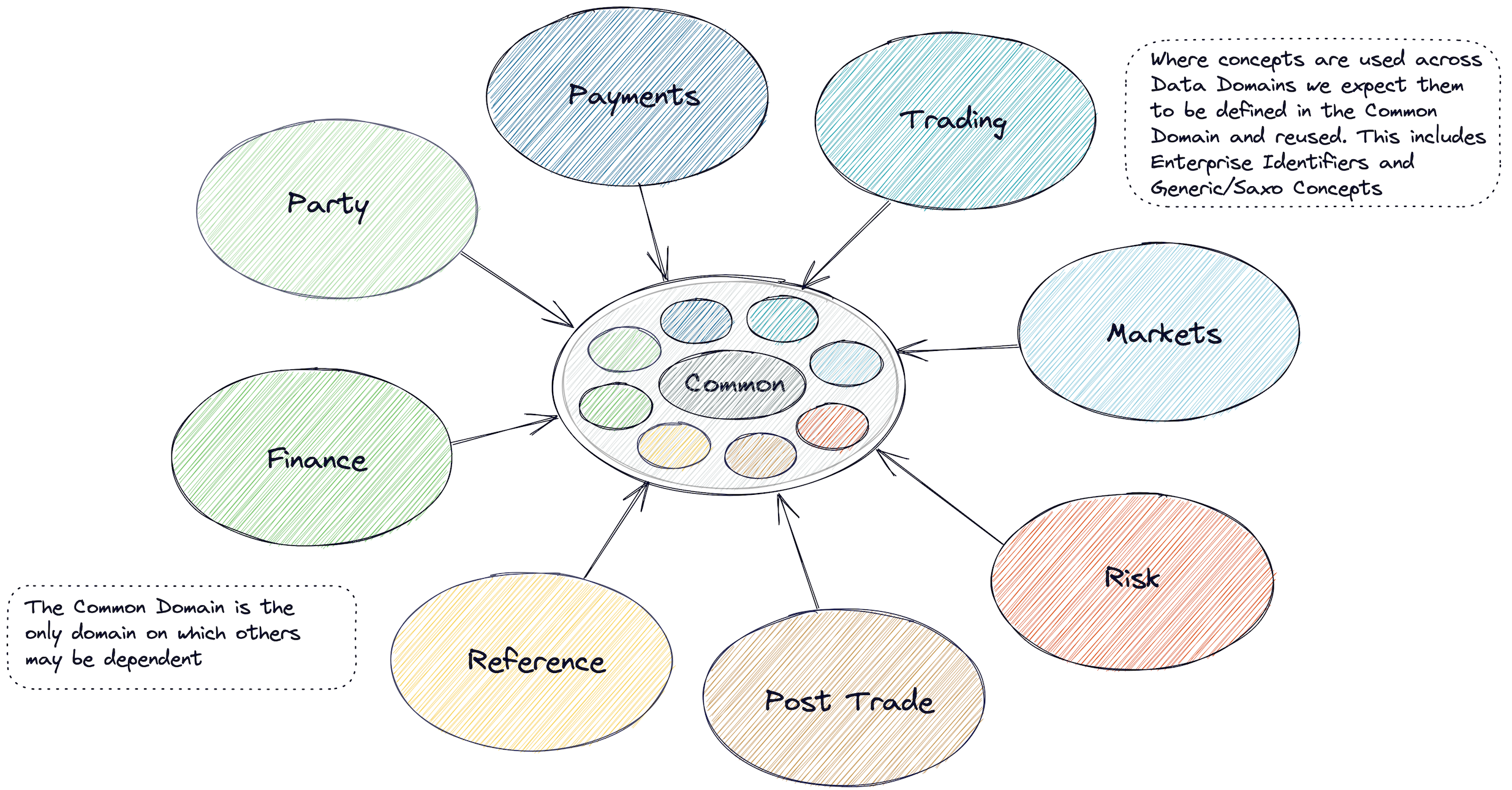
Figure 1. Data domains
Given the pace of change across the organisation, we knew that we couldn’t rely on a central team to create and populate a canonical data model for the enterprise. Our approach must scale. Instead, we federated the ownership of domain data and their representations and centralised oversight.
The challenge is to ensure that the whole is greater than the sum of the parts—that domains “mesh” and do not live in a vacuum. Figure 2 illustrates Saxo’s data operating model. The intention is that “just enough” governance allows for:
- Consumers to be decoupled from producers (events over commands)
- Authoritative sources to be identified and agreed upon
- A standard language to emerge and ensure that information can be efficiently used across the business; this standard or “ubiquitous” language is central to the idea of domain-driven design (DDD) as a means for removing barriers between developers and domain experts
- The common domain plays a key role in this as we look to standardise the fundamental concepts in use across the Bank
In conjunction with our colleagues in the Data Office, we also see this as an opportunity to ensure that ownership is anchored appropriately (typically in the business) and to start a conversation about the data issues and strategy for each domain.
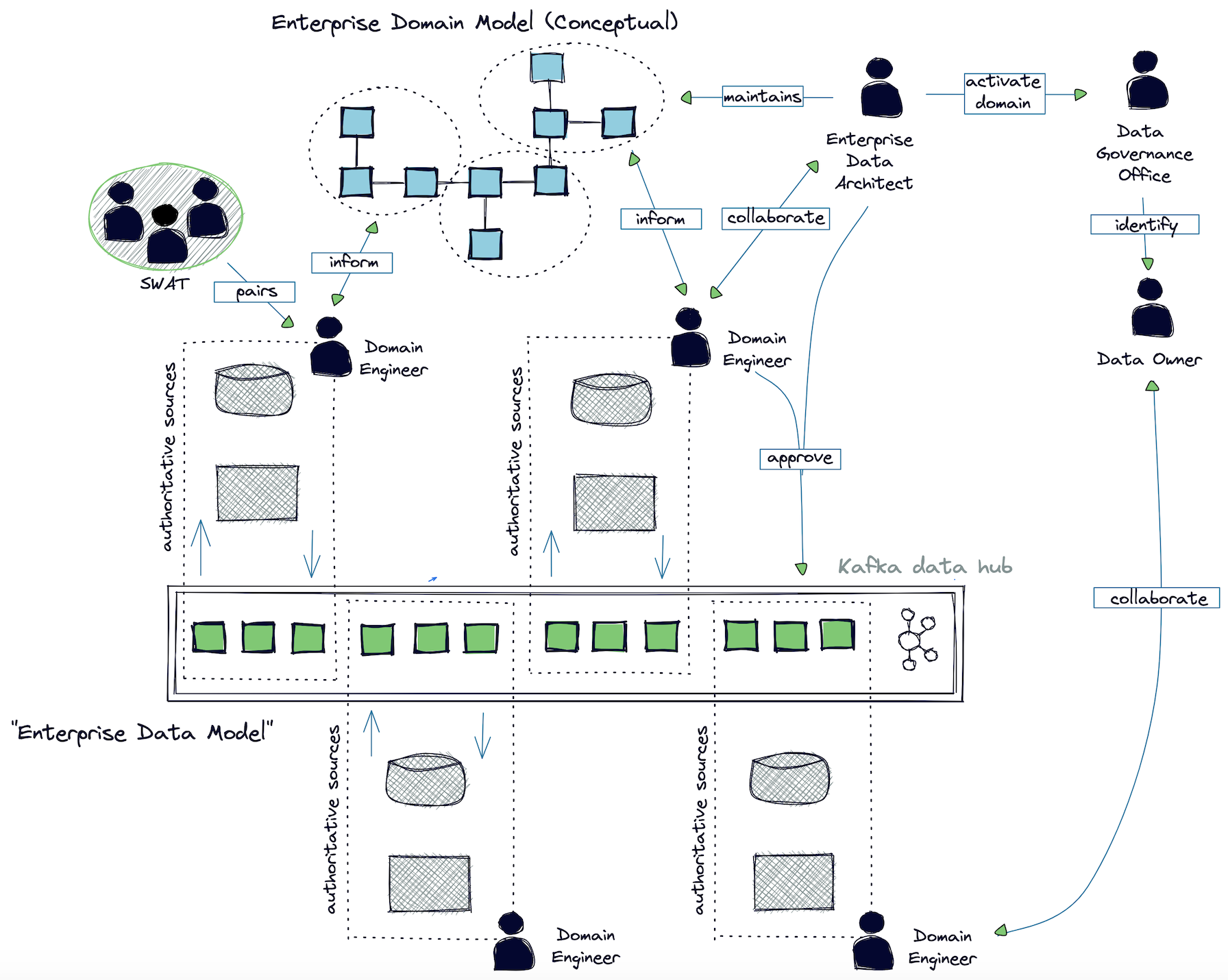
Figure 2. Data operating model
- The Domain Team is responsible for:
- Identifying the authoritative source for a dataset
- Creating the relevant data model(s)
- Making data products available to other teams through the data fabric
- Remediation of data quality (DQ) issues; issues should be fixed at the source, not on consumption
- The Enterprise Data Architect is responsible for:
- Curating and shaping our data domains into something that has long term value for Saxo
- Approving changes to physical domain models
- Collaborating with domain teams to develop the conceptual model
- The Data Governance Office is responsible for:
- “Activating” data domains, including identifying ownership, known data quality
issues, etc.
- “Activating” data domains, including identifying ownership, known data quality
The domain language manifests itself in the conceptual model (the challenge is to keep it as light as possible) and the physical model (which we embellish with metadata). We are not concerned with generating the physical model from a conceptual diagram as we believe that this switches the focus away from reasoning about a domain to visual programming.
This process isn’t easy, and we’ve only just begun. The review step certainly plays a role, as does education and building a community of practise. Schemas that are consistently well named, well documented, semantically strongly typed, and changed in small increments are quickly approved. Those which aren’t will inevitably take longer.
Furthemore, the process also relies on an acceptance that we won’t get it right the first time and on-going curation of the domain models will be required. Indeed, the role of the enterprise data architect could equally be described as a “data custodian.” Learn, iterate, and improve.
Of course, operating models are dynamic, and this simply serves as a point-in-time reference.
Self-service platform design
Data mesh is an architectural paradigm that is technology agnostic. At Saxo, we have embraced Confluent as the foundational layer of our data fabric—an authoritative interface to data domains, alongside a more traditional request-response interface.
Despite the simplicity of Apache Kafka®’s log-based underpinnings, introducing it as an enterprise backbone is not without its challenges. Our intention is to free domain teams from having to think about the mechanics of deploying connectors, generating language bindings, how to deal with personally identifiable data, etc. This isn’t trivial, especially considering the breadth of development platforms—predominantly C#, but we’re already working with teams who are using Python, C++, and now Kotlin.
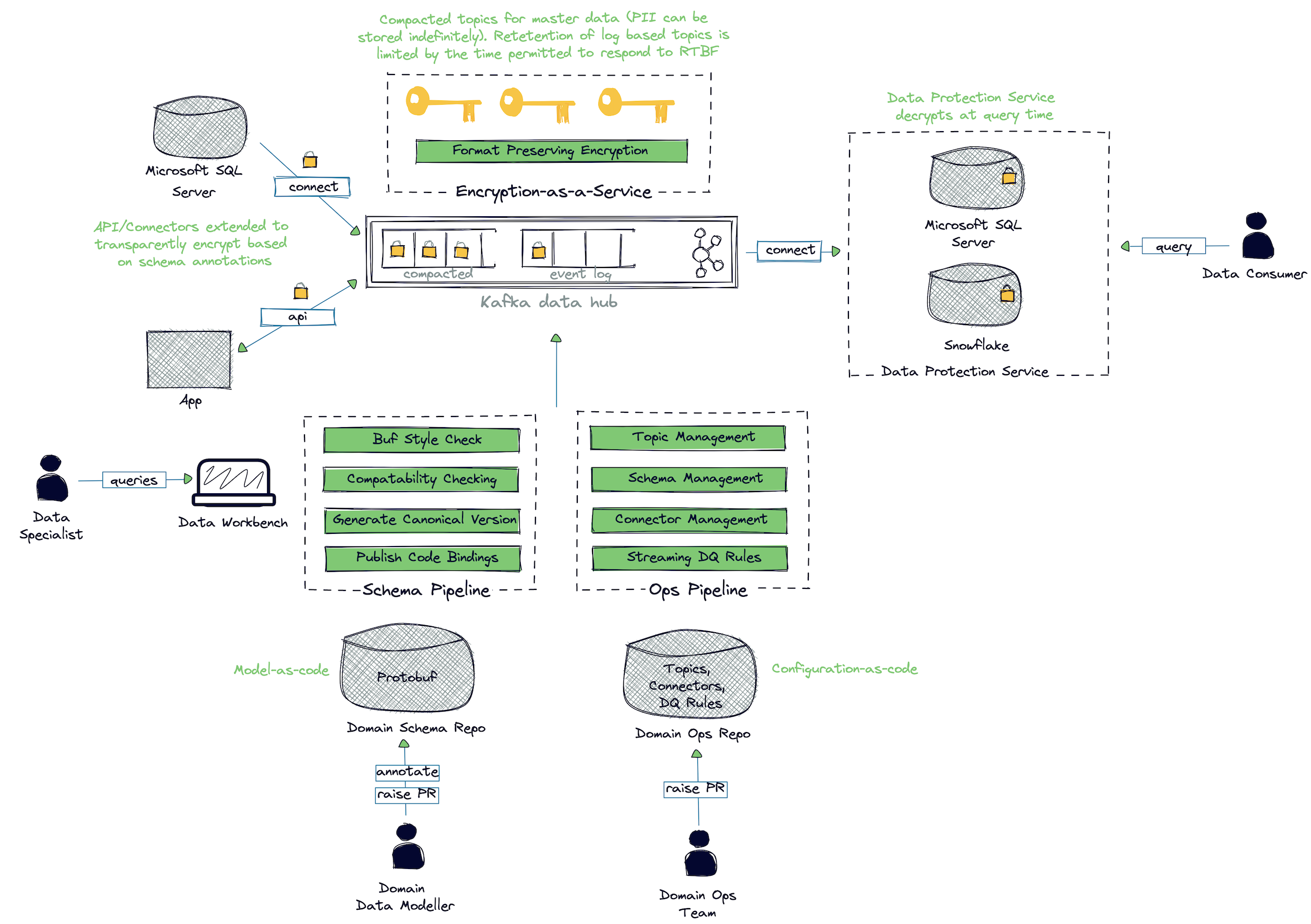
Figure 3. Saxo Bank’s architecture
Our self-service capability leans heavily on GitOps, with each data domain managed through two repositories:
- Operational
- Topic configuration including ACLs
- Management of Kafka connectors
- Data quality rules, expressed using Great Expectations’ DSL
- Schema
- Protobuf schema validation and approval
- Generation of code bindings for all supported languages and publication to our artifact repository
Discoverability isn’t just about the structure of the data—it’s also about enabling data specialists across the bank to understand lineage, ownership, and the relative health of data products (expressed as a series of quantitative metrics).
To address this, metadata and metrics are published to the Data Workbench—our implementation of LinkedIn’s open source project DataHub—giving data specialists across the bank visibility into the data assets published to Apache Kafka and their relationships. There’s a lot of scope to improve here, for example, allowing metadata curation to take place in the tool itself rather than directly in schema files.
Data and product thinking convergence
The (data) product’s usability comes down to the ease with which it can be discovered, understood, and consumed. An advantage of the centralised architecture is that it’s a lot easier to maintain a consistent user experience across the different data domains and ensure that users are able to transfer their mental model from one domain to another. Our federated architecture requires a different approach altogether.
With this in mind, our self-service platform takes a somewhat opinionated view on how Kafka should be used in Saxo. Standard pipelines ensure a common approach across all domains—style checking, generation of code bindings, data quality rule execution/reporting, and how metadata is pushed to the Data Workbench, among others.
We strive for data assets to be self-describing and for concepts to be explicitly represented. Our belief is that through the consistent and effective use of metadata in and across domains, we can improve the usability of the data and the time to market for new data products. Fundamentally, we do not expect the shape of the producer’s data to change significantly, at least in the first instance. Small changes can make a big difference:
- Employ a consistent style guide across domains
- Place a great deal of emphasis on strong typing (“Currency” carries business meaning that “string” does not)
- Align with industry standards wherever possible
- Document everything
- Prohibit “magic values”
- Capture the information classification at the source
- Link relevant concepts
This information is then surfaced through the Data Workbench which plays a key role in our implementation—not just for the discovery of data assets, but the belief that creating visibility of each data domain and asset in terms of meaning, ownership, and quality will help drive continuous improvement.
Effective schemas
So, how do we go about encouraging a consistent look and feel to our data across each data domain? The following section touches upon best practices that we encourage teams to think about as they design their data contracts, beginning with the message format itself.
Choosing a format
There are many articles that discuss the merits of different serialisation mechanisms for structured data, for example, Schema Evolution in Avro, Protocol Buffers, and Thrift by Martin Kleppmann. Typically, these are concerned with schema management and encoding efficiency.
One consideration that is often overlooked is the ease with which semantic annotations (aka metadata) can be embedded into the schema. Although XSD (XML’s schema definition language) gets a bad rap, standards such as FpML have proved to be very successful in global banks because they allow a greater level of rigour around message definitions than would otherwise be the case. Indeed, given the open nature of FpML, many have used this as a foundation for their own ubiquitous language.
However, with XML no longer de rigueur, we looked to alternatives—in particular, those currently supported by Confluent: Avro, JSON, and Protocol Buffers (Protobuf).
When looking at the feasibility of using JSON encoding, the FpML Architect Working Group noted that it was simply not possible to express the same diverse set of data types and language constraints in JSON. Apart from anything else, the only reliable way to express a decimal value is to encode it as a string. Furthermore, JSON Schema does not have a way of expressing custom semantic annotations. For these reasons, we did not consider JSON Schema.
Avro fares slightly better in this context, particularly when used in conjunction with Avro interface definition language (IDL), which allows for schema composability. We can express semantic annotations as loosely typed name-value pairs to add additional properties to types and fields. Although Avro defines a small set of primitives, the language has been extended to include a number of core logical types (decimal, UUID, date, and time).
Protobuf takes it a step further by allowing strong message types and field-level annotations using “custom options.” This enables compile time checks, which is, of course, advantageous.
Another consideration is the maturity of language bindings. Whilst Saxo originally opted for Avro, we reluctantly came to realise that this was a major point of friction in our rollout. The C# and Python implementations lagged behind the JVM, and although we did contribute a few fixes (thanks to the support of Matt Howlett), we felt that rallying support around the C# implementation was going to be too much of a distraction.
Another advantage of Protobuf over Avro is that your bindings will follow the stylistic norms of your target language for types and attributes, irrespective of the naming convention used in the schema. Although this might seem like a trivial point, it’s another source of friction if not properly accounted for.
We eventually switched to Protobuf in late 2020, not long after it was supported as a first-class citizen by the Confluent Schema Registry. Certainly for the language bindings of interest—C#, Python, C/C++, and as Kafka Streams gains more interest, the JVM—we’ve found the implementations to be more consistent than was the case with Avro.
Self-describing schemas
For those unfamiliar with Protobuf, rest assured that if you’ve mastered the intricacies of XSD, you’ll find it’s a walk in the park.
In short, complex types are represented as a “message” irrespective of whether it’s an event or a type referenced by an event. Although the syntax varies slightly, “options” (i.e., semantic annotations) can be expressed at the level of message (type) or field (attribute). For more details, see the Proto3 Language Guide.
Naming
Naming is hard, but use of Uber’s Style Guide encourages consistency and provides a well-thought-out approach to versioning.
We also have many guidelines that you’d expect to see in any coding standard: Singular values should have a name in the singular, repeated fields should have a plural name, etc.
Documentation
Documentation is required for all records and attributes. Even seemingly obvious fields often have non-obvious details.
Identifiers
The consistent use of enterprise identifiers is one of the key requirements in making this distributed model work. Consider, after all, the meaning behind the word mesh: “to join together in the correct position.” Identifiers uniquely identify an entity and can be thought of as the “primary keys” of a domain, which is one of the foundational principles behind our data mesh implementation.
Identifiers are defined using Protobuf’s IDL as follows:
// This is how we pass 'Thing' by reference
message ThingIdentifier {
int64 id = 1;
}
By convention, we name the sole attribute of the identifier as id for numeric identifiers and code for alphanumeric identifiers. Enterprise identifiers, which are prevalent across domains, must be defined in a common way.
References
References can be thought of as alternate identifiers with weaker constraints. For example, a PaymentReference may be a free-form text field provided by a customer. Here is an example:
// User supplied reference. Not necessarily unique
message ThingReference {
string ref = 1;
}
By convention, we name the sole attribute of the reference as ref (typically of type string). Enterprise references must be defined in a common way.
Enumerations and schemes
A number of data elements are restricted to holding only one of a limited set of possible values. Such restricted sets of values are often referred to as enumeration.
Protobuf, similar to many other languages, supports the use of enumerated types. Where the range of values is small (e.g., < 10) and not expected to change often, it is perfectly acceptable to use an enum. However, it is generally expected that types will refer to an external coding scheme, a concept taken from FpML.
Schemes are referenced in the IDL as follows:
// Currency as represented by the three character alphabetic code as per ISO 3166
// https://www.iso.org/iso-4217-currency-codes.html
// https://spec.edmcouncil.org/fibo/ontology/FND/Accounting/CurrencyAmount/Currency
message CurrencyIdentifier {
option (metadata.coding_scheme) = "topic://reference-currency-compact-v1";
// Alphabetic (three letter) code
string code = 1;
}
In this example, the reader is directed towards the compacted topic reference-currency-compact-v1 for the definitive list of currency codes and their meaning.
Schemes not only help the recipient understand the range of values, but they also open the door to automated data quality monitoring. Ideally, schemas reference another topic, but we’re (almost) as happy if teams reference the documentation.
Information classification
Saxo defines four classifications of information, each implying a specific level of sensitivity. This is reflected in the schema illustrated below:
// Name of a natural person
message Name {
option (metadata.msg_info_class) = INFO_CLASS_PERSONAL;
// The given name or first name of a person, that is the name chosen for them
// at birth or changed by them subsequently from the name give at birth
string given_name = 1;
}
Although this is expected to be reflected at the message level, there may be valid reasons for expressing this at the field level. In this case, the field_info_class option should be specified. If not stated, a default ‘internal only’ classification is assumed.
A key part of our journey into the cloud is to ensure that PII data is encrypted. It is our intention to eventually drive this directly from the schema annotations, freeing development teams from concerning themselves with such details.
External schema
Although we have standardised on Protobuf, we support the idea of ‘bring your own schema’ for some use cases. In this case, the actual schema used must be explicitly referenced using the external_schema option:
// An example of an external schema
message EventWithExternalSchema {
XmlString vendor_string = 1 [(metadata.external_schema) = "https://example/third-party.xsd"];
}
Note that whilst the payload as represented by vendor_string may contain a reference to third-party.xsd, it must be explicitly referenced in the metadata for ease of use at “design time.”
Deprecation
Deprecation is an integral part of evolution and provides consumers with insight into your future plans for breaking changes. Deprecation can be expressed at the field or message level, as shown below:
// An example of a deprecated attribute
message EventWithDeprecatedField {
// Seemed like a good idea at the time. Will be removed (or reserved) at a later date
int32 old_field = 1 [deprecated = true];
// Much better idea
int64 new_field = 2;
}
External standards
How should you represent an email address? A date? A product? A regulatory submission? Chances are that there is a standard out there, so let’s use it.
Wherever practical, we always reference these standards in our documentation—either as the sole definition or in relation to Saxo’s implementation. We link the domain model to external standards by virtue of the “business term” option using the term_source and term_ref options illustrated below:
// The measure which is an amount of money specified in monetary units (number with a
// currency unit). Where the currency is inferred (i.e. not populated) references to this types
// should clearly articulate in which currency the price is denominated.
message MonetaryAmount {
option (metadata.term_source) = TERM_SOURCE_FIBO;
option (metadata.term_source_ref) = "https://spec.edmcouncil.org/fibo/ontology/FND/Accounting/CurrencyAmount/MonetaryAmount";
// Financial amount
DecimalValue amount = 1;
// Optional currency code
CurrencyIdentifier ccy = 2;
}
This example explicitly notes that the definition of MonetaryAmount has been taken directly from the Financial Industry Business Ontology’s term of the same name.
Linking terms
As we iterate the domain model, we may inadvertently duplicate concepts across different data domains. This is inevitable, no matter how much upfront design is performed. Rather than wait for a breaking change, there needs to be a mechanism that allows us to reference an existing concept without impacting existing producers or consumers.
We link elements in the domain model to what is recognised as the authoritative definition of the business term by virtue of the field_term_link option:
// An example of linking to a 'business term'
message EventWithLinkedTerm {
// the trade currency
string trade_currency = 1 [(metadata.field_term_link) = "CurrencyIdentifer"];
}
In this example, we annotated trade_currency to reference the ubiquitous representation of ‘currency’ without impacting the compatibility of the schema. This can be used to not only improve documentation but also serve as an aide-memoire for future iterations of the domain model.
Measuring value
The value of this design lies in our ability to exploit data further. How do we know that we’re on the right path? In our case, Saxo has identified a number of indicators we will use to measure progress towards our vision:
- Number of connections in the mesh (a disconnected domain is unlikely to offer wider value)
- Producer:Consumer ratio
- Lead time to create a consumer-aligned data product
- Data product measures (e.g., trend of data quality coverage)
- Test coverage (resilience to change)
- Etc
Future direction
Although Saxo has iterated on these ideas for a while, it’s only relatively recently that adoption has grown as we look to address our scaling challenges. Our primary focus is to:
- Continue to lower the barrier of entry to the platform
- Increase the value-add of the platform through, for example, an automated reconciliation framework
- Work with our colleagues across in the Data Office and across the Bank to embed domain thinking
- Continue to collaborate with Acryl and the LinkedIn DataHub community to make the Data Workbench a one-stop shop for all data professionals through:
- A domain-centric user interface
- Gamification of domain health
- Crowdsourcing improvements to schema documentation
- Display data quality rules and results in the user interface
- Inclusion of all other upstream/downstream platforms
- Enable teams to easily adopt tools such as ksqlDB
Learn more about data mesh
- Check out the Data Mesh 101 course available for free on Confluent Developer
- Listen to the Streaming Audio podcast, where I discuss the content in this post in further detail
- Watch my talk The Good, the Bad, and the Ugly
References
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, Zhamak Dehghani
- MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean & Sanjay Ghemawat
- Data Mesh Principles and Logical Architecture, Zhamak Dehghani
- Data Mesh Defined, James Serra
- Guide to GitOps, WeaveWorks
- Domain Language, domainlanguage.com
- Data Integrity at Origin, ThoughtWorks Technology Radar
- 2020 State of DevOps Report, Puppet Labs
- DataHub Repo, LinkedIn
- Schema Evolution in Avro, Protocol Buffers and Thrift, Martin Kleppman
- https://www.fpml.org/
- JSON & FpML: A Discussion Document, FpML Architect Working Group
- Adding Semantic Annotations to JSON Schema, json-schema-org
- Language Guide (proto3), Google
- TwoHardThings, Martin Fowler
- Buf, Uber
- Mesh, Cambridge Dictionary
- Financial Industry Business Ontology, EDM Council
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.



Predictive Analytics: How Generative AI and Data Streaming Work Together to Forecast the Future
Discover how predictive analytics, powered by generative AI and data streaming, transforms business decisions with real-time insights, accurate forecasts, and innovation.